この記事について
マルチAIエージェントを作れるオープンソースのライブラリ、crewaiについて学んだことのメモ続編。
基本編はこちらです。
この記事では、複数のタスクの順序制御についてまとめます。
今回の例
今回は、あるお題をもとに二人の芸人がそれぞれギャグとだじゃれを作り、最後に審査員がそれを審査するという例でマルチエージェントのクルーを作ってみたいと思います。
(あまり実用性はないかもしれませんが、わかりやすさ重視でこの例を選びました)
LLMのモデルは Bedrock の Claude3.5 sonnet を使います。
また、環境準備の手間が最小で済むように、Google Colab を使う前提でコードサンプルを掲載します。
コードサンプル
インストール
!pip install crewai
!pip install boto3
コード
前準備部分
以下のように、必要なモジュールのインポートや環境変数の設定などを行います。
# インポート
from crewai import Agent, Task, Crew, Process, LLM
import os
# Bedrock を利用するための環境変数の設定
os.environ['AWS_ACCESS_KEY_ID'] = "BedrockにアクセスできるIAMユーザーのアクセスキー"
os.environ['AWS_SECRET_ACCESS_KEY'] = "BedrockにアクセスできるIAMユーザーのシークレットアクセスキー"
os.environ['AWS_DEFAULT_REGION'] = "Bedrockをサポートしているリージョン(ap-northeast-1など)"
# ClaudeをBedrock経由で利用するための指定
claude_llm = LLM(
model="anthropic.claude-3-5-sonnet-20240620-v1:0"
)
エージェントの作成
以下のように、3つのエージェントを作ります。
# ギャガー
gagger = Agent(
role="ギャガー",
goal="{odai}に関するギャグを言う",
backstory="元気だがネタを言わない人気芸人",
tools=[],
llm=claude_llm,
verbose=True
)
# だじゃれ芸人
dajare_geinin = Agent(
role="だじゃれ芸人",
goal="{odai}に関するだじゃれを言う",
backstory="知的で独創的なだじゃれを作るシュール系芸人",
tools=[],
llm=claude_llm,
verbose=True
)
# 審査員
jury = Agent(
role="審査員",
goal="ギャガーとだじゃれ芸人が言ったギャグとだじゃれを評価する",
backstory="お笑いに関する豊富な知識と経験を持った中立的な審査員",
tools=[],
llm=claude_llm,
verbose=True
)
タスクの作成
# タスク
gag = Task(
description=f"{odai}に関するギャグをやってください",
expected_output="下ネタを含まない元気な短いギャグ。ギャグだけ言って、前後のセリフはいりません。",
agent=gagger,
async_execution=True # ここをFalseにすると、gagが終わってからdajareが始まる
# True にしておくことで、gagとdajareを同時進行できる
)
dajare = Task(
description=f"{odai}に関するだじゃれを言ってください",
expected_output="知的で独創的な、でもわかりにくすぎないだじゃれ。だじゃれだけ言って、前後のセリフはいりません。",
agent=dajare_geinin,
async_execution=True # ここをFalseにすると、gagが終わってからdajareが始まる
# True にしておくことで、gagとdajareを同時進行できる
)
judge = Task(
description="{{{gag}}}と{{{dajare}}}を比較して審査してください。",
expected_output="{{{gag}}}と{{{dajare}}}それぞれに関する100点満点の点数と、関西弁の辛口な評価コメント、勝者は誰か、勝者のネタ。",
agent=jury
)
judge の中にある {{{gag}}} や {{{dajare}}} などの表記は、gagやdajareの出力結果を使うという意味です。
{{{タスク名}}} の形式で、任意のタスクの結果を利用することができます。
実行
odai = "レモン"
crew = Crew(
agents=[gagger, dajare_geinin, jury],
tasks=[gag, dajare, judge],
verbose=False # <- 今回は出力結果を簡潔に見たいのでFalseにしておく
)
result = crew.kickoff()
上記のように、agents や tasks に複数のエージェントやタスクを列挙することで、基本的には tasks のリストに記載された順番にタスクが一つずつ実行されます。
ただし、今回は gag と dajare に async_execution=True を指定しているため、このふたつのタスクは非同期で同時に動きます。
また、judgeタスクは{{{gag}}} および {{{dajare}}} の指定によって、gag と dajare の出力結果を使うことから、両タスクの終了を待ってからの開始となります。
実行結果
async_execution=False の場合
async_execution=False の場合、tasks=で指定されたリストの要素が順番に実行されます。
今回は tasks=[gag, dajare, judge] という指定になっているので、まずはギャグをやるタスク(gag)が指示され、実行されます。
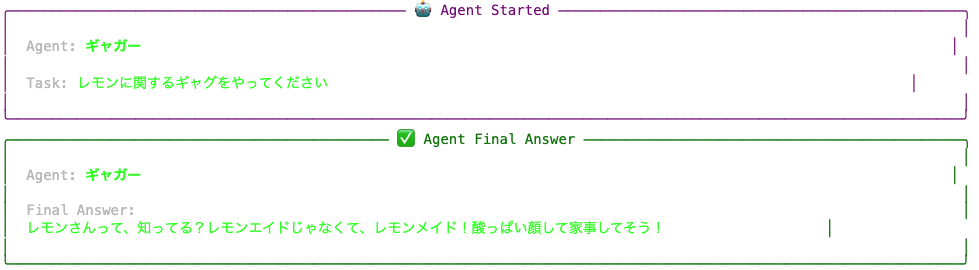
ギャグ(gag)の実行が完了してから、だじゃれ(dajare)の実行指示が出され、実行されます。
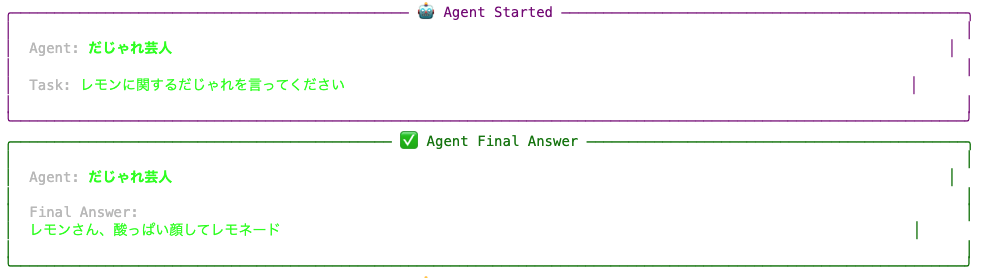
両者の完了後に、審査員のタスク(judge)がキックされ、実行されます。

async_execution=True の場合
async_execution=True になっているタスク同士は、非同期で実行されます。
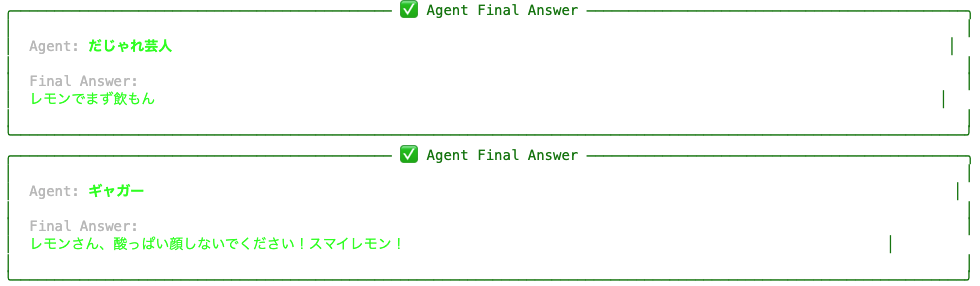
今回の例でgagとdajareにそれぞれasync_execution=Trueを指定すると、まずギャグとだじゃれを作る指示が同時に出されます。

そして、終わった順に結果が表示されます。
指示は ギャグ→だじゃれ という順番で出されましたが、だじゃれの方が完了が早かったので、結果はだじゃれの方が先に出ています。
(今回の結果はこうでしたが、ギャグの方が先に実行が終わればギャグの結果が先に表示されます)
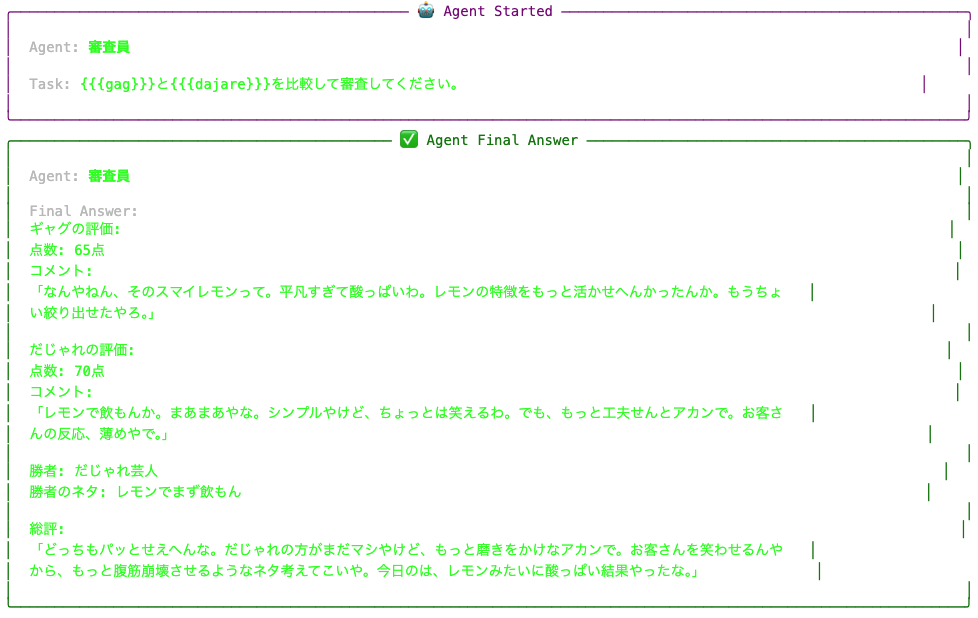
gagとdajare両方の結果を必要とする審査員のタスク(judge)は、両者の完了後にキック&実行されるという点は同じです。
まとめ
今回は、「あるお題をもとに二人の芸人がそれぞれギャグとだじゃれを作り、最後に審査員がそれを審査する」という例をもとに、マルチエージェントのクルーを作るサンプルを掲載しました。
async_execution=を使った順序制御の基本についても触れました。
なお、出力結果を詳しく見た方は、だじゃれやギャグの品質や審査の結果について、色々と思うところもあるかもしれません。
モデルによっては、「この出力結果はだじゃれと言えるのか・・・?」といったものが出てくるケースもあるでしょう。そうした場合は、タスクのexpected_outputにだじゃれとは何かの説明や具体例などを追加してあげることで、期待する出力結果に近づけることができます。
モデル別のだじゃれやギャグのうまさについては今回は検証していませんが、興味がある方がいたらぜひ試してみてください。
では!