はじめに
この記事では、私が作成した(ネタ)プラグイン「ushitapunikiakun.vim」の紹介をします。
Q. 「う し た ぷ に き あ く ん 笑 っ て な ん で す か 笑 ? 」
A. 「知 り ま せ ん 笑 」
正直よくわかっていません。(は?) 競技プログラミング界隈でいつの間にか流行っていました。
詳しくはここを見てください。
どんなプラグイン?
皆さんは、以下のツイートのように文字列に1文字ずつ空白を入れた文章を作ったことはありますか?
う し た ぷ に き あ く ん 笑
— タプリス(人生終了) (@_ei1333) May 25, 2019
6 V メ タ モ ン よ こ せ や 笑 #Peing #質問箱 https://t.co/Lb3A70GTkZ
— Inazuma110 (@Inazuma_110) November 25, 2019
ありますよね?? 特にTwitter廃人の方はあるかと思います。
しかし、全文字間に空白を入れるのは普通に面倒くさいです。特に、文字列内に漢字が入ったりアルファベットが入ったりすると余計に面倒くさいと思います。
このプラグインを使うと、Vimに書かれている文字列の間に全角空白を挟み込むことを容易にします。
プラグイン紹介
使用例
Ushitapunikiakun
:Ushitapunikiakunで、現在の行に全角空白を挿入します。
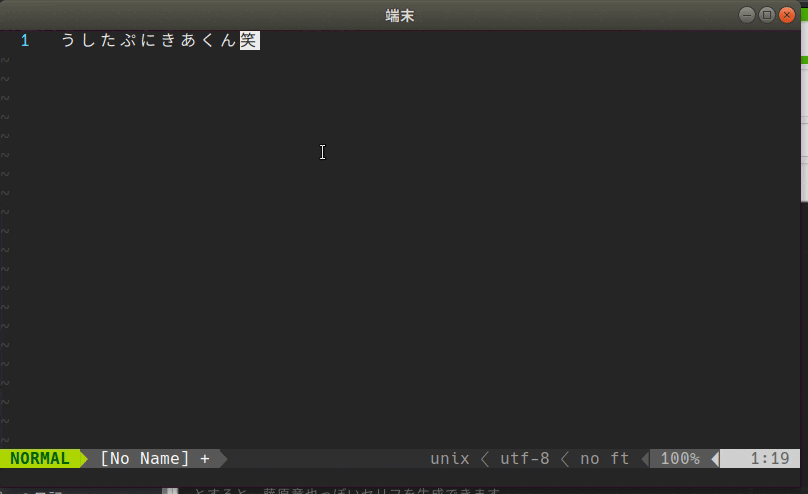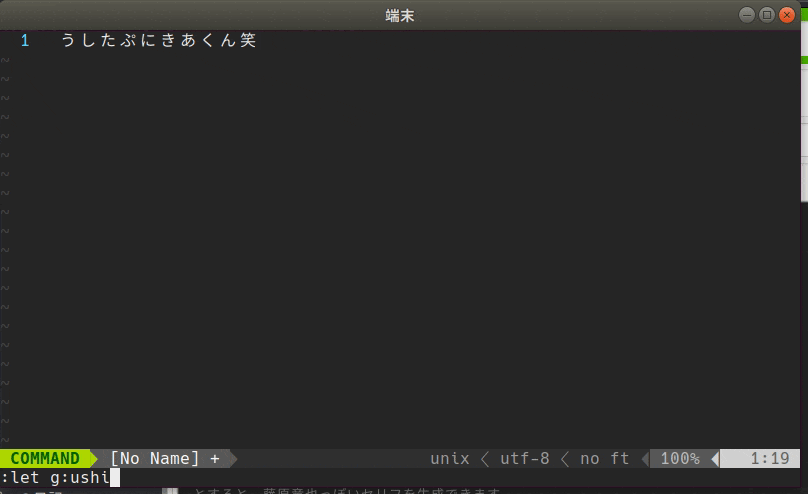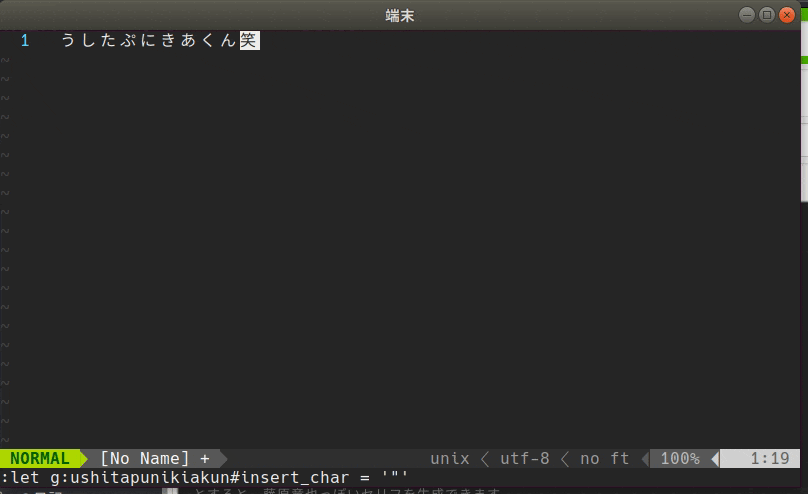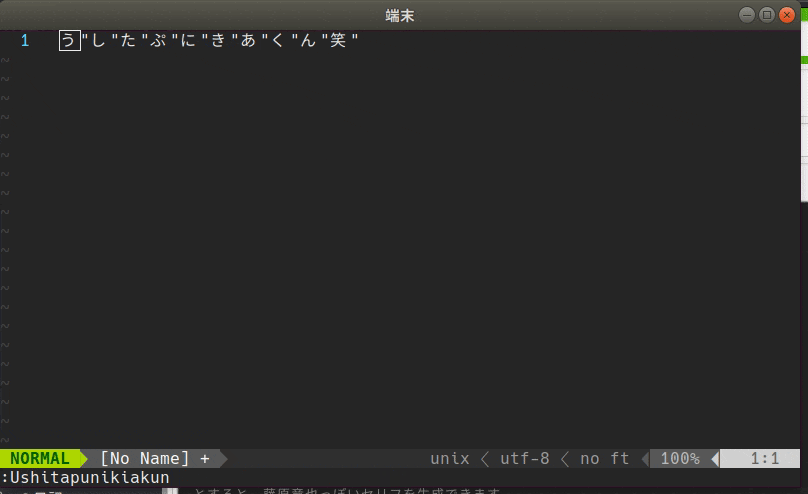
うしたぷにきあくん笑
↓ (:Ushitapunikiakun)
う し た ぷ に き あ く ん 笑
ちなみに現在の行が空だった場合、う し た ぷ に き あ く ん 笑が挿入されます笑。
この文字列は、設定することができます。
UshitapunikiakunAll
先のコマンドが現在の行だけだったのに対し、このコマンドはVimの文字すべてに空白を挿入します。
設定
挟み込む文字はデフォルトでは全角空白ですが、変更することもできます。変更する場合は.vimrcに以下のように記述します。
let g:ushitapunikiakun#insert_str = '🐮'
このように設定すると、Ushitapunikiakunコマンドの結果は以下のようになります。
う🐮し🐮た🐮ぷ🐮に🐮き🐮あ🐮く🐮ん🐮笑🐮
また、文字列が空だった場合に入力する文字は、ushitapunikiakun#empty_strの値で設定できます。
便利な利用例
藤原竜也っぽいセリフを生成する
let g:ushitapunikiakun#insert_str = '"'
とすると、藤原竜也っぽいセリフを生成できます。(お好みで'" 'などを設定すると良いです。)
demo
firenvimと組み合わせる
https://github.com/glacambre/firenvim
こちらのfirenvimというプラグインを用いると、ブラウザのテキストボックスに自分のNeovimを展開することができます。
このプラグインを合わせると、とても簡単にうしたぷにきあくん構文をツイートすることができます。
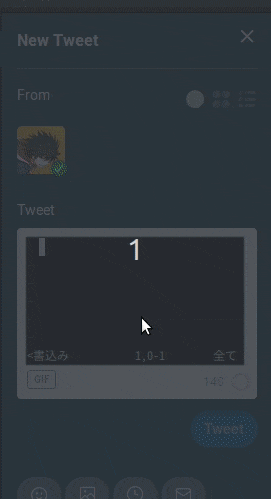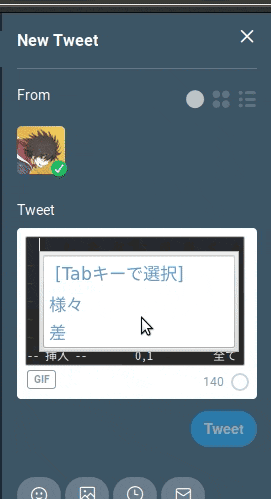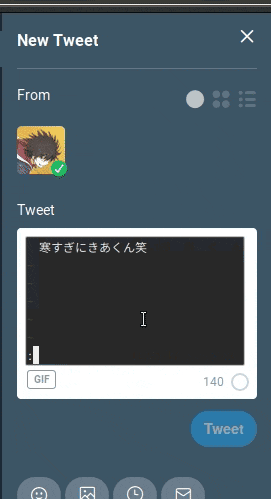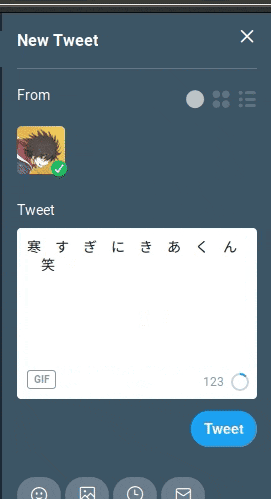
これはTweetDeckでの利用イメージです。
demo
「う し た ぷ に き あ く ん 笑」や任意の文字列のうしたぷにきあくん笑構文をTweetdeck内で素早く作成しています。
Firenvimについては、いつか別記事で便利な設定例なども紹介したいなと思っています。
思っていましたが、Vim advent calendar 2019の14日目の記事にてすでに良い記事が公開されていました!
(ちなみにこの記事も、Neovim in Qiitaによって書いています)
実装について
とくに興味がなければ、最後にまでとんでください。
結論からいうとこのプラグインは
s/\(.\)/\=submatch(1) . g:ushitapunikiakun#insert_char/g
というシンプルな文字列置換をしているだけにすぎません。ただ、この実装に行き着くまで時間がかかってしまいました。
この章ではVimscript初心者が、この実装に行き着いた経緯を書こうと思っています。
for文による実装
はじめ、このプラグインは「2重for文で行、文字を順に見て、g:insert_charを使って空白入り文字列を作り直す」という実装を考えていました。
具体的には、
let l:source_code_list = getline(0, '$')
for s:lnum in range(len(l:source_code_list))
let l:newline = ''
for s:cnum in range(strlen(l:source_code_list[s:lnum]))
let l:newline = l:newline . l:source_code_list[s:lnum][s:cnum] . g:insert_char
endfor
call setline(s:lnum + 1, l:newline)
endfor
という実装をしていました。
ちなみに、このコードを書いているときはスコープや名前空間の重要さなどをよくわからずに変数名を定義しています…。今もスコープについては理解しきれていないかもです……。
(当初と現在は変数名などが一部異なっています)
しかし、このコードを日本語に適用するとバグが発生することがわかりました。
以下のコードを試してみてください。
let japanese = "あいうえお"
for i in range(strlen(japanese))
echon japanese[i]
endfor
(少なくとも私の環境では)結果はこうなります。
<e3><81><82><e3><81><84><e3><81><86><e3><81><88><e3><81><8a>
(おそらくUTF-8の文字コード?)
つまり、日本語にこの関数を適用しても<e3> <81> <82>...のように、想定していない文字列を生成してしまいます。
この問題を修正するために、実装を変更する必要がありました。
正規表現による実装
しばらく、「どのようにすれば日本語の文字単位でfor文を使えるようにできるか」考えていましたが、次第に「文字列置換なら正規表現で実現できるのでは?」と考えるようになりました。しかし、
%s/\(.\)/\1 /g
このコードなら全角空白を挿入することができますが、変数g:ushitapunikiakun#insert_charによるカスタムができなくなってしまいます。
色々調べたのですが、後方参照と変数の挿入を同時に実現する方法がどうしてもわからず、vim-jpのSlackにて質問をしてみたところ、解決することができました。
最終的な実装
最終的に、\=とsubmatch()関数を使うことで解決しました。
\=は聞いたこともなかったのですが、helpによると「置換文字列が "\=" で始まるとき、それ以降の文字列は式として解釈される。」ようです。(詳しくは:h sub-replace-expression)
式として扱われるので、変数や関数の呼び出しができるようになる、というわけですね。
ということで、最終的に
s/\(.\)/\=submatch(1) . g:ushitapunikiakun#insert_char/g
という実装になりました。
(実際にこのプラグインを使用してみて、全文にこの関数を適用したいと思うことがなかったので、現在の行に関数を適用するよう修正されました。)
最後に
質問に答えてくださったvim-jpの皆様、ありがとうございました。
Vim plugin作成経験やVimscript経験などまだまだ浅いので、何か間違っているところやより良い実装、改善案などがありましたら、この記事のコメントやIssues、PRにお願いします。![]()