経緯
最近、object trackingについていくつか手法を調査していたので、そのとき調べた手法を共有します。前回、こちらの記事で紹介したSiamCARという手法があるのですが、その手法より速くて正確なSiamFC++という手法を発見したので紹介します。コードはこちらです。
ざっくりとはどんな論文?
- object trackingの設計のためのガイドラインを作ったよ
- 90FPS以上(RTX2080Ti)で動いて、object trackingのタスクでSOTAも達成したよ
0. Abstract
classificationとtarget state estimation branch(G1), 曖昧さのないclassification score(G2), 事前知識のないtracking(G3), estimation quality score (G4)を導入することにより、Fully Convolutional Siamese tracker++ (SiamFC++)を提案します。SiamFC++ trackerは5つのデータセット(OTB2015, VOT2018, LaSOT, GOT-10k, TrackingNet)でSOTAを達成しています。
1. Introduction
trackingは動画上で、動き続ける物体の位置を特定することを目指します。与えられる情報は、ほとんどが初期フレームのアノテーション情報のみです。object tracking独自の特徴の1つとして、object classなどの事前知識がありません。
trackingは、classificationタスクとestimationタスクの組み合わせとして扱われます。1つ目のタスクはclassificationを介して、robustな粗い位置を提供します。2つ目のタスクは正確なtarget state、ほとんどの場合はbounding boxを推測します。近年のtrackerが大きく進展している間、それらの手法は2つ目のタスクにおいて大きく異なっています。それに従い、以前の手法は大きく3つのカテゴリに分けられます。1つ目のカテゴリは、不正確で効果的ではないmulti-scale testを行ったDiscriminative Correlation FilterとSiamFCが含まれます。2番目のカテゴリとして、target bounding boxを推測するためにgradient ascendingを介して、複数の初期bounding boxを反復的に洗練するATOMという手法があります。これは精度において大きな進歩をもたらしました。しかしながら、大きな計算コストをもたらし、多くの追加のハイパーパラメータのチューニングが必要となりました。3つ目のカテゴリはSiamRPN tracker familyです。これは、Region Proposal Network(RPN)を導入することにより、正確で効率的なtarget state estimationを実現します。しかしながら、事前に定義されたanchorの設定はあいまいなsimilarity scoringをもたらすだけでなく、データ分布の事前情報も必要とします。これは、汎用的なobject trackingの精神に反します。前述の分析に動機づけられ、私達は高性能かつ汎用的なobject trackerの設計のためのガイドラインを提供します。
ガイドラインの説明
-
G1: classificationとstate estimationの分解
パワフルな分類器なしには、trackerはbachgroundまたは紛らわしいものからtargetを見分けることはできません。正確な推論結果なしだとtrackerの精度は制限されます。 -
G2: 曖昧さのないscoring
分類スコアは、アンカーボックスのような事前定義された設定ではなく、対応するピクセルのサブウィンドウで、ターゲットの存在の信頼スコアを直接表す必要があります。否定的な例として、オブジェクトとアンカー(アンカーベースのRPNブランチなど)間の一致は、誤検出をもたらす傾向があり、追跡の失敗につながります。 -
G3: 事前知識を使わない
trackingの手法は事前知識を使うべきではありません。事前知識に依存することは、汎化性能の妨げとなります。 -
G4: estimation qualityの評価
以前の研究で示されているように、bounding boxの選択のためにclassification confidenceを直接用いることはパフォーマンスの低下をもたらします。object detectionとtrackingの両方において、多くの研究で言われているようにestimation quality scoreはclassficationと独立したものが使われるべきです。
上記のガイドラインに従って、SiamFC++を設計しています。
正確なtarget estimationのために、G1と並行してregression headを追加しました。事前に定義されたanchorの設定が無くなるので、G2とG3も取り除かれます。最後に、G4に従ってquality assessment branchが追加されています。
私達の貢献は以下の3点に要約されます。
- tracking独自の特徴を認識することで、モダンなtrackerの設計のためのtarget state estimationの実践的なガイドラインを考え出しています
- 私達の提案するガイドラインのアプリケーションと共に、シンプルですがパワフルなSiamFC++ trackerを設計しています。広範囲の実験と分析によりガイドラインの効果を実証しています。
- 私達の手法は5つの難しいベンチマークでSOTAを実現しています。我々の知る限り、90FPS以上でlarge-scale TrackingNet
datasetにおいてAUC score of 75.4を達成したのはSiamFC++が初めてのtrackerです。
2. Related Works
Detection Framework
物体追跡タスクには、物体検出と多くの共通点があります。例えば、Faster-RCNNをもとに考案されたRPN構造はSiamRPNにおいて驚異的な精度を達成しました。Faster-RCNNを継承した多くのSOTAのtrackerはanchor-based detectorsと名付けられ、RPN構造とanchor boxを採用しています。アンカーベースの検出器は、アンカーと呼ばれる事前定義されたboxを使って分類し、bounding boxの位置の予測をします。しかし、ハイパーパラメータのチューニングが精度に大きな影響を及ぼし、人の負担が大きくなります。研究者は、物体の中心に近い点のbounding boxを予測したり、bounding boxのコーナーのペアを検出してグルーピングするなどのanchor-free detecotrsを設計するために様々な方法に挑戦してきました。
3. SiamFC++: Fully Convolutional Siamese Tracker for Object Tracking
このセクションでは、私達のFully Convolutional Siamese tracker++について詳しく説明します。SiamFC++はSiamFCに基づいており、ガイドラインに従って改良されています。
Siamese-based Feature Extraction and Matching
trackingタスクはsimilarity learningと見ることができます。siamese networkは2つのブランチで構成されます。template branchは、入力として最初のフレームのtarget patchを取ります(zとします)。search branchは入力として現在のフレームを取ります(xとします)。siamese backboneは、2つのブランチの間でパラメータを共有し、input zとxで次のタスクのために共通の特徴空間に埋め込むために同じように変形したものを出力します。埋め込み空間φにおいて、template patchとsearch patchの間でのcross-correlationが出力されます。
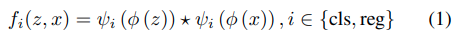
*はcross-correlationを示しており、φ()はcommon feature extractionのためのsiamese backboneを示しています。ψi() はタスク固有のlayerを示しており、iはsubtask type(clsはclassficationでregはregression)を示しています。私達の実装では、共通の特徴量をタスク固有のfeature spaceに適合させるためのcommon feature extractionの後に、ψclsとψregの両方のために2つのconvolution layersを用いています。
cross-correlation→1であれば正の相関、0であれば無相関、-1であれば負の相関となる。参照元
Application of Design Guidelines in Head Network
SiamFCをベースに、ガイドラインに従ってそれぞれのパートで改善しました。
G1に従って、埋め込み空間におけるcross-correlationの後、classification headとregression headの両方を設計しています。feature mapにおけるそれぞれのピクセルにおいて、classification headは入力としてψclsを取り、対応するimage patchを正または負のpatchとして分類します。一方で、regression headは入力としてψregを取り、bounding boxの位置の予測を改善するために追加のoffsets regressionを出力します。headの構造はFigure2のcross-correlationの後に位置しています。

classificationでは、対応している位置がground truthのbounding boxと一致していればfeature map ψclsは正のサンプルとみなされます。もし違えば、負のサンプルとなります。ここでsはbockboneのstrideの合計です(この論文では、s=8)。feature map ψregにおける各positive location (x, y)のregression targetのために、final layerは対応した位置からground-truth bounding boxの4つの側面の位置を距離を予測し、4D vector t* = (l*, t*, r*, b*)として示されます。したがって、location(x, y)のためのregression targetsは次のように定式化されます。
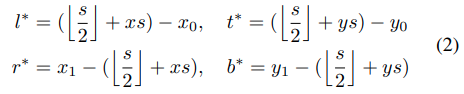
(x0, y0)と(x1, y1)はgroung-truth bounding box Bの左上と右下を表しています。
G2に従って、位置に対応したimage patchを直接分類し、target bounding boxを回帰します。言い換えれば、SiamFC++は位置をtraining sampleとして直接表示します。入力画像上の場所を複数のアンカーボックスの中心と見なすanchorベースの手法は、同じ場所で複数の分類スコアを出力します。 そして、これらのアンカーボックスに関してターゲットbounding boxを回帰し、アンカーと物体の間のあいまいな一致につながります。
SiamFC++は位置に関して、classificationとregressionを行いますが、事前に定義したanchor boxはいりません。target のデータ分布に関する事前の知識はいらず、これはG3に準拠しています。
G4に従って、Figure2の右で示されているように並列の1 * 1 convolution classfication headを加えることにより、シンプルですが効果的なassessment branchを付け加えました。出力は下で定義されているPrior Spatial Score(PSS)です。
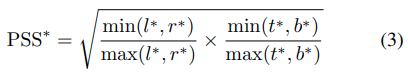
推論したboxとground-truth boxesとのIoUも取得できます。
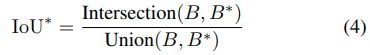
Bは予測したbouding boxで、Bはそれに対応するground-truth bounding boxです。
推論の間、最終的なboxの選択のために使われるscoreは、予測されたclassification scoreに一致したPSSを掛けることによって計算されます。このやり方では、物体の中心から遠いbounding boxのscoreは低くなります。それにより、tracking精度は改善されます。
Training Objective
training objectiveを次のように最適化します。
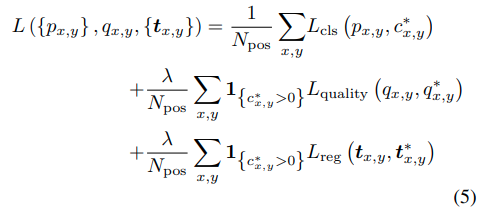
1{}は条件を満たした場合1をとり、なかった場合0をとりま。Lclsはclassification resultのためのfocal lossで、Lqualityはquality assessmentのためのbinary cross entropy(BCE) lossを表し、Lregはbounding boxのためのIoU lossを示しています。もし(x,y)が正のsampleだと考えられる場合、C*x,yに1を割り当て、負のsampleの場合は0を割り当てます。
4. Experiments
Implementation Details
Model settings
この研究では、異なるbackbone architectureをもつ2つのバージョンのtrackerを実装しています。1つはAlexNetの変更版を採用したSiamFC++-AlexNetです。もう1つは、GoogLeNetを使ったSiamFC++-GoogLeNetです。後者の手法は低い計算コストでResNet-50を使った手法よりtrackingベンチマークにおいて、同等かそれ以上のパフォーマンスを達成しています。どちらのネットワークもImageNetで事前学習されています。
Training data
基本的なtraining setとしてILSVRC-VID/DET, COCO, YoutubeBB, LaSOT, GOT-10kを採用しています。モデルの紛らわしいものを見分ける能力を高めるために、training sampleに負のsampleを含ませています。
Training phase
AlexNet版では、conv1からconv3, fine-tune conv4, conv5のパラメータを固定します。GoogLeNet版では、stage 1, 2, fine-tune stage 3, 4を固定します。
AlexNet版のtrackerは VOT2018 short-term benchmarkにおいて160FPS出ます。GoogleNet backboneの方は、VOT2018 short-term benchmarkにおいて90FPS出ます。RTX 2080Ti GPUを用いた場合です。
Test phase
私達のモデルの出力は、cofidence scores sに対応したbounding boxesのセットです。Scoreは直近のフレームにおいて、一致したboxの予測されたtarget positionからの距離や大きさ、縦横の割合に基づいて、与えられます。最も高いscoreを持ったboxが選ばれ、target stateをアップデートするために使われます。
From SiamFC towards SiamFC++
どちらもper-pixel predictionのやり方を取っていますが、SiamFCとSiamFC++の間には性能の大きな差があります。
結果がTable1に示されています。

学習データを追加したり、より良いhead structureを適用したり、より正確な推定のためにregression branchを追加したりすることにより徐々にSiamFCをアップデートしました。さらに、AlexNetをより強力なGooLeNetに置き換えました。
tracking performanceのための重要な要素は次の順番にリスト化出来ます。regression branch
(0.094), データの多様性(0.063/0.010), より強力なbackbone (0.026), より良いhead structure (0.020)という順番です。カッコ内にそれぞれのパートによってもたらされた∆EAO(Expected Average Overlap)が記されています。追加の要素をSiamFCに追加した後、少ない計算リソースで優れたperformanceを達成しました。
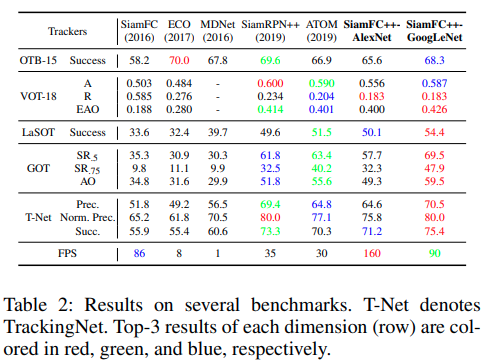
Results on Several Benchmarks
Table2にベンチーマークと結果を載せています。
Comparison with Trackers that Do not Apply Our Guidelines
SiamRPN familyはここ数年visual trackingにおいて大きな成功をあげており、trackingコミュニティからかなりの注目をあびてきました。ここではSOTAのSiamRPN++ trackerを例に使います。SiamRPN familyの最近の成功にも関わらず、私達はSiamRPN familyが私達の提案するガイドラインに従っていないことを発見しています。
- (G2) SiamRPNのclassification scoreはtemplate objectとobjectsというよりは、anchorとobjectの類似性を表しており、これはマッチングの曖昧さをもたらす可能性があります。
- (G3) 事前に準備したanchor boxの設計はtargetのサイズと縦横のアスペクト比の事前知識を必要とします。
ガイドラインG2の違反の結果により、SiamRPN familyがfalse-positiveをもたらす傾向があることを、経験的に発見しています。言い換えれば、SiamRPNはtarget objectに外見上のバリエーションがあると、近くの物体や背景に理由もなく高い数値を与えてしまうということです。Figure1で示されているように、SiamRPN++はout-of-plane rotationやdeformationのような難しいシナリオの場合、近くの物体に高い数値を与えてしまうことにより、target objectの追跡に失敗していることがわかります。

G3の違反により、SiamRPNのパフォーマンスはanchorの大きさやアスペクト比によって異なります。best performanceはデータの分布の事前知識を活かすことのみにより達成され、これは汎用的なobject trackingの精神に反しています。
5. Conclusion
この論文では、trackerの設計においてtrackingタスク特有の特徴や以前のtrackerの流れを分析することにより、target state estimationのためのガイドラインを提案します。ガイドラインに従って、classificationとtarget state estimationにおいて効率的(G1)で、曖昧さがないclassification score(G2)を与え、事前知識なしでtrackingし(G3)、estimation qualityを意識する(G4)私達の手法を提案します。広範囲の研究により提案されたガイドラインの効果を検証しています。また、これらのガイドラインに基づいた私達のtrackerが、90FPSで5つの難しいベンチマークでSOTAを実現していることを示しています。
まとめ
アンカーフリーが主流になってるみたいですね。あと、FPSが遅いと使いものにならないので、そこらへん研究者の方お願いします(笑)。
間違いや質問、ご意見等ありましたらお気軽にコメントください。頑張って答えますので(笑)。