
概要
インテルが新しく開発したオープンソースの「Polite Guard」は、テキストの分類を目的とした自然言語処理 (NLP) モデルです。BERT をベースにファインチューニングしたこのモデルは、テキストを polite (丁寧)、somewhat polite (やや丁寧)、neutral (中立)、impolite (失礼) の 4 レベルに分類します。モデルのほかに、Hugging Face ではトレーニングに使用されたデータセットが、GitHub ではソースコードが公開されています。
メリット
- 拡張性の高いモデル開発パイプライン: 独自の合成データを簡単に生成、モデルのファインチューニングをスムーズに実行。
- 安定性の向上: 悪意ある攻撃に対抗する防御メカニズムを備え、システムの耐障害性を強化。
- ベンチマークと評価: ポライトネス分類 (礼儀正しさのレベル) の観点からモデルのパフォーマンスを評価、比較。
- 顧客体験の向上: 多様なプラットフォームにわたり敬意を込めた丁寧なやり取りを徹底することで、顧客の満足度とロイヤリティーを向上。
合成データの生成とファインチューニングのプロセス
Python で作成した合成データ生成モデルをインテル® Xeon® プロセッサーに実装し、顧客サービスの詳細なやり取りをラベル付きサンプルとして出力しました。サンプルには、金融、旅行、食品、小売、スポーツ、文化、人材育成など、さまざまな分野でのやり取りが含まれます。次に、このデータセットを用いてベースとなる BERT モデルをファインチューニングしました。
データが偏らないようにラベルとカテゴリーをランダムに選択し、指定したカテゴリーとラベルに紐づく合成データの生成を言語モデルに指示しています。生成プロセスでは、多角的な視点を考慮して多様なプロンプトを用意し、3 つの大規模言語モデル (Llama 3.1-8B-Instruct、Mixtral 8x7B-Instruct-v0.1、Gemma 2-9B-It) を使用しました。
次に、Optuna で Tree-structured Parzen Estimator (TPE) アルゴリズムを使用して、学習率と重みの減衰についてハイパーパラメーターのチューニングを行っています。これは評価指標の F1 スコアを最大化するためです。また、Optuna のプルーニング機能を使って、性能の低いハイパーパラメーターの試行を早期に停止しています。ハイパーパラメーターの検索スペースと、パフォーマンスの高かったパラメーターについては、Hugging Face で公開しているモデルカードを参照してください。
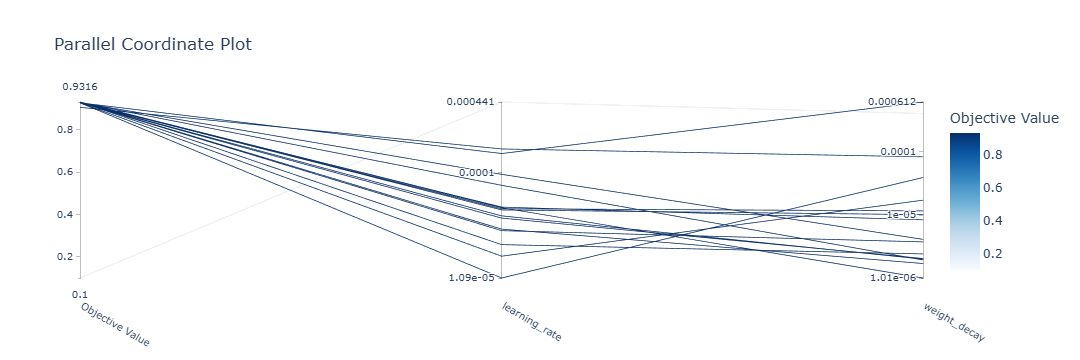
図 1. ハイパーパラメーター最適化中の、ハイパーパラメーター (学習率と重みの減衰) とモデルの F1 スコア (目標値) の関係を視覚化した平行座標プロット。各線が試行 1 回を表し、ハイパーパラメーターの組み合わせを変えることでパフォーマンスにどのような影響があるかを示している。
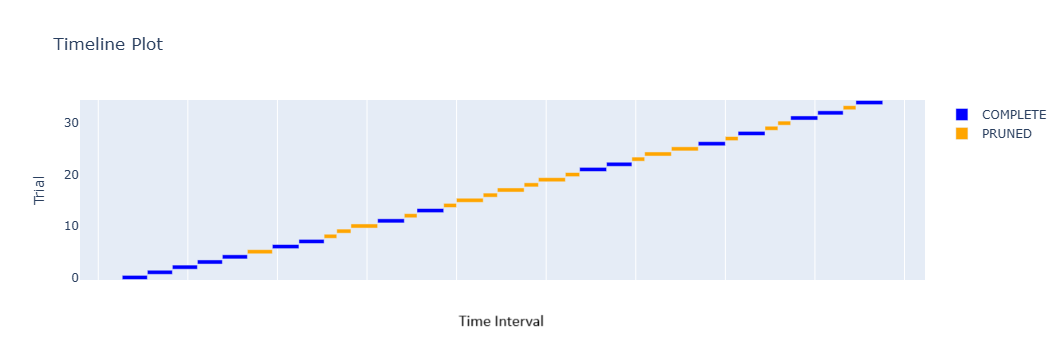
図 2. Optuna による試行 (0~34) の経過を時間軸に沿って示したタイムライン・プロット。完了した試行と打ち切られた試行が色分けされている。
アクセスと利用方法
-
データセット: Hugging Face にある Polite Guard データセットは、次の 3 つのコンポーネントで構成されています。
- Few-Shot プロンプトで生成した 50,000 件のラベル付きサンプル。
- Chain-of-Thought (CoT) プロンプトで生成した 50,000 件のラベル付きサンプル。
- 個人情報をマスクした企業研修用の 200 件の注釈付きサンプル。
合成データは均等になるように、トレーニング用 (80%)、検証用 (10%)、テスト用 (10%) の各セットに、ラベルごとに分割されています。Polite Guard はこの合成データのみでトレーニングが行われましたが、合成データと実際の注釈付きデータを組み合わせて評価し、92.4% の精度と F1 スコアを達成しました。
- ソースコード: 合成データ生成機能と、インテル® Gaudi® AI アクセラレーターなどを活用したファインチューニング機能のソースコードは Polite Guard の GitHub リポジトリーで公開しています。
- 実行: リポジトリーのクローンを作成して、コードを任意のクラウドサービスで実行してください。
次のステップ
Polite Guard を利用すれば、さらに安定性の高い、丁寧な言葉づかいの顧客サービス用 NLP アプリケーションを構築できます。このオープンソース・プロジェクトに協力して、進化を続ける生成 AI をぜひ活用してください。
また、ここで紹介した以外にも、インテルの AI/ML フレームワーク最適化やツールを AI ワークフローに取り入れ、統一されたオープンな標準ベースの oneAPI プログラミング・モデルについて学ぶこともお勧めします。これはインテル® AI ソフトウェア・ポートフォリオの基盤を成すものです。
参照リンク
元記事
著者: Ramya Ravi、Ehssan Khan
所属: インテル
公開日: 2025年2月10日