はじめに
KINTO Technologies Advent Calendar 2021 - Qiita の15日目の記事です。
こんにちは。Kinto Technologies Corporation(以下、KTC)でMLOpsの推進活動を担当しています。
KTCには分析グループという、「データ基盤開発・運用」、「データ分析」、「機械学習システムの開発・運用」を担う十数名のメンバーで構成されたチームがあります。
AWSを中心にCI/CD基盤やMLOps基盤を構築しており、本日は「機械学習システムの開発・運用」のテーマに焦点を当て、業務で使う中で発見したSageMaker Processing(Pipelines)のちょっとしたTipsをシェアできればと思います。
前提
SageMaker Processing
SageMaker上で特徴量エンジニアリングやデータバリデーション、機械学習モデルの評価など、あらゆる処理を従量課金で実行するマネージドサービスです。
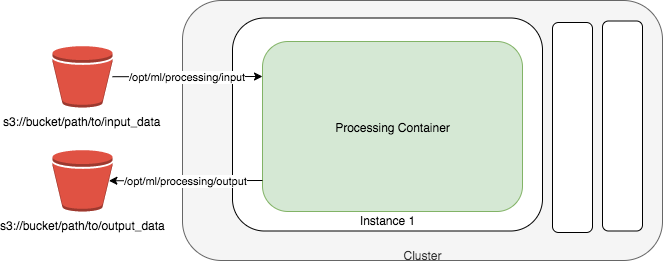
(※1 developer guideより引用)
SageMaker Processingを実行すると、上図のようにProcessing Containerが起動し、S3に保存されているインプットデータをダウンロードして、処理し、アウトプットデータをS3に出力します。
2021年12月時点で4種類あると認識しており、①PySparkProcessor, ②SKLearnProcessor, ③Script Processor, ④Processorがあります。
本記事では任意のpythonスクリプトを実行するScript Processorに焦点を当てていきたいと思います。
具体的なサンプルコードは以下のイメージです。
from sagemaker.processing import ScriptProcessor, ProcessingInput, ProcessingOutput
ecr_image_uri = f'{account_id}.dkr.ecr.{region}.amazonaws.com/{ecr_repo}:{tag}'
process_role = f'arn:aws:iam::{account_id}:role/{processing_role}'
# ECRのコンテナイメージを指定し、実行環境を定義します。
script_processor = ScriptProcessor(command=['python3'],
image_uri=ecr_image_uri,
role=process_role,
instance_count=1,
instance_type='ml.t3.medium')
# SageMaker Processing実行時に任意のpythonスクリプトおよびデータの入出力に関して引数で指定します。
script_processor.run(code='src/transform.py',
inputs=[ProcessingInput(
source=f's3://{bucket}/{prefix}/extract.csv',
destination='/opt/ml/processing/input/extract')],
outputs=[ProcessingOutput(
source='/opt/ml/processing/output',
destination=f's3://{bucket}/{prefix}/output')])
ECRに登録するコンテナの作り方や必要な権限は本記事の趣旨から外れるため、公式のdeveloper guide(※1)を参照ください
また、script_processorインスタンスに渡すpythonスクリプトは以下のように書きます。
import os
import pandas as pd
if __name__ == "__main__":
file_name="extract.csv"
input_data_path = os.path.join("/opt/ml/processing/input/extract", file_name)
print("Reading input data from {}".format(input_data_path))
df = pd.read_csv(input_data_path)
filter_col = ['feature1', 'feature2', 'y']
df = df.reindex(columns=filter_col)
local_output_path = os.path.join("/opt/ml/processing/output", "transform.csv")
print(f"Saving output data to {local_output_path}")
df.to_csv(local_output_path, header=False, index=False)
script_processorに渡す「ProcessingInputのdestination」および「ProcessingOutputのsource」と、
transform.pyの入出力のパスを合わせるのがポイントです。
(なお、ローカルのパスは/opt/ml/processing/で必ず始めないといけない仕様なようです)
SageMaker Pipelines
SageMaker PipelinesのStep定義もscript_processorインスタンスを渡すことで定義することができます。
transform = ProcessingStep(
name='transform_step',
processor=script_processor,
code=f'src/transform.py',
# transformステップの直前にextractステップがあるという前提でProcessingInputを定義しています。
inputs=[ProcessingInput(source=extract.properties.ProcessingOutputConfig.Outputs["extract"].S3Output.S3Uri,
destination='/opt/ml/processing/input/extract')],
outputs=[ProcessingOutput(output_name="transform",
source='/opt/ml/processing/output',
destination=f's3://{bucket}/{prefix}/output')])
Glueのカタログテーブルおよびパーティション
この記事ではScriptProcessorで出力したcsvデータをS3に出力させますが、それをAthenaやRedshift SpectrumでクエリできるようにするためにはGlueのカタログテーブルとして登録する必要があります。また、カタログテーブルにパーティションを認識させる必要もあります。
Glueのパーティションの切り方はs3://bucket/prefix/output/processing_date_jst=2021-12-15といったようにkey=val形式でS3にデータを格納する必要があります(※2)。
S3を意識せずにS3のパーティションを切る
何を言ってるんやという感じですが、そのまんまです。
ScriptProcessorを使うとできてしまって驚きました。
SageMaker Processingのインプットとアウトプットのインターフェースは上記で見たように、
「ローカル」と「S3」の両方を指定する必要があります。
以下の部分ですね。
# インプットについては、sourceが「S3」、destinationが「ローカル」です。
ProcessingInput(source=f's3://{bucket}/{prefix}/extract.csv',
destination='/opt/ml/processing/input/extract')
# アウトプットについては、sourceが「ローカル」、destinationが「S3」です。
ProcessingOutput(source='/opt/ml/processing/output',
destination=f's3://{bucket}/{prefix}/output')
このような記述をすることで、「S3」→「ローカル」→「S3」というデータの移動を抽象化してくれます。
まるでローカルとS3をマウントする感覚で使えるので楽しいです。
このように抽象化するメリットとして、pythonファイル作成者はローカルでpythonファイルの動作確認さえできれば、クラウド上のS3連携は勝手にScriptProcessorが担ってくれるということです。
実際、上述のtransform.pyはS3に関する記述を一切していません。
そのため、動作確認のためにAWSアカウントの認証をしたり、コンソール開いてS3確認したりといった作業が基本的には不要になりました。(パス間違えとかしてなければね)
これらは大した手間ではないかもしれませんが、やっぱり微妙にめんどくさかったりします。
SageMaker Studioの左側にあるFile Browserでローカルの環境を確認すれば動作確認できるのは地味に嬉しい機能でした。
(S3アップロードの書きっぷりもboto3.resourceやclient、sagemaker.sessionを使うなど多様にありますが、それも意識することなく標準化できますしね)
そして、個人的な感動ポイントはこの機能を用いてパーティション作成も反映できるということです。
データ量の多い処理をする際にはパーティションもサクッと作ってあげると、クエリを書くアナリストやデータサイエンティスト、ETL処理を開発するデータエンジニア、ひいてはコスト管理の観点でインフラエンジニアなど、みんなハッピーになれるかもしれません(もちろん仕様や要件、責務について認識のすり合わせはしてください)。
さきほどのtransform.pyのローカルへの出力部分をこんな感じに書き換えます。
# Glueのパーティションの仕様に則って、あたかもS3のパーティションを定義するように、ローカルに出力する。
local_output_path = os.path.join(f'/opt/ml/processing/output/process_date_jst={today}', 'partition.csv')
print(f"Saving output data to {local_output_path}")
df.to_csv(local_output_path, header=False, index=False)
例の如くS3に関するコードは一切ありませんが、S3にしっかり反映してくれました。
また、上記の例では1パーティション追加するだけですが、階層構造を持たせたり(e.g. year=/month=/day=)、複数のパーティションを切るように書いたとしても/otp/ml/processing以下のoutputディレクトリはそのままS3に反映されるので、結果的にパーティションを切ることができるというわけです。
最高でした。
落穂拾い
パーティションを切ると豪語しましたが、athenaへ連携するにはglueカタログテーブルにパーティションを認識させないといけません。
以下のようなCloudFormationテンプレートおよびパーティション登録の作業を忘れずに実行することをお勧めします。
AWSTemplateFormatVersion: "2010-09-09"
Description: provision partitioned_table_sample
Resources:
PartitionedTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Sub ${AWS::AccountId}
DatabaseName: !Sub ${DB}
TableInput:
Name: !Sub ${Table}
Description: "partitioned_table_sample"
TableType: EXTERNAL_TABLE
Parameters:
classification: csv
EXTERNAL: TRUE
columnsOrdered: true
areColumnsQuoted: false
delimiter: ','
PartitionKeys:
- Name: process_date_jst
Type: string
StorageDescriptor:
Columns:
- Name: feature1
Type: string
Comment: feature1の説明。
- Name: feature2
Type: string
Comment: feature2の説明。
- Name: y
Type: string
Comment: 目的変数。
Location: !Sub s3://${Bucket}/${Prefix}/output
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
SerdeInfo:
Parameters:
field.delim: ','
serialization.format: ','
SerializationLibrary: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
パーティション登録の作業はパイプラインの後処理として自動化するのが良いと思います。
boto3でathenaのclientを作ってMSCK REPAIR TABLE Table;をクエリ実行するか、
同じくglueのclientをboto3で作り、create_partition()などを実行するか、が考えられると思います。
SageMaker ProcessingにはPySparkProcessorもあるので、大規模データに対してはPySparkでGlueの肩代わりをしてもらうのも選択肢のひとつになるかもしれませんね。
最後に
ここまででSageMaker Processingを使ってS3のパーティションを切る流れを見てきました。
「Pythonスクリプトのアプリケーションロジック」と「Dockerの実行環境」の分離を担うScriptProcessorは、
他にも動作確認をローカルで行うことができる点や、必要に応じてロジック開発者とDockerの実行環境開発者の作業分担することができるなどの点も魅力だと感じています。
「組織の拡大」や「業務の細分化および専門化」が進めば進むほどうまみがでてくる機能だと思うので、今後もうまく付き合っていければと思っています。
当社では、トヨタ車のサブスク「KINTO」等の企画/開発を行っており、エンジニアを募集中です。
KINTO Technologies コーポレートサイト
参考
- (※1)SageMaker Processingのdeveloper guide: https://docs.aws.amazon.com/sagemaker/latest/dg/processing-job.html
- (※2)Glueパーティションのdeveloper guide: https://docs.aws.amazon.com/glue/latest/dg/aws-glue-programming-etl-partitions.html