はじめに
ふかか ふっか ふかか かふか ふか〜♪

冗談ですごめんなさいしにます。(知らない人のほうが多そう)
それはさておきアイスタイル Advent Calendar 2017 3日目は インフラG兼開発G兼DB&解析系Gを纏めてマネジメントする何でも屋 @imyslxが、お菓子のお話、はしません。(くどい)
Kafkaのお話です。
個人的に最近気に入っているアプリケーションの一つ。
Kafkaとは
オープンソースの分散ストリーミング処理を行うプラットフォームです。(ってWikipediaにかいてあります。)
要するに、ログとかイベントとかを高速に収集/配信するためのシステムです。
ストレージとして、メッセージングシステムとして、ストリーミング処理基盤として、様々な用途で利用できます。
今回はストリーミングの方に注目する形でお話していきます。
背景
さてさて、メインテーマはアクセスログのストリーミング処理です。
社内の情報をもっと有効活用しよう!という取組の一環で、もともとメインで使っているモノとは別に新しい分析基盤を創り始めたのがきっかけです。
所謂Webサーバだけでも数十台の規模になるので、バックエンドのAPI層も含むと結構な数になります。
(公開数値はちょっと忘れましたが)PV数+バックエンドAPIのアクセス数を全て収集する事が可能な基盤というと選択肢は限られてきます。
技術選定
①簡単にtd-agent only
まず、初めはtd-agentと簡単なParserだけの構成から、Elasticsearchに流すという環境でTry。
負荷分散のために各サーバに簡単なParser(by perl)を設置して、それをtd-agentに食わせる、という仕組みでした。

問題点
- アプリケーションから吐かれるログの量>Parserの処理速度
- 各サーバから受信するFluentdのBufferがががg
- サーバにBufferが溜まって。。。
②RabbitMQ
RabbitMQはAMQPを利用したメッセージングアプリケーションです。
クラスタリングやミラーリングといった所謂HA的な機能が備わっており、社内でもある程度知見があるため検討に乗せてみました。
結構頑張ってConsumerであるPHPのチューニングはかなり早いところまでやったんですが、RabbitMQがもう一つってかんじで不採用にしました。

問題点
- Mirrorとかはしてくれるけど適切にバランシングするためにLB置いたりコンポーネントが増える。
- Consumerが止まるとものすごい勢いでMessageが溜まってメモリとDiskを食いつぶして停止する。
- コレについては設定のチューニングが半端だった可能性もあるけど、「High watermark!!」ってなると受信を停止してしまう基本構造。
- 2台死ぬと残りのホストが割を食って全滅、Producerであるtd-agentが動作停止する自体に。
- あんまりいっぱい処理するというよりかは信頼性に重きをおいたアプリケーションなのかなって印象。
③Kafka
あんまり頑張ってRabbitMQ使うのも本質的じゃないかなということで、新しいソリューションに手を出そう!ということで持ってきたのがKafkaです。
まぁこういったモノをちょっと動かすだけじゃなくて、高負荷なサービス上で虐め倒すのは趣味の一環でもあります(
選定理由
- 基本的に分散プラットフォームであること。
- RabbitMQとかは正直そんなに分散考えてなさそう。
- 複数のConsumerからデータを取得することを前提に考えられていて、固定されない様々な用途でデータを利用出来る。
- Cosumerがどこか死んでも色々巻き込んで死なない。
- データ量の閾値や指定した時間が経過すると古いデータは自動的に消えていく。
- Consumer側も複数用意しておけばデータロストもせずに済む。
ということでKafka使ってやってみることにしたわけです。
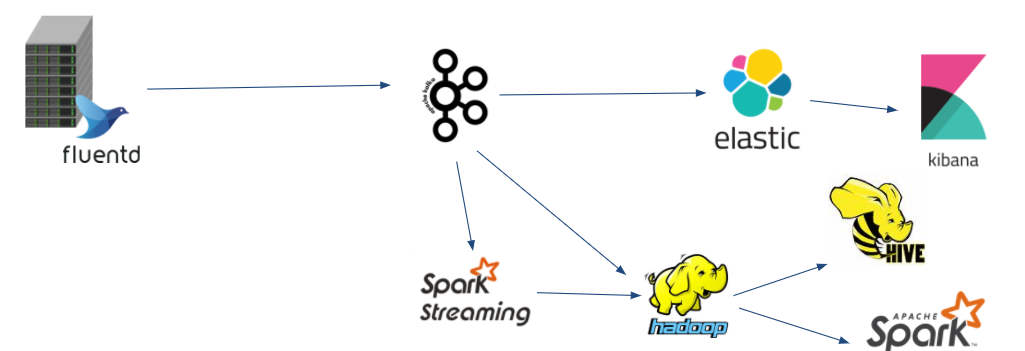
構成
割りとシンプルに、各サーバからKafkaにログを飛ばして、StreamsとConnectを使ってParseと送信処理を行っています。
やってること
- td-agentでLTSV出力したログを拾ってKafkaのTopicに投げる
- kafkastreamsを用いてLTSVをJSONにしつつ、独自Cookieをバラし、不要なデータの破棄する
- kafka-connectでJSONをElasticsearchに投げる
- 各サーバの応答速度やリクエスト数などを確認出来るなど、エンジニア的な用途で使ったり、データを吸い出して別のプロダクトに持っていったり。
- kafkastreamsを用いてJSONをAvro形式に変換しつつ、解析に必要なデータの抽出や不要なデータの破棄
- HDFS/Hive上にLoadさせていく。
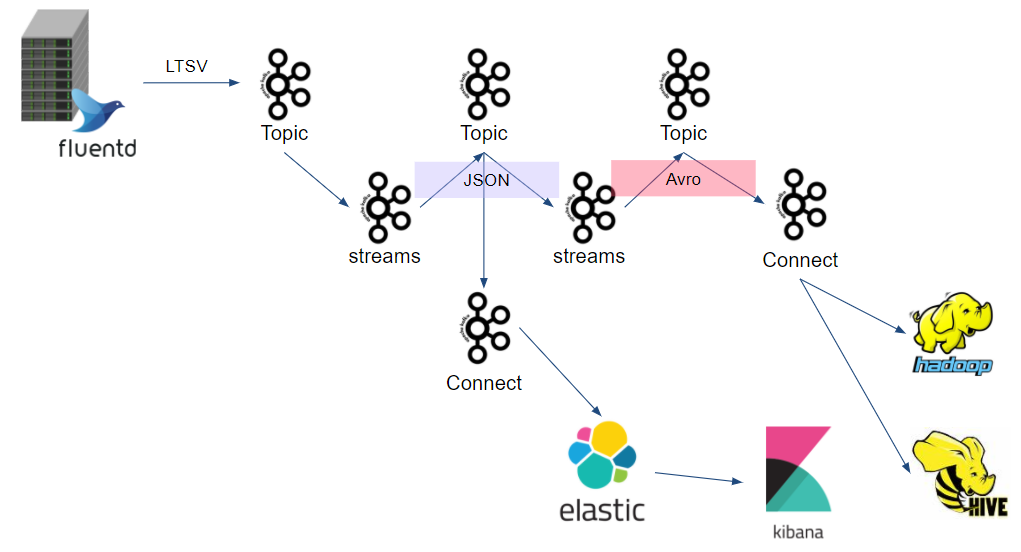
KafkaStreamsやKafkaConnectについてはあまり情報もないので、どんなことしているかは追々別で記事を書きたいと思ってます。
Javaのコードの話とか始めると長くなりそうなので。。。
Dailyで1億レコード超を処理していて、要するに各TopicへのIN/OUTを考えると軽く数億レコードの処理を最小構成の3台のクラスタでこなしています。
秒間だとピーク時5000レコード超でしょうか。
よく頑張るなぁとか最初思ってました(
これからやること
取り敢えずハコを作ったところなので、これをごにょごにょするとまさになんでも生み出せますね。
やりたいことは数年分くらい積み上がっているので幾つか上げてみたいと思います。
- Elasticsearchに乗っているデータを纏めてアクセス状況を可視化したい。
- 社内数値を纏めたポータルみたいなものを作りたいと予予考えている。
- 社内でそういう情報に手軽に触れてデータで遊べる空気感を醸成したい。
- 機械学習系にはぜひ手を出したい。
- さっさとやって学習しっかりしたほうがいい説もある。
夢はいっぱいですが工数が得られるかはまた別のお話。
まぁたぶん趣味で作ってなんとなく公開していく感じで考えてます。
おわりに
どっちかというと雑談チックな進行でしたが、何方かのご参考にでもなれば幸いです。
まだまだデータの取扱は過渡期なので、タノシイことが出てきたら記事を増やしていきたいと思います。
4日目は @yutanakano が「ポエム書く」って言ってましたので、お楽しみに!?