こちらの記事の続きになります
麻雀と情報工学基礎レベル(エントロピッピがわかるレベル)で噛み砕いているので、分かりづらかったらごめんなさい
4. オフライン評価
2章と3章で紹介したうち、オフライン上での学習の有効性を報告する。
4.1 教師あり学習
Suphxでは5つのモデル(捨て牌・ポン・カン・チー・リーチモデル)を別々に教師あり学習で学習した。学習データには牌譜より入力を「対局中の状態」、出力を各種「行動」として行う。例えば捨て牌モデルなら入力は「場から観測できる牌の情報」で、出力はプレイヤーが切る牌にあたる。
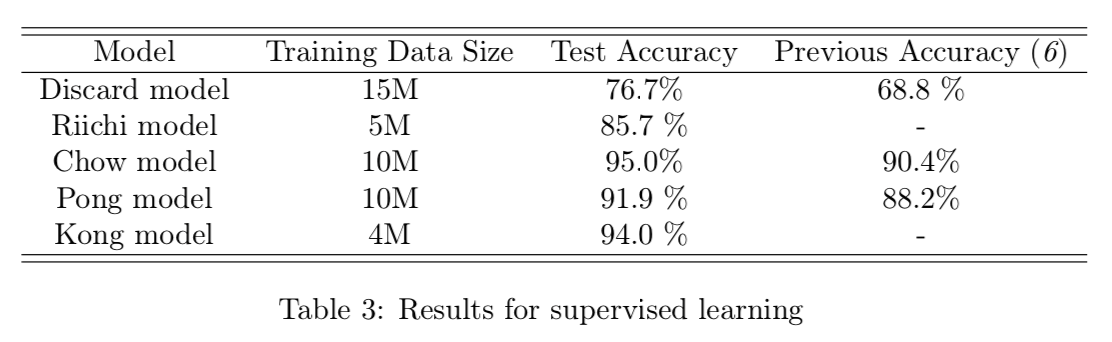
学習時のデータ量とテスト時の精度を表3に示す。検証用とテスト用データのサイズはそれぞれ1万と5万である。捨て牌モデルは34種の分類問題を取り扱うために、他のモデルと比較して多くのデータで学習した。結果は捨て牌モデルで76.7%、リーチモデルは85.7%、チーモデルは95%、ポンモデルは91.9%となった。
4.2 強化学習
Suphxの学習において強化学習の価値を検証するために、いくつか種類の異なる条件のエージェントを学習させた。
- 教師あり学習エージェント
- このエージェントは、4.1で説明された教師あり学習で学習されたモデル
- 教師あり学習エージェント(学習不足版)
- ↑のモデルの学習不足モデル。他のエージェントを評価するために使用するモデル。
- 強化学習エージェント
- このエージェントでは、捨て牌モデルで初期化したあと、点棒状況を報酬として、エントロピー正則化を実施して方策勾配法で最適化したもの。その他の4つのモデルについては教師あり学習エージェントと同じ。
- 強化学習エージェント(1)
- 強化学習エージェントをGlobal reward predictionで強化したエージェント。点数予測モデルは牌譜を元に学習されたもの。
- 強化学習エージェント(2)
- 強化学習エージェント(1)にOracle guidingを加えたもの。なお3つ強化学習エージェントは捨て牌モデルに対してのみ学習する。
初期配牌はランダム性が強く、ゲームの勝敗を左右するため配牌のばらつきを抑えるために、オフライン評価の際には100万ゲームをランダムに生成。各エージェントはこれらのゲームで学習不足版と対戦させる。この設定では1つのエージェントの学習に20個のTesla K80 GPUを2日使用した。また天鳳の段位に基づいてエージェントの安定段位を計算した。また安定段位の分散を減らすために、生成した100万ゲームの内80万ゲームをランダムに1000回サンプリングしている。
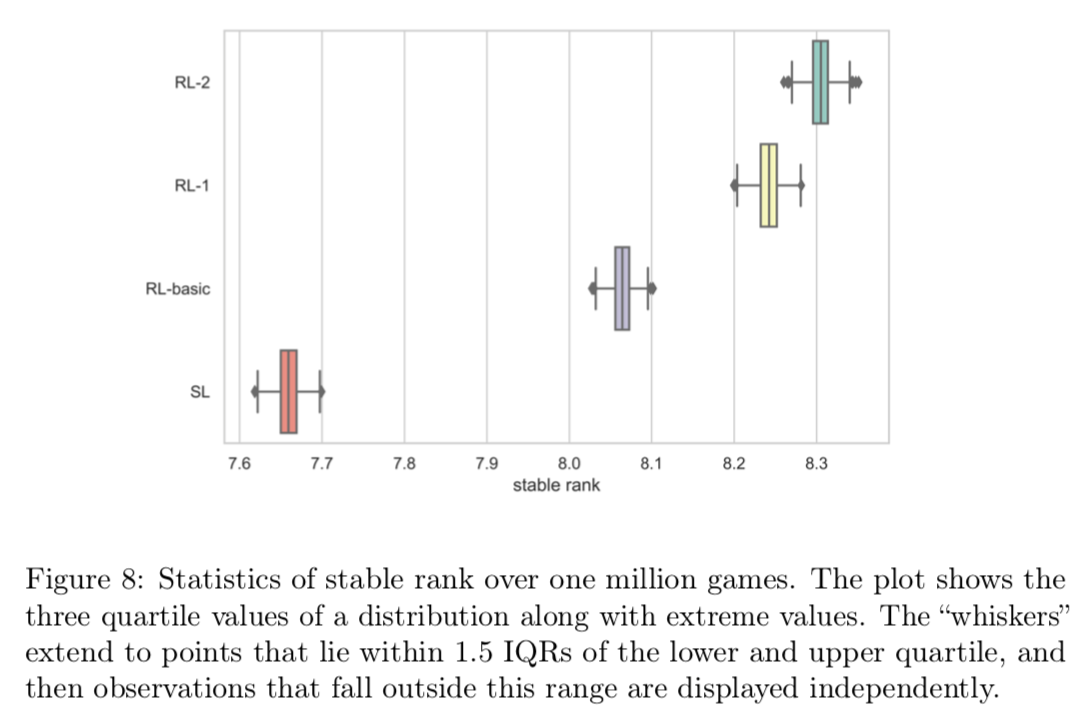
図8は安定段位の箱ひげ図を示している。公平に比較するために各エージェントは150万回のゲームを使って学習されたことに注意する必要がある。各エージェントの学習には、44個のGPU(パラメータサーバーのために4このTitan XP、自己学習用に40個のTesla K80)を使って2日かかった。
結果として強化学習は教師あり学習に比べて改善サれていることがわかる。さらに強化学習エージェントは提案手法を組み込むことでそれぞれのアルゴリズムが学習に寄与していることを明確に表している。(教師あり学習で7.65段前後、強化学習エージェント(2)だと8.3段)

Global reward predictionによって、ゲームの報酬を各局に分配することで、エージェントは局ごとのスコアではなく、最終的なゲームの報酬を最大化することができる。図9では南家の我々のエージェントが、オーラス時点で大きくリードしており、手牌もとてもよいが、この局に勝つよりも他家に振り込んでしまうリスクのほうが大きいため、保守的にプレイしている。通常の強化学習エージェントの場合は対局の勝ちを目指すため赤枠の六萬を捨ててしまうが、Global reward predictionをもったエージェントは青枠の六筒を選び安牌を切り続ける。
4.3 parametric Monte-Carlo Policy Adaption の評価
強化学習の評価に加えて、ランタイムポリシーの評価も実施した。実施時の設定を以下に示す。
- データの生成
- エージェントの手牌を固定して、10万回のゲームをシミュレートする。シミュレート中は他家の手牌と山がランダムに生成されて、局が終了するまで展開される。
- ポリシーの適用
- 方策勾配法を使用して、10万回のシミュレーションを使いポリシーを微調整する
- 適用されたポリシーのテスト
- 更新されたポリシーを用いて手牌を固定したまま、さらに10万回のシミュレーションを実施する。これによってポリシー適用有無での改善状況を確認する。
ランタイムでのポリシー適用は、シミュレーションとオンライン学習によって時間がかかる点に注意する必要がある。そのため現時点では数100回程度でしか実施していない。しかしその結果は強化学習エージェント(2)に対する勝率は66%となりポリシー適用の優位性を示している。

ポリシー適用は特に最終局近い状況においてよく機能する。図10ではオーラスタイミングで4着の状況だが3着にあがるためには、より多くの点数を必要とする。アガリを最優先すれば西を切るが、打点を意識してラス回避を考えるなら六萬を切って混一色を目指すだろう。
5. オンライン評価
Suphxの実際の評価をするために天鳳で実際に打ってもらった。天鳳には特上卓(四段R1800以上)と鳳凰卓(七段R2000以上)に分かれているが、天鳳運営ルールに則りAIは特上卓での対局しか認められていないため、特上卓にて5000局以上の対局を実施した。
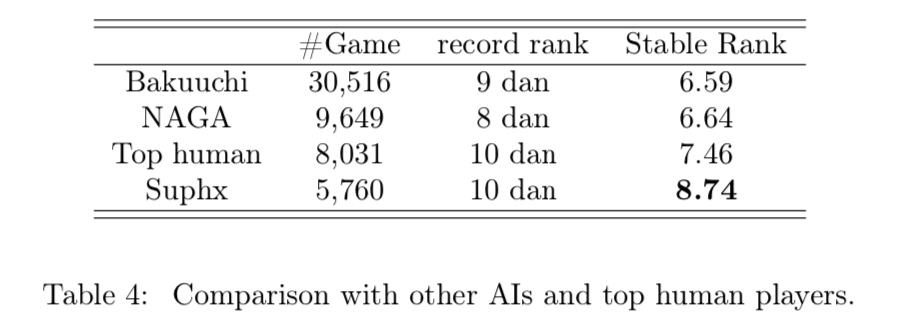
表4よりSuphxは過去に発表された麻雀AIであるNAGA(ドワンゴメディアヴィレッジの開発の麻雀AI。学習は教師あり学習のみ)やBakuuchi(東京大学開発の麻雀AI。学習は教師あり学習のみ。)よりも二段ほど優れていることがわかる。天鳳のトッププレイヤーである十段を持つユーザーであっても安定段位が低いことが多く、その点Suphxは安定段位が他と比べて高い。
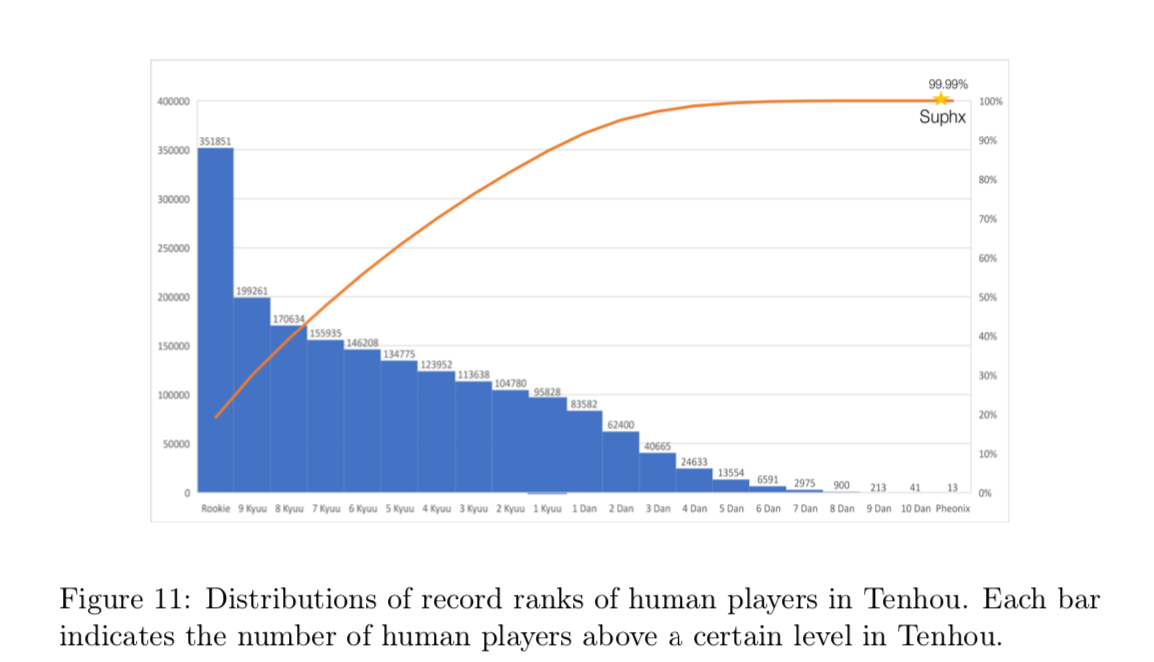
また図11では天鳳のアクティブユーザーの段位を示しており、天鳳全ユーザーの99.99%を上回っていることをしめす。(まぁ初段までのユーザーでおよそ80%位いるのでそれはそう)
また天鳳の歴史では十段到達したプレイヤーは100人以上いるが、安定段位はユーザーによって大きく異なることが考えられる。そのためより信頼性の高い比較を実施するために、特上卓のログからK回ゲームをサンプリングして安定段位を計算する。このようなサンプリングをN回実施して、各プレイヤー(AI)の対応するN個の安定ランクの統計を下記の図12に示す。
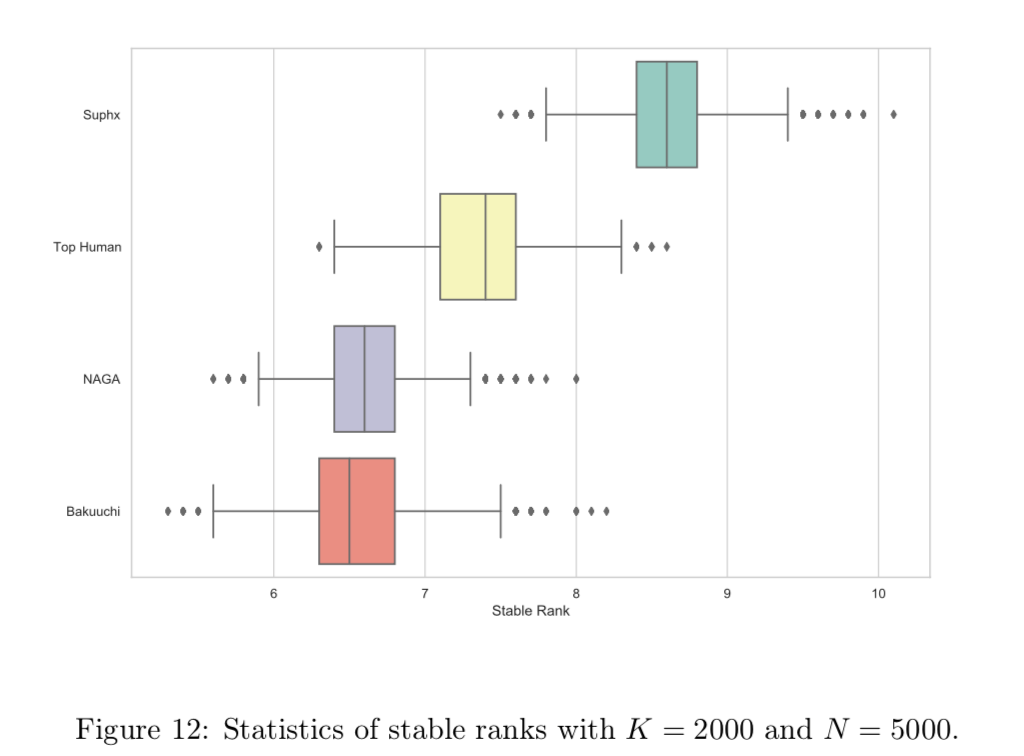
これを見ても安定段位が最強AIたちやトップ雀士の平均成績を超えていることがわかる。
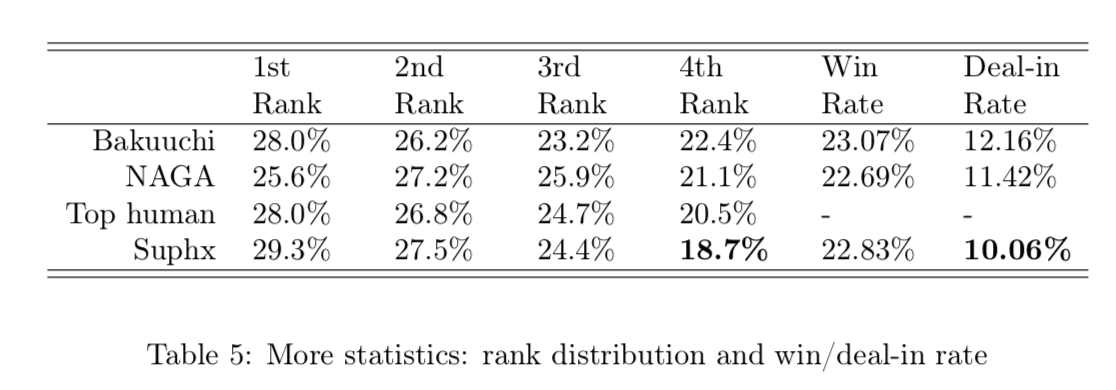
さらに対局順位情報の統計情報を表5に示す。これを見てわかるようにSuphxは4着率が非常に低く、天鳳の段位システムにおいて有利な物となっており、非常に負けにくいAIになっている。この強さは人間のトッププレイヤーにも認められており、特に安牌を持つために一色手を好みます。図13では将来的な守備を意識して安全パイを保持している。

6. 結論と展望
Suphxは天鳳とにおいて人間のトッププレイヤーの殆どを超えた初めてのAIとなった。麻雀は複雑で独特な課題があるため、Suphxは非常に優れた性能を発揮しているがまだまだ改善の余地があると考えている。
- Global reward predictionについては、限られた少ない情報を入力として受け取るが、情報が多ければより精度の高い予測を返すことは事実である。例えば手牌が良いときは予測を真に受ける必要はないし、手牌が悪いときは予測の影響をうけるべきだと考える。つまり報酬を設計する際にゲーム難易度が加味される必要がある。
- Oracle guidingでは完全な状態から不完全な状態へ移行させていくことで具体化した。これ以外にも完全な情報を活用するアプローチはあると考えられる。例えばオラクルエージェントとノーマルエージェントを同時に学習させて、オラクルエージェントの得た知識をノーマルエージェントに継承することで、より近づけ得ることができると考えている。ちなみに予備実験段階ではこの手法も機能している。他の例としてはポリシー学習を高速にするためにOracle guideにフィードバックを提供する教師を設計することも考えられる。
- ランタイムポリシーの適用については、本稿では配牌時に限定していたが、シミュレーションは配牌時に限らず、各プレイヤーが牌を切ったときにもできる。ゲームが進み情報が増えた状態で適応が進むため、さらにポリシーのパフォーマンスを向上させることができるだろう。さらにポリシー適用は徐々に行うため、サンプリングやシミュレーションの回数はあまり必要なく、少ない計算リソースでポリシー適用を行うことができる。
Suphxは常に学習して強くなるエージェントであるため、今回の実現はスタートに過ぎない。今後は斬新な技術を導入して麻雀AIに限らず不完全情報のゲームでの開拓を進めていきたいと思う。もっといえば金融市場の予測や物流最適化など、複雑なルールや操作など同じ特徴を持っているため、幅広い実世界のアプリケーションに役に立つと思う。
読んだ筆者の感想
アルゴリズムを含め非常に良くできているモデルで、これまで難しかったプロを超えるというところを達成したのも納得がいきました。とはいえ個人開発をするとなるとリソースとお金があわわわわって感じなので、特に強化学習のところを如何にリソース少なく代替して達成できると良いなと思いました。
まずは教師あり学習モデルから着手して物を作っていければと思います。翻訳に際し間違ってるところや表記ゆれなど有りましたらぜひぜひコメントお待ちしてます。