💬 はじめに
本番環境で Railsのコンテナが突然落ちる という事象が発生しました。
AWSのコンソールを見ると、ログにこう出ていました。
OutOfMemoryError: Container killed due to memory usage
メトリクスを見てみると
- メモリ使用率が常に高い状態でCPUが時折100%を超えている!
→これはおそらくコンテナがメモリ不足で落ちてECSが自動的に再デプロイしている!!
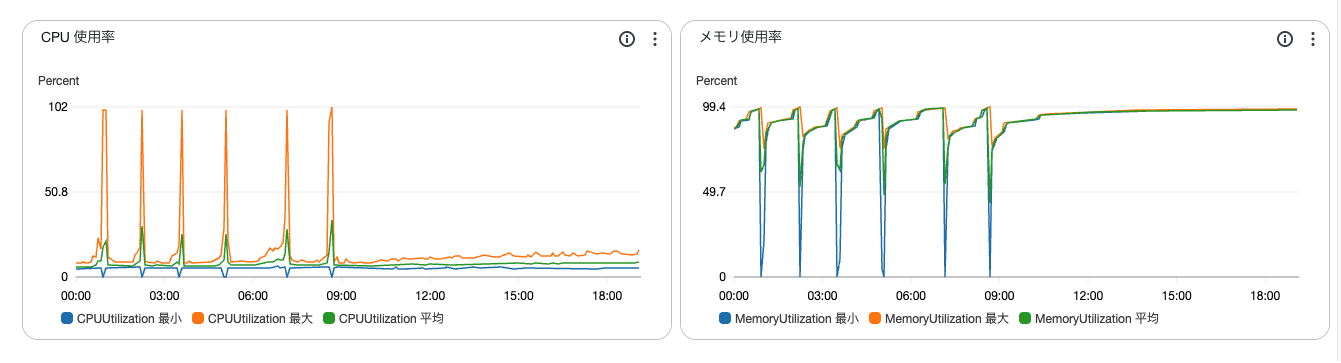
↑これは明らかに異常です!
調査を進めると、
Jobで使用しているSolid Queue の並列設定が“盛りすぎ” になっており、
ワーカーが過剰にスレッドを確保してメモリを食い潰していることが原因でした。
今回は、同一コンテナ内でディスパッチャとワーカーの並列度を絞り込み、さらに Puma 側のスレッド数を明示することで安定化させた経緯をまとめます。
※Solid Queue を Railsコンテナとは別コンテナとして分離し、バックグラウンド処理専用のタスクとして運用するのが理想かもしれないです。
🧩 背景と課題
もともとの設定は以下のようなものでした。
-
高めの並列設定
batch_size: 1000threads: 5processes: 2
- 実際のジョブ負荷は軽く、I/O待ち中心
-
WEB_CONCURRENCYやRAILS_MAX_THREADSが未設定のまま起動-
そのため、Pumaと Solid Queueがそれぞれ独立して並列処理を走らせており、
コンテナ全体としてメモリ使用量の整合が取れていない状態 でした。🔹 🔍 整合性が取れていないとは?
ここでの「整合性が取れていない」とは、Webサーバー(Puma)とバックグラウンドワーカー(Solid Queue)が、同じコンテナ内でそれぞれ勝手にスレッド・プロセスを立てていた状態を指します。ECSなどの本番環境では、RailsのWeb処理(Puma)とジョブ処理(Solid Queue)が
同じメモリ空間を共有して動作させています。- Puma側では
WEB_CONCURRENCY × RAILS_MAX_THREADSの分だけスレッドが起動 - Solid Queue側では
processes × threadsの分だけスレッドが確保
それぞれが「自分の世界」で並列処理を行うため、
結果的にメモリ使用量が2倍、3倍と重なって膨らんでいくわけです。 - Puma側では
-
この状態だと、Solid Queue のワーカーが複数スレッド分のメモリを同時確保し続けるため、使用率が徐々に上昇 → 解放が追いつかず コンテナ落ち に至ります。
用語の解説(理解されている方は飛ばしてください)
🔹 Solid Queue 側のパラメータの解説
batch_size
- 概要:ディスパッチャが1回のポーリングでまとめて取得するジョブ数。
-
挙動:値を大きくすると一度に多くのジョブをフェッチ→メモリ使用量が増えやすい。
小さくすると頻度は上がるが、メモリが安定しスケジューリングも追従しやすい。 - ポイント:I/O待ちが多い軽めのジョブでは 100〜300程度 がで十分。今回は1000はオーバースペックであったと思う。
threads
- 概要:1プロセスあたりのジョブ実行スレッド数。
- 挙動:上げすぎるとメモリ使用量が増加。
-
ポイント:まずは 1 から。増やすよりプロセス分離(
processes)の方が安定。
processes
- 概要:ワーカーのプロセス数(OSプロセス単位の並列度)。
- 挙動:上げるとプロセスごとにRailsをロードするためメモリコストは増えるが、障害の影響を分離できる。
- ポイント:小規模の利用であれば、初期値は 1 で十分。必要に応じて 2 へ増やす方針で対応すると良いかも。
💡 総並列度の目安:
threads × processes がワーカー全体の実効並列数になります。
🔹 Puma 側の環境変数の解説
WEB_CONCURRENCY
- 概要:Pumaのワーカー数(プロセス数)を指定する環境変数。
-
使われ方:HerokuやECSなどで一般的な慣習。
workers Integer(ENV.fetch("WEB_CONCURRENCY", 1)) -
効果:Railsアプリを複数プロセスで並列起動。
各プロセスが独立メモリ空間を持つため、上げすぎるとコンテナメモリを圧迫。
RAILS_MAX_THREADS
- 概要:Pumaのスレッド数を指定する環境変数。
-
使われ方:
threads_count = Integer(ENV.fetch("RAILS_MAX_THREADS", 5)) threads threads_count, threads_count -
効果:1プロセス内での同時リクエスト処理数。
増やすとスループットは上がるが、メモリ使用量も増える。
💡 Pumaの総並列度:
workers × threads が全体の同時リクエスト処理数の目安。
🔧 Solid Queue 設定の見直し
変更内容
# config/solid_queue.yml(一部抜粋)
production:
<<: *default
dispatchers:
- polling_interval: 1
batch_size: 200 # 1000 → 200 に縮小
workers:
- queues: ["default", "mailers"]
threads: 1 # 5 → 1
processes: 1 # 2 → 1
ポイント
| 項目 | 変更理由 |
|---|---|
batch_size: 200 |
一度に大量のジョブをフェッチせず、小刻みに処理してメモリ使用量を均す |
threads / processes: 1 |
スレッドの競合を防ぎ、プロセスごとのメモリ確保を最小化 |
🧠 Puma 側のデフォルトも明示
Solid Queueの並列度を落としたなら、
Webプロセス(Puma)側のスレッド数も明示しておくとより安定します。
# entrypoint.prod.sh(一部抜粋)
export WEB_CONCURRENCY=${WEB_CONCURRENCY:-1}
export RAILS_MAX_THREADS=${RAILS_MAX_THREADS:-2}
これにより:
- インフラ側で値を渡さなくても最低限の構成で起動
- Solid Queueとの整合性が明確に
- 「Railsがどの程度の並列処理を想定しているか」が一目で分かるように
📊 効果(初期観測)
期待していたこと
- 不要な並列処理を削減し、メモリ使用量を平準化
- Solid Queueワーカーの暴走を防止し、コンテナ落ちを回避
- Puma側との整合性を確保して、全体負荷を安定化
実際の初期観測
- 本番環境で メモリ使用率が最大100% → 約45%に低下
- コンテナ再デプロイが発生しなくなった
↓最終的には落ち着かせることができました!
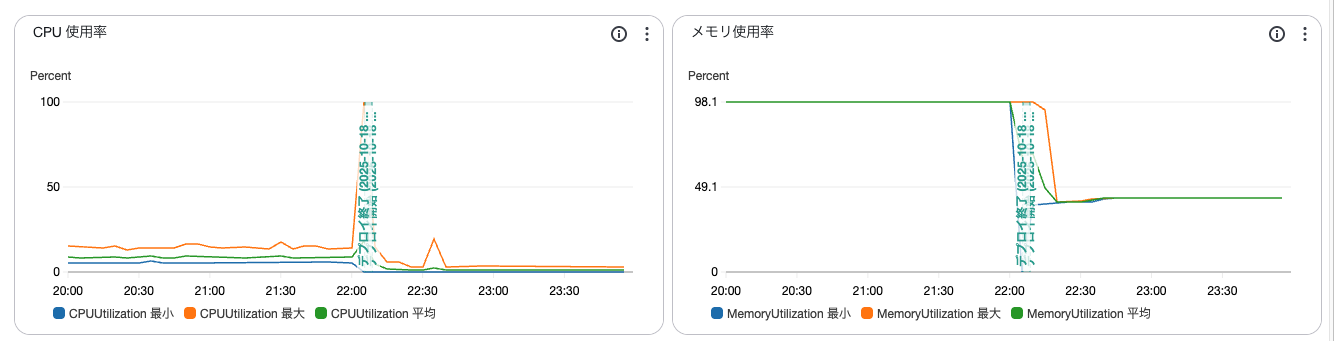
🧭 今回の学び
- 「とりあえずスレッド増やす」は危険。 必要があれば増やすという方針がよさそう!
- ワークロードに合わせたbatchサイズと並列度の設計が大切!
💬 おわりに
今回のOutOfMemoryErrorは、「負荷ではなく設定」が原因でした。
PumaとSolid Queueの並列度を見直すだけで、 コンテナの安定性が大きく改善することを実感しました。
今後は、ジョブ種別ごとに処理の重さを考慮してメモリ消費の見積もって設定をしていこうと思います。
同じように「Solid Queueを導入したらメモリが膨らんで落ちる…」という悩みを抱えている方の参考になれば嬉しいです。