経緯
arxivで論文の要約を読んで、面白そうだったらmendleyにストックするという作業を毎日していたのですが、面倒くさくなってきたので自動化することにしました。ちなみにCVPR2020の論文収集を自動化した記事はこちらです。前回はherokuにデプロイしましたが、今回はCloud functionsとCloud schedulerを使っていきたいと思います。
システム要件
- arxivの中で自分の興味のあるカテゴリ(今回はcs.CV)から論文のタイトル、要約、pdfのリンクを取得する。要約に関しては和訳もする。
- 取得した情報をcloud functionsとcloud shedulerで毎日定期実行して、slackに通知する。
システム構成
システム構成は下の図のようになります。まず、Cloud schedulerから定期的にCloud functionsを呼び出します。呼び出されたCloud functionsはarxivから論文データを取得してslackに通知します。slackへの通知にはincoming webhookを使います。
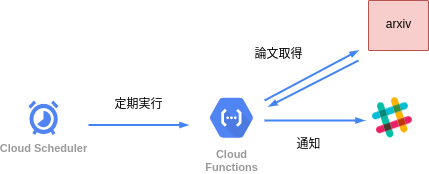
Step.1 arxivから論文情報を取得
arxivから論文情報を取得するときは、arxiv APIのPythonのラッパーであるライブラリarxivを使います。詳しい使い方はこちらで説明されています。今回はarxivのcs.cvのカテゴリーの論文を取得するので以下のコードで論文情報を取得します。submittedDateの後の{}に日付を入れると、期間で論文の絞り込みができます。
import arxiv
cv_papers = arxiv.query(query='cat:cs.cv AND submittedDate:[{} TO {}]'.format(dt_day, dt_last), sort_by='submittedDate')
1日に2回(昼12時と夜0時)に分けて1週間前の論文を取得します。arxivは更新が少し遅いので、取得する論文のsubmittedDateは1週間前にしています。プログラムが実行される時刻で場合分けしています。
import arxiv
import time
import pytz
import datetime
dt_now = datetime.datetime.now(pytz.timezone('Asia/Tokyo'))
dt_old = dt_now - datetime.timedelta(days=7)
dt_all = dt_old.strftime('%Y%m%d%H%M%S')
dt_day = dt_old.strftime('%Y%m%d')
dt_hour = dt_old.strftime('%H')
if dt_hour == '00':
dt_last = dt_day + '115959'
cv_papers = arxiv.query(query='cat:cs.cv AND submittedDate:[{} TO {}]'.format(dt_day, dt_last), sort_by='submittedDate')
else:
dt_last = dt_day + '235959'
cv_papers = arxiv.query(query='cat:cs.cv AND submittedDate:[{} TO {}]'.format(dt_all, dt_last), sort_by='submittedDate')
Step.2 論文情報を整形してslackに通知する
今回は論文のタイトル、要約、pdfのリンクを取得します。また、googletransを使って要約を和訳します。使い方はこちらにまとめてあります。slackに通知するところでは、slackのincoming webhookを使っています。googletransの使い方はこちらが参考になるかと思います。
import slackweb
from googletrans import Translator
translator = Translator()
for cv_paper in cv_papers:
title = cv_paper['title']
pdf = cv_paper['pdf_url']
summary = cv_paper['summary']
summary = ''.join(summary.splitlines())
summary_ja = translator.translate(summary, src='en', dest='ja')
summary_ja = str(summary_ja.text)
attachments_title = []
attachments_contents = []
paper_title = {"title": title,
"text": pdf}
paper_contents = {"title": summary,
"text": summary_ja}
attachments_title.append(paper_title)
attachments_contents.append(paper_contents)
slack = slackweb.Slack(url=" ")
slack.notify(attachments=attachments_title)
slack.notify(attachments=attachments_contents)
time.sleep(1)
slackweb.Slack(url=" ")のところには、通知するslack用のincoming webhookのurlを入れてください。"title"に指定している文章は"text"より文字が太くなって、slackに通知されます。slackの呼び出し回数には時間単位で制限があるので、time.sleep()を使って間隔を空けています。
Step.3 Cloud functionsで作成したコードを実行してみる
Cloud functionsにコードを載せて実行するところまで説明します。まずは、Cloud functionsの関数を作成、のボタンを押して下の画面に移ります。
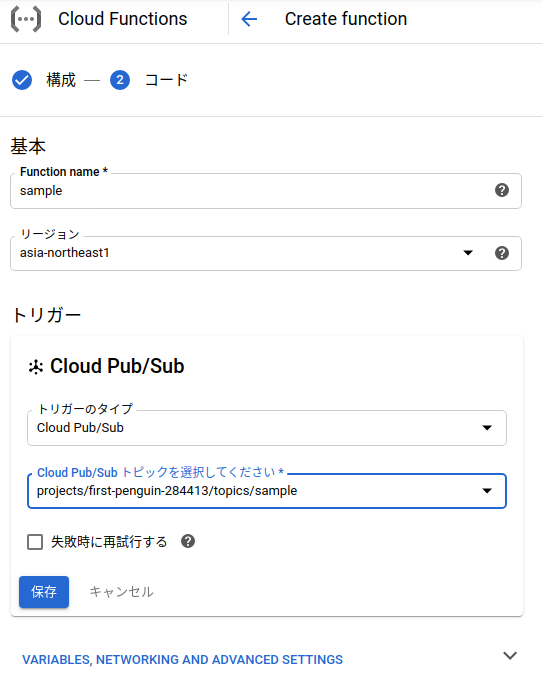
function nameは適当に決めて、リージョンはasia-northeast1にします。トリガータイプpub/subにして、トピックを作成します。このトピックはcloud schedulerと連携させるときに使うので、自分がつけたトピック名は覚えておいてください。それが終わったら保存を押して、下のVARIABLES~を押します。すると、下の画面が出てくるので、念のためにタイムアウトをデフォルトの60から120に変更します。完了したら、次へのボタンを押します。
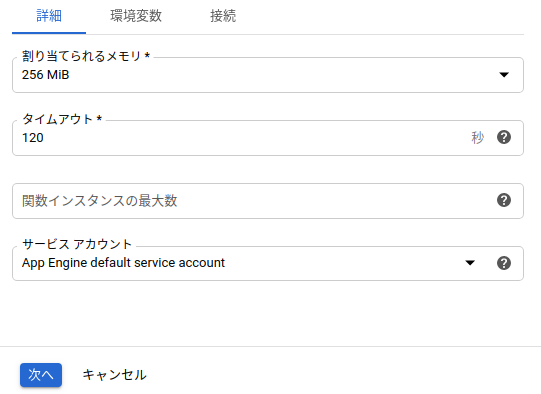
ボタンを押すと下の画面に移ります。ランタイムを自分が使っているpythonに合わせて選択してください。また、エントリポイントも実行したい関数名を入力してください。今回は、main関数のみなので、mainと入力します。
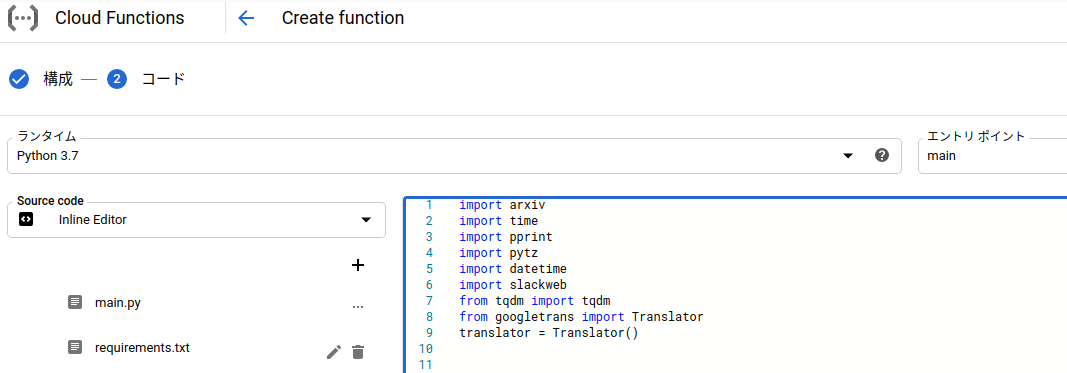
main.pyには下のコードを上の画像の右側にそのまま貼り付けます。画像の左側のrequirements.txtには、必要なパッケージのバージョンが書いてあるrequirements.txtの中身をそのまま貼り付ければ大丈夫です。
import arxiv
import time
import pprint
import pytz
import datetime
import slackweb
from tqdm import tqdm
from googletrans import Translator
translator = Translator()
def main(data, context):
try:
dt_now = datetime.datetime.now(pytz.timezone('Asia/Tokyo'))
dt_old = dt_now - datetime.timedelta(days=7)
dt_all = dt_old.strftime('%Y%m%d%H%M%S')
dt_day = dt_old.strftime('%Y%m%d')
dt_hour = dt_old.strftime('%H')
if dt_hour == '00':
dt_last = dt_day + '115959'
cv_papers = arxiv.query(query='cat:cs.cv AND submittedDate:[{} TO {}]'.format(dt_day, dt_last), sort_by='submittedDate')
else:
dt_last = dt_day + '235959'
cv_papers = arxiv.query(query='cat:cs.cv AND submittedDate:[{} TO {}]'.format(dt_all, dt_last), sort_by='submittedDate')
for cv_paper in cv_papers:
title = cv_paper['title']
pdf = cv_paper['pdf_url']
summary = cv_paper['summary']
summary = ''.join(summary.splitlines())
summary_ja = translator.translate(summary, src='en', dest='ja')
summary_ja = str(summary_ja.text)
attachments_title = []
attachments_contents = []
paper_title = {"title": title,
"text": pdf}
paper_contents = {"title": summary,
"text": summary_ja}
attachments_title.append(paper_title)
attachments_contents.append(paper_contents)
slack = slackweb.Slack(url="")
slack.notify(attachments=attachments_title)
slack.notify(attachments=attachments_contents)
time.sleep(1)
except Exception as e:
print(e)
実行する関数の引数にdata,contextを入れることを忘れないでください。多分、トリガーのような役割だと思います。違ったら教えてください。
Step.4 Cloud shedulerで定期的にプログラムを実行
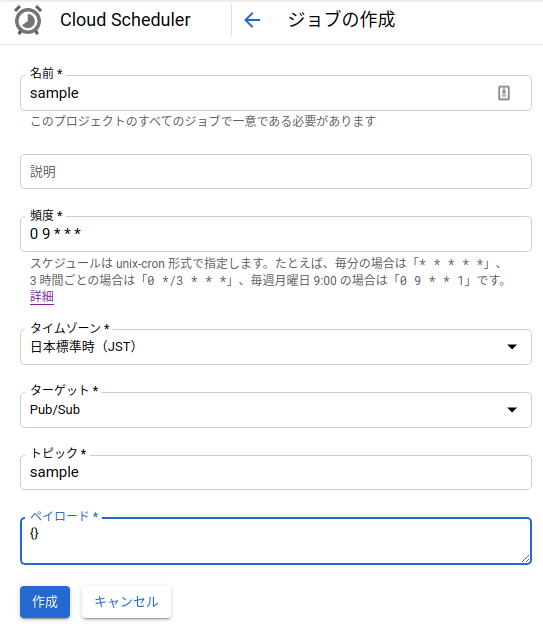
ここまで来たら、あとはcloud schedulerで先程作成したCloud functionsの関数を定期実行するだけです。まずは、Cloud schedulerのコンソール画面に行き、ジョブを作成というボタンを押します。すると下の画像の画面になります。名前は適当につけてください。頻度はcron形式で書いてください。画像の場合は毎日9時に実行されます。ターゲットをPub/Subに指定すると、トピック名が出てくるので、先程cloud functions側で入力したトピック名を入力してください。ペイロードを{}にして作成ボタンを押すと完成です。テストをしてくれるボタンがあるので、念のためにやってみてください。
まとめ
完成したものはこんな感じになります。

Cloud functionsとCloud schedulerの組み合わせはすごく相性がいいので、是非皆さんも色んなものを作ってみてください。
間違いや質問、ご意見等ありましたらお気軽にコメントください。頑張って答えますので(笑)。