はじめに
Qiita に限らず,Solr の検索機能についての記事はよく見かけるのですが,ドキュメント登録(インデクシング)についての記事はあまり見かけません。
と思っていたところ Solr のインデクシングに関して少し検索をしてみたら,思っていた以上に記事を見つけることができました。。。(2017年12月現在)
Solr Advent Calendar 2017 の 15 日目はインデクシングについて書こうとしていたので,さてどうしたものかと思ったのですが,Solr を初めて触る人向けの「インデクシング最初の一歩」的な記事であれば少しは意義があるかと思い,これをモチベーションにしたいと思います。
Solr にドキュメントを登録する時はどうすれば?
Solr にドキュメントを登録することをインデクシングと言ったりしますが,皆さん Solr にインデクシングする時はどのような手段を用いているのでしょうか?
DataImportHandler?ManifoldCF?独自クローラー?
間違いではありませんが,何だかどれも初めの一歩としてはハードルが高そうです。Solr に興味を持ったのに,肝心のドキュメント登録で躓いていては Solr のリッチな検索機能を堪能することはできません。
手っ取り早くインデクシングするには PostTool を使うのが一番です。Solr のマニュアルなどを見ても,とりあえず PostTool を使ってサンプルをインデクシングしていますね。
ということで,本記事では Solr に標準搭載されている PostTool の使い方や挙動について解説したいと思います。
環境
本記事は以下の環境で実行しています。
- Solr のバージョン:7.1
- OS:macOS Sierra
PostTool とは?
PostTool とは,Solr に標準搭載されているインデクシング用のアプリケーションです。と言っても,インデクシング用に GUI が用意されていたりするわけでもなければ,エンタープライズ用途に耐えられる充分な機能が備えられているわけでもありません。
PostTool はとてもコマンドライン上で動作する,とてもシンプルなアプリケーションです。
とりあえず使ってみる
何はともあれ PostTool を使ってみましょう。以下の手順でサンプルをインデクシングします。
$ cd {Solr のインストールディレクトリ}
$ bin/solr start
$ bin/solr create_core -c collection1 -d sample_techproducts_configs
$ bin/post -c collection1 example/exampledocs/*.xml
...(省略)
POSTing file vidcard.xml (application/xml) to [base]
14 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/collection1/update...
Time spent: 0:00:00.446
上記の操作によって example/exampledocs 配下にある XML ファイルを collection1 に対してインデクシングできました。マニュアルなどでもよく見かける操作だと思います。
実際にインデクシングされたか Solr で検索し,確認してみましょう。
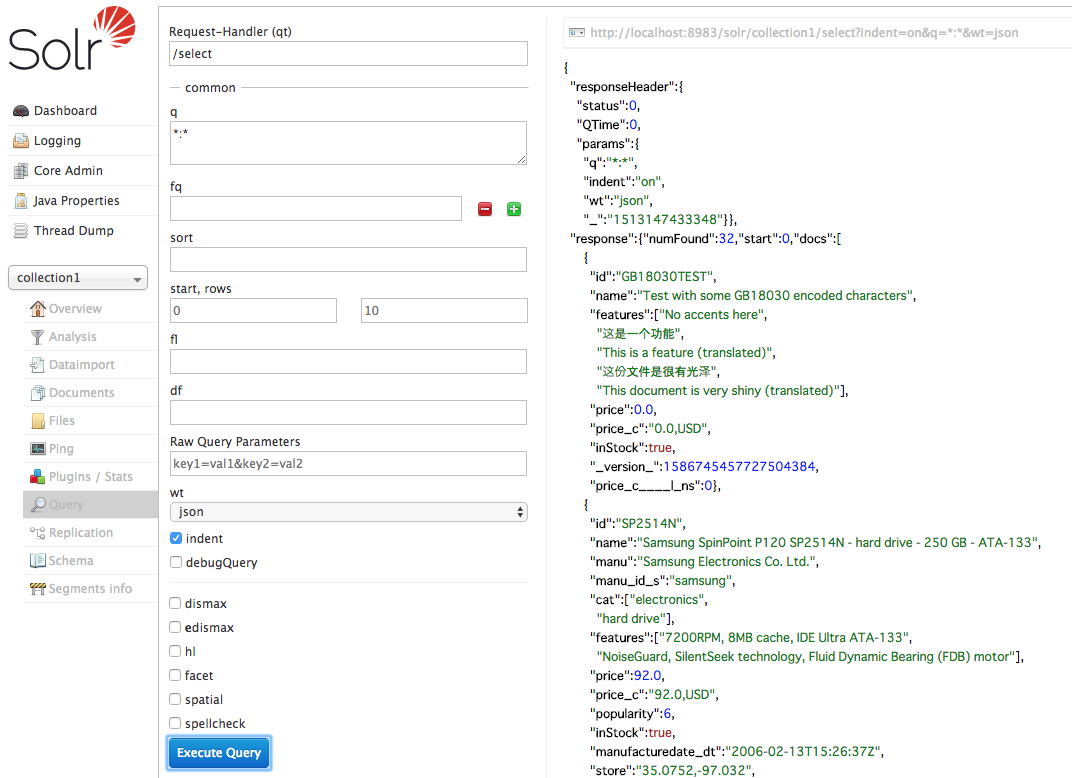
全件検索した結果は 32 件だそうです。先程 PostTool で実行した結果 14 files indexed.とあったので,検索結果も 14 件なのかと思いきや,どうやらそうではないようです。一体 PostTool は何をインデクシングしたのでしょうか?
先程インデクシングした XML を一部見てみましょう。
以下は ipod_other.xml の中身です。
<add>
<doc>
<field name="id">F8V7067-APL-KIT</field>
<field name="name">Belkin Mobile Power Cord for iPod w/ Dock</field>
<field name="manu">Belkin</field>
<!-- Join -->
<field name="manu_id_s">belkin</field>
<field name="cat">electronics</field>
<field name="cat">connector</field>
<field name="features">car power adapter, white</field>
<field name="weight">4.0</field>
<field name="price">19.95</field>
<field name="popularity">1</field>
<field name="inStock">false</field>
<!-- Buffalo store -->
<field name="store">45.18014,-93.87741</field>
<field name="manufacturedate_dt">2005-08-01T16:30:25Z</field>
</doc>
<doc>
<field name="id">IW-02</field>
<field name="name">iPod & iPod Mini USB 2.0 Cable</field>
<field name="manu">Belkin</field>
<!-- Join -->
<field name="manu_id_s">belkin</field>
<field name="cat">electronics</field>
<field name="cat">connector</field>
<field name="features">car power adapter for iPod, white</field>
<field name="weight">2.0</field>
<field name="price">11.50</field>
<field name="popularity">1</field>
<field name="inStock">false</field>
<!-- San Francisco store -->
<field name="store">37.7752,-122.4232</field>
<field name="manufacturedate_dt">2006-02-14T23:55:59Z</field>
</doc>
</add>
doc タグが 2 つ確認できます。他の XML ファイルを開いても同様のフォーマットで複数の doc タグが確認できるものもありました。
どうやら example/exampledocs/ にある XML ファイルはタダの XML ファイルではなく,doc タグ 1 つに対して Solr には 1 つのドキュメントとして認識されるようなフォーマットらしいことが分かります。
なるほど 32 件の謎は解けましたが,PostTool を使って Solr にドキュメントをインデクシングする際には,そのドキュメントは Solr が解釈できるフォーマットになっている必要があると言うことでしょうか。もしそうなら,PDF や Microsoft Office のファイルはどうすれば良いのでしょうか。メタデータや本文を抽出してこのような XML にしなければならないのであれば,とても面倒くさそうです。
とりあえず先程の要領で PDF ファイルをインデクシングしてみるとどうなるでしょうか?幸運にもサンプルには PDF ファイルがあるのでこれを使いましょう。
$ bin/post -c collection1 example/exampledocs/solr-word.pdf
...(省略)
POSTing file solr-word.pdf (application/pdf) to [base]/extract
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/collection1/update...
Time spent: 0:00:01.460
何事もなくインデクシングが完了しました。
Solr の検索画面で確認してみると,PDF の内容がインデクシングされていることが分かります。PostTool は Solr フォーマットのファイルでも PDF のようなバイナリファイルでも両方処理するよう賢く振る舞ってくれるということでしょうか?
PostTool を使ったインデクシング時の挙動
PostTool は Content-type によって挙動を変えます。XML や JSON の場合は,Solr が解釈できるフォーマットだとして処理されます。一方で TXT や PDF,Microsoft Office のようなファイルは内部のテキストが抽出され,メタデータと本文がうまく Solr のフィールドにマッピングされるよう振る舞います。
XML や JSON の場合は,フィールド名とその値を明示してあるので何が登録されるのか一目瞭然ですが,PDF などのバイナリファイルが持つメタデータはどのように Solr に取り込まれるのでしょうか。
バイナリファイルのメタデータはどのように Solr にマッピングされるのか
PDF や Microsoft Office ファイルなど,バイナリファイルのメタデータは Solr のどのフィールドにマッピングされるのでしょうか。そして Solr 側ではどのようなフィールドを用意しておけば良いのでしょうか?
PostTool がバイナリファイルを Solr にポストすると,Solr 内部では SolrCell という機能が呼ばれ,メタデータや本文のテキストを抽出し,Solr にインデクシングされます。SolrCell がどのようなフィールドに対してインデクシングするか確認するには以下の方法が一番簡単でしょう。
managed-schema に以下のフィールドを用意するだけです。もともと定義してあるフィールドはあってもなくてもどちらでも良いですが,id と _version_ だけは残しておきましょう。
<dynamicField name="*" type="string" indexed="true" stored="true" multiValued="true"/>
dynamicField フィールド を使うことで,SolrCell がどんなフィールド名で出力しても受け取れるようにした,ということですね。
この設定を使って PDF の結果を見てみましょう。(長いので大事なところだけ)
...
"id":"/Users/issei/Downloads/solr-7.1.0/example/exampledocs/solr-word.pdf",
"date":["2008-11-13T13:35:51Z"],
"pdf_docinfo_custom_aapl_keywords":["solr, word, pdf"],
"pdf_pdfversion":["1.3"],
"pdf_docinfo_title":["solr-word"],
"xmp_creatortool":["Microsoft Word"],
"stream_content_type":["application/pdf"],
"access_permission_can_print_degraded":["true"],
"subject":"solr word",
"dc_format":["application/pdf; version=1.3"],
"pdf_docinfo_creator_tool":["Microsoft Word"],
"access_permission_fill_in_form":["true"],
"pdf_encrypted":["false"],
"dc_title":["solr-word"],
"modified":["2008-11-13T13:35:51Z"],
"cp_subject":["solr word"],
"pdf_docinfo_subject":["solr word"],
...
先程とは打って変わって沢山のフィールドが表示されていますね。SolrCell はこんなに沢山のメタデータを抽出してくれるみたいです。それぞれのフィールドが何を意味しているかは別途調べる必要はありますが,この方法で抽出できるメタデータが何なのか分かったと思います。同様の要領で Word や PowerPoint などを試してみると良いでしょう。PDF とはまた違ったメタデータを抽出できることが分かると思います。
これで出力されるメタデータが分かったので,出力結果の中から,必要なフィールドだけを managed-schema に定義してあげれば良いでしょう。
こんな感じです。
<field name="pdf_docinfo_custom_aapl_keywords" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="pdf_docinfo_creator_tool" type="string" indexed="true" stored="true"/>
...
これで必要なメタデータだけ Solr にインデクシングすることができるようになりました。これはデフォルトの使い方では分からないところだと思います。
ここで 1 つ疑問が思い浮かびます。上記のように必要なフィールドだけを定義すれば,SolrCell は残りのフィールドを勝手に捨ててくれるのでしょうか?
XML や JSON を使ってインデクシングしている人は,定義していないフィールドを Solr にポストした時にエラーとなることを知っています。バイナリファイルだとまた挙動が違うのかと思ったりもしますが,答えは solrconfig.xml にあります。
solrconfig.xml の以下の部分を見てみましょう。
<requestHandler name="/update/extract"
startup="lazy"
class="solr.extraction.ExtractingRequestHandler" >
<lst name="defaults">
<str name="lowernames">true</str>
<str name="uprefix">ignored_</str>
<!-- capture link hrefs but ignore div attributes -->
<str name="captureAttr">true</str>
<str name="fmap.a">links</str>
<str name="fmap.div">ignored_</str>
</lst>
</requestHandler>
sample_techproducts_configs から作ったコアだと,デフォルトでこのようなリクエストハンドラの記述があるはずです。
ここが SolrCell の設定箇所です。PostTool が PDF などのバイナリファイルをポストする時は,結局はここの設定が使われます。(何故この設定が使われるのか,またリクエストハンドラについては適当に調べて下さい)
ここの設定は PDF などのテキスト抽出を Solr にお任せする場合にはとても大事です。それは PostTool に限ったことではありません。ManifoldCF を使った時も同様です。
ここには SolrCell が抽出したメタデータや本文情報を Solr のどのフィールドにマッピングするか定義できます。
上記を例にすると,a というフィールド名で抽出した値は Solr の links というフィールドにマッピングするという定義がされています。
従って,新しくマッピングルールを追加する時は
<str name="fmap.{SolrCell が出力するフィールド名}">{Solr のフィールド名}</str>
と書けば良さそうです。
でもこれだけだと先程の定義されていないフィールドを捨ててくれる現象は説明できません。大事なのはここです。
<str name="uprefix">ignored_</str>
この 1 行のおかげで定義されていないフィールドが SolrCell から投げられたとしてもエラーとならなかったのです。
この設定は定義されていないフィールド名の値は全て ignored_ フィールドに投げるという設定です。
ignored_ フィールドは managed-schema を見てもらえば分かりますが,無視されるフィールドです。このフィールド名に対してインデクシングしても Solr は何もしません。
なので,ignored_ フィールドがない状態で PDF のインデクシングを PostTool でしてみて下さい。エラーとなるはずです。逆に solrconfig.xml から uprefix の行を削除して PDF をインデクシングしてみて下さい。これも同様にエラーとなるはずです。この場合は SolrCell が投げようとしたフィールドがないというエラーになるはずです。
managed-schema の ignored_ フィールドと solrconfig.xml の <str name="uprefix">ignored_</str> はセットで使うと,とても便利ということですね。
まとめ
主に PostTool の挙動について解説しました。PostTool にはもう少しだけ秘められた機能があるのですが,それについてはまた今度。
- PostTool は
Content-Typeによって挙動が変わる - PDF などのバイナリファイルをインデクシングする時は,
dynamicFieldでメタデータを確認するのが手っ取り早い - SolrCell が未定義フィールドに出力してきても
<str name="uprefix">ignored_</str>でエラー回避可能
ということでした。