ローカル環境にFirecrawlをセルフホストし、Difyから利用してみます。
環境
DifyサーバとFirecrawlサーバは別VMとして構成します。
Difyサーバ
$ cat /etc/os-release PRETTY_NAME="Ubuntu 22.04.5 LTS"

Firecrawlサーバ
$ cat /etc/os-release PRETTY_NAME="Ubuntu 24.04.3 LTS"
Firecrawl インストール
初期設定
sudo timedatectl set-timezone Asia/Tokyo
sudo apt install vim -y
sudo apt update
sudo apt upgrade -y
dockerインストール
sudo apt-get install -y apt-transport-https ca-certificates curl gnupg-agent software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt-get update
sudo apt install -y docker-ce docker-ce-cli containerd.io
docker --version
sudo apt install -y docker-compose-plugin
docker compose version
Firecrawlインストール
git clone https://github.com/mendableai/firecrawl.git
cd firecrawl
cp apps/api/.env.example .env
cat .env
vi .env
----------------
USE_DB_AUTHENTICATION=false
TEST_API_KEY=fc-my-firecrawl-20251123
----------------
cat .env
sudo docker compose up -d
sudo docker compose ps
TEST_API_KEYはfc-から始める必要があります。
docker composeでコンテナを初回ビルドする際、私の環境では10分程度かかりました。
Firecrawl単体確認
Firecrawlサーバ上でcurlコマンドを利用して動作確認
curl -v http://localhost:3002
----------------
* Host localhost:3002 was resolved.
* IPv6: ::1
* IPv4: 127.0.0.1
* Trying [::1]:3002...
* Connected to localhost (::1) port 3002
> GET / HTTP/1.1
> Host: localhost:3002
> User-Agent: curl/8.5.0
> Accept: */*
>
< HTTP/1.1 302 Found
< X-Powered-By: Express
< Access-Control-Allow-Origin: *
< Location: https://docs.firecrawl.dev/api-reference/v2-introduction
< Vary: Accept
< Content-Type: text/plain; charset=utf-8
< Content-Length: 78
< X-Response-Time: 0.277ms
< Date: Sun, 23 Nov 2025 03:10:26 GMT
< Connection: keep-alive
< Keep-Alive: timeout=5
<
* Connection #0 to host localhost left intact
Found. Redirecting to https://docs.firecrawl.dev/api-reference/v2-introduction
----------------
Firecrawlサーバの外部からブラウザで以下を打鍵
http://[FirecrawlサーバのIP]:3002
→Firecrawlのdocumentにリダイレクトします。
Difyからの接続
Difyのインストール自体は以下の記事を参考にしてください。
AzureにセルフホストしたDifyからAzure OpenAI Serviceにプライベート接続する
4.Difyインストール
https://qiita.com/Higemal/items/d32ac73db6fa67851704#4dify%E3%82%A4%E3%83%B3%E3%82%B9%E3%83%88%E3%83%BC%E3%83%AB
ツール画面からFirecrawlをインストールします。
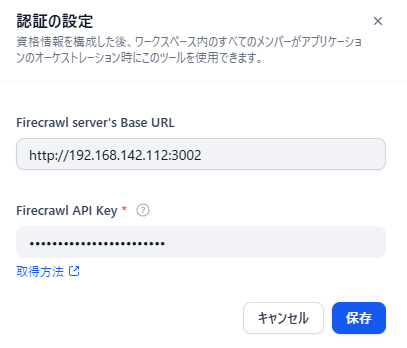
認証設定を実施します。

Firecrawl試用
エージェントアプリを作成し、ツールからFirecrawlを選択します。
今回はScrapeを利用してみます。
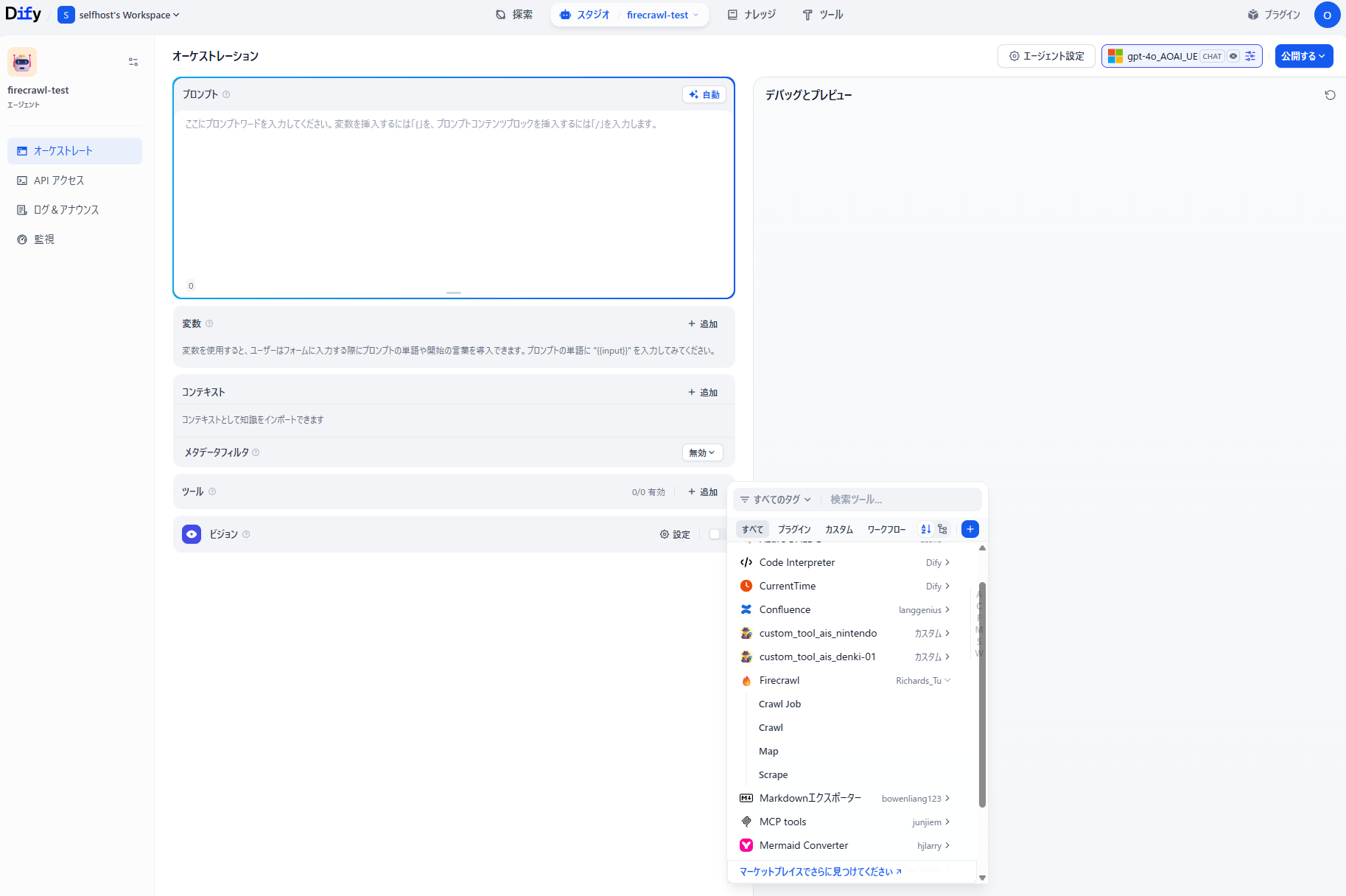
| Tool | Description |
|---|---|
| Crawl Job | ジョブIDに基づいてスクレイピング結果を取得したり、進行中のスクレイピングタスクをキャンセルしたりできます。ワークフローの管理や監視に最適です。 |
| Crawl | ウェブサイトのサブドメインを再帰的にクロールし、コンテンツを収集します。相互に関連するページから大規模なデータセットを抽出するのに最適です。 |
| Map | サイトマップを作成します。 |
| Scrape | 任意のURLをクリーンで構造化されたデータに変換し、生のHTMLを実用的なインサイトへと変換します。 |
簡単なプロンプトを利用して、URL内容取得とLLMによる要約が実施できました。
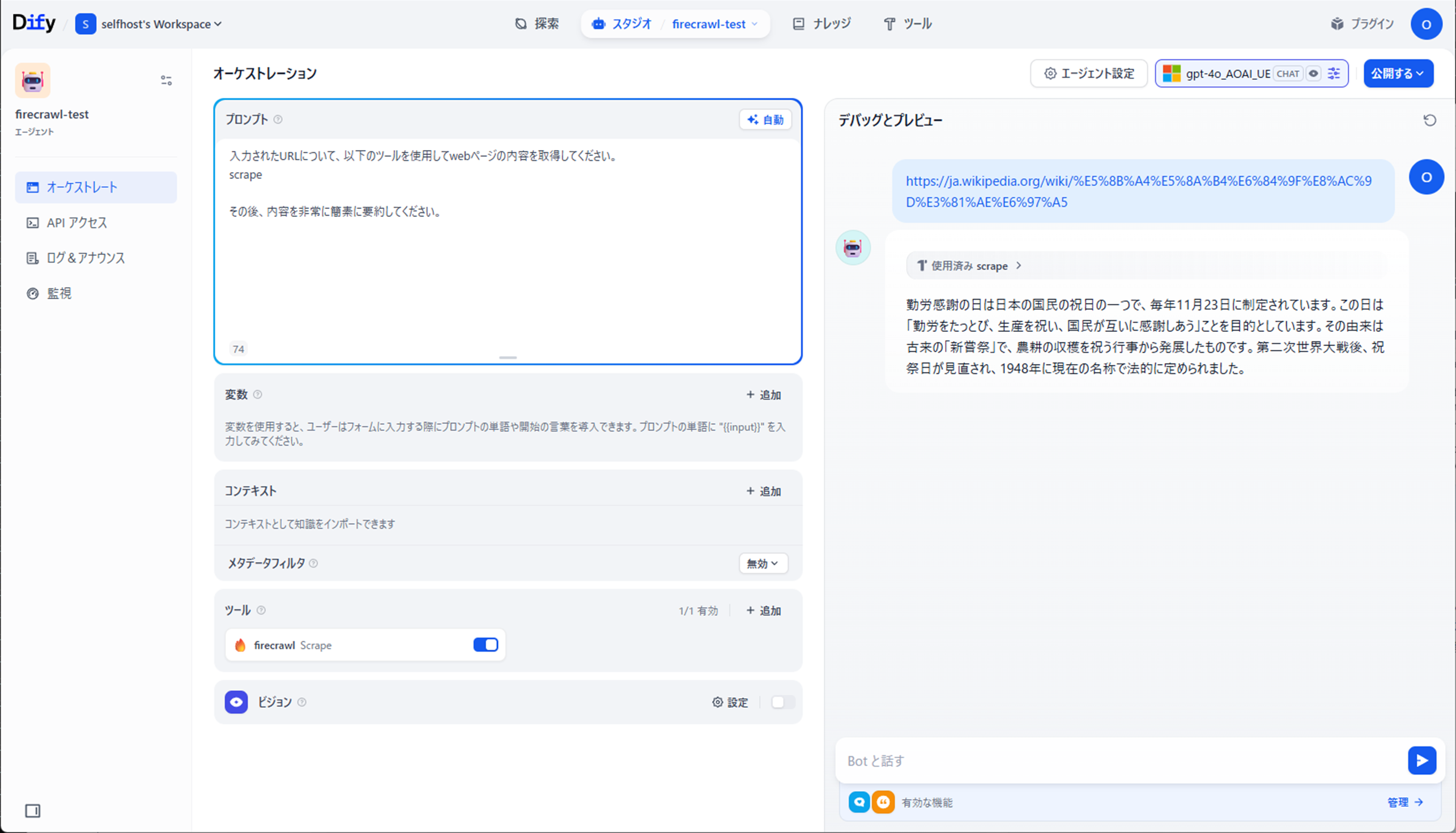
Firecrawlちょっとだけチューニング
Webサイトによっては、テキストボリュームが非常に多くなることから、LLMに直接入力させるとトークン超過エラーが発生します。
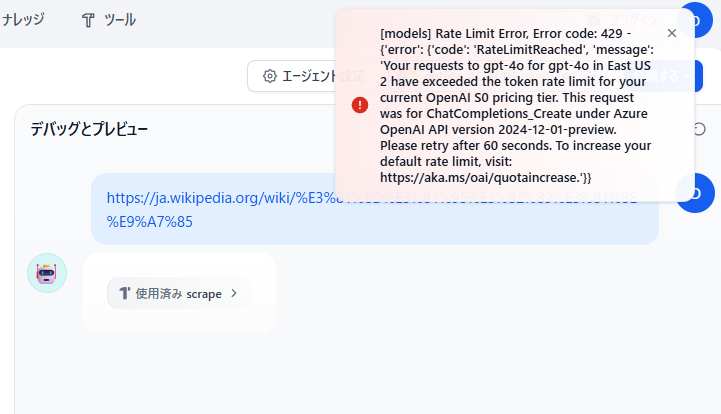
エラー内容
[models] Rate Limit Error, Error code: 429 - {'error': {'code': 'RateLimitReached', 'message': 'Your requests to gpt-4o for gpt-4o in East US 2 have exceeded the token rate limit for your current OpenAI S0 pricing tier. This request was for ChatCompletions_Create under Azure OpenAI API version 2024-12-01-preview. Please retry after 60 seconds. To increase your default rate limit, visit: https://aka.ms/oai/quotaincrease.'}}
Scrapeツールでは以下の設定が可能となるため、チューニングが実施できます。
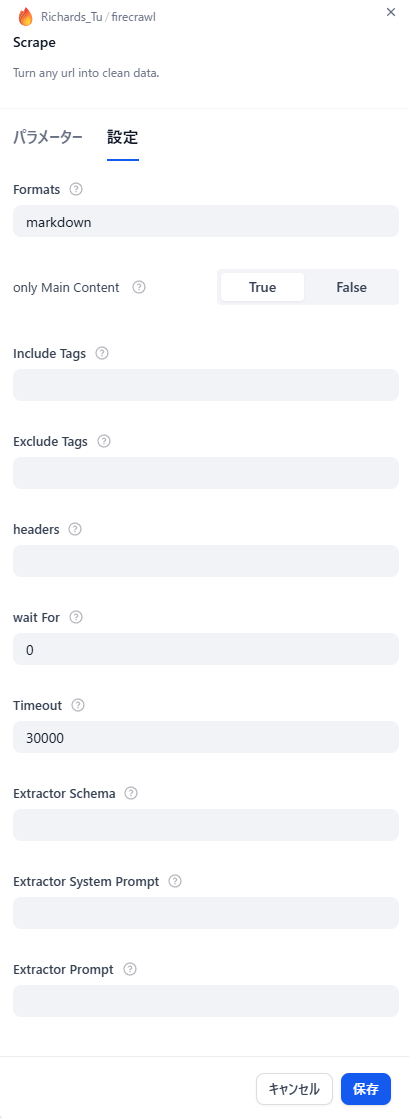
| 設定 | 内容 | 入力内容 | デフォルト |
|---|---|---|---|
| Formats | スクリプトの出力フォーマットを指定 | markdown,html,rawHtml,links,screenshot,extract,screenshot@fullPae | markdown |
| only Main Context | 指定ページのみ抽出 | True,False | False |
| include Tags | 取得するHTMLタグ | (任意) | (None) |
| Exclude Tags | 取得しないHTMLタグ | (任意) | (None) |
| headers | 送信するヘッダー | (任意) | (None) |
| wait For | ページアクセスから取得までの待機時間[msec] | (任意) | 0 |
| Timeout | ページ応答タイムアウト[msec] | (任意) | 30000 |
| Extractor Schema | 出力スキーマ指定 | (任意) | (None) |
| Extractor System Prompt | 出力のためのシステムプロンプト指定 | (任意) | (None) |
| Extractor Prompt | 出力スキーマを自然言語で指定するプロンプト | (任意) | (None) |
Extractor System PromptおよびExtractor PromptについてはOpenAI APIなどと連携する必要があり、今回は割愛します
とあるWebページを利用して、only Main ContextとExclude Tagsを利用した場合の取得内容の削減率を確認してみます。
※Exclude Tagsにて、span,supを指定しています。
| Setting | KB | Token | Compress |
|---|---|---|---|
| markdown | 304 | 135,307 | 100% |
| markdown + only Main Context | 273 | 122,549 | 91% |
| markdown + only Main Context + Exclude Tags | 127 | 56,474 | 42% |
内容の保持については怪しいところがありますが、適切なTagやSchemaを指定することでLLMに送るToken数を加減することが可能です。
参考