経緯
object trackingに触れる機会があり、その際に読んだ論文の内容を共有しようと思い、記事にしました。object tracking全体の詳しい解説はこちらが参考になると思います。自分は、エッジデバイス上でDNNを動かすことが多いため、精度もですがFPSが速い手法を特に探していました。なので、今回紹介するのはFPSがトップレベルに速いSiamCARという手法です。機械学習の用語とかはできるだけ英語のままにしています。
ざっくりとはどんな論文?
- tracking taskをカテゴリーの分類と、object bounding boxの回帰という2つの問題に分解したよ
- anchorなどを使わないパラメータチューニングがいらない手法でSOTAを達成したよ
- FPSもめちゃめちゃ速いよ
論文の前にSiameseNetworkとは?
object trackingの手法の中で、よく用いられているネットワークとしてSiamese Networkというものがあります。これを用いているobject trackingの名前はだいたいSiam~~となってます。SiamNetworkは簡単に言うと、同じクラスを近くに、違えば違うほど遠くに写像するネットワークです。こちらの記事とかが参考になると思います。
0. Abstract
tracking taskをカテゴリーの分類と、object bounding boxの回帰という2つの問題に分解した、fully convolutional Siamese networkを提案します。SiamCARは特徴量抽出のためのSiamese subnetworkとbounding box予測のためのclassfication regression subnetworkの2つで構成されています。Siamese-RPNなどのSOTAと比べて、この手法はanchorがいりません。その結果、ハイパーパラメータのチューニングから解放されます。多くの実験でSOTAを達成しています。
*anchorはあらかじめobjectの縦と横のアスペクト比を設定しておき、それをobject trackingの補助として使うものです。例えば、立っている人だったら縦が横より長いanchorになります。
1. Introduction
object trackingは幅広いアプリケーションにおいて注目を浴びており、急速に発展しています。しかし、様々な光のシチュエーションや、オクルージョンなど、現実世界で導入するには多くの課題があります。現在の人気なvisual trackingの手法はSiamese networkがベースとなっています。Siamese networkはtracking taskをtarget matching problemとし、target templateとsearch regionのsimilarity mapを学習することを目指します。
主な貢献は以下の通りです。
- visual trackingのためのSiamese classificationとregression framework(SiamCAR)を提案します。フレームワーク自体はシンプルですが、パワフルなパフォーマンスを出します。
- trackerはanchorとproposalフリーです。hyper-parameterの数が激減しました。
- accuracyとspeedにおいてSOTAを実現しています。
2. Related Work
CNNの急速な進歩により、CNN-basedの抽出器が広く用いられるようになりました。template updatingによって、trackerの適応性は改善されましたが、online trackingは非効率的です。その上、template updatingはtracking driftに悩まされています。現在の研究者はCNNを用いたSiamese based online trainingとtracking approachがaccuracyとefficiencyの間で最もバランスが良いことを示しています。
template updating → objectの外観の変化(光のあたり具合など)に応じてonlineで学習する。ただ、FPSが遅い。
tracking drift → 追跡する物体が途中で入れ替わってしまう現象。下のような画像のような感じ。

3. Proposed Method
私達はtracking taskをclassificationとregressionの2つのsubproblemに分解しています。Figure 2で示しているように、私達のフレームワークは、主にfeature extractionのためのSiamese networkと、bounding box predictionのためのother networkの2つのsimple subnetworkで構成されています。
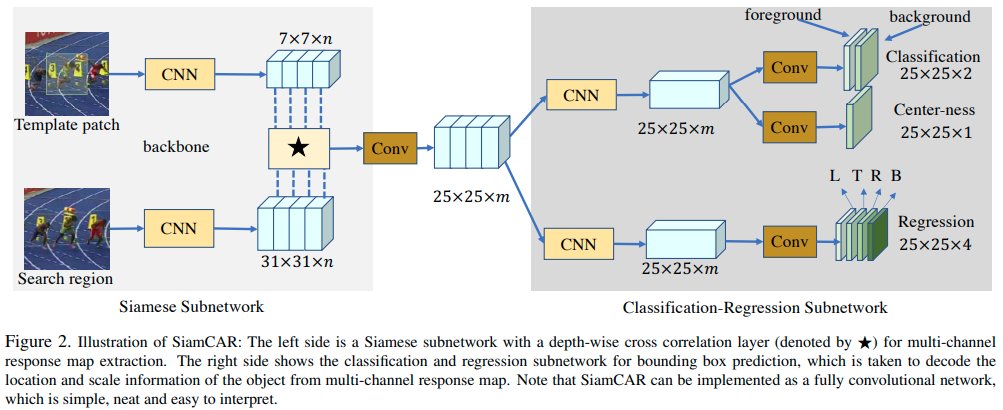
3.1. Feature Extraction
feature extractionのためにCNNを利用します。Siamese Subnetworkは2つのブランチを構成します。target branchは入力としてtracking template patch Z(前のフレームからの物体の位置、または物体の初期位置)を取り、search branchは入力としてsearch region X(この領域の中から物体を探していく)を取ります。2つのbranchはbackbone modelとして同じCNNアーキテクチャを共有し、2つのfeature maps ϕ(Z) とϕ(X)を出力します。これらの2つのbranchの情報を埋め込むために、 ϕ(X)とϕ(Z)のcross-correlationによりresponse map Rを取得出来ます。Rが豊富な情報を持っているのが理想ですが、cross-correlation layerはsingle-channel compressed response mapしか生み出すことができず、それはtrackingにおいて情報不足となります。よって、複数のsemantic similarity mapsを作り出すためにdepth-wise correlation layerを使います。
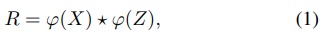
feature map→畳み込みによって得られた行列。モデルがどのようにtargetの特徴を捉えているのか確認するために、feature mapを可視化したりします。こちらとかが参考になるかもしれません。
cross-correlation→2つの対象の類似度を図る式。詳しくはこちら。
*はチャンネル毎のcorrelation操作を示しています。map Rはϕ(X)と同じ数のchanelを持ち、classficationとregressionのための多くの情報を保持しています。backbone networksとして変更を加えたResNet-50を使います。より良い推論結果を得るために、backboneの最後の3つのresidual blocksを組み合わせます。それぞれ、F3(X), F4(X), F5(X)とし、結合します。
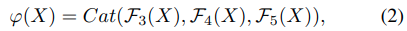
F3(X)~F(5)は256 channelsを含んでいるので、結果的にφ(X)は3 * 256channlesを含むことになります。
Depth-wise Cross Correlationはmulti-channel response mapを取得するためにsearching map φ(X)とtemplate map φ(Z)の間で実行されます。response mapはその時、256 channelsまで次元を減らすために1 * 1 kernelで畳み込まれます。最後の次元が削減されたresponse map R*はclassification-regression subnetworkの入力として採用されます。
3.2. Bounding Box Prediction
response map Rにおけるlocation(i, j)は入力のsearch region(x, y)としてマッピングすることができます。RPNベースのtrackerは検索領域の対応する場所をmulti-scale boxesの中心とみなし、これらのアンカーボックスを参照します。それらと違い、私達のネットワークはそれぞれの位置において、直接target bounding boxを分類、回帰しています。関連したtrainingはend-to-endのfully convolution operationで達成され、難解なパラメータチューニングを避け、人間の介入を減らします。
tracking taskは2つのsubtasksに分解されます。それぞれの位置におけるカテゴリを予測するためのclassification branchと、target bounding boxを計算するregression branchです。Siamese subnetworkを使って抽出されたresponse map R(whm)の場合、classification branchはclassification feature map Acls(wh2)を出力し、regression branchはregression feature map Areg(wh4)を出力します。ここでwとhは抽出したfeature mapのwidthとheightです。Figure 2で示されているように、Aclsの(i, j)それぞれの点は、2D vectorを含んでおり、input search regionにおける対応する位置のforegroundとbackground scoreを表しています。Aregにおけるeach point(i, j,:)は4D vector t(i, j) = (l, t, r, b)を含んでおり、これは対応する位置からinput search regionにおけるbounding boxの4つの辺までの距離を表しています。
classificationのためにcross-entropy、regressionのためにIoUを採用しています。(x0, y0)と(x1, y1)は左上と右下を表し、(x, y)は点(i, j)に対応する位置を表します。Aregのtarget t(i, j)は次のように計算されます。
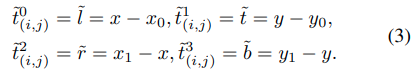
t(i, j)はground-truth bounding boxとpredicted bounding boxの間のIoUで計算されます。そのときregression lossは次のように計算されます。
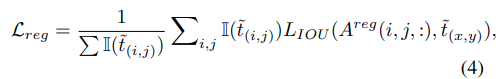
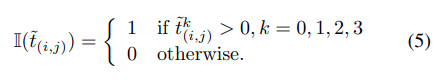
targetの中心から離れた位置では、低精度で予測されたbounding boxが生成される傾向があり、これはtracking systemのパフォーマンスの精度を下げています。外れ値を取り除くためにclassification branchと並行してcenterness branchを加えています。Figure 2で示されているように、そのbranchはcenterness feature map Acenを出力します。それぞれのpointの値は一致する位置のcenterness scoreを与えます。Acen(i,j)のC(i, j)は下のように定義されます。
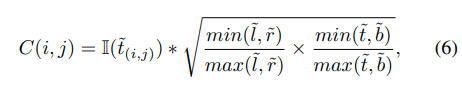
もし、(x, y)がbackgroundの位置であれば、C(i, j)の値は0に設定されます。centerness lossは次のようになります。
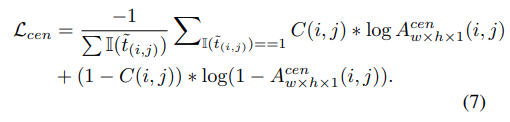
全体のloss functionは次のようになります。
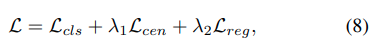
Lclsはclassificationのためのcross-entropyを表しています。λ1とλ2はcenterness lossとregression lossのweightです。trainingの間、λ = 1, λ = 3に経験的に設定しています。
3.3. The Tracking Phase
Trackingは現在のフレームでのtargetのbounding boxを予測することを目指します。位置(i, j)のために提案された手法は6D vector Tij = (cls, cen, l, t, r, b)を生成します。clsはclassificationのforeground scoreを表し、cenはcenterness scoreを表し、l + rとt + bは現在のフレームのwidthとheightを表します。trackingの間、bounding boxのsizeとアスペクト比は連続したフレームを通じて、少しづつ変わります。推論をコントロールするために、6D vectorのアップデートを認めて、clsをre-rankするためのscale change penalty pijを採用しています。trackin phaseは以下のように定式化されます。
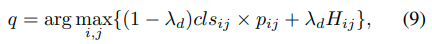
Hはcosine windowでλdはbalance weightです。出力qはtarget pixelにおいて最も高い高いscoreで検索されたlocationです。私達は、qの周りに位置するpixelはよりtarget pixelになることを観察しました。したがって、値clsij×pijに従い、qのn個の近傍から上位k個の点を選択します。最終的な推論結果は、選択されたk個のregression boxesのweighted averageです。経験的に、n = 8とk = 3が安定したtracking resultsをもたらすことを発見しました。
4. Experiments
4.1. Implementation Details
SiamRPN++と同じになるように、template patchとsearch regionの入力サイズはそれぞれ127pixlesと255pixelsに設定しています。また、SiamRPN++でのmodified ResNet-50を私達のSiamse subnetworkとして採用しています。networkはImageNetで事前学習されています。そしてモデルを学習する際の初期値としてpretrained weightsを使っています。
Training Details
- Environment → batchsize 96, 20epochs, SGD, initial learning rate 0.001
- dataset → COCO, ImageNet DET, ImageNet VID, YouTube-BB
Testing Details
testing phaseではoffline tracking strategyを使います。動画の最初のフレームでの物体のみをtemplate patchとして採用します。結果として、Siamese subnetworkのtarget branchは事前にけいsされ、tracking periodの間、修正されます。現在のフレームでのsearch regionはsearch branchの入力として採用されます。Figure3でtracking processの全体像を示しています。
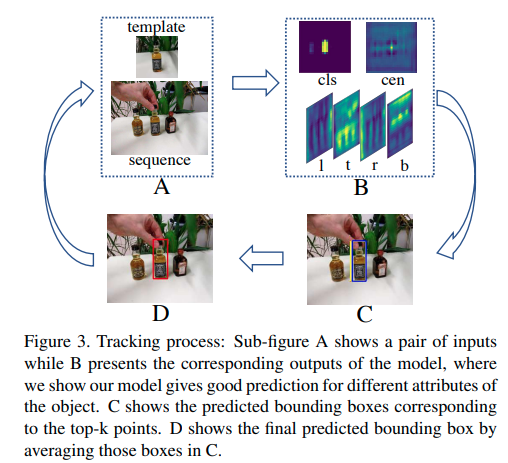
classification-regression subnetworkの出力により、式(9)を通してlocation qが出力されます。隣接したフレーム間でのより安定してスムーズなpredictionを達成するために、qのtop-3 neightborsに対応したregression boxesのweighted averageが最終的なtracking結果として計算されます。異なるデータセットの評価のために、それぞれで提供されている公式の測定方法を用いています。
4.2. Results on GOT-10K
GOT-10K [18]は、最近リリースされた、屋外の一般的な物体追跡のための大規模で多様性の高いベンチマークです。提供されている評価指標は、average overlap(AO)とsuccess rate(SR)です。AOは、推測された全てのbounding boxesとground-truth boxesとの間のaverage overlapsを表しています。SR0.5は、overlapが0.5を超えたframeの割合を示しています。Figure1はSiamCARが全てのtrackerより優れていることを示しており、Table 1は異なった指標で量的な結果を示しています。
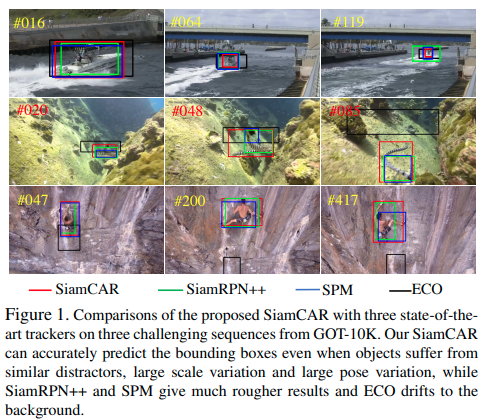
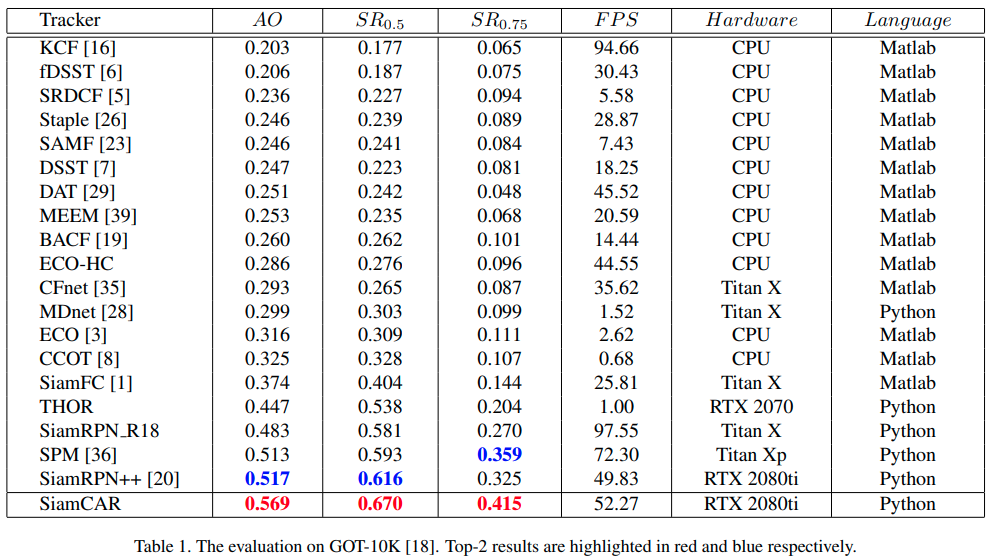
明らかに、私達のtrackerは全ての指標で最高を叩き出しています。SiamRPN++と比べて、AO, SR0.5, SR0.75においてそれぞれ5.2%, 5.4%, 9.0%改善しています。
Table 1で示されているように、他のほとんどのtrackerよりFPSが速いです。
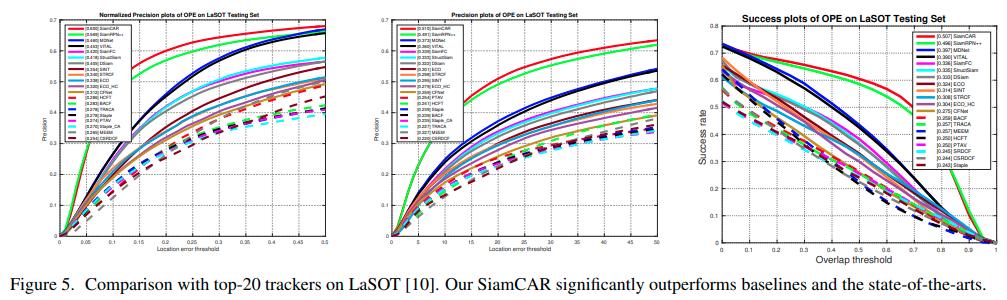
4.3. Results on LaSOT
LaSOTはNormalized precision plots, precision plots, success plotsが評価指標と考えられています。Figure5で示されているように、SiamCARはbest performanceを達成しました。赤いラインのものがSiamCARの結果です。
4.6. Backbone Architecture Evaluation
提案されたframeworkの効率性を検証するために、object trackingのための異なるbackbone architecturesを比較しています。Table 2はResNet-50, ResNet-34, AlexNetをbackbonesとして使ったtracking performanceです。
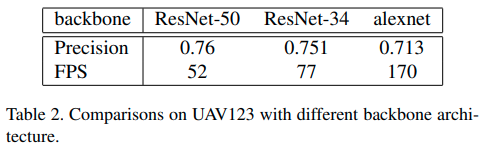
backbone networkを変えることにより、SiamCARのaccuracyとefficiencyを実世界の条件に合わせて、調整ができることがわかります。
個人的な感想
object trackingの手法は全体的にどうしてもFPSが遅くなってしまいます。なので実世界で使うためには、精度だけでなくFPSの速さも重要になってきます。どちらも高いレベルを実現している手法だったので、すごいなと思いました。ただ、精度とFPSともにさらに向上したSiamFC++という手法を最近発見したので、そちらを今度紹介します。
追記: こちらにまとめています。
間違いや質問、ご意見等ありましたらお気軽にコメントください。頑張って答えますので(笑)。