はじめに
22年度文系学部卒のたいきです。この記事では、システムの開発経験もないのに、見よう見まねで「プロジェクトごっこ」をしていきます。
・保有資格 : 応用情報技術者・AWS-SAP
・プログラミング言語:軽くPython
本記事を最初から読んでいただける方は「開発未経験がクラウドを企業に導入するプロジェクトごっこをしてみた~その1~」から読んでいただけると嬉しいです。
本記事について
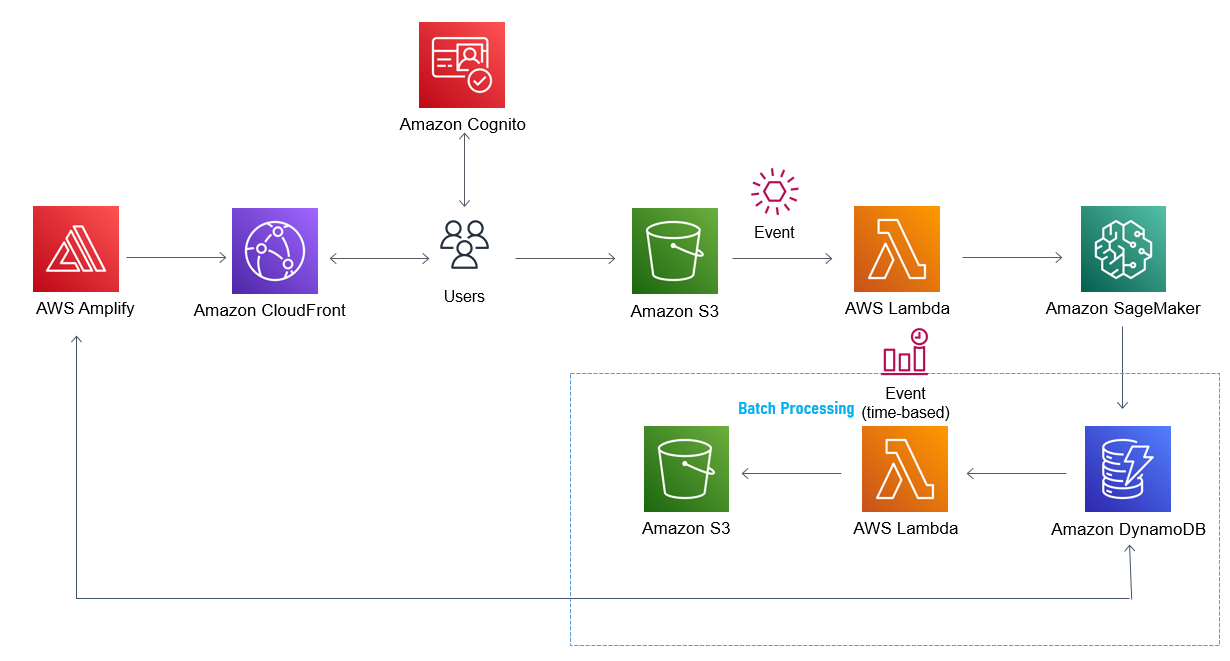
今回は、DynamoDBに格納されたきのこの山とたけのこの里の記録を、日ごとにクエリしCSVファイルに格納していきます。全体のアーキテクチャの「Batch Processing」の部分を実装していきます。
前回のコードのちょっとした修正
日次レポートを作るLambda関数を作る前に、S3イベントをもとに起動するLambda関数を修正していきます。以前のDynamoテーブルには、日次データを格納していなかったので、日次を記録できるようにしていきます。
ちょろっとしたコードを追加しただけなのですぐできました。(Typeエラーが一回出ましたが、、、)
【Lambda関数構築編】開発未経験がクラウドを企業に導入するプロジェクトごっこをしてみた~その6~
前回のコードはこちら↑
コードの実装
このような、非常に簡単なコードでDynamoDBからデータを取得することができました。今回はCloud9上で動かしました。ローカル環境でコードを実行する場合は、クレデンシャル情報と、リージョンの指定が必要です。
import boto3
from boto3.dynamodb.conditions import Key
dynamoDB = boto3.resource("dynamodb")
table = dynamoDB.Table("##your_table_name##") # DynamoDBのテーブル名
# DynamoDBへのquery処理実行
queryData = table.query(
KeyConditionExpression = Key("file_name").eq("6takes.jpg") , # 取得するKey情報
ScanIndexForward = False, # 昇順か降順か(デフォルトはTrue=昇順)
Limit = 1 # 取得するデータ件数
)
print(queryData)
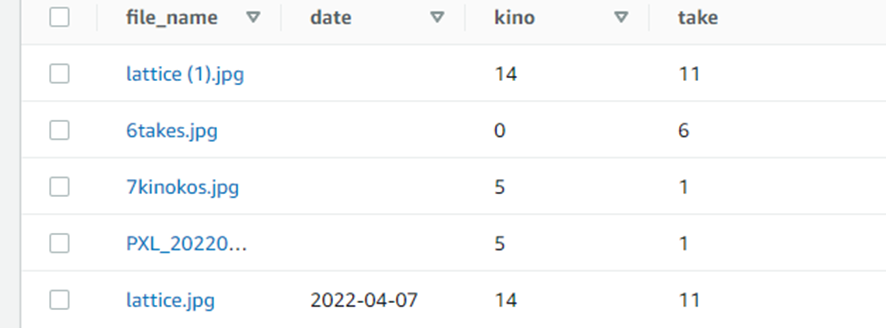
しかし、ちょっとした疑問です。この結果をどうやってきれいに扱うのか、、、また調べながらやっていきます。6takes.jpgのみを取得した結果です。
{'Items': [{'kino': Decimal('0'), 'date': '2022-04-07', 'take': Decimal('6'), 'file_name': '6takes.jpg'}], 'Count': 1, 'ScannedCount': 1, 'ResponseMetadata': {'RequestId': 'I9C7OQBRJD1ULGH8S5D7F72F7VVV4KQNSO5AEMVJF66Q9ASUAAJG', 'HTTPStatusCode': 200, 'HTTPHeaders': {'server': 'Server', 'date': 'Thu, 07 Apr 2022 03:00:18 GMT', 'content-type': 'application/x-amz-json-1.0', 'content-length': '131', 'connection': 'keep-alive', 'x-amzn-requestid': 'I9C7OQBRJD1ULGH8S5D7F72F7VVV4KQNSO5AEMVJF66Q9ASUAAJG', 'x-amz-crc32': '1034921939'}, 'RetryAttempts': 0}}
苦戦(クエリ編)
なぜか、一つのアイテムは取り出せたにも関わらず日次を指定しての複数のアイテムの取り出しができません。文法はあっているはずなのに、、、なぜでしょうか。調べに調べて数時間。答えがわかりました。どうやらDynamo DBテーブルにグローバルセカンダリインデックス(GLI)を設定しなければいけなかったようです。そうしなければパーティションキー以外で検索ができないようです。第二2のパーティションキーを作るような感覚??違ったらごめんなさい
GLIの名前はしっていたんですが、こういうことだったんですね、やっぱり手を動かすって大事です。でも、確かにそうですよね、すべての列で条件指定してクエリできてしまったらRDSでいいねすしね。
GLIを利用したクエリのコード
インデックス名を指定し、条件を指定することで、指定日のデータを取り出すことができました。コードをいかに置いときます。最後の二行は、取り出したデータをcsv化するためのものです。
import boto3
from boto3.dynamodb.conditions import Key
from boto3.dynamodb.conditions import Key, Attr
import pandas as pd
from datetime import datetime
from datetime import date
dynamoDB = boto3.resource("dynamodb")
table = dynamoDB.Table("kinotake_test_table") # DynamoDBのテーブル名
# DynamoDBへのquery処理実行
resp = table.query(
# Add the name of the index you want to use in your query.
IndexName="date-index",
KeyConditionExpression=Key('date').eq(str(date.today())),
ScanIndexForward = False
)
#csv化
df = pd.DataFrame(resp["Items"])
df.to_csv(str(date.today()) + "test.csv")
#S3へアップロード
client = boto3.client('s3')
Filename = str(date.today()) + "test.csv"
Bucket = 'kinotake-daily-record'
Key = str(date.today()) + "test.csv"
client.upload_file(Filename, Bucket,Key)
出力されたCSVファイルはこんな感じでした。なぜか、列の順番がごちゃごちゃになってますが、このままにしていきます。(頭がぼーっとしてきたので、、、笑)暇なとき、pandasで遊びがてらなおします。
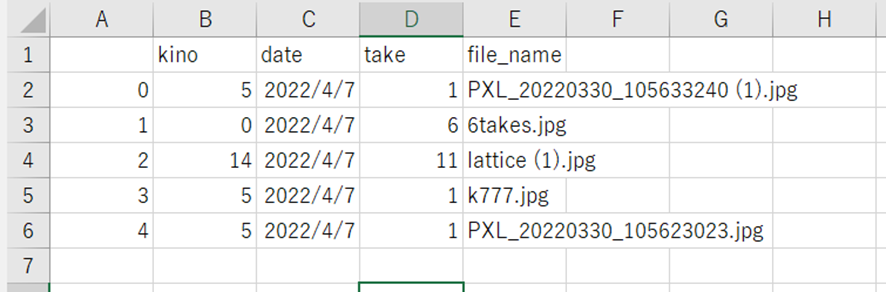
無事にCloud9上からは、アップロードすることができました。この後としては、Lambdaに実装してもしっかりと動くかどうかの確認をしていきます。最後に、time-basedのCloudWatch eventを設定していきます。
苦戦(Lambda上での実装編)
はい、さっそくエラーが発生しました。ノーエラーで順調にいくと期待した自分がバカでした。。。
Keyが定義される前にKeyが使われているということです。このKeyとはKeyConditionExpression=Key('date').eq(str(date.today())),のKey("date")の部分です。いや、でもこれ、、、「from boto3.dynamodb.conditions import Key」でインポートされたメソッドのはずなのに、、、なんででしょうか。。

では、解決していきましょう。この解決にも約3時間ほどかかりました、非常に厄介でした。この原因としては、コードの下の部分のS3へアップロードするときのKeyが優先されてクエリする際のKeyが認識されていなかったらしいです。(なんで、このライブラリを作った人はKeyなんてめちゃくちゃありそうな単語を使ったんですかね、、、)
なので以下のようにしました。
かっこよくないコードになってしまいましたが、わざわざどのライブラリのKeyなのかを宣言することで解決することができました。
'KeyConditionExpression': boto3.dynamodb.conditions.Key('date').eq("2022-04-07")
テスト成功までのエラーたち
はい、解決することができました。と書かせていただきましたが、あのエラーが解決しただけでまた新たなエラーがエラーが出現しました。毎度おなじみの権限エラーですね。これはすぐに解決して次に進めました。
errorMessage": "An error occurred (AccessDeniedException) when calling the Query operation: User: arn:aws:sts
次のエラーはこちら、またエラーメッセージが変わりましたねー。
このエラーはなんぞや、ということでエラーメッセージをコピペして検索してみました。そしたら、要するに規定の位置にファイルが保存されていないためLambdaがファイルを処理できなかったようです。これは、しっかりとtmpファイルを指定することで解決することができました。

これらのエラーを解決の後に無事に以下のようにLambdaの実行を成功させることができました。

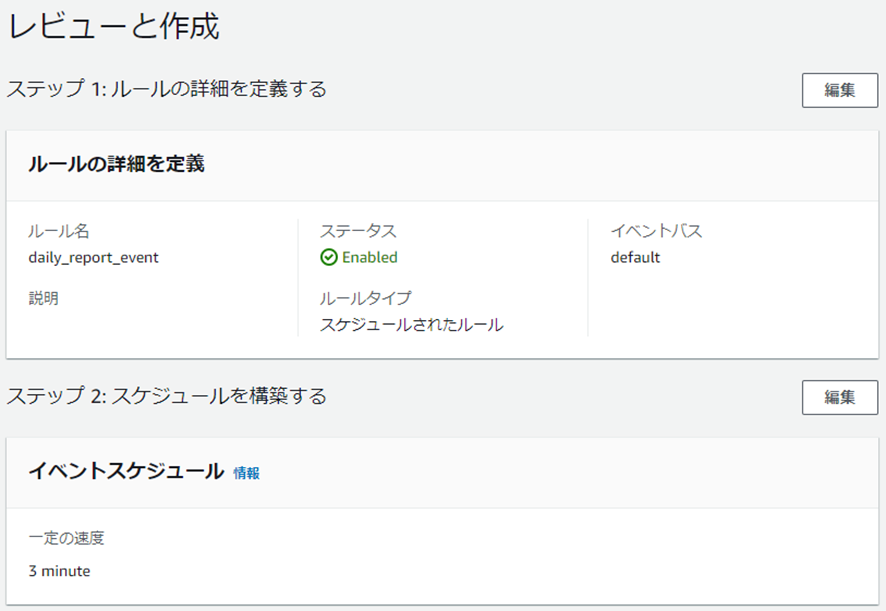
CloudWatch Eventの設定
CloudWatchの設定をしていきます。まずは、テストのために以下のように3分周期でイベントを発行するように設定していきます。
無事に、S3へファイルが格納されていることが確認できました。(3分よりも早かったような気がしますが・・・笑)
実装したコード
import boto3
from boto3.dynamodb.conditions import Key
from boto3.dynamodb.conditions import Attr
import pandas as pd
from datetime import datetime
from datetime import date
import os
def lambda_handler(event, context):
dynamoDB = boto3.resource("dynamodb")
table = dynamoDB.Table("kinotake_test_table") # DynamoDBのテーブル名
# DynamoDBへのquery処理実行
options = {
"IndexName" : "date-index",
'KeyConditionExpression': boto3.dynamodb.conditions.Key('date').eq("2022-04-07"),
}
resp = table.query(**options)
day = str(date.today())
tmp_path = '/tmp/' + day + "test.csv"
#csv化
df = pd.DataFrame(resp["Items"])
df.to_csv(tmp_path)
#S3へアップロード
client = boto3.client('s3')
Filename = tmp_path
Bucket = 'kinotake-daily-record'
Key = day + "test.csv"
client.upload_file(Filename, Bucket,Key)
おわりに
AWS-DOPの受験を考え始めましたので、もしかしたら更新頻度が大幅に落ちるかもしれませんがご容赦ください。
けど、本当に開発はたのしいですねーー。DOPを取得し、開発のベストプラクティスを学んだ後、みなさんに、数百倍高いクオリティを提供できたらとも、おもっています。