はじめに
最近のInstanaのリリース1.0.311によって、k8sのコントロールプレーンのメトリック取得による可視化が可能となりました。これによって、以下のようなk8s全体で問題がある時に、コントロールプレーンでも原因を探せるようになります。
Instanaが監視するコントロールプレーンコンポーネント:
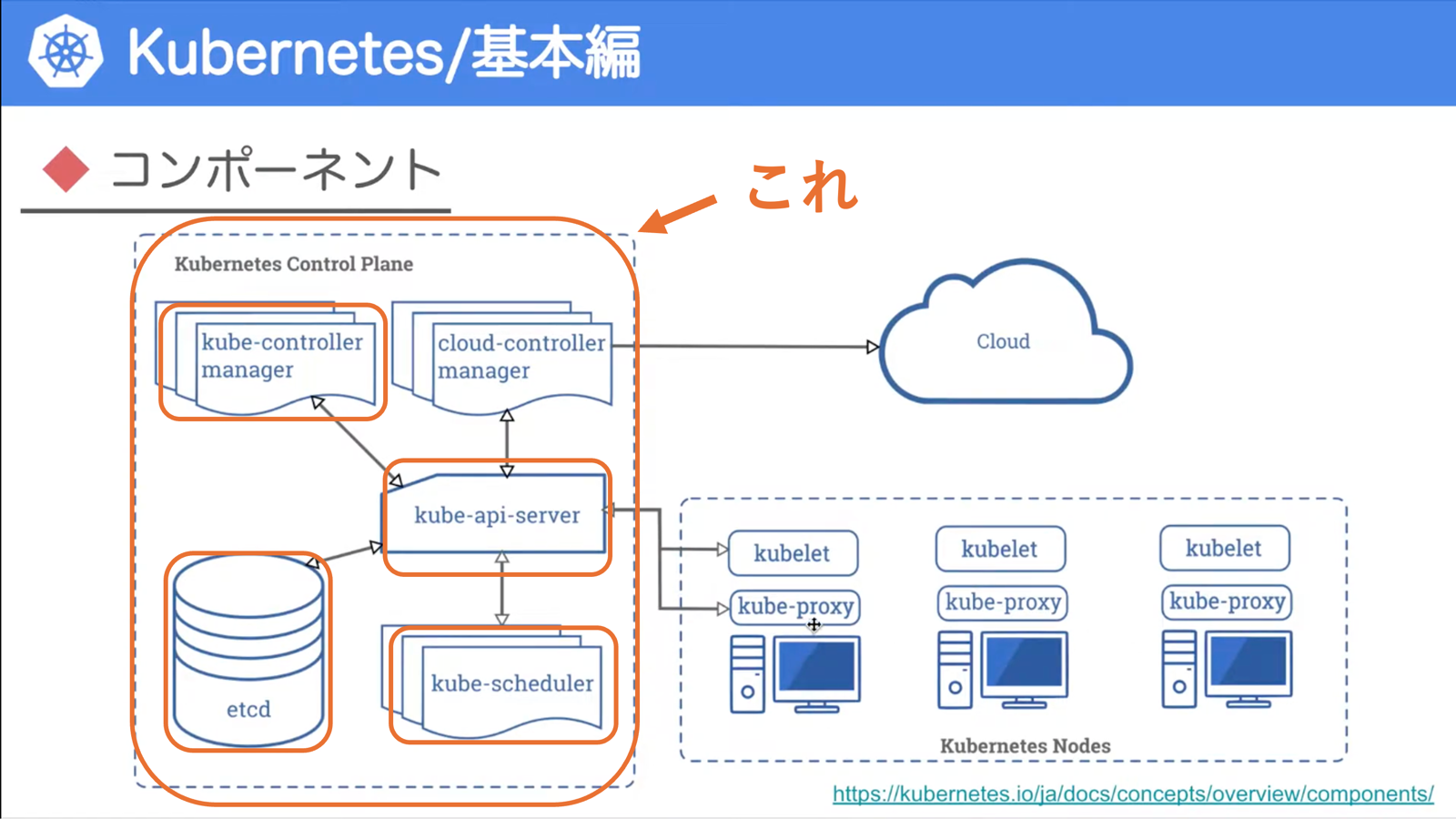
| コンポーネント | 役割 | 運用でどういう時に確認するか? |
|---|---|---|
| APIサーバー | コントロールプレーンの中核。 |
全体的なパフォーマンス - Pod作成やDeployment更新が遅い場合 - リクエスト遅延(Request Latency)が長い場合 |
| Scheduler | Podをノードに割り当てる。 |
Pod関連の問題 - PodがPendingのまま起動しない - Scheduling Latencyが長い - Failed Schedulingが増加 |
| etcd | クラスタ全体の状態情報の保存庫。 | - クラスター操作全体が遅い - 状態反映が遅い - Request Latencyが高い場合 |
| Controller Manager | 自動制御ループや自己回復の実行。 | - Podの増減や復旧が遅い - 処理時間が長く、自動制御ループが詰まっている可能性 |
監視手順(Instana UI)
-
コントロールプレーン画面に移動
ナビゲーション: プラットフォーム → Kubernetes -
各コンポーネントのメトリクス確認
- APIサーバー: リクエスト遅延やエラー数
- Scheduler: Pending Pod、Scheduling Latency、Failed Scheduling
- etcd: Request Latency、クラスタ状態更新速度
- Controller Manager: 処理時間、Pod復旧速度
1.コントロールプレーン画面に移動
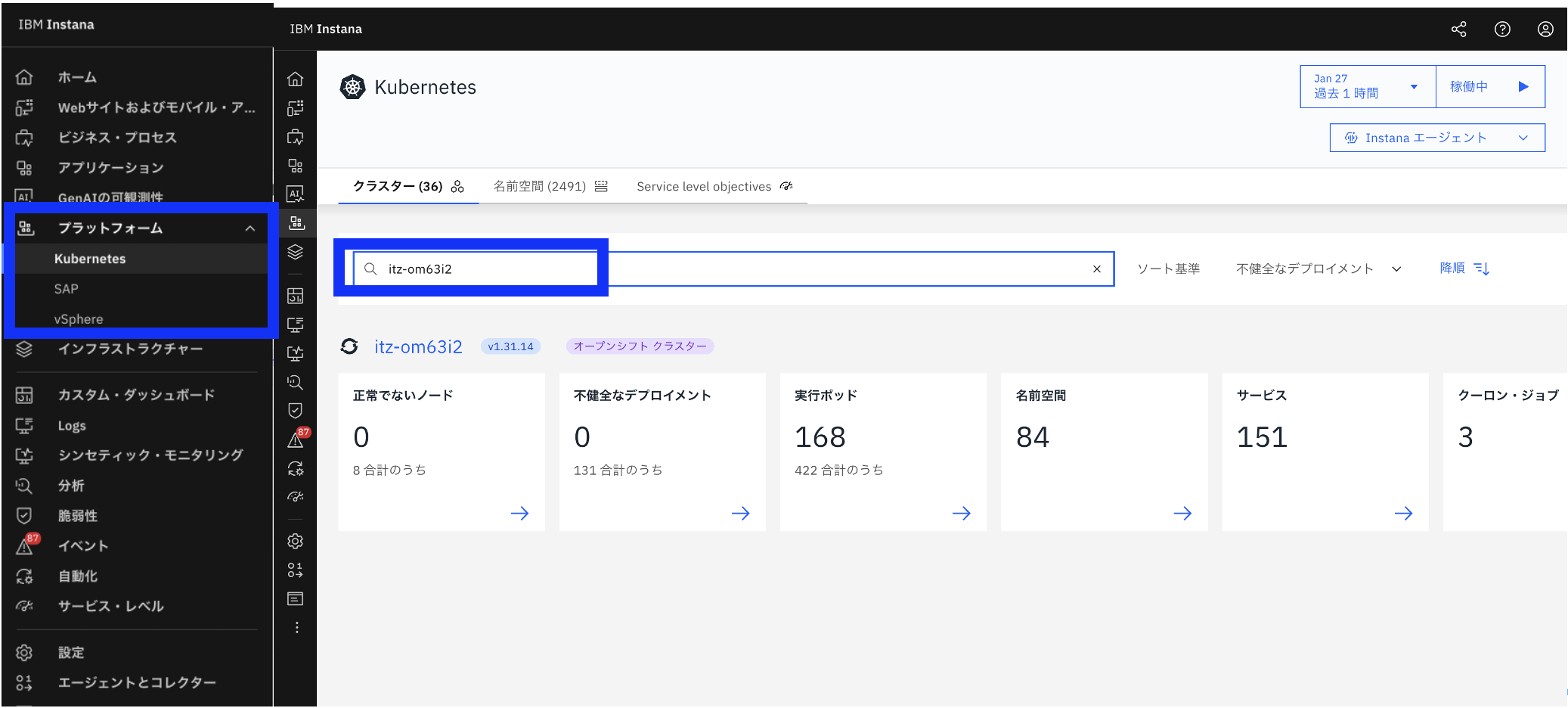
コントロールプレーンコンポーネントの確認は、プラットフォーム→kubernetesから行います。
2. 各コンポーネントのメトリクス確認
① Kubernetes API サーバー(重要)
Kubernetes APIサーバーは中心にあるので、全体がなんとなく遅いな、、重いな、、と思った時に一番初めに見る場所となります。

たとえば、
Pod 作成や Deployment 更新が遅い時、かつ
APIサーバーの要求遅延時間が伸びている場合
ワーカーノードではなくAPIサーバー側の処理詰まりが原因である可能性が高いです。
② Scheduler(重要)
Pod周りの問題が出た時に確認します。

たとえば、
Pod が Pending のまま起動しない時 かつ
スケジューリングの Scheduling Latency が長くなっている、または Failed Scheduling が増えている場合、
Pod を置くノードの選択や制約条件の評価に時間がかかっているか、リソース不足やノード設計の問題がある可能性が考えられます。
③ etcd
あまり頻繁には確認しないかも
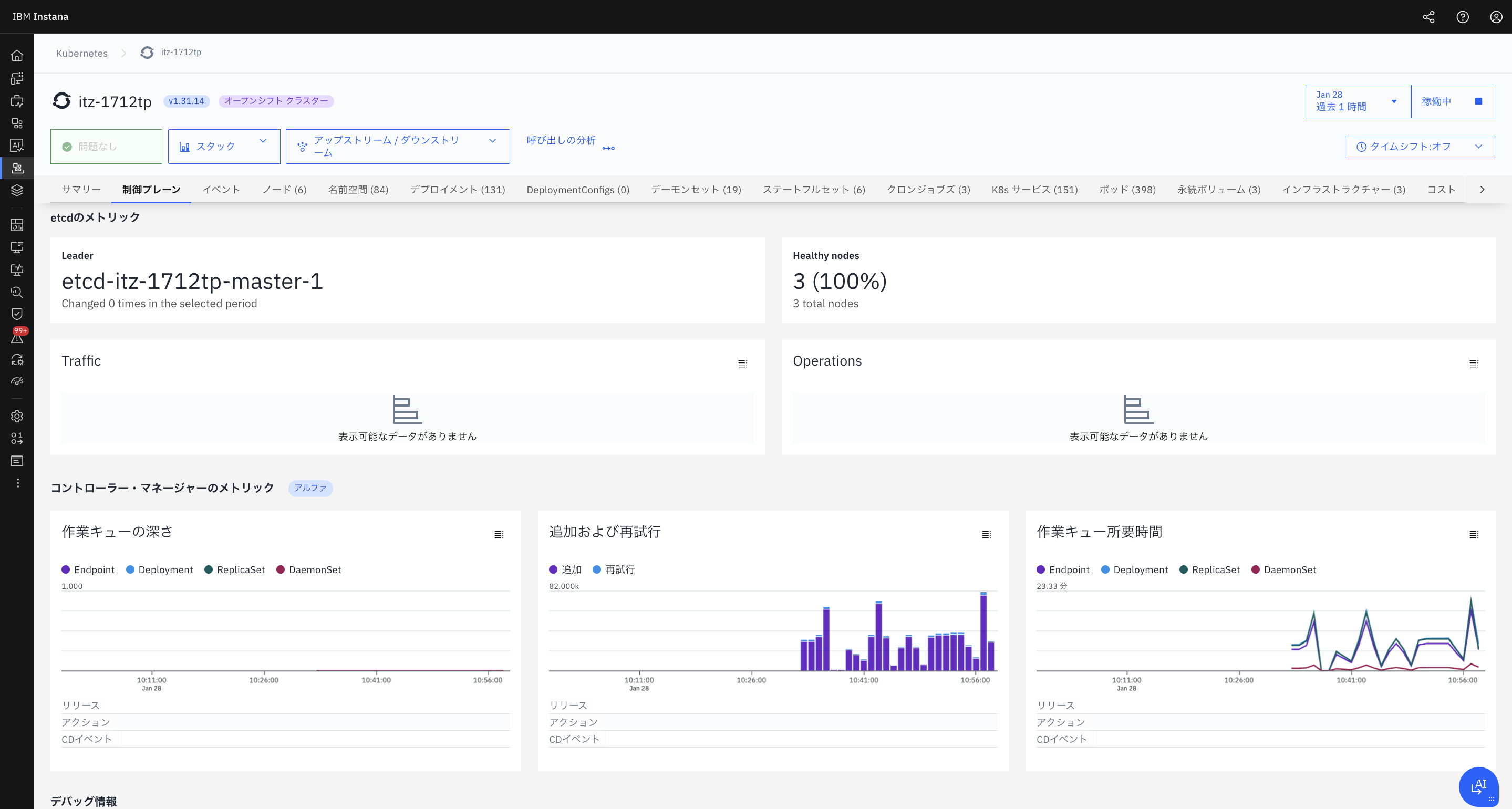
etcd のメトリクスを見ることで、
Kubernetes の状態情報が正常に保存・更新されているかを確認できます。
たとえば、
クラスター全体の操作が遅く、状態反映にも時間がかかる時に
etcdのRequest Latency が高くなっている場合、
Pod 状態や設定変更の保存処理が遅れ、
etcd 側がボトルネックになっている可能性が高いです。
④ コントローラーマネジャー
あまり頻繁には確認しないかも

コントローラーマネジャーのメトリクスを見ることで、
Kubernetes の自動制御や自己回復が正常に機能しているかを確認できます。
たとえば、
Pod 数の増減や復旧がなかなか反映されない時に
コントローラーの処理時間が長くなっている場合、
自動制御ループが詰まっている原因が大きいと考えられます。
まとめ
まとめると、
- 全体的に調子悪いなという時に、APIサーバーを確認
- Pod周りの問題が多いなという時に、Schedulerを確認
- その他etcd, Controller Managerも可視化することによって、状態保存や自動制御といった 制御プレーン内部の詰まり まで追えるようになります。
これによって、
「クラスターが全体的に遅い」、
「なんとなく不安定」
という状態に対してよりなんとなくではなくメトリクスをもとな段階的な原因特定を行えるようになるのではないかと思います!