はじめに
前回は、Mac miniとClaudeの /remote-control を使って「手ぶらで研究室に通う」環境構築について書きました。物理的な環境が整った次にこだわるべきは、やはりCLI環境でのAIの拡張です。
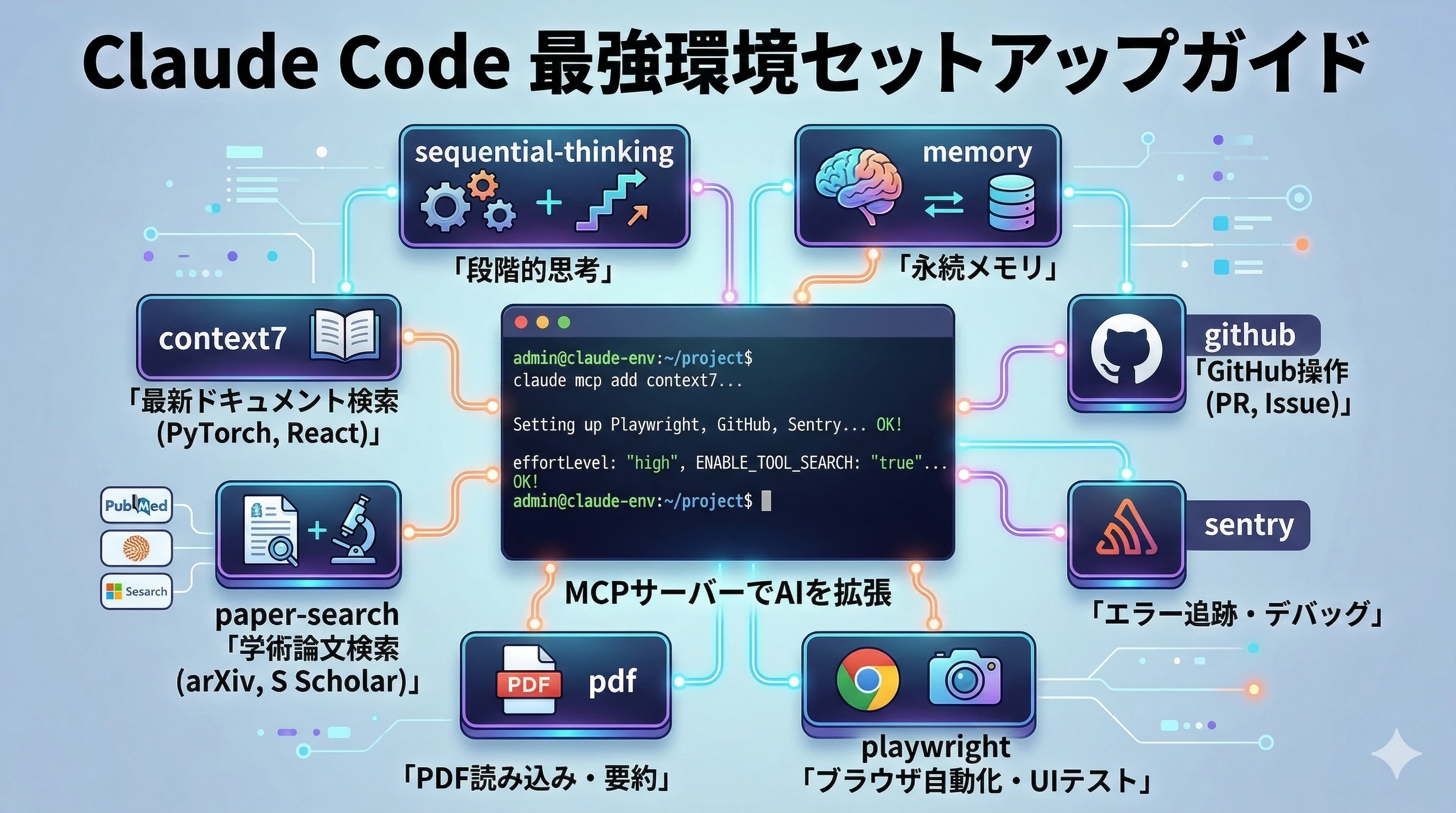
最近はターミナル上で動く Claude Code をメインに使用しています。単体でも強力ですが、MCP(Model Context Protocol)サーバーを追加することで、最新のドキュメント検索、論文調査、ブラウザ自動化などをAIに直接委譲できるようになります。
今回は、私が実際に日々の研究やアプリ開発の環境に導入している「最強MCPサーバー構成」と、その一括セットアップ方法をまとめました。
前提条件
以下のツールがインストールされている環境を想定しています。
- Node.js (v18+)
-
npxコマンド - GitHub CLI (
gh) ※gh auth loginで認証済みであること
1. グローバルMCPサーバー(全プロジェクト共通)
まずは、どのディレクトリにいても呼び出せるようにしたい「汎用的な拡張機能」をグローバルに登録します。ターミナルで以下のコマンドを順に実行するだけでセットアップが完了します。
# context7 - ライブラリドキュメント検索(PyTorch, React 等の最新ドキュメントをリアルタイム取得)
claude mcp add context7 -s user -- npx -y @upstash/context7-mcp
# paper-search - 論文検索(arXiv, Semantic Scholar, PubMed 等 14ソースから学術論文を検索)
claude mcp add paper-search -s user -- npx -y paper-search-mcp-nodejs
# pdf - PDF読み込み・テキスト抽出
claude mcp add pdf -s user -- npx -y @modelcontextprotocol/server-pdf --stdio
# memory - ナレッジグラフベースの永続メモリ(セッション間で知識を保持)
claude mcp add memory -s user -- npx -y @modelcontextprotocol/server-memory
# sequential-thinking - 段階的思考・問題分解(複雑な問題を構造化して解く)
claude mcp add sequential-thinking -s user -- npx -y @modelcontextprotocol/server-sequential-thinking
実践的なユースケース
-
paper-search+pdf: トップカンファレンス向けの論文執筆時や、査読フェーズでの追加検証などで絶大な威力を発揮します。arXiv等から関連研究を検索させ、そのままPDFを読み込んで要約や比較を行わせることがターミナル上で完結します。 -
context7: VLM(Vision-Language Model)の実装などでPyTorchの最新仕様を確認したり、アプリ開発でReactの最新ドキュメントを参照したい時に、ハルシネーションを防ぎつつ正確なコードを書かせることができます。 -
memory+sequential-thinking: 長期的なプロジェクトの文脈や、複雑なアルゴリズムの思考プロセスをClaudeに保持・整理させたい時に重宝します。
2. プロジェクトレベルMCPサーバー(.mcp.json)
次に、特定のアプリ開発プロジェクトなどでリポジトリごとに適用したいMCPです。
プロジェクトのルートディレクトリに .mcp.json というファイルを作成し、以下の内容を記述します。(このファイルはGitにコミットしてチームで共有可能です)
{
"mcpServers": {
"playwright": {
"type": "stdio",
"command": "npx",
"args": ["-y", "@playwright/mcp@latest", "--browser", "chromium"],
"env": {}
},
"github": {
"type": "http",
"url": "[https://api.githubcopilot.com/mcp/](https://api.githubcopilot.com/mcp/)"
},
"sentry": {
"type": "http",
"url": "[https://mcp.sentry.dev/mcp](https://mcp.sentry.dev/mcp)"
}
}
}
各サーバーの役割
- playwright: ブラウザの自動操作。WebスクレイピングやUIのE2Eテスト、画面のスクリーンショット取得などをClaudeに指示できます。
- github: PRの作成、Issueの管理、コードレビューなどをMCP経由で直接実行します。
- sentry: エラー追跡。Sentryのエラーやパフォーマンスデータを直接参照し、バグ修正の文脈をAIに与えます。
💡 Playwrightの追加セットアップ
初回使用時はブラウザの実体が必要です。Claude Code内で自動インストールされますが、システム依存パッケージが不足する場合は手動で以下を実行してください。
sudo npx playwright install-deps chromium
3. Claude Code自体の設定チューニング
最後に、Claude Code自体のパフォーマンスを最大化するために、~/.claude/settings.json を編集します。
{
"effortLevel": "high",
"env": {
"ENABLE_TOOL_SEARCH": "true"
}
}
-
effortLevel: "high": Claudeの推論リソースを最大化し、より深く考えて回答させます。複雑な実装や論文の考察時に必須です。 -
ENABLE_TOOL_SEARCH: "true": Tool Search機能を有効化。必要なツール(MCP)を動的に検索・遅延ロードできるようになり、Claude Codeの起動や動作が高速化されます。
まとめ:セットアップ完了までのステップ
最後に、全体の導入手順を振り返ります。
- グローバル登録: ターミナルでセクション1のコマンドを実行
-
プロジェクト設定: 開発ディレクトリに
.mcp.jsonを配置 -
Claude Code設定:
~/.claude/settings.jsonを編集 -
認証の完了:
-
gh auth loginでGitHubにログイン - Claude Code起動時に表示されるGitHub/SentryのOAuth認証を完了させる
-
- Claude Codeの再起動: 全てのサーバー接続を確認して完了!
研究のリサーチから論文の構成、そしてアプリケーションの開発・テストまで、これらのMCPサーバー群を導入することで、Claude Codeが文字通り「最強のアシスタント」に化けます。ぜひ皆さんの環境でも試してみてください!