はじめに
22年度文系学部卒のたいきです。この記事では、システムの開発経験もないのに、見よう見まねで「プロジェクトごっこ」をしていきます。
・保有資格 : 応用情報技術者・AWS-SAP
・プログラミング言語:軽くPython
本企画を最初から読んでいただける方は「開発未経験がクラウドを企業に導入するプロジェクトごっこをしてみた~その1~」から読んでいただける嬉しいです。
本記事について
本記事より、実際にシステム(アプリケーション)部分を作成していきます。この最初のステップとしてSageMakerを利用して、きのこの山とたけのこの里を、それぞれ判別できるモデルを作っていきます。
本記事のモデリングは、このプロジェクトのアイデアのもとになったBuilders.Flashさんの記事を参考に制作させていただきます。
たけのこの里が好きな G くんのために、きのこの山を分別する装置を作ってあげた。
~モデル作成編~
学習用データの用意
さっそく、きのこの山とたけのこの里を用意しました。一つ200円くらいしたので、ここでもインフレを痛感しました。。。しかし、ステルス値上げではなかったので、そこはうれしいです。笑

こんな感じで写真を撮って、学習用データを準備していきます。

ラベリング
SageMaker Ground Truthを利用してラベリングを行っていきます。ラベリングは、きのこの山とたけのこの里がどんなものかを、機械学習モデルに教え込むものです。本来であれば、画像上に座標の概念を持ってきて、数字で物体の位置をモデルに教え込むらしいです。しかし、さすがはAWSのサービス。SageMaker GroundTruthでは、そのラベリングが視覚的に行えます。
このような感じで、ドラッグだけで枠を作り、送信するだけで座標を入力してくれます。

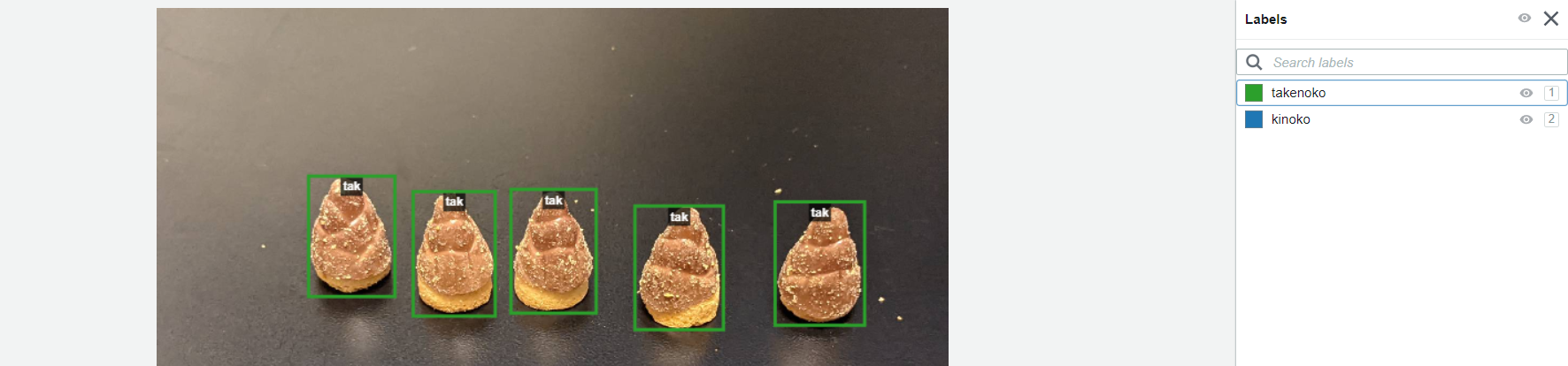
きのこと、たけのこでは枠の色を変え、違う種類の正解であるということを認識させます。たけのこはこんな感じです。
データオーグメンテーション
より精度の高いモデルを作成するために、データオーグメンテーションを行います。これは、学習用データを色々な手法で増やしていきます。画像であれば、その画像を反転させて違うデータとして扱い、これによって実質2倍の枚数の画像を学習に利用できたことになります。今回は記事の通り、ランダムクロップという手法を使います。
上記Builders.Flashさんの記事より引用
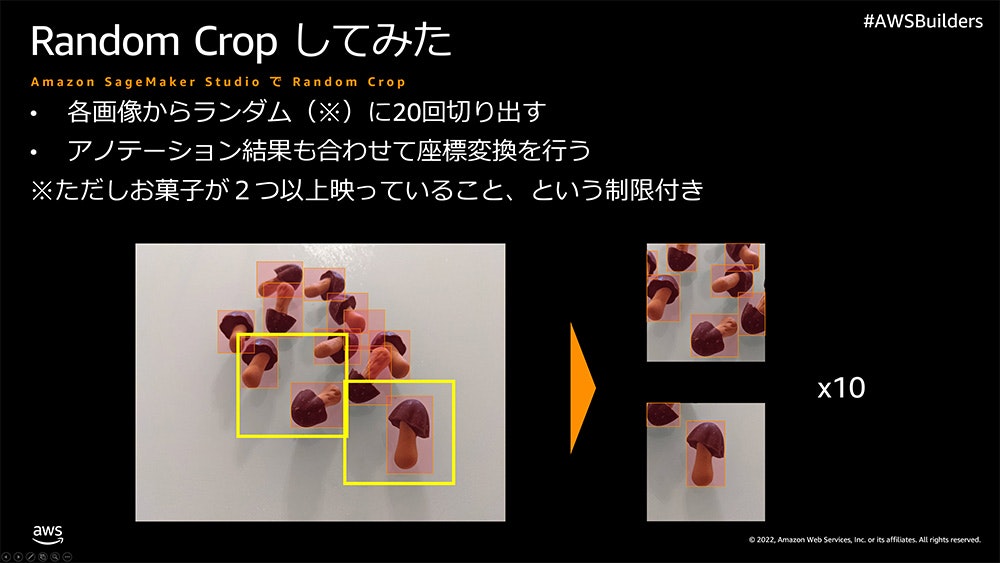
上記の説明画像のようにランダムに切り出し、切り出したものを学習用データとして再利用していきます。今回はこの処理により、23枚の写真が460枚に増幅されました。
SageMaker JumpStartでのFine-Tune(転移学習)
Fine-Tuneとは、もともと学習済みであるモデルに、そのタスクに特化するように微調整する機械学習の学習手法です。もともと、超優秀なモデルをきのこの山とたけのこの里を検知できるように、特化させるということです。
これには、SSD MobileNet1.0というニューラルネットワークをSageMaker JumpStartでFine-Tuneしていきます。
モデルは、このような感じで簡単な入力をするだけで転移学習を開始することができます。今回は、参考記事のとおりにml.g4dn.xlargeインスタンスを利用していきます。
しかし、このようなエラーが出てきました。どうやら学習する用のリソースのクオータが僕にはないようです。AWSにコンタクトをとれとのことですが、そこもやってみます。

見つけました。どうやらSagemakerでの当該インスタンスのデフォルトクオータは0のようです。そして、さらに調べたところml.m5.4xlargeインスタンスが25時間分無料枠で1クオータの制限付きで使えるようです。クオータ制限の引き上げを申請してもいいですが、AWSに問い合わせ時間がかかるそうなので、無料枠を利用していきます。
https://docs.aws.amazon.com/ja_jp/general/latest/gr/sagemaker.html
SageMakerエンドポイントとクオータ
クオータ制限を解除して使いたいという方はこちらより申請をしてみてください。
https://us-east-1.console.aws.amazon.com/support/home#/case/create
クオータ制限リクエストフォーム
実際に学習をしていきます。この学習は約39分ほど時間が必要なので、洗濯物やご飯の支度前などにおすすめです。
モデルのテスト
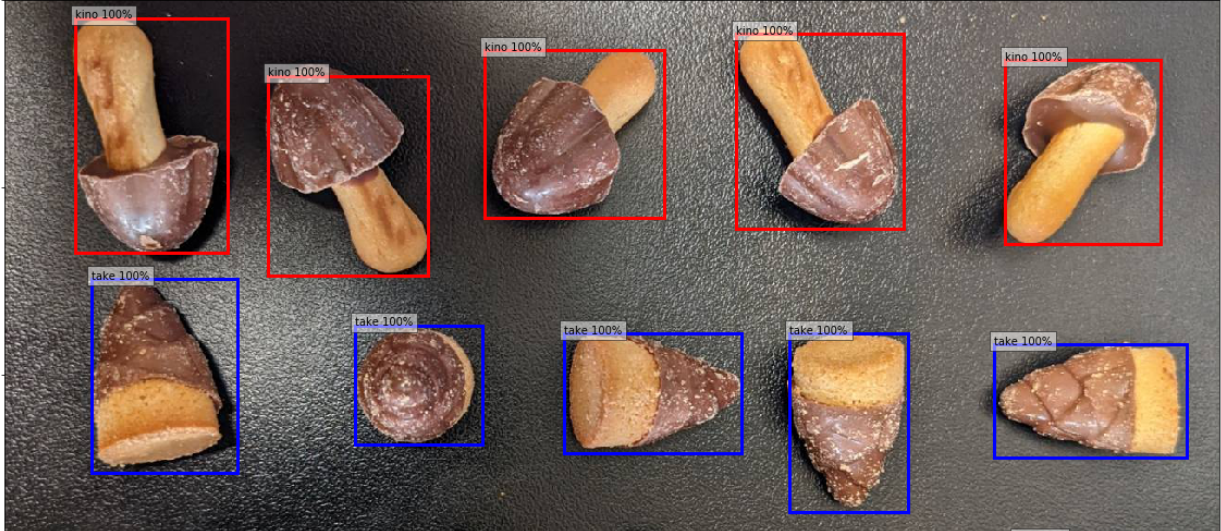
実際に、このモデルの精度はどの程度のものなのかをテストしていきます。このテスト方法は、非常に視覚的にわかりやすいように各オブジェクトを囲むように四角形を表示させます。加えて、そのオブジェクトの信頼度も表示させるようにします。このやりかたも、Builders.Flashさんを参考に実装したのでぜひそちらを参考にしてみてください。
このような感じに、非常に正確で短時間にしては非常に完成度の高いモデルが出来上がったと思います。データ収集からラベリングを合わせて1時間ほどでこの制度はなかなか恐るべしかもしれません。
推論結果の作成
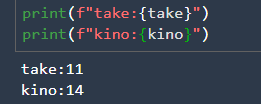
モデルが完成し、無事推論をすることができたので、きのことたけのこの各数量を計算し、DynamoDBに送信できるようにコードをリファクタリングしていきます。先ほどの、テストに用いたコードに加えて、このコードを挿入することできのこの山とたけのこの里の各数量を求めることができます。
take = 0
kino = 0
for idx in range(len(bboxes)):
# 信頼度スコアが 0.5 以上のみ
if confidences[idx]>0.5:
# 検出した座標(左上を(0,0),右下を(1,1)とした相対座標)を取得
left, bot, right, top = bboxes[idx]
# 相対座標を絶対座標に変換する
x, w = [val * image_np.shape[1] for val in [left, right - left]]
y, h = [val * image_np.shape[0] for val in [bot, top - bot]]
# 検出した物体によって、変数take,kinoへ加算する
if int(classes[idx])==0:
take += 1
else:
kino += 1
print(take)
print(kino)

上記の画像の推論結果がでて、無事にそれぞれの数量をカウントできていることがわかりました。
おわりに
builders.flashさんの記事のおかげで、順調にモデルを構築することができました。しかも楽しく!笑 Pythonでモデルを1から作成したこともありますが、全然段違いで楽でしたしわかりやすかったです。(いまは少しだけコードが読めるだけで書けませんが笑)。久しぶりにコードを少しだけ書いてみて、コーディングの楽しさを改めて実感できたいい経験でした!
続編はこちらです!【Lambda関数構築編】開発未経験がクラウドを企業に導入するプロジェクトごっこをしてみた~その6~