ChatGPTにER図を描かせてみる
今回は、ChatGPTを使ってデータベースのER図を描いてもらう方法について紹介したいと思います。
そのままChatGPTにDDLを貼って「ER図を描いて!」っておねがいしても頑張って作ってくれますが・・・
うーん、テキストベースの図って何かイケてない感じしますよね。
でも、ChatGPTに頼んで実際のデータベースから綺麗なER図を描いてもらえたら、めちゃくちゃ面白いですよね。しかもStreamlitを使って簡単にWebアプリ化できればすごくお手軽。
本記事では、ChatGPTを使って、SnowflakeスキーマのER図を描かせてみました。
こんな感じです。
使用ツール
ChatGPT
自然言語処理のタスクを実行することができ、文章生成や翻訳、文章の要約などの様々なアプリケーションに利用されます。本記事ではDDLからER図を作成するために使います。
Snowflake
クラウドベースのデータウェアハウスであり、大量のデータを高速かつスケーラブルに処理できます。30日間の無料トライアルもあります。本記事ではデータベースとして使います。
Snowpark for Python
Pythonを使ってSnowflakeに対してクエリを実行できます。また、SnowflakeはAnaconda社と提携しているため、Snowflakeがミラーリングして提供しているAnacondaパッケージを無料で利用できます。本記事ではStreamlitからSnowflakeに接続するために使います。
Streamlit
Pythonの知識があれば、誰でも簡単に機械学習やデータ分析などのアプリケーションをウェブアプリケーション化することができます。本記事ではWEBアプリとして使います。
Mermaid
ウェブベースの図表作成ライブラリであり、ER図やフローチャート、シーケンス図などを簡単に描くことができます。本記事ではER図を描画するために使います。
作成手順
コードはモックとしてかなり簡単な書き方で書いています。
1.ライブラリのインポートとコンフィグ設定
openai, streamlit, snowparkなど諸々のライブラリは既にインストールしてあるとします。
ライブラリのインポートと同時に、ChatGPT APIを利用するために必要なOrg_KeyやAPI_Keyを設定します。
import re
import openai
import streamlit as st
import streamlit.components.v1 as components
from snowflake.snowpark.session import Session, col
openai.organization = ""
openai.api_key = ""
2.アプリの処理
ここからは、アプリの処理部分を作成してきます。処理フローは以下のようになっています。
2.1.Snowflakeセッション作成処理
ここに記載した接続情報を使ってSnowflakeに接続を行います。
def create_session_object():
connection_parameters = {
"account": "",
"user": "",
"password":"",
"role": "",
"warehouse": "",
"database": "",
"schema": ""
}
session = Session.builder.configs(connection_parameters).create()
return session
2.2.データベース一覧の取得処理
Snowflakeに接続し、データベース一覧を取得します。
def load_database():
session = create_session_object()
dbdata = session.sql("show databases").collect()
session.close()
list = []
for raw in dbdata:
list.append(raw[1])
return list
2.3.スキーマ一覧の取得処理
Snowflakeに接続し、指定したデータベースにあるスキーマ一覧を取得します。
def load_schema(database):
session = create_session_object()
schmdata = session.table(database + ".INFORMATION_SCHEMA.SCHEMATA")
schmdata = schmdata.select(col("schema_name")).filter(col("schema_name") != "INFORMATION_SCHEMA").collect()
session.close()
list = []
for raw in schmdata:
list.append(raw[0])
return list
2.4.DDL取得処理
Snowflakeに接続し、指定したスキーマ上のDDLを取得します。
def load_ddl(database, schema):
session = create_session_object()
ddllist = session.sql("select get_ddl('schema','"+database+"."+schema+"');").collect()
session.close()
list = []
for raw in ddllist:
list.append(raw[0])
return str(list)
2.5.ER図に変換
ChatGPTにお願いして、取得したDDLからER図を作成してもらいます。
def generate_chat(content):
msg = [
{"role": "system",
"content": "あなたはAIアシスタントです。"},
{"role": "user",
"content": content + "\n上記のDDLからMermaid記法でER図を作成してください。ただし、作成にあたって以下の条件に従ってください。Mermaid10.1.0で動作する。Mermaid記法のコードのみ回答する。EntitiyとRelationshipのどちらも記載する。Relationshipではラベルを付ける。"}
]
res_chatgpt = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=msg,
temperature=0.1
)
chat = res_chatgpt["choices"][0]["message"]["content"]
return chat
2.6.変換結果の後処理
ChatGPTに作ってもらったMermaidコードのSYNTAX ERRORを回避するためのおまじないです。
def post_process(chat):
chat = chat.replace("mermaid", "")
chat = chat.replace("located in", "located_in")
chat = chat.replace("belongs to", "belongs_to")
chat = chat.replace("supplied by", "supplied_by")
chat = chat.replace("lives in", "lives_in")
chat = chat.replace("made by", "made_by")
chat = chat.replace("consists of", "consists_of")
chat = chat.replace("--|>", "||--||")
chat = chat.replace(",", "_")
chat = chat.replace("unique", "")
chat = chat.replace("UQ", "")
chat = chat.replace("PK FK", "FK")
return chat
2.7.上記のラップ処理
2.4~2.6を纏めたラップ処理。
def generate_response(database, schema):
data = load_ddl(database, schema)
res = generate_chat(data)
chat = post_process(res)
return chat
3.アプリのUI
ここからは、Streamlitを利用したUI部分を作成していきます。
3.1.タイトル
タイトルはChatGPTに適当に作ってもらいました。
st.title('AIER')
st.write('Artificial Intelligence Entity-Relationship diagram')
3.2.サイドバー
ER図を作成するために使うデータベース名とスキーマ名を指定する箇所です。
ページを開いた瞬間に、データベース一覧を読み込んでおく処理も書いておきます。
dblist = load_database()
with st.form("input1", clear_on_submit=False):
db_name = st.sidebar.selectbox("Select Database", dblist)
if db_name:
schmlist = load_schema(db_name)
with st.form("input2", clear_on_submit=False):
schema_name = st.sidebar.selectbox("Select Schema", schmlist)
3.3.メイン画面
Mermaid形式のコードをStreamlit上に描画します。
MermaidはJavascriptで動いているので、Streamlitのcomponentsを使ってHTMLで読み込ませています。
if submitted:
result = generate_response(db_name, schema_name)
code = f"<pre class=\"mermaid\">{result}</pre><script type=\"module\">import mermaid from 'https://cdn.jsdelivr.net/npm/mermaid@10/dist/mermaid.esm.min.mjs';mermaid.initialize({{ startOnLoad: true }});</script>"
code = code.replace("```","")
components.html(code, height=1500)
実際に動かしてみた
事前準備
Snowflake上に適当なテーブルを用意しておきます。
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(100) UNIQUE,
phone VARCHAR(20),
address VARCHAR(200)
);
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
status VARCHAR(20),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
CREATE TABLE categories (
category_id INT PRIMARY KEY,
name VARCHAR(50),
description TEXT
);
CREATE TABLE products (
product_id INT PRIMARY KEY,
name VARCHAR(50),
description TEXT,
price DECIMAL(10,2),
category_id INT,
FOREIGN KEY (category_id) REFERENCES categories(category_id)
);
CREATE TABLE order_details (
order_id INT,
product_id INT,
quantity INT,
price DECIMAL(10,2),
PRIMARY KEY (order_id, product_id),
FOREIGN KEY (order_id) REFERENCES orders(order_id),
FOREIGN KEY (product_id) REFERENCES products(product_id)
);
実行
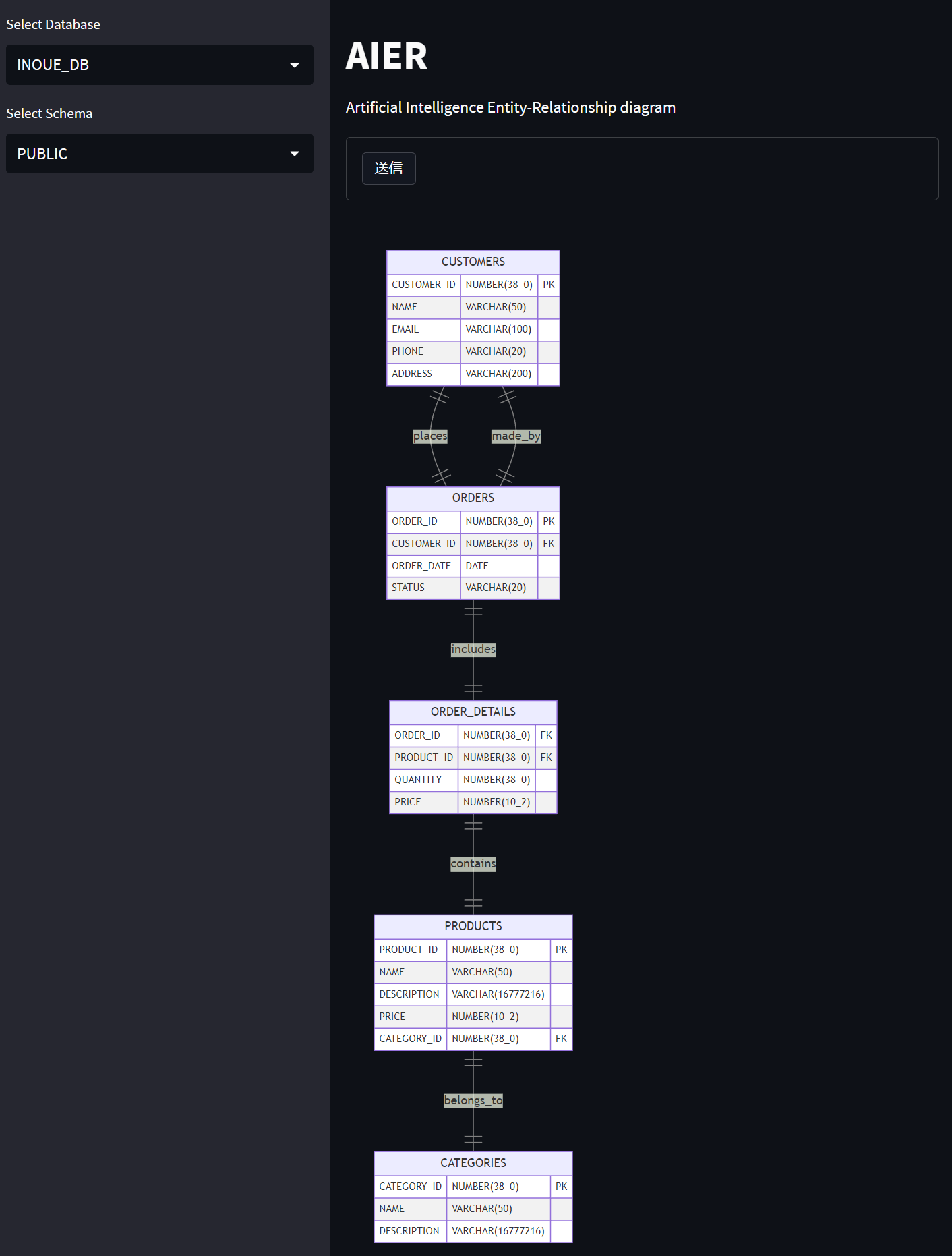
スキーマを選択して、「送信」を押下します。

結果はこんな感じです。
まだプロンプトの精度が悪いので完璧とは言えませんが、概形は結構正しく描けていますね。
まとめ
今回は、Streamlit, ChatGPT, Snowpark for Python, Mermaidと様々なツールを使ってアプリを作ってみました。これくらいのものが1日足らずで作れちゃうのは面白い時代になってきましたね。
参照元
OpenAI API Reference
Getting Started With Snowpark for Python and Streamlit
St.markdown does not render mermaid graphs
仲間募集
NTTデータ テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、
お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、
お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。
https://nttdata.jposting.net/u/job.phtml?job_code=804
4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDFⓇ-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~
https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
https://enterprise-aiiot.nttdata.com/service/tableau
NTTデータとAlteryxについて
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
https://enterprise-aiiot.nttdata.com/service/informatica
NTTデータとSnowflakeについて
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。