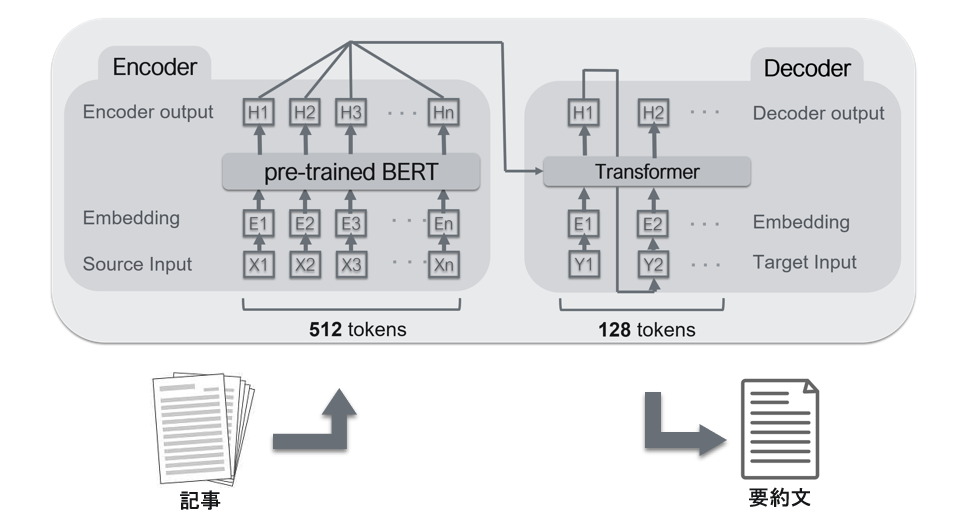
モデル概要
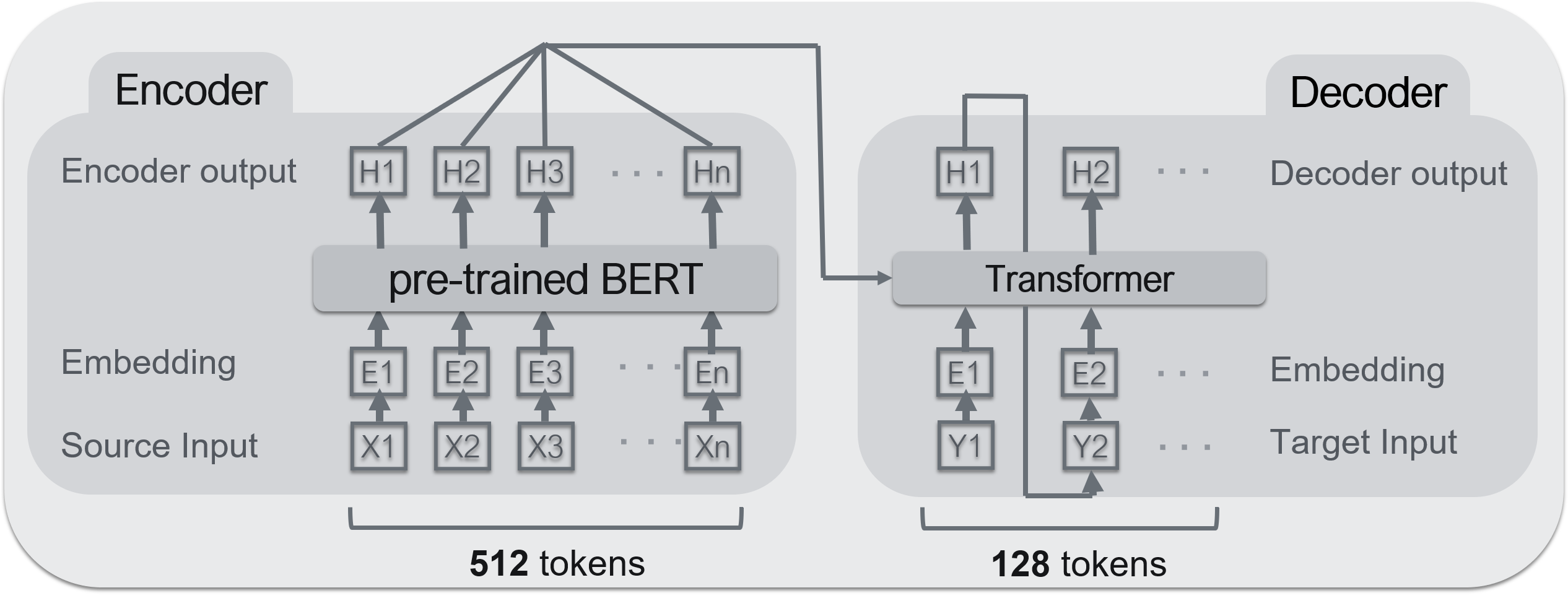
- エンコーダ:BERT
- デコーダ:Transformer
典型的なencoder-decoderモデル(Seq2Seq).Seq2Seqについては,ここら辺が参考になる.
エンコーダにはBERT,デコーダにはTransformerを使っている.BERTの事前学習モデルは京都大学 黒橋・河原研究室にて公開されているものを使用している.BERTは高性能なエンコーダになれるが,デコーダにはなれない.理由は,エンコーダの入力を受け取れないから.しかし,BERTは構造的にはTransformerの集合なので,ほぼ同じと考えてもいい.
データセット

モデルの学習用のデータセットにはLivedoorニュースを使用した.訓練データは約10万記事,検証データは約3万記事
- データセット:Livedoorニュース
- 訓練データ:100,000記事
- 検証データ:30,000記事
- 最大入力単語数:512単語
- 最大出力単語数:128単語
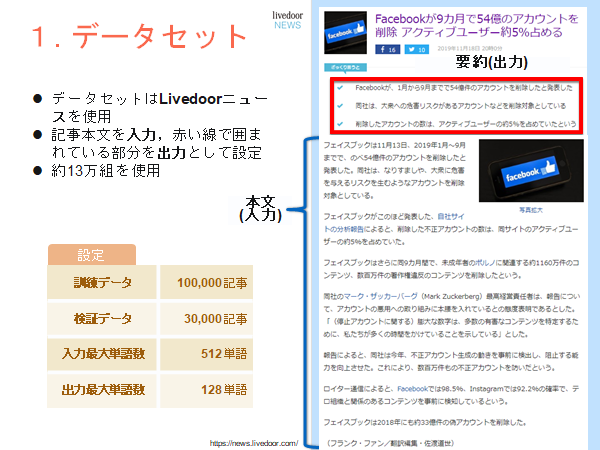
上の画像の右側,下の部分が本文(入力文),上の赤い枠で囲まれた部分が要約(出力).
本文は512単語を超えたら,それ以下の単語を切り捨てる.要約文の場合は128単語.
この手法は,文章要約タスクでよく使われるもので,「長い文章は初めの方に重要なことが書いてあることが多い」という考えに基づいている.
前処理
今回の前処理は主に二種類ある.
「単語分割」と「WordPiece」.
1. 単語分割
単語分割にはMeCab+NEologdを使用している.
→ なぜ形態素解析を用いるのか?

上の画像のように,英語などの言語は半角スペースで単語に分割することができるが,日本語はそういったことができない.そのため,形態素解析ツールで分割する.
2. WordPiece
ところで,こういったモデルは語彙をあらかじめ記憶しておいて,その語彙の中にある単語をつなぎ合わせて文章を出力する.そのため,語彙にない単語は基本的に"[UNK]"のような特殊な文字に置き換えられる.
しかし,文章要約においては固有名詞が大事だったりする.そのためできるだけ語彙にない単語(以下,未知語)を減らしたい.
そこで,「WordPiece」という手法がよく用いられる.
WordPieceとは,未知語(語彙にない単語)をさらに分割して,語彙にある単語の組み合わせで表現しよう,というものだ.具体的には,
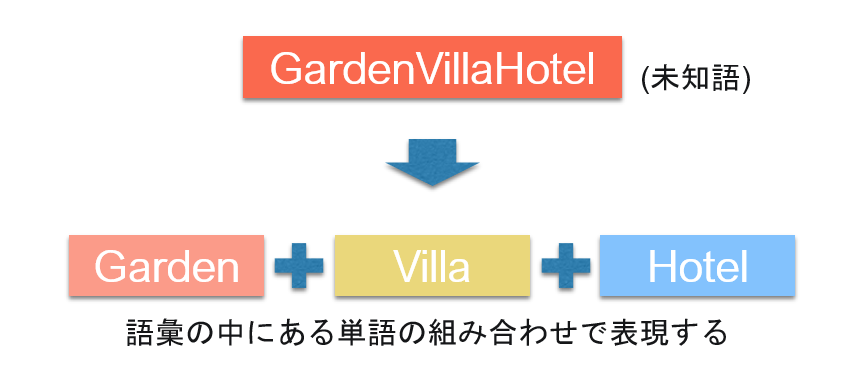
上の画像のようになる.この場合は「GardenVillHotel」という単語が語彙のリストの中になかったため,「Garden」,「Villa」,「Hotel」という,語彙の中にある単語の組み合わせで表現している.
学習
上の図のように,エンコーダに入力文(記事本文),デコーダに出力文(要約文)を設定して学習させる.
学習時のログは以下の通りとなっている.
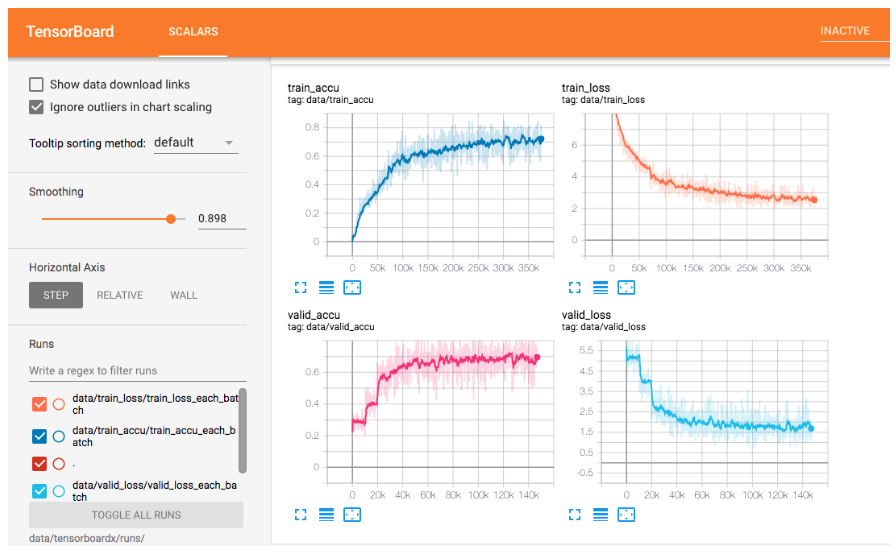
上の画像を見ると,左側の精度が徐々に上がっていき,右側の損失が徐々に下がっていっているのが見て取れる.
BERTの補足
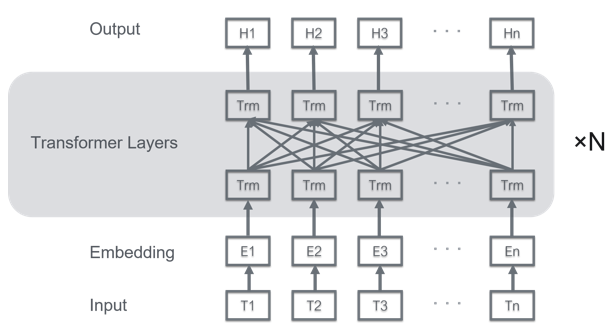
以下BERTの論文なので,詳しいことはここ見てください.
https://arxiv.org/abs/1810.04805
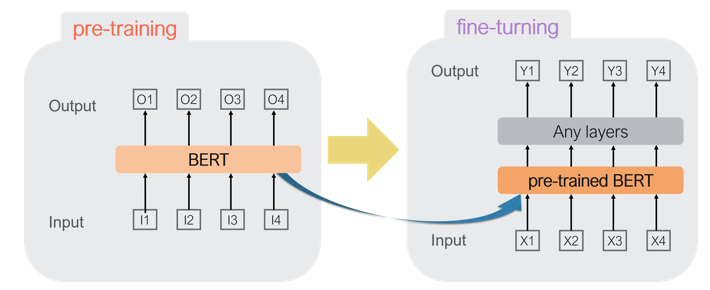
BERTは普通のモデルと違って,学習には2つのプロセスがある.
- 事前学習(pre-training)
- 転移学習(fine-turning)
1. 事前学習
事前学習とは,特定のタスクをBERTモデル単体で学習させることである.これによって,それぞれの単語の埋め込みベクトル(Embedding Layerのベクトル)を学習することができる.つまり,単語単体での意味を学習できるということだ.
2. 転移学習
転移学習は,事前学習済みモデルをほかのレイヤーと結合させ,自分のタスクを学習させるというものだ.これは,一からそのタスクを学習させるのに比べて,短時間で学習ができる.
また,BERTを用いたモデルは多数のSOTA(state-of-the-art)をたたき出しているので,一から学習するモデルより高精度でもある.