5行で
- データサイエンティストは普段はJupyterで分析をしている
- 故にDBに対する処理もJupyter上で行いたい欲望がある
- 故にBigQueryもWebUIやRESTAPIではなくライブラリ経由でJupyter上で使えた方が便利
- 上に書いたことを実現するために公式のライブラリ
google.cloud.bigqueryの機能を調べることにした - 下にBigQueryにおけるテーブル作成の方法をまとめた
下準備
from google.cloud import bigquery
# 自身のGCPProjectIDを指定
project_id = 'YourProjectID'
client = bigquery.Client(project=project_id)
Colaboratoryで認証を通す方法がわからない場合には、前に記事書いたのでそれを参照いただければと思います。
GCE環境で実行するならばそもそも認証についてはデフォルトで通っているはず。
他の環境でアクセスするならば下記の公式のAPIリファレンスに従って認証用JSONを作成して読み込ませましょう。
ColaboratoryでBigQueryにアクセスする3つの方法
公式APIリファレンス
前提
google.cloud.bigquery : Ver. 1.20.0
- GCE上で構築されたJupyterで実行されることを前提に記載します
言うまでもないけどこんな感じでインストールしておいてください
pip install google-cloud-bigquery==1.20.0
DataSetはUSリージョンで作成することを前提とします
DataSet操作
すでにDataSetが用意されているPJであればこの部分は完全にすっ飛ばしてOK。
まだDataSetがなくてもDataSetを色々と作り変えることは基本的にはないので、一度処理してしまえばここら辺の機能は忘れてOK。
ちなみに、BigQueryのDataSetは他のDBで言う所の「スキーマ」に該当する。でもBQではスキーマに別の意味を与えているのでここではDataSetの事はスキーマとは呼ばない。
DataSetの作成
# [demo]という名称でDataSetを作成
dataset_name = "demo"
dataset_id = "{}.{}".format(client.project, dataset_name)
dataset = bigquery.Dataset(dataset_id)
# locationはUSが一番安いのでいつもこれにしている. リージョンにこだわりがあれば変更してください
dataset.location = "US"
client.create_dataset(dataset)
Table操作
テーブルの作成やテーブルへのデータをロードする処理について
- テーブルの作成
- テーブルの確認
- テーブルへのData Import
- テーブルからのData Export
- テーブルの削除
基本的には↓公式リファレンスを読めば全部書いてあるけど、まぁ。。。うん。。。Qiitaで書いといてもいいじゃん。。。
-参考-
Managing Tables
データ定義言語ステートメントの使用
テーブルの作成
ここでは仮に下の様な商品の購入履歴テーブルを作成する事を想定してコード例を記載していく
| # | カラム名 | 型 | モード | コメント |
|---|---|---|---|---|
| 1 | TRANSACTION_ID | STRING | REQUIRED | 購入履歴ID |
| 2 | ORDER_TS | TIMESTAMP | REQUIRED | 購入時間 |
| 3 | ORDER_DT | DATE | REQUIRED | 購入日 |
| 4 | ITEM_CODE | STRING | REQUIRED | 商品ID |
| 5 | ITEM_NAME | STRING | NULLABLE | 商品名 |
| 6 | QUANTITY | INTEGER | NULLABLE | 購入数量 |
| 7 | AMOUNT | FLOAT | NULLABLE | 購入金額 |
| 8 | DISCOUNT | FLOAT | NULLABLE | 値引金額 |
| 9 | CUSTOMER_ID | STRING | REQUIRED | 顧客ID |
| 10 | ITEM_TAG | RECORD | REPEATED | 商品タグリスト |
| 10.1 | TAG_ID | STRING | NULLABLE | タグID |
| 10.2 | TAG_NAME | STRING | NULLABLE | タグ名称 |
*ネストされた情報を扱いたくない場合は#10のフィールドは無視する
テーブル定義を作成する(スキーマを作成する)
BigQueryではテーブルの定義のことをスキーマと読んでいる
よって、bigquery.SchemaFieldのメソッドに色々定義をぶち込んでいくことになる
フィールド名と型は省略不可
タグ情報はネストされた形式で定義
from google.cloud import bigquery
# Schemaを定義
schema = [
bigquery.SchemaField('TRANSACTION_ID', 'STRING', mode='REQUIRED', description='購入履歴ID'),
bigquery.SchemaField('ORDER_TS', 'TIMESTAMP', mode='REQUIRED', description='購入時間'),
bigquery.SchemaField('ORDER_DT', 'DATE', mode='REQUIRED', description='購入日'),
bigquery.SchemaField('ITEM_CODE', 'STRING', mode='REQUIRED', description='商品ID'),
bigquery.SchemaField('ITEM_NAME', 'STRING', mode='NULLABLE', description='商品名'),
bigquery.SchemaField('QUANTITY', 'INTEGER', mode='NULLABLE', description='購入数量'),
bigquery.SchemaField('AMOUNT', 'FLOAT', mode='NULLABLE', description='購入金額'),
bigquery.SchemaField('DISCOUNT', 'FLOAT', mode='NULLABLE', description='値引金額'),
bigquery.SchemaField('CUSTOMER_ID', 'STRING', mode='NULLABLE', description='顧客ID'),
bigquery.SchemaField('ITEM_TAG', 'RECORD', mode='REPEATED', description='タグ情報',
fields= [
bigquery.SchemaField('TAG_ID', 'STRING', mode='NULLABLE', description='タグID'),
bigquery.SchemaField('TAG_NAME', 'STRING', mode='NULLABLE', description='タグ名称'),
]
)
]
実際にテーブルを作成する
スキーマを作成したら次はテーブルを実際に作成
スキーマ以外に検討しておくべき要素としては
- 分割テーブルにするか(日付2000日を超えるデータを入れる予定ならば分割テーブルにはしない方が良い)
- クラスターテーブルにするか(分割テーブルでしか適用できないので注意)
今回は分割&クラスターテーブルとしてテーブルを作成します
from google.cloud import bigquery
# project_id = 'YourProjectID'
# client = bigquery.Client(project=project_id)
# dataset_name = "demo"
# dataset_id = "{}.{}".format(client.project, dataset_name)
# テーブル名を決める
table_name = "demo_transaction"
table_id = "{}.{}.{}".format(client.project, dataset_id, table_name)
# スキーマは上で定義したものを利用
table = bigquery.Table(table_id, schema=schema)
# 分割テーブルの設定(ここではORDER_DT)
table.time_partitioning = bigquery.TimePartitioning(
type_=bigquery.TimePartitioningType.DAY,
field="ORDER_DT"
)
# クラスターテーブルの設定
table.clustering_fields = ["ITEM_CODE", "CUSTOMER_ID"]
table.description = "Demo Data"
# テーブル作成を実行
table = client.create_table(table)
Web上のコンソールで確認するとこんな感じで定義されていることが分かる
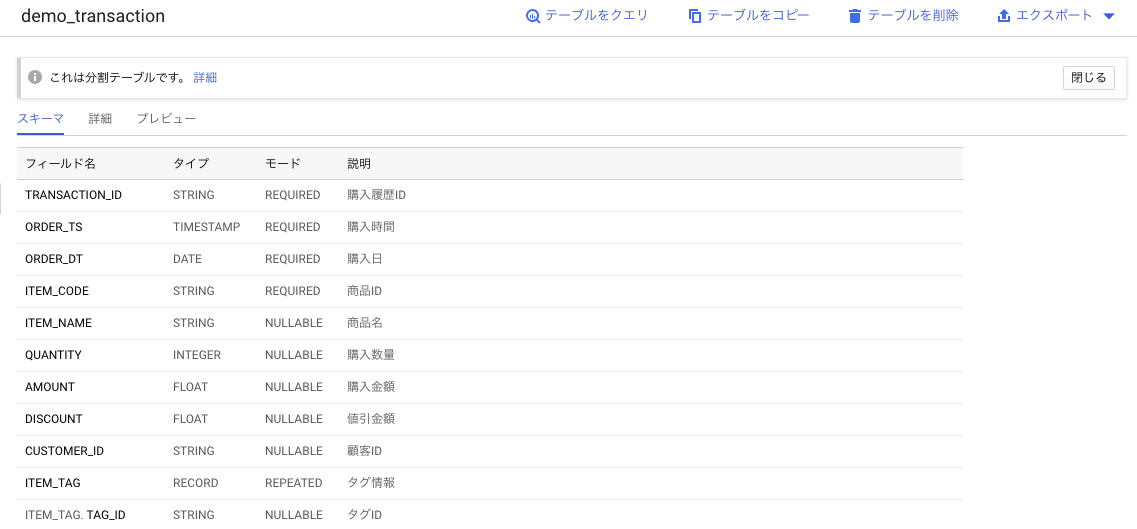
テーブル一覧確認
テーブルの一覧を確認するにはDataSet名を確定するか、もしくはDataSetオブジェクトを指定するか
で確認可能
# [demo]DataSetに入っているテーブルを確認する
# DataSet名を指定してテーブル名を確認するパターン
dataset_id = "demo"
for table in client.list_tables(dataset=dataset_id):
print(table.table_id)
# DataSetオブジェクトを指定して確認するパターン
dataset_object = client.get_dataset("demo")
for table in client.list_tables(dataset=dataset_object):
print(table.table_id)
テーブルへのデータロード
データサイエンティストはデータをImport/Exportを頻繁に繰り返すので、このあたりもちゃんと理解しておきたいところ
- ローカルファイルをImportする
- CSVを読み込む
- JSONを読み込む
- GCSファイルをImportする
ローカルファイルをImport
CSVでファイルを格納しているパターンとJSONで格納している2つのパターンを記載しておきます
CSVファイルを読み込む
CSVファイルでデータを保管していることはよくあると思うので、このパターンはフォローしておく。
ただし、ネストされたフィールドがあるテーブルではCSVでネストされた情報を表現できないので、CSVでは対応不可
ネストされた情報が含まれていないテーブル名をdemo_transacitonとしてロードしてみる
# ローカルファイルを指定
filename = 'demo_transaction.csv'
# データセット名
detaset_id = "demo"
# Importする対象のテーブル名
table_id = "demo_transaction_csv"
dataset_ref = client.dataset(dataset_id)
table_ref = dataset_ref.table(table_id)
# Importする上での設定
job_config = bigquery.LoadJobConfig()
# CSVがソースであることを指定
job_config.source_format = bigquery.SourceFormat.CSV
# ファイルにヘッダーが含まれている場合は一行目をスキップする
job_config.skip_leading_rows = 1
with open(filename, "rb") as source_file:
job = client.load_table_from_file(source_file, table_ref, job_config=job_config)
# 実行
job.result()
ちなみに何らかの理由でエラーになった場合は、job.errorsでエラーの中身を確認してロードし直してください
JSONファイルを読み込み
ネストされたデータを含むテーブルはjsonでImportします
jsonでImport可能な形式は決まっていて下記のように改行で1レコードを判断する形でデータが入っている必要がある
{"TRANSACTION_ID":"t0001","ORDER_TS":"2019-11-02 12:00:00 UTC","ORDER_DT":"2019-11-02","ITEM_CODE":"ITEM001","ITEM_NAME":"YYYYY1","QUANTITY":"29","AMOUNT":2200,"DISCOUNT":0,"CUSTOMER_ID":"F0002","ITEM_TAG":[{"TAG_ID":"XXX1", "TAG_NAME":"XYZ1"},{"TAG_ID":"XXX2", "TAG_NAME":"XYZ2"}]}
{"TRANSACTION_ID":"t0002","ORDER_TS":"2019-11-03 12:00:00 UTC","ORDER_DT":"2019-11-03","ITEM_CODE":"ITEM002","ITEM_NAME":"YYYYY2","QUANTITY":"35","AMOUNT":5700,"DISCOUNT":0,"CUSTOMER_ID":"F0002","ITEM_TAG":[]}
{"TRANSACTION_ID":"t0003","ORDER_TS":"2019-11-04 12:00:00 UTC","ORDER_DT":"2019-11-04","ITEM_CODE":"ITEM003","ITEM_NAME":"YYYYY3","QUANTITY":"48","AMOUNT":4200,"DISCOUNT":0,"CUSTOMER_ID":"F0002","ITEM_TAG":[{"TAG_ID":"XXX3", "TAG_NAME":"XYZ3"}]}
こういう状態でjson化されたデータがあった場合にローカルファイルはこうやってImportできる
# ローカルファイル名を指定
filename = 'demo_transaction.json'
# データセット名
detaset_id = "demo"
# ネスト情報ありのテーブル名
table_id = "demo_transaction"
dataset_ref = client.dataset(dataset_id)
table_ref = dataset_ref.table(table_id)
job_config = bigquery.LoadJobConfig()
# jsonが元ファイルであることを教えてあげる
job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON
with open(filename, "rb") as source_file:
job = client.load_table_from_file(source_file, table_ref, job_config=job_config)
# 実行
job.result()
ちなみにネストされたデータなので、コンソールで見るとこんな感じで見える
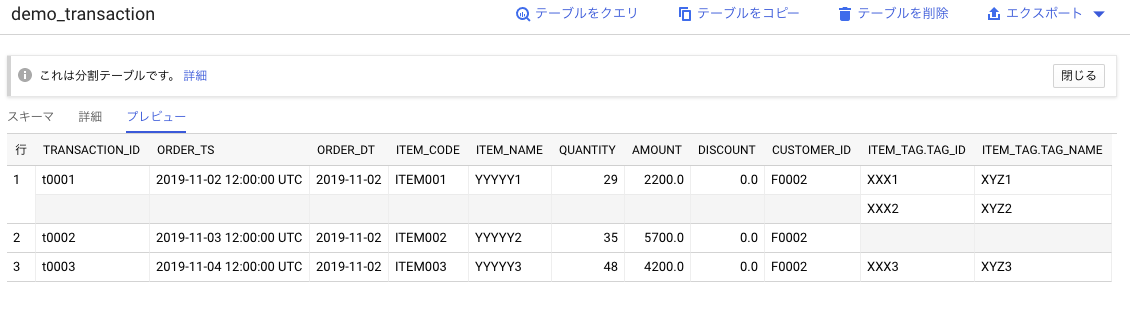
-参考-
gist:Google BigQuery の JSON投入を軽く試す
GCSファイルをImport
ローカルファイルでBigQueryにデータをImportすることもあるにはあるが、GCPを使っているのでGCSをフル活用した方が良い
ということで、GCSに置いてあるデータをImportする方法も確認しておく
GCSに格納してあるファイルのパスさえ把握しておけば、GCS関連のライブラリを呼び出す必要がないのは素敵
CSVファイルをdemo_transaction_csvテーブルにImportするのを想定した例↓
# データセット、テーブル名を指定
detaset_id = "demo"
table_id = "demo_transaction_csv"
dataset_ref = client.dataset(dataset_id)
table_ref = dataset_ref.table(table_id)
# CSVをロードするので諸々設定
job_config = bigquery.LoadJobConfig()
job_config.skip_leading_rows = 1
job_config.source_format = bigquery.SourceFormat.CSV
# GCSのファイルが置いてあるパスを指定
uri = "gs://{yourbacketname}/demo_transaction.csv"
# ジョブを生成
load_job = client.load_table_from_uri(
uri, table_ref, job_config=job_config
)
# ロードを実行
load_job.result()
(たぶん邪教)pandasの機能でDataFrameをBQに突っ込む
公式のAPIの機能ではないがpandas側の機能を使ってpd.DataFrameのデータをBigQueryのテーブルに挿入することもできる
既存のテーブルに追加で挿入することも出来るけど、どちからというと色々加工した後のDataFrameを新しいテーブルにして書き出す為に使う方が多い気がする
例として先ほど作成したdemo.demo_transaction_csvのデータを一部引っこ抜いて別のテーブルとして書き出してみる
# データの一部を取得するクエリを用意する
query = """
SELECT
TRANSACTION_ID
, ORDER_TS
, ITEM_CODE
, QUANTITY
, AMOUNT
FROM
`{YourProjectID}.demo.demo_transaction_csv`
LIMIT 200
;
"""
# クエリジョブを生成
query_job = client.query(
query, location='US'
)
# データフレームで結果を受け取る
df = query_job.to_dataframe()
# データフレームを[demo_transaciton_csv_extracted]の名前で書き出す
# if_exists:append -> すでにテーブルがあれば追記、なければ新規作成
# if_exists:fail -> すでにテーブルがあればFail、なければ新規作成
# if_exists:replace -> すでにテーブルがあれば置き換え、なければ新規作成
detaset_id = "demo"
table_id = "demo_transaciton_csv_extracted"
df.to_gbq(destination_table='{dataset}.{table}'.format(dataset=dataset_id, table=table_id),project_id=project_id, if_exists='append')
Importがうまくいっているかを一応確認しておく
detaset_id = "demo"
dataset_ref = client.dataset(dataset_id)
table_id = "demo_transaciton_csv_extracted"
table_ref = dataset_ref.table(table_id)
table = client.get_table(table_ref)
print("Table has {} rows".format(table.num_rows))
> Table has 200 rows
APIネイティブな機能でpd.DataFrameのデータをImport
邪法を先に書いてしまったが、APIでもDataFrameを入れることが可能
サンプルコードではSchemaを定義しているが無くても実行可能
import pandas as pd
detaset_id = "demo"
dataset_ref = client.dataset(dataset_id)
table_id = "demo_pandas_data"
table_ref = dataset_ref.table(table_id)
# 適当にpd.DataFrameデータを作成
rows = [
{"item_id": "xx1", "quantity": 1},
{"item_id": "xx2", "quantity": 2},
{"item_id": "xx3", "quantity": 3},
]
dataframe = pd.DataFrame(
rows,
columns=["item_id", "quantity"]
)
# スキーマを定義(無くてもImport出来るけど書いておいたほうが安全)
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField("item_id", "STRING"),
bigquery.SchemaField("quantity", "INTEGER"),
],
)
# pd.DataFrameデータをテーブルに格納する
job = client.load_table_from_dataframe(
dataframe,
table_ref,
job_config=job_config,
location="US",
)
# 実行
job.result()
既存のテーブルデータをImport
邪教的にDataFrameを介して既存のテーブルからデータを引っこ抜いて、新しいテーブルとして書き込んだけど、基本的には公式の機能で実装しておきたいところ
- APIの機能を使って既存のテーブルの情報を抜き出して新たに書き込む
- クエリで直接、新たに書き込む
APIネイティブな機能でクエリ結果を書き込む
APIの機能を使って書き込む場合は、QueryJobConfig.destinationに新たなテーブル名を指定してあげれば良いだけ
シンプル!!!
# ジョブコンフィグを生成
job_config = bigquery.QueryJobConfig()
detaset_id = "demo"
dataset_ref = client.dataset(dataset_id)
# 書き込み先のテーブル名を定義
table_id = "demo_transaciton_csv_direct_extracted"
table_ref = dataset_ref.table(table_id)
# (重要)書き込み先のテーブルを指定
job_config.destination = table_ref
# 書き込み対象のクエリを定義
query = """
SELECT
TRANSACTION_ID
, ORDER_TS
, ITEM_CODE
, QUANTITY
, AMOUNT
FROM
`{YourProjectID}.demo.demo_transaction_csv`
LIMIT 300
;
"""
# クエリジョブを生成
query_job = client.query(
query,
location="US",
job_config=job_config,
)
# 実行
query_job.result()
クエリ(CREATE TABLE [TABLE_NAME] AS SELECT)で作るパターン
QueryJobConfig.destinationで新規テーブルを定義するパターンで十分な気もするが、お馴染みの方法(CREATE TABLE ~ AS SELECT)もフォローしておく。
結局、意外と使うし。。。
detaset_id = "demo"
# 書き込み先のテーブル名を定義
table_id = "demo_transaciton_csv_as_select"
# 書き込み対象のクエリを定義
query = """
DROP TABLE IF EXISTS {dataset}.{table} ;
CREATE TABLE {dataset}.{table} AS
SELECT
TRANSACTION_ID
, ORDER_TS
, ITEM_CODE
, QUANTITY
, AMOUNT
FROM
`{YourProjectID}.demo.demo_transaction_csv`
LIMIT 400
;
""".format(dataset=dataset_id, table=table_id)
# クエリジョブを生成
job_config = bigquery.QueryJobConfig()
query_job = client.query(
query,
location="US",
job_config=job_config,
)
# 実行(もちろん何も返ってこないけどちゃんと書き込まれている)
query_job.result()
これで一通り、データをImportする方法は網羅したはず。。。
分割テーブルの作成
BigQueryは列単位の従量課金形態なので、
-
Limitを設定しても課金額は変わらない -
Whereで条件を絞っても課金額は変わらない - 列(カラム)を増やすごとに課金されていく
というサービス上の特徴がある
データボリュームが小さいうちはどうでも良いことなのだけれど(月あたり1TBはクエリ無料なので)、数十TB以上のデータを扱う場合にはそれなりに気を使う必要が出てくる
じゃあ、どうするのが良いかというと
- 分割テーブルを設定する
- クラスタテーブルを設定する
が基本的な対処方法となる
数TBデータがあるようなテーブルには必ず何らかの時系列情報が含まれるはずなので、その情報を分割対象のフィールドとして設定して分割テーブルを作成する
なお、分割テーブルとしてテーブル作成時に定義しておかないとあとで変更は出来ないので注意
-参考-
パーティション分割テーブルの概要
テーブル定義に分割オプションを入れるパターン
まずは、テーブルを作成する段階で分割オプションを設定するパターンを記載しておく
# テーブル定義を記述(時系列カラムは必須)
schema = [
bigquery.SchemaField('TRANSACTION_ID', 'STRING', mode='REQUIRED', description='購入履歴ID'),
bigquery.SchemaField('ORDER_TS', 'TIMESTAMP', mode='REQUIRED', description='購入時間'),
bigquery.SchemaField('ORDER_DT', 'DATE', mode='REQUIRED', description='購入日'),
]
detaset_id = "demo"
table_id = "demo_transaction_time_partition1"
dataset_ref = client.dataset(dataset_id)
table_ref = dataset_ref.table(table_id)
# Tableオブジェクト生成
table = bigquery.Table(table_ref, schema=schema)
# 分割オプションを設定する
table.time_partitioning = bigquery.TimePartitioning(
# 日単位で分割
type_=bigquery.TimePartitioningType.DAY,
# 対象のフィールドを設定
field="ORDER_DT"
)
table.description = "Time Partition Data"
# 分割テーブルを作成
table = client.create_table(table)
クエリ(CREATE TABLE [TABLE_NAME] AS SELECT)で作るパターン
既存のテーブルからCREATE TABLE [TABLE_NAME] AS SELECTでも分割テーブルは作成可能
一番の使いどころは、分割テーブルとして設定してないのに肥大化してしまったテーブルを作り直す場合
AS SELECTの前にPARTITION BY [Time Partition Field]を入れればOK
detaset_id = "demo"
# 書き込み先のテーブル名を定義
table_id = "demo_transaciton_csv_as_select_time_partition"
query = """
DROP TABLE IF EXISTS {dataset}.{table} ;
CREATE TABLE {dataset}.{table}
PARTITION BY
ORDER_DT
AS
SELECT
TRANSACTION_ID
, ORDER_TS
, ORDER_DT
, ITEM_CODE
, QUANTITY
, AMOUNT
FROM
`{YourProjectID}.demo.demo_transaction_csv`
LIMIT 500
;
""".format(dataset=dataset_id, table=table_id)
# クエリジョブを生成
query_job = client.query(
query,
location="US"
)
# 実行
query_job.result()
簡単!!
クラスタテーブルの作成
分割テーブルにはさらにクラスタフィールドを設定できる
分割テーブルのオプションにクラスタフィールドを指定するだけなので、抜粋して記載
-参考-
クラスタ化テーブルの作成と使用
クラスターオプションを設定するとどんな効果があるかは以下を参考にしてください
テーブル定義にクラスタオプションを入れるパターン
"""クラスタテーブルは分割テーブルである必要がある
table = bigquery.Table(table_ref, schema=schema)
table.time_partitioning = bigquery.TimePartitioning(
type_=bigquery.TimePartitioningType.DAY,
field="ORDER_DT"
)
"""
table.clustering_fields = ["ITEM_CODE", "CUSTOMER_ID"]
クエリ(CREATE TABLE [TABLE_NAME] AS SELECT)で作るパターン
SQLで指定する場合もクラスタオプションCLUSTER BYを追加するだけ
query =
"""
DROP TABLE IF EXISTS {dataset}.{table} ;
CREATE TABLE {dataset}.{table}
PARTITION BY
ORDER_DT
CLUSTER BY
ITEM_CODE, CUSTOMER_ID
AS
SELECT
*
FROM
`{YourProjectID}.demo.demo_transaction_csv`
LIMIT 500
;
""".format(dataset=dataset_id, table=table_id)
テーブルのデータをExport
ふぅ。。。ようやく、データを入れる部分が終わった。。。
次はExportの部分ですが、テーブルそのものをExportする方法はGCSに吐き出すのが基本
GCSにExport
テーブルの中身をGCSのバケットを指定して書き出す
特にjob_configを指定しなければcsvファイルとして書き出される
通常はcsvになるので、ネストされたカラムを含むテーブルはcsvでは書き出せない
# 書き出し対象のテーブルを指定
detaset_id = "demo"
dataset_ref = client.dataset(dataset_id)
table_id = "demo_transaciton_csv"
table_ref = dataset_ref.table(table_id)
# 指定バケットにファイルを格納
bucket_name = "{Your Bucket Name}"
output_name = "{}.csv".format(table_id)
destination_uri = "gs://{}/{}".format(bucket_name, output_name)
# 書き出しジョブを生成
extract_job = client.extract_table(
table_ref,
destination_uri,
location="US",
)
# 実行
extract_job.result()
ファイルを圧縮してExport
テーブルをそのままExportするとそれなりにデータ量が大きくなってしまうので、圧縮オプションは設定しておきたい
ExtractJobConfigで出力のオプションを設定して圧縮する
print_headerオプションを設定するとヘッダーを書き出すか否かを制御可能(デフォルトはTrue)
destination_uri = "gs://{YourBucket}/{filename}.gz"
job_config = bigquery.ExtractJobConfig(
compression="GZIP",
print_header=True
)
# 書き出しジョブを生成
extract_job = client.extract_table(
table_ref,
destination_uri,
job_config=job_config,
location="US",
)
# 実行
extract_job.result()
ネストされたデータを含むテーブルをjson(avro)でExport
ネストされたカラムがある場合はcsvでは書き出せないのでjsonもしくはavroで書き出す
jsonならば圧縮可能だが、avroは圧縮オプションはサポートされていない
output_name = "{}.json".format(table_id)
destination_uri = "gs://{}/{}".format(bucket_name, output_name)
# jsonで書き出す(ヘッダーは出力しない)
job_config = bigquery.ExtractJobConfig(
destination_format = "NEWLINE_DELIMITED_JSON",
print_header = False
)
# 実行
extract_job = client.extract_table(
table_ref,
destination_uri,
job_config=job_config,
)
extract_job.result()
tsvでExport
ちなみにデフォルトはcsvだが、tsvでも書き出し可能
# job_configにデリミタオプションを加える
job_config = bigquery.ExtractJobConfig(
field_delimiter="\t"
)
テーブルの削除
テーブルを削除したい場合は、テーブル名を指定するだけでOK
# from google.cloud import bigquery
# project_id = 'YourProjectID'
# client = bigquery.Client(project=project_id)
detaset_id = "{YourDataSetId}"
dataset_ref = client.dataset(dataset_id)
table_id = "{YourTableId}"
table_ref = dataset_ref.table(table_id)
# テーブルの削除
client.delete_table(table_ref)
テーブル作成周りの話は一旦これでおしまい