chatGPTなどを日々使っていて常々「こんな処理をどうやって実現しているんだろう?」という疑問を抱いていました。
最初のうちは、送った文章(プロンプト)に対して、文法的な解釈をしているのか?背後でweb検索を動かしているのか?回答のためのフォーマットか何かが決まっているのか?などいろいろ想像していだけでした。しかしちょこちょこ調べているうちに、それらがすべて間違っていることが分かってきて、面白い!と感じました。今もまだわからないことだらけですが、現時点での理解をまとめてみたいと思います。
高校生でも分かるように書こうと思いますが、行列周りの演算が出てくるのでそこだけご留意ください。
また、「なぜそういう仕組みなのか」の部分については今回は最低限にとどめます。
参考にするソース
本記事は、こちら(特にggml-ctx.cpp)を参考に書いています。
この記事の各記述がソースのどこに当たるか、などは次回詳しく書ければと思っています。
また、これ(ggml)そのものではありませんが、ggmlをつかった主要ソフトであるllama.cppのビルド/デバッグ方法について以前書いた記事があるのでそちらもよければご覧ください。
文章(=単語列)をベクトル列に変換する
※今回はプロンプトも出力も英語の場合を想定します。日本語だと単語への分解が素直にできないためです。

例として、「Q: What is the highest mountain in Japan? A:」というプロンプトを渡した場合を考えます。
このとき、LLM内部の動きとしては上図のように、単語すべてをベクトルに変換して処理する仕組みになっています。
この時点で、各ベクトルには以下のような対応関係が出来上がっています。
- king - man + woman = queen のような等式が成立
- 具体的なワードほど遠い
なお、図では2次元のベクトルを描いていますが、実際の次元は768です。
大枠:「次の単語予測機」に次々と文章を突っ込む

上の図のように、関数に「それまでの文章」を表すベクトル列を渡すと、次の単語を表すベクトルが返ってくる、というのが大枠の仕組みになっています。「関数」の処理は事前に学習したパラメータを使います。
関数内部の処理では数値計算的な処理しかしていないので、この時点で文法を解釈するような処理にはなっていなそうなのがわかります。
もう少し詳しく見ると
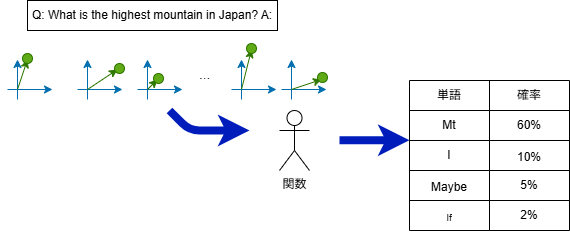
上の図のように、この関数自体は次に来る単語の"確率の一覧表"を返します。
その後実際に採用する単語を選びます。これはtop-k samplingなる処理(上位k個からランダムで選ぶ)で行われます。
関数の中身の心臓部
それではここから、関数の中身を見ていきます。
W_2 gelu(W_1x+b_1)+ b_2
xは最後の一単語、上の図で言ったら「A:」をベクトルにしたものです。ですので768次元です。
W_1とb_1は学習済みの数値が入ったデータです。W_1は3072×768の行列で、b_1は3072次元のベクトルです。
geluはmax(x,0)を少し歪ませたような形の関数です。3072個の要素すべてに対して演算します。
W_2とb_2も学習済みの数値が入ったデータです。W_2は768×3072の行列で、b_2は768次元のベクトルです。
この機構は全結合層の一種です。隠れ次元(今回では3072にあたるもの)を大きくすれば任意の関数を任意の精度で近似できることが知られているそうです。
これだけだと直前の一単語の情報のみから予測することになってしまうので、それまでの文脈も込みで予想するためにいわゆるK, Q, Vといった数値計算を入れます。
今回はここまでにして、残りは次回説明したいと思います。
[25/12/15追記]K,Q,Vなどの理解が間に合わなかったため、後ほど加筆したいと思います。
最後までお読みいただきありがとうございました。