こんにちは。LabBase リサーチチームの高橋です。
LabBase アドベントカレンダー 6 日目です(遅刻しました)。
背景
LabBase 就職 は、おもに理系の就活生の研究概要などのプロフィールを企業が閲覧し、直接スカウトを送信する就職支援サービスです。
弊サービスは、スカウトをお送りいただいた件数に応じて料金を頂いています(学生側は無料です)。この料金体系を採用する理由の 1 つは、スカウト 1 件 1 件に重みを持たせるためです。
この体系においては、スカウトの開封率、返信率、承諾率などの KPI が重要になります。参考までに 2021年3月 ~ 2022年2月 の開封率は 90%、返信率が 40% でした(上記リンク先の公開情報)。
仮にこれらの指標が悪化、すなわちスカウトを送信しても学生側のレスポンスが悪くなれば、個々の学生の専門性にフォーカスしてスカウト送信するより、固定額で無制限に送信できるほうがコスト面で優位になるでしょう。これは『研究の力を、人類の力に』という LabBase の方針に悖ります。
したがって、これら KPI につながる学生および企業ユーザーの行動分析は重要です。
通常はプロフィール記述量や各種行動のリードタイム、ログイン頻度などの変数が注目されますが、本記事はやや趣向を変え、自然言語処理を用いてプロフィールから KPI に相関する変数を抽出する 試みを紹介します。
RIASEC
世に就活生の職業適性を測る試みはいくつも提案されています。G テストやマイナビ提供の WEB テストなど、就活中に受験された方もおられるかと思います。
しかし大半は、検査項目や評価算出がすべて公開されてはおらず、今回の目的に適いませんでした。
以下では、RIASEC モデル について検討します。
ホランドコード(英:Holland Codes)またはRIASECとは、アメリカの心理学者であるジョン・L・ホランドによって開発された性格タイプに基づくキャリアと職業選択の理論である。
米国労働省の雇用訓練局は、1990年代後半の開始以来、無料のオンラインデータベースO-NET(Occupational Information Network)の「興味」(Interests)セクションで、RIASECモデルの更新・拡張版を用いている。
RIASEC は以下のアクロニムです。各職業がこれらのカテゴリに分類されます。
- R: Realistic (Doers)
- I: Investigative (Thinkers)
- A: Artistic (Creators)
- S: Social (Helpers)
- E: Enterprising (Persuaders)
- C: Conventional (Organizers)
具体的にどの職業がどこに分類されているかは、上記リンクを参照してください。
RIASEC は Vocational Preference Inventory (VPI) テストによって測るのが一般的のようです。調べてみると、O-NET Interest Profiler Reference Manual が見つかりました。
- 60 項目(RIASEC 各カテゴリに 10 項目ずつ紐づく)
- 5 段階評価 (Strongly Dislike / Dislike / Unsure / Like / Strongly Like)
RIASEC はテストが公開されていてかつ実績があり、今回の目的に適していました。
データ拡張
テストは公開されていますが、以下の理由からこれをそのまま使うことはできません。
- 既述のプロフィールから推定したい
- 項目内容が現代の国内の理系学生の実情に必ずしもフィットしていない
- 項目数が少ない
そこで LLM に検査項目を修正・拡張してもらうことにしました。
以下は RIASEC 職業適性コードを検査するための項目です。
{items}
これらのリストを現代日本で理学や工学を専攻する学生向けに作り直してください。各タイプの項目数は {n} 個とします。
複数のタイプに当てはまる項目や、論理的に互いに排他でない項目群の生成は禁止します。
一例として以下のような出力が得られます(Realistic)。
- 実験装置を組み立てる
- 機械の部品を精密に加工する
- 電子回路を設計し、試作する
- ...
余談ですが、LLM にバーっと短文を吐き出させるやり方は、DeepSeek が使ったという知識蒸留からパクりました:Symbolic Knowledge Distillation: from General Language Models to Commonsense Models
可視化
このように出力した項目群が、埋め込み空間上でカテゴリごとにクラスタを形成しているか確認してみましょう。埋め込みモデル ruri-v3-310m を使用しました。
RIASEC ごとに 30 個生成した埋め込みベクトル群の距離行列を可視化してみます。

うっすらとですが、対角上に RIASEC に対応する 6 つのブロックが見られます。
また Artistic の排他性が高く Enterprising は低いこと、Realistic と Artistic は比較的相関が見られることなどが観察できます。
また埋め込みベクトルを UMAP で次元削減して可視化してみました。
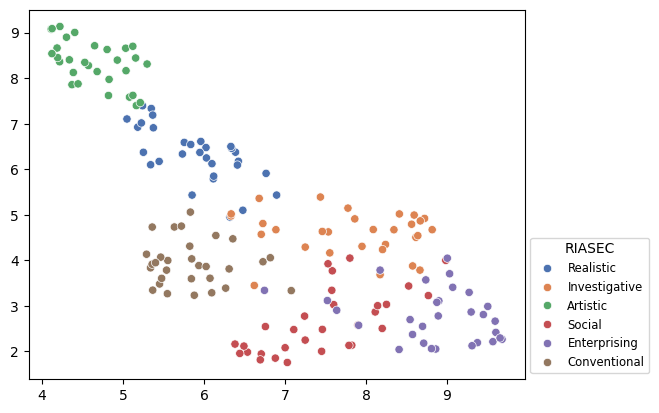
実はもっと分布が重なることを想定していましたが、思いのほかくっきり分かれてくれました。
応用
さて、これらを用いて任意のプロフィール文の各 RIASEC カテゴリのスコアを算出しましょう。
もっとも単純なのは、各クラスタの重心ベクトルをそのカテゴリの代表と見做し、埋め込み空間で距離(埋め込み空間が単位球面なら内積)を取ることです。これはニューラルネットワークで分類問題を解くとき最終層付近でやっていることとほぼ同じです。
分散も考慮してマハラノビス距離を取ると、より丁寧かもしれません。
また埋め込みデータを ICA で分解して軸ごとにソートすると、解釈性の高い構成になることが知られています:Discovering Universal Geometry in Embeddings with ICA
以下はサンプルコードです(embeddings の定義などは割愛)。
from sklearn.decomposition import FastICA
from scipy.stats import skew
n, k = 100, 10
ica = FastICA(n_components=n, max_iter=1000, tol=0.001)
embeddings_ica = ica.fit_transform(embeddings)
embeddings_ica *= np.sign(skew(embeddings_ica)) # 歪度の大きい向きを正に
for i in range(n):
comp = embeddings_ica[:,i]
topk = np.argsort(-comp)[:k] # descending
print([riasec_items[j] for j in topk])
この結果から、特定カテゴリが上位に固まるような軸ベクトルを各カテゴリ分布の重心の代わりに使うこともできるでしょう。結局は重心ベクトルに近いベクトルになるかもしれませんが、観察過程で新たな洞察が得られる可能性があります。
プロフィールと同様にスカウトの文を埋め込んでスコアを比較したり、あらかじめ企業ユーザーの RIASEC 職業コードを用意しておくことで、その合致率を特徴量として抽出し、冒頭の KPI との相関を測ることができるようになります。
スカウトに現れる文の傾向や、既存の職業コードと実情のギャップによって、埋め込みの調整が必要になる場合は、マルチモーダル特徴量に関する知見が役に立つかもしれないと推測しています。
跋
NLP を用いてプロフィールから特徴を抽出する試みを紹介してきました。
今回のセマンティックな特徴量と KPI との相関を計算した結果は、まだ確認できていません。機会があればお話ししたいと思っています。
LabBase では AI を援用したデータ分析と KPI 改善にも積極的に取り組んでいます。興味のある方はお声掛けください。