ご挨拶
ご無沙汰しております!
所属が変わったため、改めて自己紹介します。
燈株式会社でアルゴリズムエンジニアをしている、自認プーさんの秋田と言います!(わいわい)
それでは本題へ、どうぞ!
目的
この記事がフォーカスするのは、
- 量子機械学習(量子ニューラルネットワーク)を Qiskit で簡単に実装する
というところにあります。
そもそもの「量子機械学習ってなんぞや?」や、「それぞれのモジュールについて詳しい解説を求む」というのはスコープ外ですので、あくまでも実験等で Qiskit ベースの QNN を簡単に使えるようにすることにだけフォーカスしていきます!
PyTorch
軽く PyTorch についても触れていきます。
何をするライブラリ?
深層学習(ディープラーニング)の要である「ニューラルネットワーク」のモジュールを多数兼ね備えており、これらを駆使してオリジナルのモデルを作成・学習させることができます!
例えばこんな感じで!
import torch
from torch import nn
class MyModel(nn.Module):
def __init__(self):
# 親クラスのコンストラクタを呼び出す
super(MyModel, self).__init__()
# ネットワークの構築
self.model = nn.Sequential(
nn.Linear(13, 32),
nn.ReLU(),
nn.Linear(32, 16),
nn.ReLU(),
nn.Linear(16, 3)
)
# 出力層の活性化関数として Softmax 関数を使用
self.softmax = nn.Softmax(dim=1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
x: torch.Tensor
入力データに対する予測結果
"""
# 順伝播の計算
x = self.model(x)
# Softmax 関数を適用
x = self.softmax(x)
return x
なぜ PyTorch なの?
ディープラーニング系のライブラリは多くあります。
TensorFlow や JAX などなど。
結論から言うと、 Qiskit の機械学習用のサブモジュール(Qiskit Machine Learning)が QNN 用に提供しているパイプラインが PyTorch 依存であるからです。
...なんか、しょーもない理由で申し訳ございません🙇♂️
しかし、私自身ずっとディープラーニングは PyTorch ベースでの実装を行なっていたこともあり、慣れると使いやすいということももちろんあります!
実行環境
Python に限らずですが、こういうのをやる時の障害として1番目に出てくるのが「環境構築」でしょう...。
ということで、みなさんが簡単にできるように、今回も Google Colaboratory を使ってやってみましょう!
Google Colaboratory
使い方の説明は省きますが、以下の点でこれを選んでいるということはご理解ください!
- Google アカウントがあれば誰でも面倒な構築をすることなく使える
- Jupyter Notebook のスタイルなので、セルごとの実行も可視化も簡単にできる
インストール
Qiskit 系のライブラリはデフォルトで入っていないので、1番最初のセルに以下のコードを書いてそのまま実行してください!
!pip install qiskit qiskit-machine-learning pylatexenc
入れたのは3つで、
-
qiskit(2.3.0) -
qiskit-machine-learning(0.9.0) -
pylatexenc(2.10)
になります(カッコ内は自分が実行した段階でのバージョンになります)。
最後の pylatexenc は、 Qiskit の量子回路を描画する上で必要なものではありますが、今回は特に無くても問題ないです!
結論
先に結論から言うと、以下のようなクラスを作成すると完成になります!
Estimator
class QEstimator(nn.Module):
def __init__(
self, qcs: list[QuantumCircuit], seed: int,
observables: list[SparsePauliOp]
):
# 親クラスのコンストラクタを呼び出す
super(QEstimator, self).__init__()
# 量子回路のリストを取得
self.qc = qcs[0]
self.feature_map = qcs[1]
self.ansatz = qcs[2]
# 量子層の定義
self.qnn_est = self.set_estimator(seed, observables)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 量子層の順伝播計算
out = self.qnn_est(x)
return out
def set_estimator(
self, seed: int, observables: list[SparsePauliOp]
) -> TorchConnector:
"""
Estimator の QNN を用意する関数
Parameters
----------
seed: int
乱数シード値
observables: list[SparsePauliOp]
observable のリスト
Returns
----------
qnn: TorchConnector
Estimator の QNN 層
"""
# Estimator のインスタンスを用意
estimator = Estimator(seed=seed)
# QNN をセットアップ
qnn_base = EstimatorQNN(
circuit=self.qc,
estimator=estimator,
observables=observables,
input_params=self.feature_map.parameters,
weight_params=self.ansatz.parameters
)
initial_weights = 0.01 * (
2 * algorithm_globals.random.random(qnn_base.num_weights) - 1
)
qnn = TorchConnector(qnn_base, initial_weights=initial_weights)
return qnn
Sampler
class QSampler(nn.Module):
def __init__(
self, qcs: list[QuantumCircuit], seed: int, output_dim: int
):
# 親クラスのコンストラクタを呼び出す
super(QSampler, self).__init__()
# 量子回路のリストを取得
self.qc = qcs[0]
self.feature_map = qcs[1]
self.ansatz = qcs[2]
# 量子層の出力次元を設定
self.output_dim = output_dim
# 量子層の定義
self.qnn_sam = self.set_sampler(seed)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 量子層の順伝播計算
out = self.qnn_sam(x)
return out
def set_sampler(self, seed: int) -> TorchConnector:
"""
Sampler の QNN を用意する関数
Parameters
----------
seed: int
乱数シード値
Returns
----------
qnn: TorchConnector
Sampler の QNN 層
"""
# Sampler のインスタンスを用意
sampler = Sampler(seed=seed)
# QNN をセットアップ
qnn_base = SamplerQNN(
circuit=self.qc,
sampler=sampler,
input_params=self.feature_map.parameters,
weight_params=self.ansatz.parameters,
output_shape=self.output_dim
)
initial_weights = 0.01 * (
2 * algorithm_globals.random.random(qnn_base.num_weights) - 1
)
qnn = TorchConnector(qnn_base, initial_weights=initial_weights)
return qnn
QNN 層
class QuantumNeuralNetwork(nn.Module):
def __init__(
self, input_dim: int, num_reuploads: int,
net_type: Literal["Estimator", "Sampler"], seed: int,
feature_map_reps: int = 1, ansatz_reps: int = 1,
observables: Optional[list[SparsePauliOp]] = None,
output_dim: Optional[int] = None
):
# 親クラスのコンストラクタを呼び出す
super(QuantumNeuralNetwork, self).__init__()
# 入出力層の次元を設定
self.input_dim = input_dim
if net_type == "Sampler" and output_dim is not None:
self.output_dim = output_dim
# 量子回路を設計
qcs = self.build_reuploading_circuit(
self.input_dim, num_reuploads, feature_map_reps, ansatz_reps
)
self.qc = qcs[0]
self.feature_map = qcs[1]
self.ansatz = qcs[2]
self.qcs = [self.qc, self.feature_map, self.ansatz]
# observable を定義
if net_type == "Estimator" and observables is not None:
self.observables = observables
# QNN を構築
if net_type == "Estimator":
self.qnn = QEstimator(self.qcs, seed, self.observables)
elif net_type == "Sampler":
self.qnn = QSampler(self.qcs, seed, self.output_dim)
else:
pass
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 量子層の順伝播計算
out = self.qnn(x)
return out
def build_reuploading_circuit(
self, num_qubits: int, num_reuploads: int,
feature_map_reps: int = 1, ansatz_reps: int = 1
) -> list[QuantumCircuit]:
"""
QNN 用の量子回路を設計する関数
Parameters
----------
num_qubits: int
量子ビット数
num_reuploads: int
Re-Upload の回数
feature_map_reps: int = 1
特徴マップのリピート数
ansatz_reps: int = 1
ansatz のリピート数
Returns
----------
out: list[QuantumCircuit]
量子回路のリスト
"""
# 量子回路を初期化
qc = QuantumCircuit(num_qubits)
# 特徴マップと ansatz の定義
feature_map = zz_feature_map(num_qubits, reps=feature_map_reps)
ansatz = real_amplitudes(
num_qubits, entanglement="linear", reps=ansatz_reps
)
# Re-Upload
for _ in range(num_reuploads):
qc.compose(feature_map, inplace=True)
qc.compose(ansatz, inplace=True)
# 量子回路をまとめてリスト化
out = [qc, feature_map, ansatz]
return out
使い方
# ニューラルネットワーク全体像(Estimator を使用することを想定)
class MyModel(nn.Module):
def __init__(
self, input_dim: int, quantum_input_dim: int, output_dim: int,
num_reuploads: int, seed: int, observables: list[SparsePauliOp]
):
# 親クラスのコンストラクタを呼び出す
super(MyModel, self).__init__()
# 各層次元設定
self.input_dim = input_dim
self.quantum_input_dim = quantum_input_dim
self.output_dim = output_dim
# observables の定義
self.observables = observables
# 入力層の定義
self.linear_in = nn.Linear(self.input_dim, self.quantum_input_dim)
# 量子層の定義
self.estimator = QuantumNeuralNetwork(
self.quantum_input_dim, num_reuploads, net_type="Estimator", seed,
observables=self.observables
)
# 出力層の定義
self.linear_out = nn.Linear(len(self.observables), self.output_dim)
# 活性化関数の定義
self.tanh = nn.Tanh()
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 入力層の順伝播計算
h = self.linear_in(x)
h = self.tanh(h)
# 量子層の順伝播計算
q_out = self.estimator(h)
# 出力層の順伝播計算
out = self.linear_out(q_out)
return out
詳細
これだけじゃ何がなんだかわかりませんよね。
順を追って説明します。
Estimator?Sampler?
まず、 Qiskit には Estimator という機能と Sampler という機能の2種類が存在します。
-
Estimator- 量子回路に対して「物理量(期待値)」を計算するもの
- 量子回路と Observable (ハミルトニアンなど)を与えて期待値 $\langle \psi | O | \psi \rangle$ を返す
- 典型的な用途
- QNN の損失関数評価
- VQE
- 量子化学・最適化
-
Sampler- 量子回路を実行して「測定結果の分布」を返すもの
- 量子回路を実行して ビット列の出現確率を返す
- 典型的な用途
- QAOA のビット列サンプリング
- 回路の挙動確認
- 分類やサンプリング系アルゴリズム
基本的には、 QNN に使用するのは Estimator で良いと考えて大丈夫です。
アルゴリズムの探索や、「実はこういうケースでは Sampler を使った方が表現力が増すのでは?」みたいな実験を行いたい場合に関しては、 Sampler を使ってみるのも面白いかもしれないですね!
QNN の文脈では、量子回路の入力はデータの次元数に対応するので、説明変数の数だけの量子ビットを使うことになります。
しかし、 Estimator と Sampler では出力するものが上記より根本的に異なるので、以下の注意が必要です。
-
Estimator- 出力次元は基本的には $1$
-
observablesを与えてあげることで、出力次元をコントロールできる
-
Sampler- 出力次元は基本的には $2^n$ (ただし $n$ は入力次元)
-
output_shapeを与えてあげることで、出力次元をコントロールできる
Sampler 用のクラスを設計し、どちらも選択できるモジュールにはしますが、今回は素直に Estimator を使ってみることにしましょう!
具体的な設計
Estimator も Sampler も流れとしてはほとんど同じなので、ここでまとめて整理してみましょう。
まず、1番最初にやらなければいけないことは量子回路の設計です。
基本的な量子回路の設計方法については割愛しますが、わからない場合は筆者の過去の記事(Qiskitを使った量子最適化アルゴリズムの応用へ 〜パート1 量子計算の基礎〜)を参照いただければと思います!
量子回路
QNN で基本とされている構成は以下の通りです。
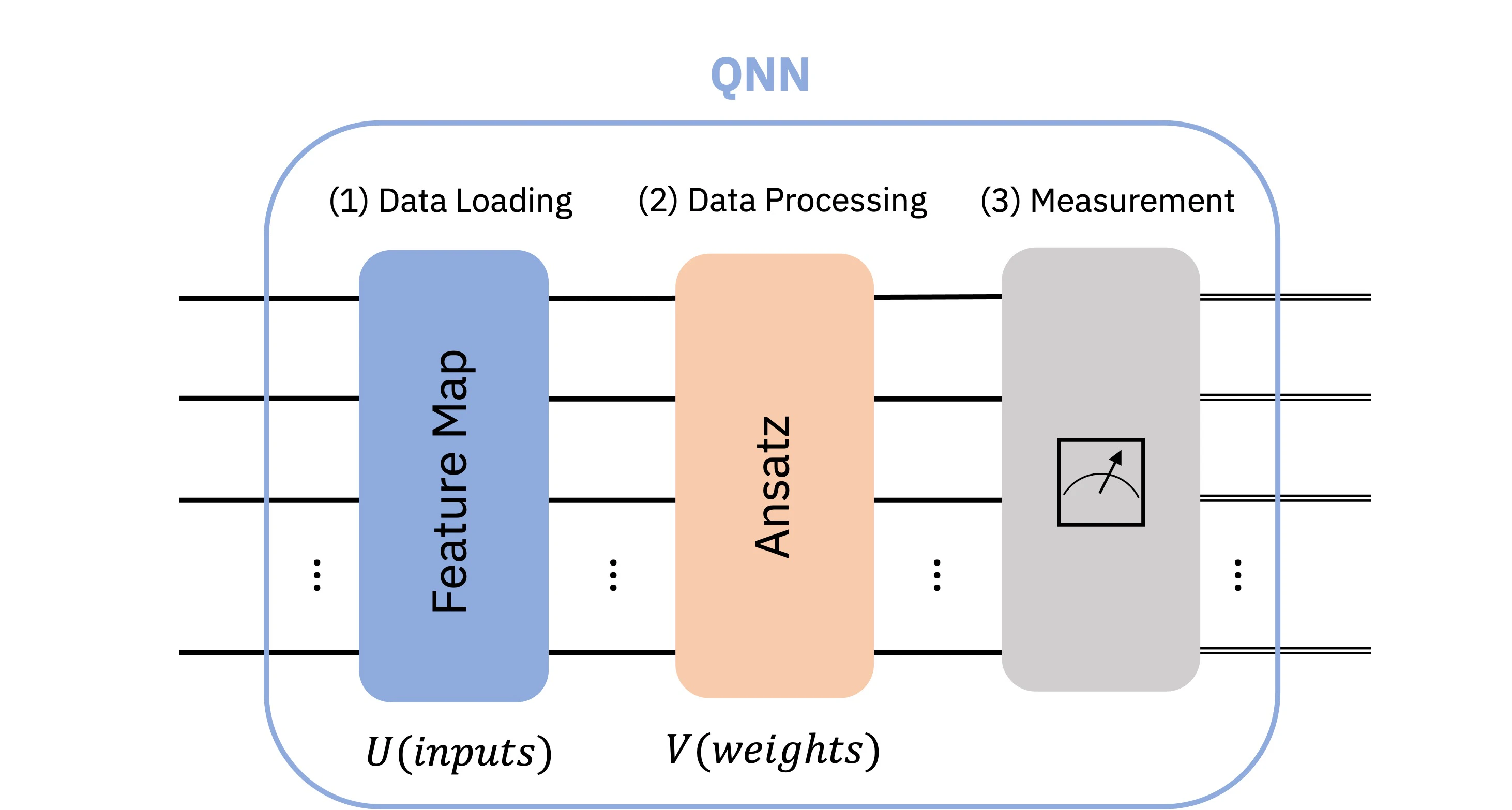
拝借元: https://qiskit-community.github.io/qiskit-machine-learning/tutorials/01_neural_networks.html
Feature Map にてデータを量子回路上にエンコードし、 Ansatz によってヒルベルト空間上で線形変換を行い、最後の測定で非線形変換を行うという流れになります。
これを古典的なニューラルネットワークの1層に準えると、
- 線形層
- Feature Map + Ansatz
- 活性化関数
- 測定
となります。
「測定はわかるけども、 Feature Map と Ansatz とはなんぞや?」という方も多いかと思います。
...そういうものだと思いましょう!
Feature Map については一応過去にそれっぽい記事(初めてQiskitを使ってからQiskitで量子機械学習ができるようになるまで 〜パート4〜)を上げているのですが、B4 $\rightarrow$ M1 の時期の筆者が書いた拙い説明なので役に立つのか...。
Ansatz は PQC (VQA)を語る上では避けて通れない部分も大いにあるのですが、簡単に言うとパウリゲートなどの簡易的なものではなく、複雑なエンタングルメントをパラメータで管理し、逐一更新していく「ミキサー」の役割を担っています(少なくとも筆者はそのような認識です...)。
では、プログラムレベルで作成してみましょうか!
# 必要なライブラリをインポート
from qiskit import QuantumCircuit
from qiskit.circuit.library import real_amplitudes, zz_feature_map
# 量子ビット数
num_qubits = 4
# 量子回路を初期化
qc = QuantumCircuit(num_qubits)
# Feature Map と Ansatz の回路の深さ(繰り返し数)を設定
feature_map_reps = 1
ansatz_reps = 1
# Feature Map と Ansatz の定義
feature_map = zz_feature_map(num_qubits, reps=feature_map_reps)
ansatz = real_amplitudes(
num_qubits, entanglement="linear", reps=ansatz_reps
)
# Re-Upload による回路の統合
num_reuploads = 3
for _ in range(num_reuploads):
qc.compose(feature_map, inplace=True)
qc.compose(ansatz, inplace=True)
いくつかポイントがあります。
まず、大元となる量子回路 qc は初期化する必要がありますね。
次に、 Feature Map と Ansatz の繰り返し数を設定することで回路の深さを調節します。
回路が深ければ表現力の可能性は広がりますが、その分計算量が多くなります。
基本として zz_feature_map を使っていますが、他の Feature Map に変えても良いと思います。
Ansatz の entanglement を "linear" にしていますが、ここも "circular" や "full" に変えてみても面白いかもしれません!
最後に、 Re-Upload ですが、これのイメージとしてはヘッド数を稼いでネットワーク全体の表現力を上げるための仕組みになります。
やっていることはシンプルに、 Feature Map と Ansatz のセットを繰り返し繋げているだけになります。
さて、これで量子回路が完成したので、 Estimator (Sampler)を使っていきましょう!
QNN の基盤
まずは Estimator や Sampler のインスタンスを生成します。
# 必要なライブラリをインポート
from qiskit.primitives import StatevectorEstimator as Estimator
# from qiskit.primitives import StatevectorSampler as Sampler
from qiskit.quantum_info import SparsePauliOp
from qiskit_machine_learning.connectors import TorchConnector
from qiskit_machine_learning.neural_networks import EstimatorQNN
# from qiskit_machine_learning.neural_networks import SamplerQNN
from qiskit_machine_learning.utils import algorithm_globals
# 乱数シードを固定
seed = 42
algorithm_globals.random_seed = seed
# Estimator のインスタンスを用意
estimator = Estimator(seed=seed)
# observables の設定
obs_01 = SparsePauliOp.from_list([("ZZII", 1.0)])
obs_12 = SparsePauliOp.from_list([("IZZI", 1.0)])
obs_02 = SparsePauliOp.from_list([("ZIZI", 1.0)])
obs_03 = SparsePauliOp.from_list([("ZIIZ", 1.0)])
observables = [obs_01, obs_12, obs_02, obs_03]
# QNN をセットアップ
qnn_base = EstimatorQNN(
circuit=qc,
estimator=estimator,
observables=observables,
input_params=feature_map.parameters,
weight_params=ansatz.parameters
)
initial_weights = 0.01 * (
2 * algorithm_globals.random.random(qnn_base.num_weights) - 1
)
# # Sampler のインスタンスを用意
# sampler = Sampler(seed=seed)
# # 出力次元を設定
# output_dim = 4
# # QNN をセットアップ
# qnn_base = SamplerQNN(
# circuit=qc,
# sampler=sampler,
# input_params=feature_map.parameters,
# weight_params=ansatz.parameters,
# output_shape=output_dim
# )
# initial_weights = 0.01 * (
# 2 * algorithm_globals.random.random(qnn_base.num_weights) - 1
# )
# qnn = TorchConnector(qnn_base, initial_weights=initial_weights)
Estimator にしても Sampler にしても、それぞれのインスタンスを用意して observables or output_shape を作って QNN クラスに与えれば良いということになりますね!
initial_weights というのを定義していますが、これは文字通り初期重みであり、これを大きくし過ぎて Barren Plateau の問題に沼らないようにしましょう。
最後に、 TorchConnector というクラスを使って PyTorch で1つの層として動かせるようにしてあげればもう完成のようなものです!
今回は Estimator を使っているので、 observables について少しだけ補足すると、ここの物理量に何かの意味を求めようとしてはいけません。
ぶっちゃけテキトーです。
これはニューラルネットワークの中間層の次元を変化させるものと同じだと思ってください。
出力次元は observables の数と一致します。
では、これらを汎用化を踏まえてクラス化してみましょう。
# 必要なライブラリをインポート
import torch
from torch import nn
from qiskit import QuantumCircuit
from qiskit.circuit.library import real_amplitudes, zz_feature_map
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
from qiskit.quantum_info import SparsePauliOp
from qiskit_machine_learning.connectors import TorchConnector
from qiskit_machine_learning.neural_networks import EstimatorQNN, SamplerQNN
from qiskit_machine_learning.utils import algorithm_globals
class QEstimator(nn.Module):
def __init__(
self, qcs: list[QuantumCircuit], seed: int,
observables: list[SparsePauliOp]
):
# 親クラスのコンストラクタを呼び出す
super(QEstimator, self).__init__()
# 量子回路のリストを取得
self.qc = qcs[0]
self.feature_map = qcs[1]
self.ansatz = qcs[2]
# 量子層の定義
self.qnn_est = self.set_estimator(seed, observables)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 量子層の順伝播計算
out = self.qnn_est(x)
return out
def set_estimator(
self, seed: int, observables: list[SparsePauliOp]
) -> TorchConnector:
"""
Estimator の QNN を用意する関数
Parameters
----------
seed: int
乱数シード値
observables: list[SparsePauliOp]
observable のリスト
Returns
----------
qnn: TorchConnector
Estimator の QNN 層
"""
# Estimator のインスタンスを用意
estimator = Estimator(seed=seed)
# QNN をセットアップ
qnn_base = EstimatorQNN(
circuit=self.qc,
estimator=estimator,
observables=observables,
input_params=self.feature_map.parameters,
weight_params=self.ansatz.parameters
)
initial_weights = 0.01 * (
2 * algorithm_globals.random.random(qnn_base.num_weights) - 1
)
qnn = TorchConnector(qnn_base, initial_weights=initial_weights)
return qnn
class QSampler(nn.Module):
def __init__(
self, qcs: list[QuantumCircuit], seed: int, output_dim: int
):
# 親クラスのコンストラクタを呼び出す
super(QSampler, self).__init__()
# 量子回路のリストを取得
self.qc = qcs[0]
self.feature_map = qcs[1]
self.ansatz = qcs[2]
# 量子層の出力次元を設定
self.output_dim = output_dim
# 量子層の定義
self.qnn_sam = self.set_sampler(seed)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 量子層の順伝播計算
out = self.qnn_sam(x)
return out
def set_sampler(self, seed: int) -> TorchConnector:
"""
Sampler の QNN を用意する関数
Parameters
----------
seed: int
乱数シード値
Returns
----------
qnn: TorchConnector
Sampler の QNN 層
"""
# Sampler のインスタンスを用意
sampler = Sampler(seed=seed)
# QNN をセットアップ
qnn_base = SamplerQNN(
circuit=self.qc,
sampler=sampler,
input_params=self.feature_map.parameters,
weight_params=self.ansatz.parameters,
output_shape=self.output_dim
)
initial_weights = 0.01 * (
2 * algorithm_globals.random.random(qnn_base.num_weights) - 1
)
qnn = TorchConnector(qnn_base, initial_weights=initial_weights)
return qnn
さらに、これらのクラスを自由に選択できるような QNN パイプラインを構築します。
# 必要なライブラリをインポート
from typing import Literal, Optional
import torch
from torch import nn
from qiskit import QuantumCircuit
from qiskit.circuit.library import real_amplitudes, zz_feature_map
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
from qiskit.quantum_info import SparsePauliOp
from qiskit_machine_learning.connectors import TorchConnector
from qiskit_machine_learning.neural_networks import EstimatorQNN, SamplerQNN
from qiskit_machine_learning.utils import algorithm_globals
class QEstimator(nn.Module):
def __init__(
self, qcs: list[QuantumCircuit], seed: int,
observables: list[SparsePauliOp]
):
# 親クラスのコンストラクタを呼び出す
super(QEstimator, self).__init__()
# 量子回路のリストを取得
self.qc = qcs[0]
self.feature_map = qcs[1]
self.ansatz = qcs[2]
# 量子層の定義
self.qnn_est = self.set_estimator(seed, observables)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 量子層の順伝播計算
out = self.qnn_est(x)
return out
def set_estimator(
self, seed: int, observables: list[SparsePauliOp]
) -> TorchConnector:
"""
Estimator の QNN を用意する関数
Parameters
----------
seed: int
乱数シード値
observables: list[SparsePauliOp]
observable のリスト
Returns
----------
qnn: TorchConnector
Estimator の QNN 層
"""
# Estimator のインスタンスを用意
estimator = Estimator(seed=seed)
# QNN をセットアップ
qnn_base = EstimatorQNN(
circuit=self.qc,
estimator=estimator,
observables=observables,
input_params=self.feature_map.parameters,
weight_params=self.ansatz.parameters
)
initial_weights = 0.01 * (
2 * algorithm_globals.random.random(qnn_base.num_weights) - 1
)
qnn = TorchConnector(qnn_base, initial_weights=initial_weights)
return qnn
class QSampler(nn.Module):
def __init__(
self, qcs: list[QuantumCircuit], seed: int, output_dim: int
):
# 親クラスのコンストラクタを呼び出す
super(QSampler, self).__init__()
# 量子回路のリストを取得
self.qc = qcs[0]
self.feature_map = qcs[1]
self.ansatz = qcs[2]
# 量子層の出力次元を設定
self.output_dim = output_dim
# 量子層の定義
self.qnn_sam = self.set_sampler(seed)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 量子層の順伝播計算
out = self.qnn_sam(x)
return out
def set_sampler(self, seed: int) -> TorchConnector:
"""
Sampler の QNN を用意する関数
Parameters
----------
seed: int
乱数シード値
Returns
----------
qnn: TorchConnector
Sampler の QNN 層
"""
# Sampler のインスタンスを用意
sampler = Sampler(seed=seed)
# QNN をセットアップ
qnn_base = SamplerQNN(
circuit=self.qc,
sampler=sampler,
input_params=self.feature_map.parameters,
weight_params=self.ansatz.parameters,
output_shape=self.output_dim
)
initial_weights = 0.01 * (
2 * algorithm_globals.random.random(qnn_base.num_weights) - 1
)
qnn = TorchConnector(qnn_base, initial_weights=initial_weights)
return qnn
class QuantumNeuralNetwork(nn.Module):
def __init__(
self, input_dim: int, num_reuploads: int,
net_type: Literal["Estimator", "Sampler"], seed: int,
feature_map_reps: int = 1, ansatz_reps: int = 1,
observables: Optional[list[SparsePauliOp]] = None,
output_dim: Optional[int] = None
):
# 親クラスのコンストラクタを呼び出す
super(QuantumNeuralNetwork, self).__init__()
# 入出力層の次元を設定
self.input_dim = input_dim
if net_type == "Sampler" and output_dim is not None:
self.output_dim = output_dim
# 量子回路を設計
qcs = self.build_reuploading_circuit(
self.input_dim, num_reuploads, feature_map_reps, ansatz_reps
)
self.qc = qcs[0]
self.feature_map = qcs[1]
self.ansatz = qcs[2]
self.qcs = [self.qc, self.feature_map, self.ansatz]
# observable を定義
if net_type == "Estimator" and observables is not None:
self.observables = observables
# QNN を構築
if net_type == "Estimator":
self.qnn = QEstimator(self.qcs, seed, self.observables)
elif net_type == "Sampler":
self.qnn = QSampler(self.qcs, seed, self.output_dim)
else:
pass
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 量子層の順伝播計算
out = self.qnn(x)
return out
def build_reuploading_circuit(
self, num_qubits: int, num_reuploads: int,
feature_map_reps: int = 1, ansatz_reps: int = 1
) -> list[QuantumCircuit]:
"""
QNN 用の量子回路を設計する関数
Parameters
----------
num_qubits: int
量子ビット数
num_reuploads: int
Re-Upload の回数
feature_map_reps: int = 1
特徴マップのリピート数
ansatz_reps: int = 1
ansatz のリピート数
Returns
----------
out: list[QuantumCircuit]
量子回路のリスト
"""
# 量子回路を初期化
qc = QuantumCircuit(num_qubits)
# 特徴マップと ansatz の定義
feature_map = zz_feature_map(num_qubits, reps=feature_map_reps)
ansatz = real_amplitudes(
num_qubits, entanglement="linear", reps=ansatz_reps
)
# Re-Upload
for _ in range(num_reuploads):
qc.compose(feature_map, inplace=True)
qc.compose(ansatz, inplace=True)
# 量子回路をまとめてリスト化
out = [qc, feature_map, ansatz]
return out
QuantumNeuralNetwork クラスの build_reuploading_circuit メソッドで量子回路を作成し、引数で与えた net_type により Estimator か Sampler かを選び、それぞれを呼び出します。
Estimator を選択しているのであれば、 observables も与えるようにしており、 Sampler を選択しているのであれば、 output_dim も与えるように設計しました。
これで一旦完成です!
実験
QNN 層を入れたモデルで3次元空間に配置された球体の内外を判定する分類問題を解いてみましょう!
データセット
次のコードでデータを作成します。
# 必要なライブラリをインポート
import warnings
import numpy as np
import pandas as pd
# 警告の無視
warnings.simplefilter("ignore")
# 乱数シードの設定
seed = 42
np.random.seed(seed)
# x, y, z 座標データを300点分作成
x = np.random.normal(0, 1, 300)
y = np.random.normal(0, 1, 300)
z = np.random.normal(0, 1, 300)
# データフレームで保存
df = pd.DataFrame({"x_val": x, "y_val": y, "z_val": z})
# 原点からのユークリッド距離を計算, 距離が1.5以下のものを0, それ以外を1とラベル付け
df["distance"] = np.sqrt(df["x_val"] ** 2 + df["y_val"] ** 2 + df["z_val"] ** 2)
df["label"] = np.where(df["distance"] <= 1.5, 0, 1)
これを可視化すると次のようになります。
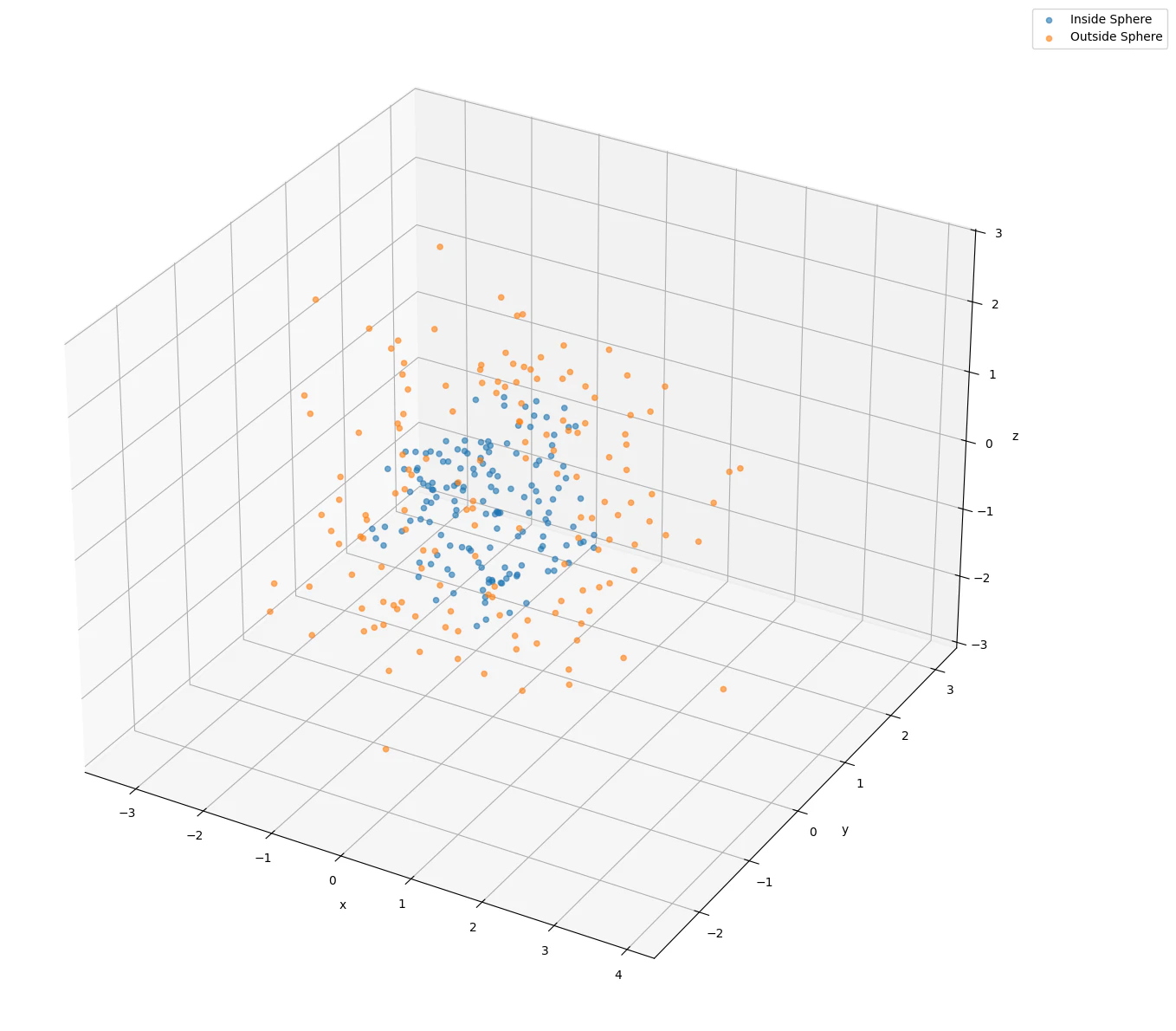
これを前処理していきましょう!
前処理
Scikit-Learn の train_test_split 関数を使ってデータを分割し、「学習用」「検証用」「評価用」に分けます。
そして、 PyTorch のモデルで処理できるように Tensor 型に変換したのち、「学習用」と「検証用」データローダを作成します。
今のところの全てのコードは次のとおりです。
# 必要なライブラリをインポート
import warnings
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import torch
from torch.utils.data import DataLoader, TensorDataset
# 警告の無視
warnings.simplefilter("ignore")
# 乱数シードの設定
seed = 42
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
# デバイスの指定
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"device:\t{device}\n")
# バッチサイズの指定
batch_size = 16
# x, y, z 座標データを300点分作成
x = np.random.normal(0, 1, 300)
y = np.random.normal(0, 1, 300)
z = np.random.normal(0, 1, 300)
# データフレームで保存
df = pd.DataFrame({"x_val": x, "y_val": y, "z_val": z})
# 原点からのユークリッド距離を計算, 距離が1.5以下のものを0, それ以外を1とラベル付け
df["distance"] = np.sqrt(df["x_val"] ** 2 + df["y_val"] ** 2 + df["z_val"] ** 2)
df["label"] = np.where(df["distance"] <= 1.5, 0, 1)
# 説明変数と目的変数を抽出
exp = df[["x_val", "y_val", "z_val"]].to_numpy()
obj = df["label"].to_numpy()
# データを学習用と検証用と評価に分割
exp_train, exp_test, obj_train, obj_test = train_test_split(
exp, obj, test_size=0.30, random_state=seed
)
exp_valid, exp_eval, obj_valid, obj_eval = train_test_split(
exp_test, obj_test, test_size=0.50, random_state=seed
)
# NumPy 配列を PyTorch のテンソルに変換する
exp_train = torch.tensor(exp_train, dtype=torch.float32)
exp_valid = torch.tensor(exp_valid, dtype=torch.float32)
exp_eval = torch.tensor(exp_eval, dtype=torch.float32)
obj_train = torch.tensor(obj_train, dtype=torch.float32).unsqueeze(1)
obj_valid = torch.tensor(obj_valid, dtype=torch.float32).unsqueeze(1)
obj_eval = torch.tensor(obj_eval, dtype=torch.float32).unsqueeze(1)
# 学習用と検証用のデータを TensorDataset と DataLoader に変換する
train_dataset = TensorDataset(exp_train, obj_train)
valid_dataset = TensorDataset(exp_valid, obj_valid)
train_loader = DataLoader(train_dataset, batch_size=batch_size)
valid_loader = DataLoader(valid_dataset, batch_size=batch_size)
では、モデルを作り、学習までしていきましょう。
学習
学習用の関数を作りましょう。
ここの解説は特にしません。
今回のデータと問題に沿った設計となっています。
# 必要なライブラリをインポート
from torch import nn, optim
from tqdm import tqdm
def train(
model: nn.Module, criterion: nn.Module, optimizer: optim.Optimizer,
data_loaders: dict, num_epochs: int, device: str
) -> tuple[nn.Module, list, list]:
"""
モデルの学習を行う関数
Parameters
----------
model: nn.Module
学習するモデル
criterion: nn.Module
損失関数
optimizer: optim.Optimizer
最適化手法
data_loaders: dict
学習用・テスト用データの DataLoader を格納した辞書
num_epochs: int
学習のエポック数
device: str
デバイス
Returns
----------
model: nn.Module
学習後のモデル
train_loss_list: list
学習用データにおける学習過程の損失を格納したリスト
test_loss_list: list
テスト用データにおける学習過程の損失を格納したリスト
"""
# 学習用・テスト用データの損失を格納するリスト
train_loss_list = []
test_loss_list = []
# 学習ループの実行
with tqdm(range(num_epochs)) as pbar_epoch:
# エポックごとのループ
for epoch in pbar_epoch:
# エポック数の表示
pbar_epoch.set_description(f"Epoch {epoch + 1}")
# フェーズごとのループ
for phase in ["train", "test"]:
# フェーズに応じてモデルのモードを切り替え
if phase == "train":
# モデルを学習モードに設定
model.train()
else:
# モデルを評価モードに設定
model.eval()
# エポックの損失を初期化
epoch_loss = 0.0
# ミニバッチ学習の実行
for inputs, labels in data_loaders[phase]:
# 勾配の初期化
optimizer.zero_grad()
# デバイスに渡す
inputs = inputs.to(device)
labels = labels.to(device)
# 順伝播の計算
with torch.set_grad_enabled(phase == "train"):
outputs = model(inputs)
loss = criterion(outputs, labels)
# 学習モードのときのみ逆伝播の計算とパラメータの更新
if phase == "train":
loss.backward()
optimizer.step()
# エポックの損失を更新
epoch_loss += loss.item()
# エポックの平均損失を計算
epoch_loss /= len(data_loaders[phase])
if phase == "train":
train_loss_list.append(epoch_loss)
else:
test_loss_list.append(epoch_loss)
return model, train_loss_list, test_loss_list
さらに、学習のロス曲線を描画するための関数を定義しましょう。
# 必要なライブラリをインポート
import matplotlib.pyplot as plt
def plot_data(train_loss_list: list, test_loss_list: list) -> None:
"""
学習過程の損失をプロットする関数
Parameters
----------
train_loss_list: list
学習用データにおける学習過程の損失を格納したリスト
test_loss_list: list
テスト用データにおける学習過程の損失を格納したリスト
Returns
----------
None
"""
# 横軸の設定
x = [i + 1 for i in range(len(train_loss_list))]
# 出力画像の設定
plt.figure(figsize=(18, 12), tight_layout=True)
plt.title("Training Loss over Epochs", size=15, color="red")
plt.grid()
plt.xlabel("Epoch")
plt.ylabel("Loss")
# 学習過程の損失をプロット
plt.plot(x, train_loss_list, label="Train Loss", color="blue")
plt.plot(x, test_loss_list, label="Test Loss", color="orange")
# グラフの表示
plt.legend(bbox_to_anchor=(1.01, 1), loc="upper left", borderaxespad=0)
plt.show()
今回のモデルですが、 Estimator を使った QNN 層を中間層に持つだけのシンプルな3層 NN とします。
入力層で $3 \rightarrow 4$ の次元変換を行い、活性化関数として Tanh 関数を使います。
QNN 層では入力と同じ次元数の出力となるよう Observable の数を4つにします。
出力層では、今回は「球体の内側に入るかどうか」なので $4 \rightarrow 1$ で良いと思います。
そのように実装してみましょう!
# 必要なライブラリをインポート
from typing import Literal, Optional
from qiskit import QuantumCircuit
from qiskit.circuit.library import real_amplitudes, zz_feature_map
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
from qiskit.quantum_info import SparsePauliOp
from qiskit_machine_learning.connectors import TorchConnector
from qiskit_machine_learning.neural_networks import EstimatorQNN, SamplerQNN
from qiskit_machine_learning.utils import algorithm_globals
class QEstimator(nn.Module):
def __init__(
self, qcs: list[QuantumCircuit], seed: int,
observables: list[SparsePauliOp]
):
# 親クラスのコンストラクタを呼び出す
super(QEstimator, self).__init__()
# 量子回路のリストを取得
self.qc = qcs[0]
self.feature_map = qcs[1]
self.ansatz = qcs[2]
# 量子層の定義
self.qnn_est = self.set_estimator(seed, observables)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 量子層の順伝播計算
out = self.qnn_est(x)
return out
def set_estimator(
self, seed: int, observables: list[SparsePauliOp]
) -> TorchConnector:
"""
Estimator の QNN を用意する関数
Parameters
----------
seed: int
乱数シード値
observables: list[SparsePauliOp]
observable のリスト
Returns
----------
qnn: TorchConnector
Estimator の QNN 層
"""
# Estimator のインスタンスを用意
estimator = Estimator(seed=seed)
# QNN をセットアップ
qnn_base = EstimatorQNN(
circuit=self.qc,
estimator=estimator,
observables=observables,
input_params=self.feature_map.parameters,
weight_params=self.ansatz.parameters
)
initial_weights = 0.01 * (
2 * algorithm_globals.random.random(qnn_base.num_weights) - 1
)
qnn = TorchConnector(qnn_base, initial_weights=initial_weights)
return qnn
class QSampler(nn.Module):
def __init__(
self, qcs: list[QuantumCircuit], seed: int, output_dim: int
):
# 親クラスのコンストラクタを呼び出す
super(QSampler, self).__init__()
# 量子回路のリストを取得
self.qc = qcs[0]
self.feature_map = qcs[1]
self.ansatz = qcs[2]
# 量子層の出力次元を設定
self.output_dim = output_dim
# 量子層の定義
self.qnn_sam = self.set_sampler(seed)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 量子層の順伝播計算
out = self.qnn_sam(x)
return out
def set_sampler(self, seed: int) -> TorchConnector:
"""
Sampler の QNN を用意する関数
Parameters
----------
seed: int
乱数シード値
Returns
----------
qnn: TorchConnector
Sampler の QNN 層
"""
# Sampler のインスタンスを用意
sampler = Sampler(seed=seed)
# QNN をセットアップ
qnn_base = SamplerQNN(
circuit=self.qc,
sampler=sampler,
input_params=self.feature_map.parameters,
weight_params=self.ansatz.parameters,
output_shape=self.output_dim
)
initial_weights = 0.01 * (
2 * algorithm_globals.random.random(qnn_base.num_weights) - 1
)
qnn = TorchConnector(qnn_base, initial_weights=initial_weights)
return qnn
class QuantumNeuralNetwork(nn.Module):
def __init__(
self, input_dim: int, num_reuploads: int,
net_type: Literal["Estimator", "Sampler"], seed: int,
feature_map_reps: int = 1, ansatz_reps: int = 1,
observables: Optional[list[SparsePauliOp]] = None,
output_dim: Optional[int] = None
):
# 親クラスのコンストラクタを呼び出す
super(QuantumNeuralNetwork, self).__init__()
# 入出力層の次元を設定
self.input_dim = input_dim
if net_type == "Sampler" and output_dim is not None:
self.output_dim = output_dim
# 量子回路を設計
qcs = self.build_reuploading_circuit(
self.input_dim, num_reuploads, feature_map_reps, ansatz_reps
)
self.qc = qcs[0]
self.feature_map = qcs[1]
self.ansatz = qcs[2]
self.qcs = [self.qc, self.feature_map, self.ansatz]
# observable を定義
if net_type == "Estimator" and observables is not None:
self.observables = observables
# QNN を構築
if net_type == "Estimator":
self.qnn = QEstimator(self.qcs, seed, self.observables)
elif net_type == "Sampler":
self.qnn = QSampler(self.qcs, seed, self.output_dim)
else:
pass
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 量子層の順伝播計算
out = self.qnn(x)
return out
def build_reuploading_circuit(
self, num_qubits: int, num_reuploads: int,
feature_map_reps: int = 1, ansatz_reps: int = 1
) -> list[QuantumCircuit]:
"""
QNN 用の量子回路を設計する関数
Parameters
----------
num_qubits: int
量子ビット数
num_reuploads: int
Re-Upload の回数
feature_map_reps: int = 1
特徴マップのリピート数
ansatz_reps: int = 1
ansatz のリピート数
Returns
----------
out: list[QuantumCircuit]
量子回路のリスト
"""
# 量子回路を初期化
qc = QuantumCircuit(num_qubits)
# 特徴マップと ansatz の定義
feature_map = zz_feature_map(num_qubits, reps=feature_map_reps)
ansatz = real_amplitudes(
num_qubits, entanglement="linear", reps=ansatz_reps
)
# Re-Upload
for _ in range(num_reuploads):
qc.compose(feature_map, inplace=True)
qc.compose(ansatz, inplace=True)
# 量子回路をまとめてリスト化
out = [qc, feature_map, ansatz]
return out
class MyModel(nn.Module):
def __init__(
self, input_dim: int, quantum_input_dim: int, output_dim: int,
num_reuploads: int, seed: int, observables: list[SparsePauliOp]
):
# 親クラスのコンストラクタを呼び出す
super(MyModel, self).__init__()
# 各層次元設定
self.input_dim = input_dim
self.quantum_input_dim = quantum_input_dim
self.output_dim = output_dim
# observables の定義
self.observables = observables
# 入力層の定義
self.linear_in = nn.Linear(self.input_dim, self.quantum_input_dim)
# 量子層の定義
self.estimator = QuantumNeuralNetwork(
self.quantum_input_dim, num_reuploads, net_type="Estimator",
seed=seed, observables=self.observables
)
# 出力層の定義
self.linear_out = nn.Linear(len(self.observables), self.output_dim)
# 活性化関数の定義
self.tanh = nn.Tanh()
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 入力層の順伝播計算
h = self.linear_in(x)
h = self.tanh(h)
# 量子層の順伝播計算
q_out = self.estimator(h)
# 出力層の順伝播計算
out = self.linear_out(q_out)
return out
モデルが出来たので、学習設定をしていきましょう。
Observable はわりとテキトーに、最適化手法は Adam を使って、損失関数は BCEWithLogitsLoss を使いましょう。
エポックは300くらいにしてみましょう(なかなか終わらないかも...?)。
# observables の設定
obs_01 = SparsePauliOp.from_list([("ZZII", 1.0)])
obs_12 = SparsePauliOp.from_list([("IZZI", 1.0)])
obs_02 = SparsePauliOp.from_list([("ZIZI", 1.0)])
obs_03 = SparsePauliOp.from_list([("ZIIZ", 1.0)])
observables = [obs_01, obs_12, obs_02, obs_03]
# モデルの定義
model = MyModel(
input_dim=3, quantum_input_dim=4, output_dim=1, num_reuploads=3, seed=seed,
observables=observables
).to(device)
print(model)
# 最適化手法の設定
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 損失関数の設定
criterion = nn.BCEWithLogitsLoss()
# エポック数の設定
num_epochs = 300
# DataLoader の辞書
data_loaders = {"train": train_loader, "test": valid_loader}
そして、実際に学習とロス曲線の描画までやってみましょう!
# 学習の実行
model, train_loss_list, test_loss_list = train(
model, criterion, optimizer, data_loaders, num_epochs, device
)
# 学習過程の損失をプロット
plot_data(train_loss_list, test_loss_list)
評価
「評価用」のデータで精度を見てみましょう!
# 必要なライブラリをインポート
from sklearn.metrics import classification_report
# 評価データを予測
inputs = exp_eval.to(device)
labels = obj_eval.to(device)
outputs = model(inputs)
probs = torch.sigmoid(outputs)
preds = (probs > 0.5).long()
# 予測と正解の評価指標を表示
y_true = labels.cpu().numpy().ravel()
y_pred = preds.cpu().numpy().ravel()
print(
classification_report(
y_true, y_pred, target_names=["Inside Sphere", "Outside Sphere"]
)
)
全部まとめる
# 必要なライブラリをインポート
from typing import Literal, Optional
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
import torch
from torch import nn, optim
from torch.utils.data import DataLoader, TensorDataset
from tqdm import tqdm
from qiskit import QuantumCircuit
from qiskit.circuit.library import real_amplitudes, zz_feature_map
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
from qiskit.quantum_info import SparsePauliOp
from qiskit_machine_learning.connectors import TorchConnector
from qiskit_machine_learning.neural_networks import EstimatorQNN, SamplerQNN
from qiskit_machine_learning.utils import algorithm_globals
class QEstimator(nn.Module):
def __init__(
self, qcs: list[QuantumCircuit], seed: int,
observables: list[SparsePauliOp]
):
# 親クラスのコンストラクタを呼び出す
super(QEstimator, self).__init__()
# 量子回路のリストを取得
self.qc = qcs[0]
self.feature_map = qcs[1]
self.ansatz = qcs[2]
# 量子層の定義
self.qnn_est = self.set_estimator(seed, observables)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 量子層の順伝播計算
out = self.qnn_est(x)
return out
def set_estimator(
self, seed: int, observables: list[SparsePauliOp]
) -> TorchConnector:
"""
Estimator の QNN を用意する関数
Parameters
----------
seed: int
乱数シード値
observables: list[SparsePauliOp]
observable のリスト
Returns
----------
qnn: TorchConnector
Estimator の QNN 層
"""
# Estimator のインスタンスを用意
estimator = Estimator(seed=seed)
# QNN をセットアップ
qnn_base = EstimatorQNN(
circuit=self.qc,
estimator=estimator,
observables=observables,
input_params=self.feature_map.parameters,
weight_params=self.ansatz.parameters
)
initial_weights = 0.01 * (
2 * algorithm_globals.random.random(qnn_base.num_weights) - 1
)
qnn = TorchConnector(qnn_base, initial_weights=initial_weights)
return qnn
class QSampler(nn.Module):
def __init__(
self, qcs: list[QuantumCircuit], seed: int, output_dim: int
):
# 親クラスのコンストラクタを呼び出す
super(QSampler, self).__init__()
# 量子回路のリストを取得
self.qc = qcs[0]
self.feature_map = qcs[1]
self.ansatz = qcs[2]
# 量子層の出力次元を設定
self.output_dim = output_dim
# 量子層の定義
self.qnn_sam = self.set_sampler(seed)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 量子層の順伝播計算
out = self.qnn_sam(x)
return out
def set_sampler(self, seed: int) -> TorchConnector:
"""
Sampler の QNN を用意する関数
Parameters
----------
seed: int
乱数シード値
Returns
----------
qnn: TorchConnector
Sampler の QNN 層
"""
# Sampler のインスタンスを用意
sampler = Sampler(seed=seed)
# QNN をセットアップ
qnn_base = SamplerQNN(
circuit=self.qc,
sampler=sampler,
input_params=self.feature_map.parameters,
weight_params=self.ansatz.parameters,
output_shape=self.output_dim
)
initial_weights = 0.01 * (
2 * algorithm_globals.random.random(qnn_base.num_weights) - 1
)
qnn = TorchConnector(qnn_base, initial_weights=initial_weights)
return qnn
class QuantumNeuralNetwork(nn.Module):
def __init__(
self, input_dim: int, num_reuploads: int,
net_type: Literal["Estimator", "Sampler"], seed: int,
feature_map_reps: int = 1, ansatz_reps: int = 1,
observables: Optional[list[SparsePauliOp]] = None,
output_dim: Optional[int] = None
):
# 親クラスのコンストラクタを呼び出す
super(QuantumNeuralNetwork, self).__init__()
# 入出力層の次元を設定
self.input_dim = input_dim
if net_type == "Sampler" and output_dim is not None:
self.output_dim = output_dim
# 量子回路を設計
qcs = self.build_reuploading_circuit(
self.input_dim, num_reuploads, feature_map_reps, ansatz_reps
)
self.qc = qcs[0]
self.feature_map = qcs[1]
self.ansatz = qcs[2]
self.qcs = [self.qc, self.feature_map, self.ansatz]
# observable を定義
if net_type == "Estimator" and observables is not None:
self.observables = observables
# QNN を構築
if net_type == "Estimator":
self.qnn = QEstimator(self.qcs, seed, self.observables)
elif net_type == "Sampler":
self.qnn = QSampler(self.qcs, seed, self.output_dim)
else:
pass
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 量子層の順伝播計算
out = self.qnn(x)
return out
def build_reuploading_circuit(
self, num_qubits: int, num_reuploads: int,
feature_map_reps: int = 1, ansatz_reps: int = 1
) -> list[QuantumCircuit]:
"""
QNN 用の量子回路を設計する関数
Parameters
----------
num_qubits: int
量子ビット数
num_reuploads: int
Re-Upload の回数
feature_map_reps: int = 1
特徴マップのリピート数
ansatz_reps: int = 1
ansatz のリピート数
Returns
----------
out: list[QuantumCircuit]
量子回路のリスト
"""
# 量子回路を初期化
qc = QuantumCircuit(num_qubits)
# 特徴マップと ansatz の定義
feature_map = zz_feature_map(num_qubits, reps=feature_map_reps)
ansatz = real_amplitudes(
num_qubits, entanglement="linear", reps=ansatz_reps
)
# Re-Upload
for _ in range(num_reuploads):
qc.compose(feature_map, inplace=True)
qc.compose(ansatz, inplace=True)
# 量子回路をまとめてリスト化
out = [qc, feature_map, ansatz]
return out
class MyModel(nn.Module):
def __init__(
self, input_dim: int, quantum_input_dim: int, output_dim: int,
num_reuploads: int, seed: int, observables: list[SparsePauliOp]
):
# 親クラスのコンストラクタを呼び出す
super(MyModel, self).__init__()
# 各層次元設定
self.input_dim = input_dim
self.quantum_input_dim = quantum_input_dim
self.output_dim = output_dim
# observables の定義
self.observables = observables
# 入力層の定義
self.linear_in = nn.Linear(self.input_dim, self.quantum_input_dim)
# 量子層の定義
self.estimator = QuantumNeuralNetwork(
self.quantum_input_dim, num_reuploads, net_type="Estimator",
seed=seed, observables=self.observables
)
# 出力層の定義
self.linear_out = nn.Linear(len(self.observables), self.output_dim)
# 活性化関数の定義
self.tanh = nn.Tanh()
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
順伝播を行う関数
Parameters
----------
x: torch.Tensor
入力データ
Returns
----------
out: torch.Tensor
出力データ
"""
# 入力層の順伝播計算
h = self.linear_in(x)
h = self.tanh(h)
# 量子層の順伝播計算
q_out = self.estimator(h)
# 出力層の順伝播計算
out = self.linear_out(q_out)
return out
def train(
model: nn.Module, criterion: nn.Module, optimizer: optim.Optimizer,
data_loaders: dict, num_epochs: int, device: str
) -> tuple[nn.Module, list, list]:
"""
モデルの学習を行う関数
Parameters
----------
model: nn.Module
学習するモデル
criterion: nn.Module
損失関数
optimizer: optim.Optimizer
最適化手法
data_loaders: dict
学習用・テスト用データの DataLoader を格納した辞書
num_epochs: int
学習のエポック数
device: str
デバイス
Returns
----------
model: nn.Module
学習後のモデル
train_loss_list: list
学習用データにおける学習過程の損失を格納したリスト
test_loss_list: list
テスト用データにおける学習過程の損失を格納したリスト
"""
# 学習用・テスト用データの損失を格納するリスト
train_loss_list = []
test_loss_list = []
# 学習ループの実行
with tqdm(range(num_epochs)) as pbar_epoch:
# エポックごとのループ
for epoch in pbar_epoch:
# エポック数の表示
pbar_epoch.set_description(f"Epoch {epoch + 1}")
# フェーズごとのループ
for phase in ["train", "test"]:
# フェーズに応じてモデルのモードを切り替え
if phase == "train":
# モデルを学習モードに設定
model.train()
else:
# モデルを評価モードに設定
model.eval()
# エポックの損失を初期化
epoch_loss = 0.0
# ミニバッチ学習の実行
for inputs, labels in data_loaders[phase]:
# 勾配の初期化
optimizer.zero_grad()
# デバイスに渡す
inputs = inputs.to(device)
labels = labels.to(device)
# 順伝播の計算
with torch.set_grad_enabled(phase == "train"):
outputs = model(inputs)
loss = criterion(outputs, labels)
# 学習モードのときのみ逆伝播の計算とパラメータの更新
if phase == "train":
loss.backward()
optimizer.step()
# エポックの損失を更新
epoch_loss += loss.item()
# エポックの平均損失を計算
epoch_loss /= len(data_loaders[phase])
if phase == "train":
train_loss_list.append(epoch_loss)
else:
test_loss_list.append(epoch_loss)
return model, train_loss_list, test_loss_list
def plot_data(train_loss_list: list, test_loss_list: list) -> None:
"""
学習過程の損失をプロットする関数
Parameters
----------
train_loss_list: list
学習用データにおける学習過程の損失を格納したリスト
test_loss_list: list
テスト用データにおける学習過程の損失を格納したリスト
Returns
----------
None
"""
# 横軸の設定
x = [i + 1 for i in range(len(train_loss_list))]
# 出力画像の設定
plt.figure(figsize=(18, 12), tight_layout=True)
plt.title("Training Loss over Epochs", size=15, color="red")
plt.grid()
plt.xlabel("Epoch")
plt.ylabel("Loss")
# 学習過程の損失をプロット
plt.plot(x, train_loss_list, label="Train Loss", color="blue")
plt.plot(x, test_loss_list, label="Test Loss", color="orange")
# グラフの表示
plt.legend(bbox_to_anchor=(1.01, 1), loc="upper left", borderaxespad=0)
plt.show()
# 警告の無視
warnings.simplefilter("ignore")
# 乱数シードの設定
seed = 42
np.random.seed(seed)
algorithm_globals.random_seed = seed
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
# デバイスの指定
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"device:\t{device}\n")
# バッチサイズの指定
batch_size = 8
# x, y, z 座標データを300点分作成
x = np.random.normal(0, 1, 300)
y = np.random.normal(0, 1, 300)
z = np.random.normal(0, 1, 300)
# データフレームで保存
df = pd.DataFrame({"x_val": x, "y_val": y, "z_val": z})
# 原点からのユークリッド距離を計算, 距離が1.5以下のものを0, それ以外を1とラベル付け
df["distance"] = np.sqrt(df["x_val"] ** 2 + df["y_val"] ** 2 + df["z_val"] ** 2)
df["label"] = np.where(df["distance"] <= 1.5, 0, 1)
# 説明変数と目的変数を抽出
exp = df[["x_val", "y_val", "z_val"]].to_numpy()
obj = df["label"].to_numpy()
# データを学習用と検証用と評価に分割
exp_train, exp_test, obj_train, obj_test = train_test_split(
exp, obj, test_size=0.30, random_state=seed
)
exp_valid, exp_eval, obj_valid, obj_eval = train_test_split(
exp_test, obj_test, test_size=0.50, random_state=seed
)
# NumPy 配列を PyTorch のテンソルに変換する
exp_train = torch.tensor(exp_train, dtype=torch.float32)
exp_valid = torch.tensor(exp_valid, dtype=torch.float32)
exp_eval = torch.tensor(exp_eval, dtype=torch.float32)
obj_train = torch.tensor(obj_train, dtype=torch.float32).unsqueeze(1)
obj_valid = torch.tensor(obj_valid, dtype=torch.float32).unsqueeze(1)
obj_eval = torch.tensor(obj_eval, dtype=torch.float32).unsqueeze(1)
# 学習用と検証用のデータを TensorDataset と DataLoader に変換する
train_dataset = TensorDataset(exp_train, obj_train)
valid_dataset = TensorDataset(exp_valid, obj_valid)
train_loader = DataLoader(train_dataset, batch_size=batch_size)
valid_loader = DataLoader(valid_dataset, batch_size=batch_size)
# observables の設定
obs_01 = SparsePauliOp.from_list([("ZZII", 1.0)])
obs_12 = SparsePauliOp.from_list([("IZZI", 1.0)])
obs_02 = SparsePauliOp.from_list([("ZIZI", 1.0)])
obs_03 = SparsePauliOp.from_list([("ZIIZ", 1.0)])
observables = [obs_01, obs_12, obs_02, obs_03]
# モデルの定義
model = MyModel(
input_dim=3, quantum_input_dim=4, output_dim=1, num_reuploads=3, seed=seed,
observables=observables
).to(device)
print(model)
# 最適化手法の設定
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 損失関数の設定
criterion = nn.BCEWithLogitsLoss()
# エポック数の設定
num_epochs = 300
# DataLoader の辞書
data_loaders = {"train": train_loader, "test": valid_loader}
# 学習の実行
model, train_loss_list, test_loss_list = train(
model, criterion, optimizer, data_loaders, num_epochs, device
)
# 学習過程の損失をプロット
plot_data(train_loss_list, test_loss_list)
# 評価データを予測
inputs = exp_eval.to(device)
labels = obj_eval.to(device)
outputs = model(inputs)
probs = torch.sigmoid(outputs)
preds = (probs > 0.5).long()
# 予測と正解の評価指標を表示
y_true = labels.cpu().numpy().ravel()
y_pred = preds.cpu().numpy().ravel()
print(
classification_report(
y_true, y_pred, target_names=["Inside Sphere", "Outside Sphere"]
)
)
結果
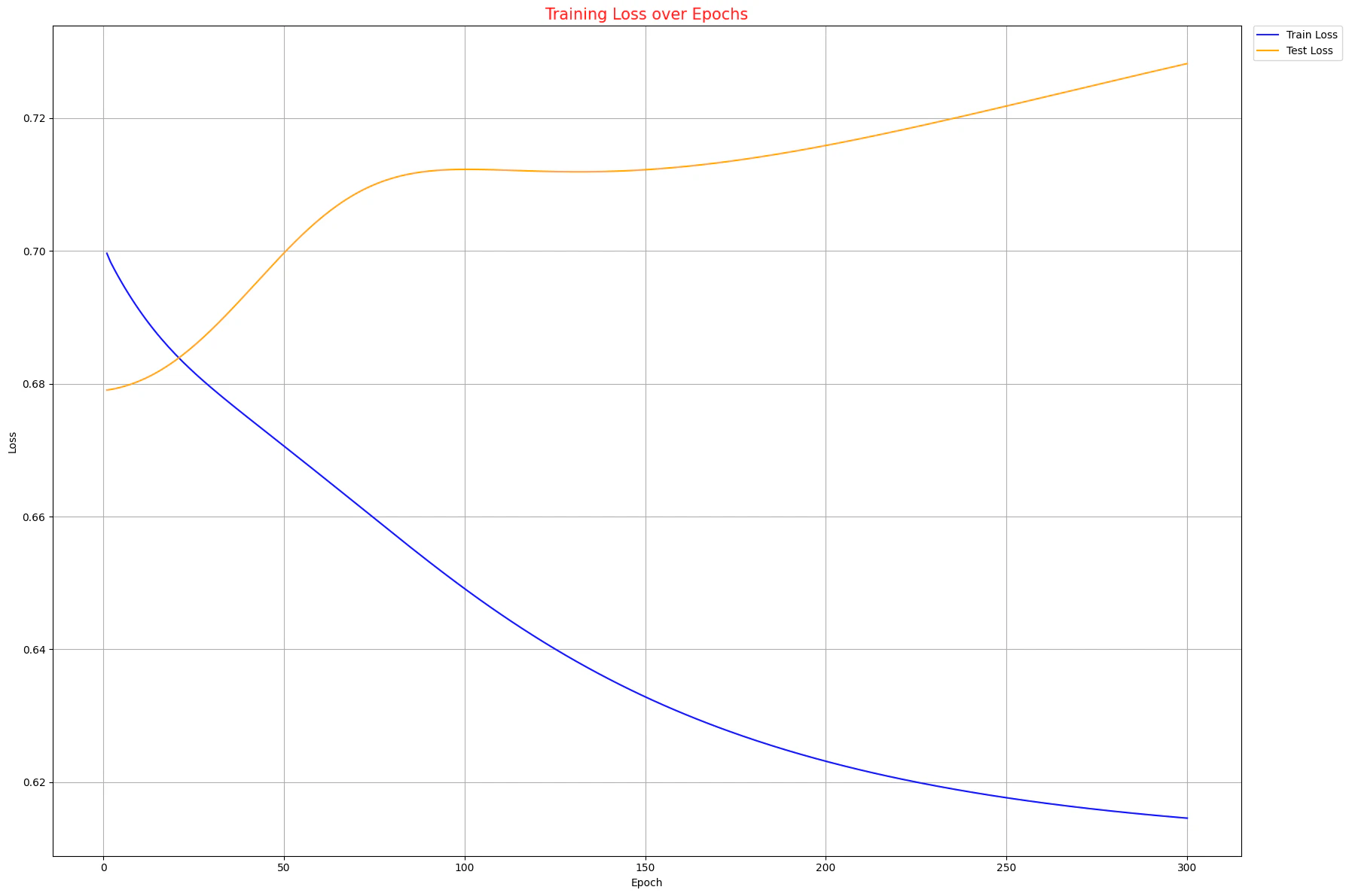
ロス曲線
評価
precision recall f1-score support
Inside Sphere 0.48 0.45 0.47 22
Outside Sphere 0.50 0.52 0.51 23
accuracy 0.49 45
macro avg 0.49 0.49 0.49 45
weighted avg 0.49 0.49 0.49 45
う〜ん、難しいですね...。
学習用データでのロス曲線が安定的に下がっている一方で、検証用の方はパッと見で単調増加。
検証用と評価用のデータセットがそれぞれ45個ずつなので、データ数が少なくて分布が異なっていた可能性がありますね。
とはいえ、学習用データについてはちゃんと学習できているようですし、 QNN そのものは正常に働いているので大丈夫ですね!
まとめ
QNN の正体は、 Feature Map と Ansatz によって作られる量子回路でした。
Qiskit に用意された Estimator を使って物理量を推論するフレームワークを、 PyTorch のモデルの中に統合するような形で、実質 PyTorch として QNN を扱うことができるようになりました!