この記事は Mariano Tepper と Ted Willke が執筆を担当した、インテルラボで両名が取り組む研究の一部です。
概要
ベクトル検索は、AI 革命の中心にあり、アプリケーションが意味的に関連性の高い非構造化データへアクセスできるようにするテクノロジーです。インテル® スケーラブル・ベクトル・サーチ (インテル® SVS) は、数十億規模の類似度検索を実行するパフォーマンス・ライブラリーとして、高効率の演算最適化に加え、ベクトル圧縮と次元数削減の手法が用いられています。
演算処理を最適化することでメモリーへの負荷は再び高まりますが、新たなベクトル圧縮と次元数削減の手法によって、フェッチするデータ量が減るため、さらなる高速化が可能になります。このページでは、検索パフォーマンスとメモリー・フットプリントの観点で、インテル® SVS がどのように最先端を確立しているかを解説します。シリーズの今後の記事では、ベクトル圧縮、次元数削減、RAG システムについてさらに深く掘り下げていく予定です。
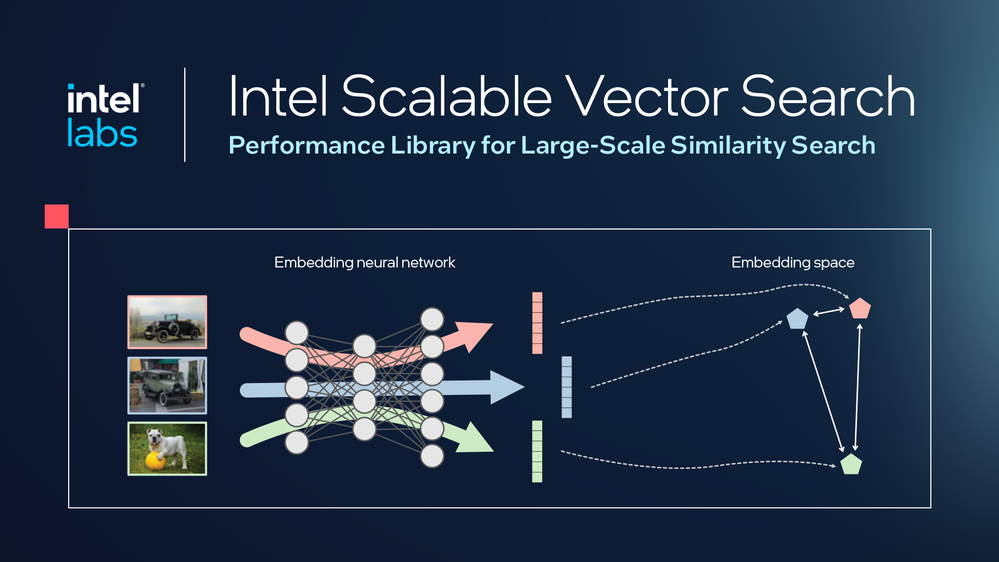
ここ数年の間に、高次元ベクトルは、画像や音声、動画、テキスト、ゲノム情報、プログラミング・コードといった非構造化データを表現する、典型的なデータ形式となりました。このベクトルは「埋め込み」とも呼ばれ、類似度関数に従って、意味的に関連性の高いベクトルが近い位置に配置されるように生成されます。
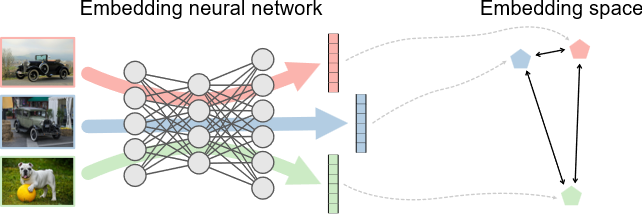
数十億ものベクトルの中から、1 クエリーに対して最も類似度の高いベクトルを見つけ出すのは、ベクトル検索 (あるいは類似度検索) の普遍的な課題です。この技術は、画像生成、自然言語処理、質問応答、レコメンデーション・システム、広告マッチングなど、さまざまなアプリケーションに関連し、その範囲はますます広がっています。
RAG の「R」
この数年で検索拡張生成 (RAG) モデルの利用は急速に拡大し、長期記憶 (例: チャット・エージェントが長い会話の中で過去のやり取りを記憶) 、知識のモジュール化 (例: ユーザーの認証情報に応じて応答内容を変える) 、トレーニング後の適応 (例: モデルを再トレーニングすることなく新しい知識を追加) といった能力を生成 AI システムにもたらしました。
また、既存の知識に基づきモデル出力の根拠を示すことで、ハルシネーションを軽減する効果もあります。RAG では、推論よりも前に検索ステップが入り、通常はここにベクトル検索が使われます。プロンプトの目的は、モデルに提示する類似要素の検索です。その後でモデルにはベクトルを使用するように指示が出され、プロンプトを検討して出力を生成します。
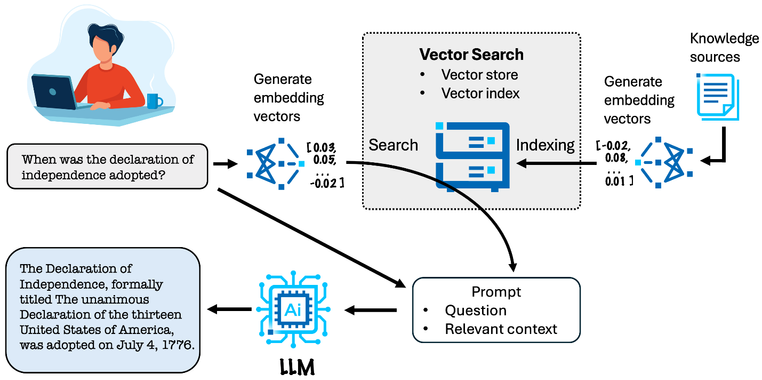
RAG は AI を取り巻く環境を急速に変えつつあり、RAG への需要の高まりが大規模システムの導入を加速しているものの、このようなシステムの所有と運用には本質的に膨大なコストは避けられません。この分野で製品やサービスの提供に注力している企業にとって、ハードウェア / ソフトウェア・システムの運用コストの削減は、事業を存続していくうえで非常に重要な優先事項です。ベクトル検索はこのようなシステムのパフォーマンスとコストの両面で重要な役割を果たします。
RAG の実稼働前の小規模実装において、ベクトル検索にかかる時間は LLM 推論と比較して高速ですが、この点はよく見過ごされてきました。ただし、実装を拡大した巨大なベクトル集合でトラフィックを処理する実稼働環境では、ベクトル検索がボトルネックとなることも考えられ、例えば (数十億規模の) 大規模ベクトル集合に大量のユーザーから同時に検索する必要があると、レイテンシーが桁違いに増大する可能性があります。
メモリー容量が限られていると分かっていても、パフォーマンス向上のために高価な GPU に頼りたくなる誘惑もありますが、手に負えないほどコストが増えるわりには、それほどのパフォーマンス向上は期待できません。
インテルラボの研究から、最新のデータセンター向け CPU は、十分な速度 (レイテンシーとスループット) を維持しながら、ベクトル検索を本稼働に申し分ないレベルで実行できることが明らかになっています。そのため、メモリーとストレージの節約によって、システムのコストの削減が可能になります。
ベクトル検索の概要
数千次元の大規模なデータセットはますます一般的になってきており、例えば最新の埋め込み大規模言語モデルは 768 ~ 1,536 次元のベクトルを生成し、4,096 次元にも及ぶモデルもあります。十億もの高次元ベクトルからなるデータセットに線形スキャン (全件走査) を実行して最近傍を見つける「厳密な最近傍探索」は時間がかかりすぎて、アプリケーション要件を満たせません。
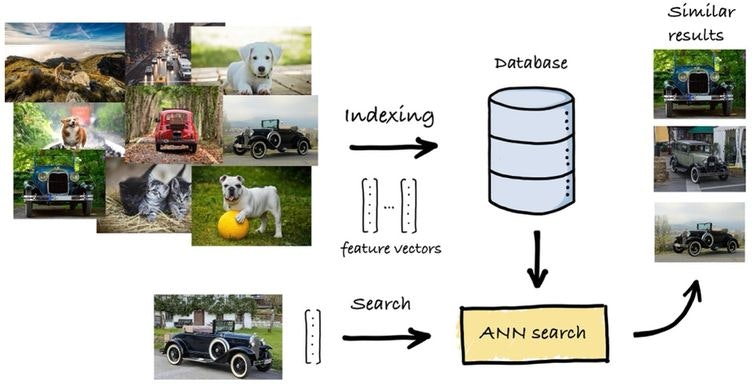
返される最近傍に一部のベクトルが誤って検索されるわずかな誤差が発生する可能性を許容するのであれば、全件スキャンを回避できます。これは近似最近傍検索と呼ばれ、この諸刃の問題に対する二重の解決策となります。
- ベクトル・インデックス: ベクトルを整理するためのデータ構造。1 回の検索でデータセット全体の一部だけにアクセスするため、メモリーアクセスを低減。
- ベクトル表現: 各ベクトルを圧縮するための、データのエンコード形式。検索の高速化、メモリー占有量の縮小、演算カーネルの効率維持が可能。
ベクトル・インデックス: ベクトルを整理して検索を高速化する方法
ベクトル・インデックスのアプローチを選択する際には、さまざまなトレードオフを考慮する必要があります。考慮すべき重要な項目を以下のように図で示して解説しました。コスト効率と性能を両立させるシステム設計の最終的な目標は、トレードオフとアプリケーションの目的とを照らし合わせて、それぞれの側面を最大化することにあります。
例えば、ビジネス向けのコストモデルでは、多少の精度は犠牲にしてでも、メモリー・フットプリントの縮小が優先されるかもしれません。あるいは、LLM アプリケーションの場合、追加のインデックス作成に時間がかかるとしても、ベクトル検索の高速化を優先することもあるでしょう。これらの側面すべてでバランスを取る最大の要素の 1 つは、インデックス作成アルゴリズムの選択です。
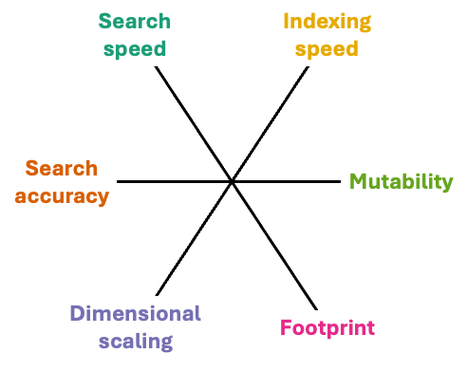
検索速度: 理想を言えば、データベースのサイズが大きくなるペースよりも検索時間の方がだいぶ緩やかにスローダウンするべき。数百万 ~ 数十億のベクトルを処理する場合には特に重要。インデックス構造によって、ユーザーの待ち時間を抑えるための低レイテンシー (検索完了までの時間) と、同時に多くのユーザーにサービスを提供できる高スループット (1 秒当たりのクエリー数) を実現する必要があります。
検索精度: 与えられたクエリーに対して類似するベクトルを正確に検索して返すことが不可欠。関連性の高い商品をおすすめするレコメンデーション・システムや、検索の類似度が全体的なパフォーマンスに直結する RAG においては極めて重要。
インデックス化の速度: 検索を高速化するには、規則に沿ったデータの整理が必要。ドキュメントを日付順にインデックス化するような全順序集合の単純なインデックス化とは対照的に、多次元ベクトルのインデックス化は難しく、時間がかかります。
次元スケーリング: 次元数が増えると「次元の呪い」が発生し、検索空間での迅速な絞り込みは困難。この現象に対抗できるインデックス作成は、データベース・サイズの拡張と同様に重要。
可変性: 多くの場合、データベースの内容は時間とともに変化し、ベクトルが追加 / 削除 / 更新されるたびにインデックス全体を最初から再構築するには膨大な時間がかかるため、最新のインデックス構造はインプレース更新に対応。つまり可変性を備えているということです。さらに、データの分布も時間とともに変化するため、インデックス構造はそのような変化にもシームレスに適応する必要があります。
フットプリント: データベースの次元数とベクトル数が増えるとともにインデックス作成は複雑になり、インデックスを支えるデータ構造のサイズも増大。現在、ベクトル検索を提供する HW システムにおいて、主なコスト要因はメモリーとストレージ。
近似最近傍検索のアルゴリズムには、いくつかのカテゴリーが存在します。最初に出てきたソリューションはツリー構造で、1 次元オブジェクトのインデックス化に最適でした。しかし、これらの拡張版は「次元の呪い」を受けやすく、次元数が増えるにつれてパフォーマンスが低下します。次の世代のソリューションは反転インデックス (IVF) から派生し、データベースのサブセットのみを検索対象に絞るクラスタリングが用いられるようになりました。それほど精度が重視されない検索では高速ですが、高い精度を求めるようになると、パフォーマンスは急速に低下します。
また、時間とともにデータベースの内容が変化 (ベクトルの追加、削除、更新) する動的な設定には適応しにくいという課題もあります。現在の最先端は、グラフベースの手法です。高速でありながら精度も高く、次元スケーリングへの耐性もあり、動的な設定にも適応しやすいという特長があります。
グラフベースの手法では、インデックスは有向グラフで構成され、各頂点がデータベースのベクトル 1 つに対応し、辺の疎な集合がベクトル間の近傍関係を表します。これらの近傍関係は、グラフ全体を効率的に走査して準線形時間で最近傍を見つけられるように、貪欲な最良優先アルゴリズムを用いて構築されており、各ステップでクエリーに最も類似する近傍へと移動していきます。バックトラッキングによって、1 回の検索で複数の近傍を返すことも可能です。
ベクトル表現
ベクトルの構造化によって検索を効率化するのと同じくらい重要なのが、ベクトルをどのように生成して表現するかです。 大規模なベクトル検索に関する研究文献では、距離計算の回数を減らすことを目標に、このようなワークロードにおける演算負荷の高さに焦点が当てられています。しかし実際のところ、このワークロードの中心にあるのはベクトル類似度を求めるベクトルのドット積のようなシンプルなカーネル演算であり、これはインテル® AVX-512 のような最新のベクトル命令セットを使用すれば効率的な処理が可能です。したがって、本質的な課題は、メインメモリーまたはストレージからベクトルをいかに効率的にフェッチできるかにあります。
加えて、ベクトルが占有するメモリー・フットプリントも、急速に問題になりつつあり、例えば 1 億個のベクトルをそれぞれ 1,536 次元、単精度浮動小数点フォーマットで保存する場合、572GB のメモリー容量が必要です。1 台のマシンに搭載されているメモリー容量で、このベクトルの数とサイズをホストするのは不可能な場合もあります。
この課題への対応策として、多くのソリューションがベクトルの本質的な特性を保持しながらベクトルを小さくする方法に注力してきました。ここでもやはり、問題のどの側面を優先するかによって、考慮すべき重点項目の間にさまざまなトレードオフが存在します。例えば、セマンティクス的類似性の解像度を多少犠牲にしてでも、ベクトルの圧縮率を高めてメモリーを節約する方を優先する選択肢もあるでしょう。以下の図では、考慮すべき項目とその相互作用について解説します。
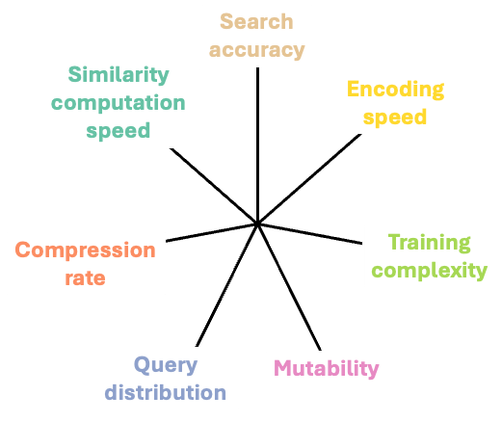
類似度計算の速度: 検索が不必要に遅くならないよう、類似度計算をシンプルかつ高速に維持。
圧縮率: 節約できるメモリー量の指標。極めて単純なシナリオを例に考えると、ベクトルのエントリーを単精度 (FP32) から半精度 (FP16) の浮動小数点値に圧縮すれば、圧縮率は 2 倍。
検索精度: 現在、ほとんどのユースケースで高い精度レベルが必須要件。要求されるレベルの精度に達しながら、メモリーとメモリー帯域幅を節約できるのが理想ではあるものの、この高い精度レベルと圧縮率の両立は、検索における未解決の課題。
トレーニングの複雑さ: マシンラーニングのようなデータ駆動型の圧縮手法を用いる場合、モデルには相対的に高速の学習処理が必要。ベクトル圧縮のためにディープ・ニューラル・ネットワークを使うとトレーニングに時間がかかりすぎる。
可変性: 圧縮手法はベクトル集合の分布変化に対して適応力が必要。部分的にでも変化に応じたモデルの再トレーニングが必要になっても、迅速に適応できるインデックスの可変性が重要 (前のセクションを参照)。
**エンコード速度: データベースに新しく追加されるベクトルには、最適な圧縮手法でのエンコードが必要。エンコードの演算負荷が高すぎると、インデックスの可変性 (前のセクションを参照) は損なわれ、例えばディープ・ニューラル・ネットワークによるベクトル圧縮も検討されてはいるものの、モデルの推論処理に時間がかかるため、実用は限定的。
**クエリー分布: クエリー側ベクトルの特徴がデータベース側ベクトルと異なる場合でも、検索精度の維持が必要。この課題については、本シリーズの今後の記事で解説する予定です。
ベクトルの大半は、(1) スカラー量子化、(2) ベクトル量子化、(3) 次元数削減の 3 タイプの手法で表現が変換され、これらを組み合わせて相乗効果を得る複合的なソリューションもますます増えています。今後の記事では、こうした多様なソリューションと、インテルラボでの研究成果として紹介されてきたイノベーションについて深く掘り下げる予定です。
インテルのベクトル検索
ここまで説明してきたように、十億規模の類似度検索システムの多くは、ベクトル化された距離計算性能を最大限に引き出してメモリーを節約できるだけの、ハイパフォーマンスな演算処理を実現する基本的な仕組みが十分とは言えません。このような課題に対処するため、インテル® スケーラブル・ベクトル・サーチ (インテル® SVS) は開発されました。インテル® SVS は、高度に最適化されたベクトル・インデックスの実装と、ベクトル圧縮の新しい手法によって、これまでの限界に挑むソリューションです。インテル® SVS のベクトル類似度検索には、以下のような特長があります。
- 数十億規模の高次元ベクトルに対応
- 高い検索精度
- 最先端の検索速度
- ほかのソリューションよりも少ないメモリー消費
こうした特長により、アプリケーションやフレームワークの開発現場では、第 2 世代以降のインテル® Xeon® プロセッサーで運用する類似度検索の性能を最大限に引き出せるようになります。インテル® SVS では、ほとんどの標準ライブラリーと互換性のある、シンプルでありながら豊富な機能を備えた Python API を活用可能です。また、C++ で記述されているため、パフォーマンス重視のアプリケーションへもスムーズに統合できます。以下の動画でインテル® SVS のデモをご覧ください。
シリーズの今後の記事では、ベクトル圧縮、次元数削減、RAG システムについてさらに深く掘り下げていく予定です。ぜひインテル® SVS をお試しください。スマートなインデックス作成と表現の選択肢にご満足いただけるはずです。
元記事
筆者:Scott_Bair
所属:インテル
投稿日:2025年2月4日