これは何?
Sidekiqには同時実行数のパラメータconcurrencyがあるため、それをどのようにセットするべきか決める必要があります。
これは、Ruby on Rails 7でSidekiq v7のconcurrencyのチューニングに必要な情報を事前調査してまとめたものです。
Sidekiq v6はこちら => Sidekiq v6チューニングのためのパラメータ整理
結論
-
Active Recordのpool値 - 1 = concurrency <= 50とします-
config/database.ymlのpoolをconcurrency + 1にします
-
- 最初から水平スケーリング(プロセス数増加)できるアーキテクチャとしておきたいです
- 要求されるスループットのジョブを回してパフォーマンスを測定して決めます。理論的にはアムダールの法則やUniversal Scalability Lawを使って効果が飽和する手前の並列度を見積もるなどの定量的な手法もあります。
アーキテクチャ概要
プロセスとキュー、スレッドの関係は、Sidekiq v7から導入された Capsules(カプセル)機能によって、仕様変更があります。
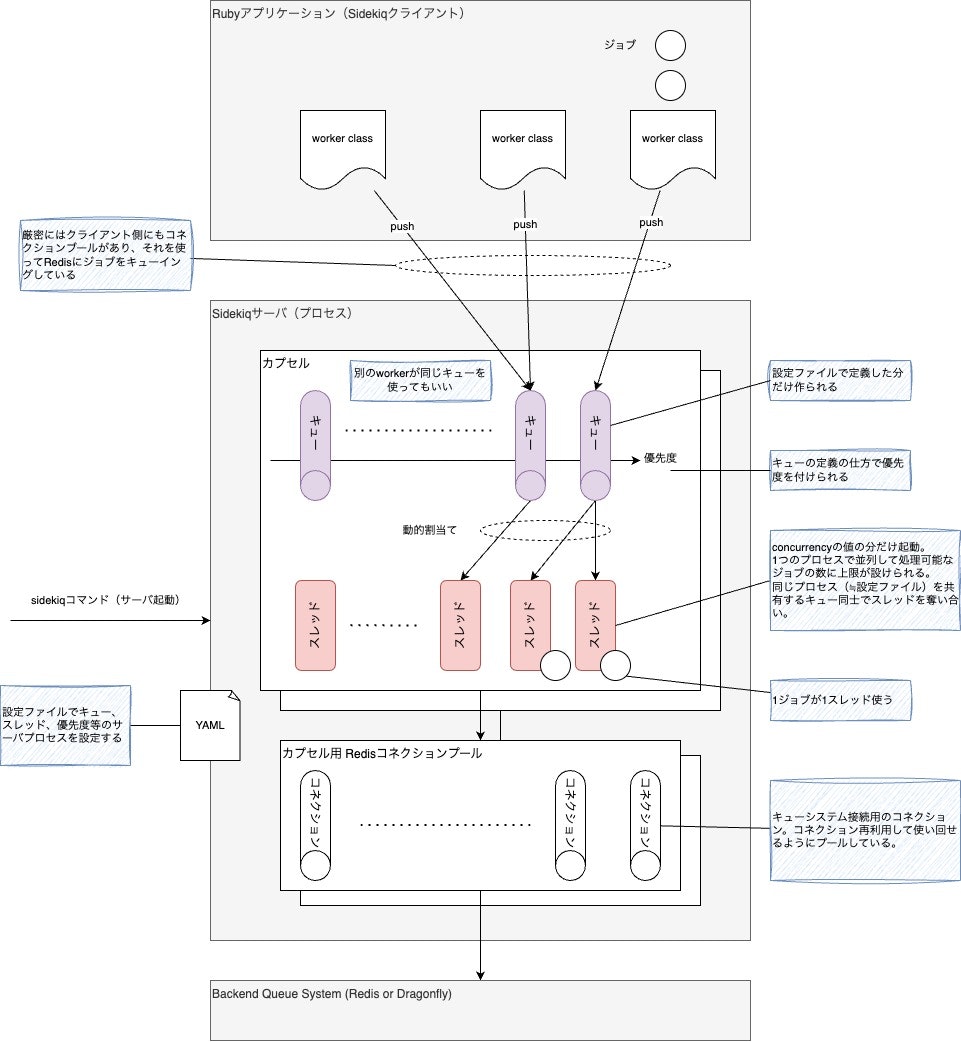
キューとスレッドの割り当て関係は、v7で導入されたカプセルによって指定できるようになりました。ただし、想定できる最も柔軟な設定よりは制約があり、大半のユースケースにおいては、1キューあたりの並列度は指定できないと考えた方がいいです。つまり、プロセス全体の並列度(concurrency)のみ指定するのが通常となります。
もう少し柔軟な設定とするには、sidekiq-throttledの利用を検討ください。
Capsules(カプセル)
カプセルはキューを処理するのに必要なリソース(キュー、concurrency、Redisコネクションプール、エラーハンドラ、Sidekiqミドルウェアチェーン)をまとめたものです。
デフォルトでは、Sidekiq::Capsuleインスタンスが1つ作成され、設定やコマンド引数に応じてインスタンスが更新されます。
concurrency
- 公式の説明
- 1つのSidekiqプロセスまたはカプセルで使用するスレッド数
- デフォルト値: 5
502 13124 775 0 7:10PM ttys008 0:02.79 sidekiq 7.3.0 app-name [0 of 5 busy]
- 推奨は50以下と書いてるが、結局はそれぞれの環境で検証してね。というスタンスっぽいです。
- 各SidekiqスレッドでDB接続することを想定して、Active Recordコネクションプールサイズ(config/database.yml内のpoolの値)とセットでチューニングが必要です。「ActiveJobでsidekiqを使う場合、connection_poolの値はconcurrency + 1以上にしよう」によれば、
conccurency = Active Recordコネクションプールサイズ - 1としておいた方が安心です。
スレッド
Sidekiqではジョブ処理ごとに1スレッドを使用しています。
ソースコードレベルでは未確認ですが、ジョブ作成する度にps結果のbusyの数が増えていったためです。
実際の並列処理はCPUスペックに依存します。
コネクションプール
Sidekiqの文脈で言うコネクションプールはRedisコネクションプールのことで、Active Recordのものではありません。
ただし、Sidekiqプロセス内でActive Recordを利用すると、SidekiqプロセスからDB接続するためのActive Recordコネクションプールを利用します。なので、Sidekiqのconcurrencyとそれらのプールサイズは密接な関係があります。
Redisコネクションプールとconnection_pool gem
- このgemはSidekiqがRedisのコネクションをプーリングするために使用します。
- 自分で制御したい場合は、
config/initilizers/sidekiq.rbにこう書きます。 - コンストラクタに指定するsizeはプールするコネクション数。
- Sidekiq内で以下のように使用されます(ソースコード)
module Sidekiq
class RedisConnection
class << self
def create(options = {})
# ...
redis_config = Sidekiq::RedisClientAdapter.new(symbolized_options)
ConnectionPool.new(timeout: pool_timeout, size: size, name: pool_name) do
redis_config.new_client
end
end
end
end
end
Active Recordコネクションプール
- 『データベース接続をプールする』
- 『Concurrency and Database Connections in Ruby with ActiveRecord (Heroku)』
- 『ActiveJobでsidekiqを使う場合、connection_poolの値はconcurrency + 1以上にしよう』
- Rails 7.1以下でmysqlを使うとデフォルトでこうなっています
ENV.fetch("RAILS_MAX_THREADS") { 5 }- ソースコード
拡張性
拡張可能な変数としては以下のとおりです。
- スレッド(concurrency)
- ワーカー
- キュー
- プロセス
- Redisコネクションプールサイズ
スレッド(concurrency)
- 1プロセスで50スレッド以下にした方がよいとの公式見解のため、少し余裕をもった値にしつつ、50に近づいたらプロセスを増やします(スケールアウトします)
- 個人的には50も多過ぎると思うので、ビタビタに攻めるよりは最初から水平スケーリングできるようにしたいです
- もちろん、CPUスペックやDB負荷を気にして効率の良い数を決めます
- 起点としては、APMツールなどでI/O待ち時間の割合を測定しアムダールの法則を適用したり、異なる並列度での実験値をUniversal Scalability Lawを使ってフィッティングするなどして、効果が飽和する手前の並列度を見積もるなどの定量的な手法もあります
ワーカー
- まずは非機能要件からではなく、仕事内容に応じてワーカーを定義していきます。1つのワーカーの責務が大きくなったら、処理ワークフローを再考してワーカーの分割を検討します。
- 仕事内容は、引数で受け取るリソース、リトライ範囲、順序や一貫性を保証したい範囲など、非機能要件側からも境界を決めていきます。
- 非同期なワーカーが増える場合、ワーカー同士の依存関係を主としてシステムの複雑度が上がってないかチェックしたいです。また、業務自体が複雑化しているシグナルと捉え、業務見直しのチェックポイントを最初から考慮しておくと拡張しやすくなります。
キュー
- 待ち行列となる(待つことになる、FIFOになる)ことを考慮して、キューの分割を考慮します。例えば、頻度が少ないが来たらすぐに処理したいワーカーには専用のキューを用意し、その優先度を上げるようにします。
- 平均処理時間の異なる2つのワーカーは別キューに分けます。なぜなら、同じ優先度の異なるキューに入れば、それぞれから1つずつ処理してくれることになり、短時間タスクが長時間タスクによって待たされることが減るからです。
- なお、優先キューを作ることは処理順序に影響をもたらし、そのワーカーの仕事内容によっては許容されないケースもあるかも知れないので注意です。例えば、1日の中では順序非依存でも、日付の前後が入れ替わる処理順では困る場合です。意外と簡単に既存仕様を破壊しかねないので気を付けたいです。
プロセス
- キューごとの並列度、言い換えればワーカーごとの並列度はSidekiq単体では指定できないと考えたほうがいいです。カプセル機能が導入されましたが、その柔軟性は低く、多くのユースケースではv6以前同様にconcurrencyをプロセス全体で共有する設定になります。よって、キューごとに別々の並列度を指定したい場合は、別プロセスに分割するか、sidekiq-throttledを導入することも検討します。
- concurrencyが上限に近づくか、レイテンシーの頭打ちとなったらプロセスをスケールアウトします。
- 最近はコンテナ単価も安いので、concurrency頑張るより水平スケーリングさせるのがいいです。
- プロセスを増やすとDBコネクション含めて外部リソース利用も増えるため、限界値を見積もって将来に備えます。
Redisコネクションプールサイズ
- 特別チューニングする必要はありません。
- concurrencyよりも多く準備する必要があるが、デフォルトでconcurrencyと同数のコネクションが確保されるようになっています。