この記事について
Cloudera は、データプラットフォームと直結した可視化ツールとして Cloudera Dataviz を提供しています。
Cloudera Dataviz は以下のように様々な形式で利用することができ、利用方法によって料金体系が変わります。
- Cloudera Onpremise の Base の機能として
- Cloudera Data Warehouse の付属機能として
- Cloudera AI の付属機能として
Base や Cloudera Data Warehouse との接続のスムーズさは、Cloudera Dataviz の魅力のひとつです。
一方、Cloudera AI を単体で利用している場合、Cloudera AI のプロジェクトファイルを Datavizと接続して可視化したい! というニーズもあるでしょう。
この記事では、そんなニーズに対応するために、Cloudera Dataviz を Cloudera AI のプロジェクトファイルと接続する方法を解説します。
接続方法
シナリオ
プロジェクトファイルとして、以下のような cereal.csv というファイルがプロジェクトの親フォルダに存在するとします。
name,mfr,type,calories,protein,fat,sodium,fiber,carbo,sugars,potass,vitamins,shelf,weight,cups,rating
100% Bran,N,C,70,4,1,130,10,5,6,280,25,3,1,0.33,68.402973
100% Natural Bran,Q,C,120,3,5,15,2,8,8,135,0,3,1,1,33.983679
All-Bran,K,C,70,4,1,260,9,7,5,320,25,3,1,0.33,59.425505
All-Bran with Extra Fiber,K,C,50,4,0,140,14,8,0,330,25,3,1,0.5,93.704912
Almond Delight,R,C,110,2,2,200,1,14,8,-1,25,3,1,0.75,34.384843
Apple Cinnamon Cheerios,G,C,110,2,2,180,1.5,10.5,10,70,25,1,1,0.75,29.509541
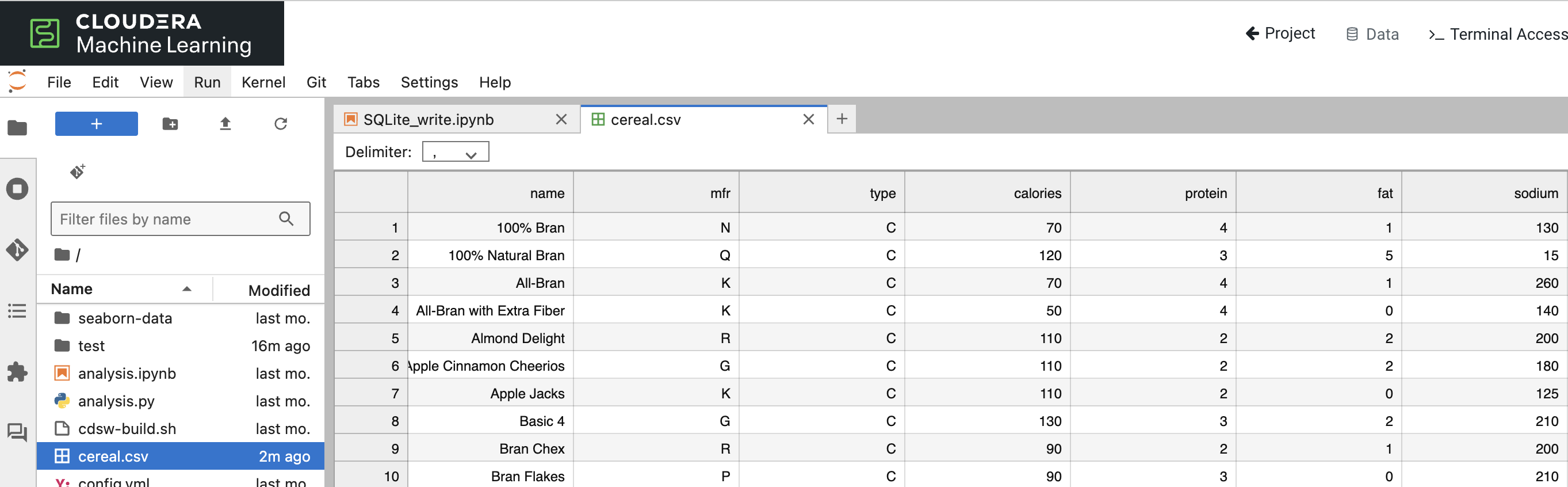
これを、Dataviz で可視化することを考えてみましょう。
前提
Cloudera AI で Python を使っている場合、Python には一般的に SQLite が同梱されています。
そこで、SQLite のコネクションファイルを作った上で、csv データを SQLite のデータベースに格納し、それと接続するという方法をとります。
手順
SQLite のコネクションファイルの設定
Cloudera AI のセッションで、以下のコードを実行します。
import sqlite3
conn = sqlite3.connect("connection.sqlite")
すると、ワーキングディレクトリ(通常はノートブックを開いているディレクトリ)配下に connection.sqlite というファイルができます。
ファイル名は任意の名前で大丈夫です。
コネクションファイルとの接続
Cloudera AI のプロジェクト配下の Data メニュー > Datasets タブで、NEW CONNECTION ボタンをクリックします。

出てきたウィンドウで、下記のとおり設定します。
- Connection type - SQLite を選択
- Connection name - 任意の名前を設定
- File name -
/home/cdsw/connection.sqlite1

設定したら、TESTボタンをクリックします。
以下のように、緑の成功マークが出ればOKです。2

「CONNECT」をクリックします。

プロジェクトファイルをSQLデータとして格納
Cloudera AI のセッションで以下のコードを実行します。
dtype には、SQLite格納時に型を明示的に指定したい項目を定義します。(指定しない場合は、Pythonの推論に従います)
import pandas as pd
import sqlite3
from sqlalchemy.types import Integer, Text, Float
# データの読み込み
df = pd.read_csv("cereal.csv")
# SQLite への書き込み
conn = sqlite3.connect("connection.sqlite")
df.to_sql(
"cereal_table", conn,
if_exists="append",
index=False,
dtype={
'name': 'TEXT',
'calories': 'INTEGER',
'protein': 'INTEGER',
'fat': 'INTEGER',
'rating': 'REAL'
}
)
conn.close()
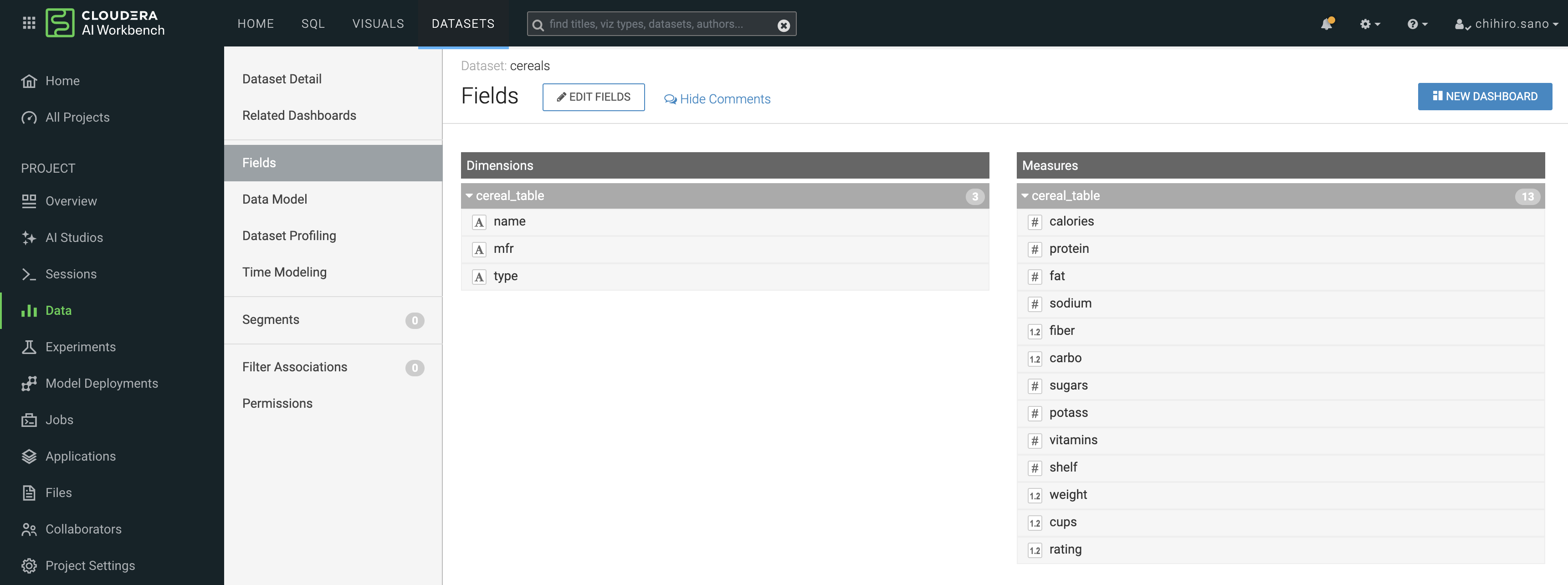
Dataviz での利用
Dataviz でデータを利用するためには、データセット(Dataviz が利用するデータの論理的なビュー)を作る必要があります。
以下の手順でデータセットを作ります。
Cloudera AI > Data > DATASETS > SQLiteとのコネクション を選択し、NEW DATASET をクリックします。

出てきたウィンドウに、以下の要領で設定します。
- Dataset Title - 任意の名称を設定(テーブル名など)
- Select Database - main を選択
- Select Table - 接続したいテーブルを選択

CREATE をクリックすると、データセットが作成されます。
おまけ:Dataviz 側から CSV をアップロードする方法
すでに分析可能な状態の CSV ファイルが手元にある場合、わざわざプロジェクトファイルとしてアップロードし、SQLiteに書き込んでコネクションを作るのが面倒なこともあるでしょう。
そうした場合は、Dataviz のアップロード機能を使ってデータセットを作ることもできます。
以下はその手順です。
コネクションの画面から、ADD DATA をクリックします。
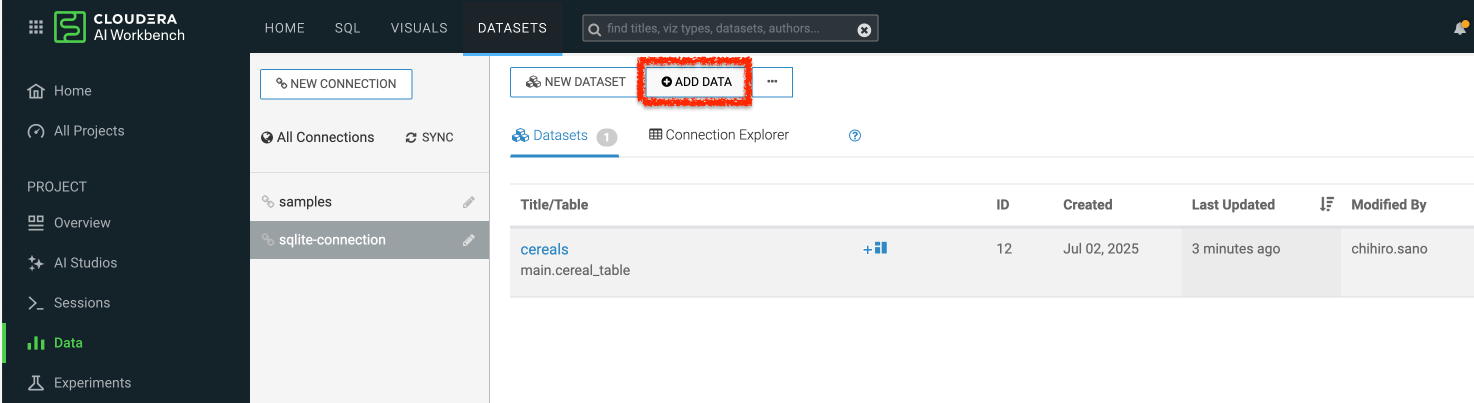
分析したい CSV ファイルをアップロードし、GET DATA をクリックします。

以下のように、CSVの情報が表示されます。
設定項目を以下の要領で確認します。
- Table Name - 任意の名前を設定します
- Upon Import - Create Dataset を選択します
- カラム名、型 - カラム名(CSVの1行目)、型(Dataviz が推論したもの)が表示されますので、必要に応じて変更します

確認が完了したら、CONFIRM IMPORT をクリックします。

確認のポップアップが出てくるので、CONFIRM IMPORT をクリックします。

以上の手順で、Dataviz 側からプロジェクト内のSQLite にデータを書き込みつつデータセットを作成することができます。
おまけのおまけ:SQLite に書き込んだデータを分析する
SQLite へのデータ格納をセッション上で行った場合も、Dataviz から行った場合も、最終的には SQLite のデータベースとしてデータが書き込まれることになります。
したがって、どちらのデータも SQLite の文法にしたがって自由に取り出したり、編集することが可能です。
以下によく使うコードを書いておきます。
最初にやるインポート、初期化
import sqlite3
conn = sqlite3.connect("connection.sqlite")
cursor = conn.cursor()
テーブル一覧の取得
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = cursor.fetchall()
tables
# [('cereal_table',), ('cereal2',)]
テーブルのデータを pandas の df に取り込み
import pandas as pd
df = pd.read_sql("SELECT * FROM cereal2", conn)
df
最後に必ず行う:コネクションの close
conn.close()
よくある QA
Q. セッションが止まっている状態でも、プロジェクト内のSQLiteとのコネクションは有効ですか?
A. 有効です。
以上!
この記事が、Cloudera AI 上の Dataviz をもっと気軽に活用する一助になれば幸いです。
-
プロジェクトファイルの親のディレクトリが
/home/cdsw/というパスになっています。親ディレクトリ直下にconnection.sqliteファイルが存在する場合は/home/cdsw/connection.sqliteのままでよいですが、たとえばconnection.sqliteファイルをsqliteフォルダ配下に作った場合は/home/cdsw/sqlite/connection.sqliteを指定します。 ↩ -
存在しないファイルパスを指定して TEST をすると、Dataviz がその名前でコネクションファイルを作りに行きます。コネクションファイルが作成できた場合、TESTは成功になります。 ↩