はじめに
先日、Kaggleの『MAP - Charting Student Math Misunderstandings』(通称 MAPコンペ)に参加し、7位チーム金メダルを獲得しました。
私達のチームのソリューションについては下記からご覧ください!
チームのソリューションの中でも、私は主に合成データの作成を担当しました。この記事では、「コンペのオリジナルデータと合成データの比較」を行います。
MAPコンペのオリジナルデータについて
MAPコンペのオリジナルデータはこちらから入手可能です。
生徒が多肢選択問題に取り組み、選択した回答と根拠となる説明文を提出します。この生徒の説明文に対して、誤解の種類がラベル付けされています。
ラベルのフォーマットは以下の通りです:
{True,False}_{Misconception,Correct,Neither}:{36種類のMisconception}
具体例としては、False_Misconception:Incomplete, True_Correct:NAなどです。
生徒が取り組む問題のIDも与えられます。その問題の種類が15件のみと限られており、trainにはそれぞれ数千レコード存在しています。
合成データについて
MAPコンペのデータは、train/Public LB/Private LBで独立同分布として共通していることが大きな特徴です。従って、合成データを用いてN数を増やすことが有力と考えられます。
自分が取り組んだ合成データ作成方法は以下の通りです。
- trainデータセットから、同一のラベル、および問題IDを持つ 5件以上存在するデータグループから、ランダムに3つのデータを抽出し、新しい「生徒の説明文」をLLM APIで生成するための参考として利用
- 3つの異なるエントリを使用することで、単一の例への過剰適合を回避

Nano Banana Pro による図解
上記はソリューションにも同様の内容を記載しています。
ソリューションには記載していないですが、事前検証として、AI Agentを用いた合成データの作成や小さなN数でのプロンプトの調整などを行いました。ある程度勘所を掴んだ後に、フローをまとめてN数を増やしました。
合成データによるスコアの変化について
gemma-2-9b-itを用いた合成データの影響に関するStratifiedKFoldの結果は以下の通りです。LBはOOFを平均して推論しています。
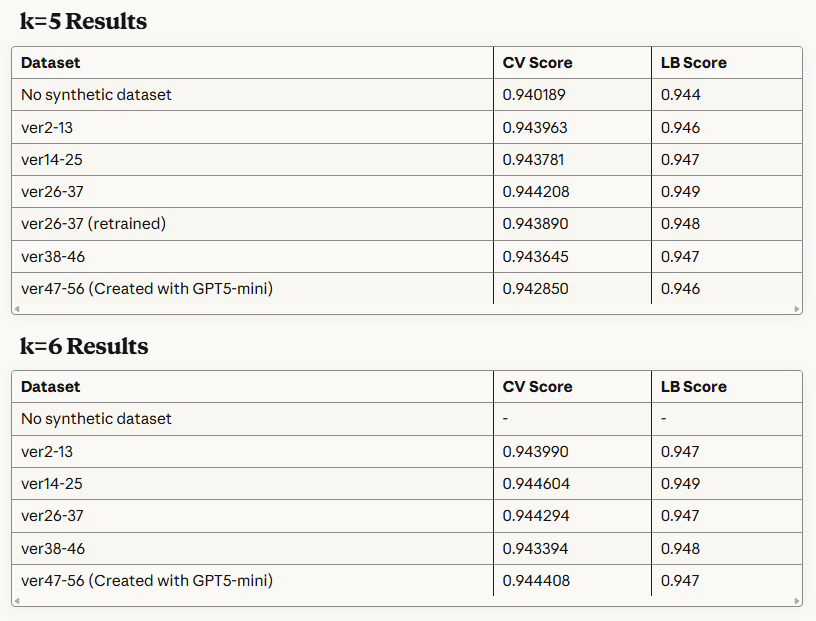
CVスコアは+0.003 ~ +0.004、LBスコアは+0.002 ~ +0.005と顕著なスコアの向上が確認できました。
しかしながら、こちらの合成データを用いたスコア向上は、モデルやパラメーターによってマチマチで、逆に悪化することさえありました。
原因ですが、①「生成した生徒の説明文」、②「ラベル付け」、以上2点に関してオリジナルデータと合成データで差異があるためと考えています。
その後、チームメイトが考案した擬似ラベルを付与する工夫により、②「ラベル付け」の差異については、緩和することができ、無事に最終ソリューションにおいてもスコアのブーストを達成することができました。メデタシメデタシ
①「生成した生徒の説明文」の差異については、目視では問題がないことをざっと確認していますが、コンペ期間中に深く調べることができませんでした。次の章で詳しく見ていきます。
「生成した生徒の説明文」をUMAPで可視化する
LLMの埋め込み表現をUMAPで2次元に投影することで、オリジナルデータと合成データの比較を行います。
埋め込み表現に使うLLMとしては、gemma-2-9b-it, deepseek-r1-distill-qwen-14b, Qwen2.5-Math-7B-Instructの3種類を用います。
データは、オリジナルデータ(青)と合成データ(赤)からそれぞれ4000件ランダムサンプリングし、合計8000件のデータを用います。
gemma-2-9b-itの可視化結果(Kaggleでの計算結果はこちら)
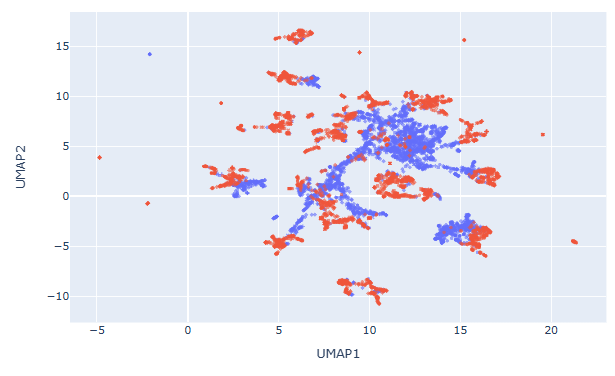
deepseek-r1-distill-qwen-14bの可視化結果(Kaggleでの計算結果はこちら)
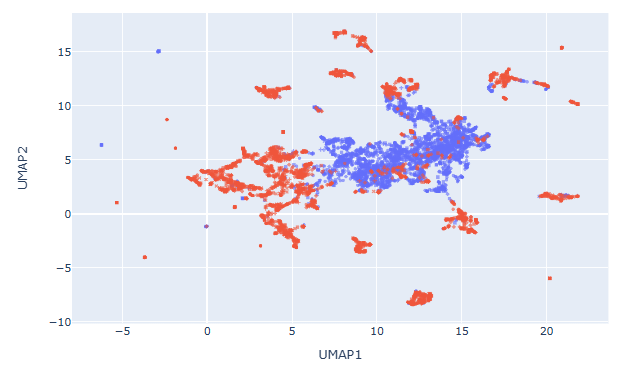
Qwen2.5-Math-7B-Instructの可視化結果(Kaggleでの計算結果はこちら)

gemma-2-9b-itの可視化結果については、ある程度は混ざり合っていることがわかります。しかしながら、完全に独立同分布には見えないことから、「生成した生徒の説明文」は完全にオリジナルデータと同程度のクオリティではなさそうです。
※計算量の関係で、サンプリング数を4000ずつとしましたが、全データを使用するともう少し混ざり合いが改善される可能性はあります。
deepseek-r1-distill-qwen-14bとQwen2.5-Math-7B-Instructの可視化結果については、相対的にgemma-2-9b-itよりも混ざり合いが低減されているように見えます。こういったことから、合成データの活用度はgemma-2-9b-itの方が高いのかもしれません。
逆にこれくらいの乖離があったとしても、擬似ラベルを付与することでスコア改善に繋がることに驚きました。
まとめ
- 本コンペでは、生徒の説明文に対する誤解ラベル分類において、LLMを用いた合成データが有効でした
-
gemma-2-9b-itで生成した合成データは、CV/LBともに +0.002〜+0.005 程度の安定した改善を示しました- 一方で、モデルや設定次第では合成データが逆効果となるケースも確認されました
- ラベル付与の揺らぎは、擬似ラベルにより緩和でき、最終的なスコア向上に貢献しました
- 一方で、モデルや設定次第では合成データが逆効果となるケースも確認されました
- 説明文そのものの品質差は、UMAPを用いた可視化によってモデル間の混ざり具合の違いとして現れました
-
gemma-2-9b-itはオリジナルと合成が比較的よく混ざり、独立同分布に近い結果でした -
deepseek-r1-distill-qwen-14bとQwen2.5-Math-7B-Instructは分布の乖離が大きく、合成データ活用度は相対的に低い可能性があります
-
本記事は以上となります。ご覧頂き、ありがとうございました。