前回に引き続き、第四回目です。
疑似ラベリングとQDA(判別分析)を使用した予測
疑似ラベリングというと、半教師あり学習のイメージがあります。
今回はカーネル中の図がコード付きでないためそのまま引っ張ってきています。
本編
過去にローマンさんが疑似ラベルを使ったカーネルを作成しています。
https://www.kaggle.com/nroman/i-m-overfitting-and-i-know-it/notebook
カーネルの解説と改善を行い、疑似ラベルの威力を実証します。
サンタンデールのコンペでは、疑似ラベルを使用したチームが二位に入賞し、25000ドル(250万円くらい?)を獲得しました。
疑似ラベルって?
疑似ラベル手法は5つのステップからなります
1:トレーニングデータを使用してモデルを作成
2:テストデータをモデルで予測
3:テストデータとトレーニングデータを混ぜる
4:混ぜたデータでモデルを作る
5:このモデルを使いさらに正確に予測する
step1 モデル作成
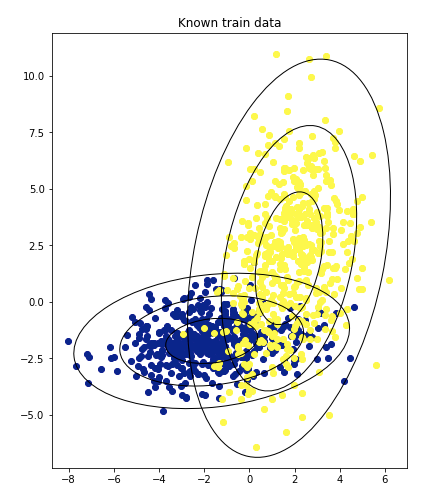
50個のトレーニングデータがある。
ターゲット=1なら黄
ターゲット=0なら青
QDAを使用してモデルを構築します。 QDAは多変量ガウス分布を計算し、target = 1とtarget = 0を予測するモデルを作ります。
分布ごとに1σ、2σ、3σの楕円として表されます。
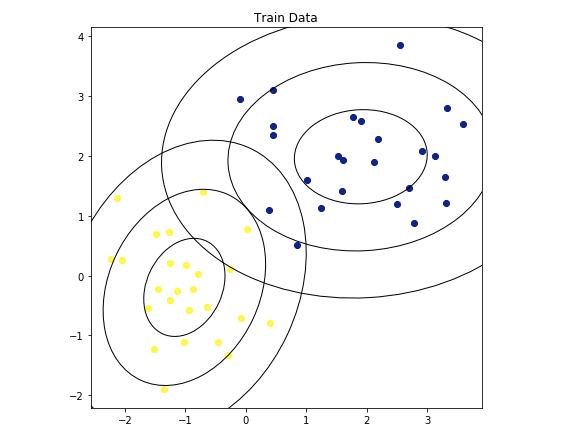
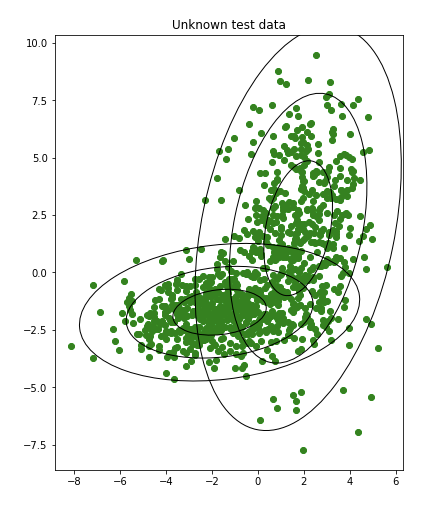
step2 テストデータを予測
モデル(楕円)を使用して、50個の未知のデータを予測します。
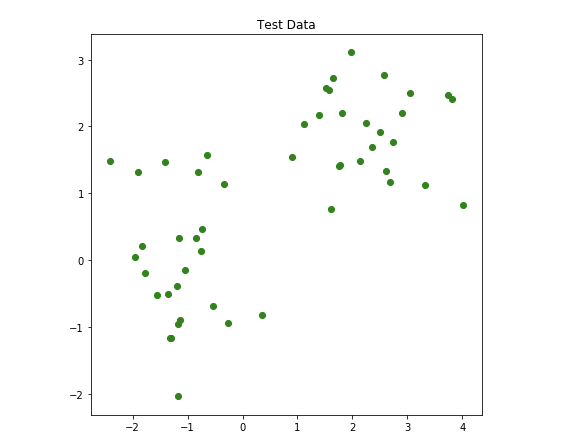
下の写真は、分類子が行った予測の結果を示しています。
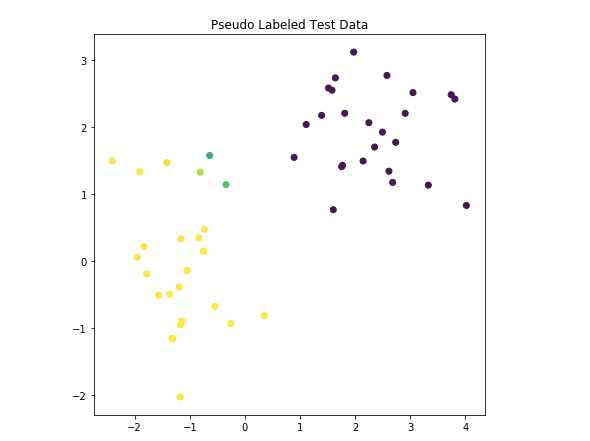
(黄色か青かを予測して色付けしていると思われる)
step3と4 改善モデルを作るために、疑似ラベルデータを使う
確信度が0.99の予測データをトレーニングデータに結合させました。
こうして結合した90点のデータを使い、新しいモデルを作ります。
赤い楕円はQDAによる新しいガウス分布の範囲を示しています。
最初よりもいい分類をする楕円を描いているので、いいモデルといえるでしょう。
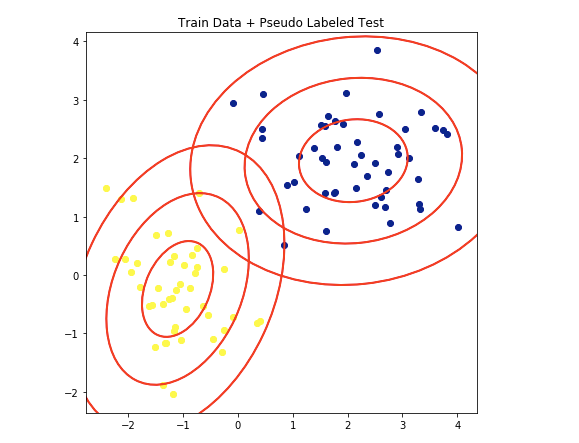
step5テストデータの予測
テストデータに二度目のモデルを適応させましょう。
疑似ラベルは何故働くのか
疑似ラベルを最初に学んだのはwizardyさんの記事からでした。
モデルの精度をさらに高めることが出来ることに驚きました。
一度目のモデルで作成した確信度の高い予測データを含めて、モデルを作成したため、テストデータの予測精度はさらに向上するのです。
疑似ラベルの仕組みは、QDAによって理解しやすくなります。
QDAはp次元空間の点を使用して超楕円を見つける手法です。
こちらで説明します。
先にリンク先の内容から。
QDAの説明
異なる2つの多変量ガウス分布からデータを生成します。
一つの分布からの観測値にtarget=1というラベルを付け、
もう一方の分布の観測値にtarget=0というラベルを付けましょう。
こういうデータにはQDA(Quadratic Discriminant Analysis)が良き分類器になります。
QDAはtarget=1,0のガウス分布を見つけます。
データは多変量ガウス分布から得られたデータであり、p次元空間の超楕円体です。(p=変数の数)
2次元(p=2)の場合を図示します。
黄色はtarget=1,青色はtarget=0,緑は不明。
データにQDAを行うと、楕円体を見つけてくれます。
図は1,2,3σを円として書いています。
判別のつかない不明データ(緑)が見つかった場合、どの楕円体に分類される確率が高いかを考えてくれます。
この時の計算は、P1/(P0 + P1)を計算しています。
target=1である確率 / 0である確率 + 1である確率
P1=データが楕円1(target=1)に含まれる確率
P0=データが楕円0(target=0)に含まれる確率
もとに戻って
疑似ラベルはより多くのデータを使って、各超楕円の中心と形状を正確に推定することにより、良い予測ができるようになるのです。
モデルはp次元空間でのtarget=1およびtarget=0の形状を可視化できます。
疑似ラベルの試みはすべてのタイプのモデルに役立ちます。
多くのデータがあればより正確な形を推定できるのです。
こちらで詳しく
またまたリンクに飛びます。
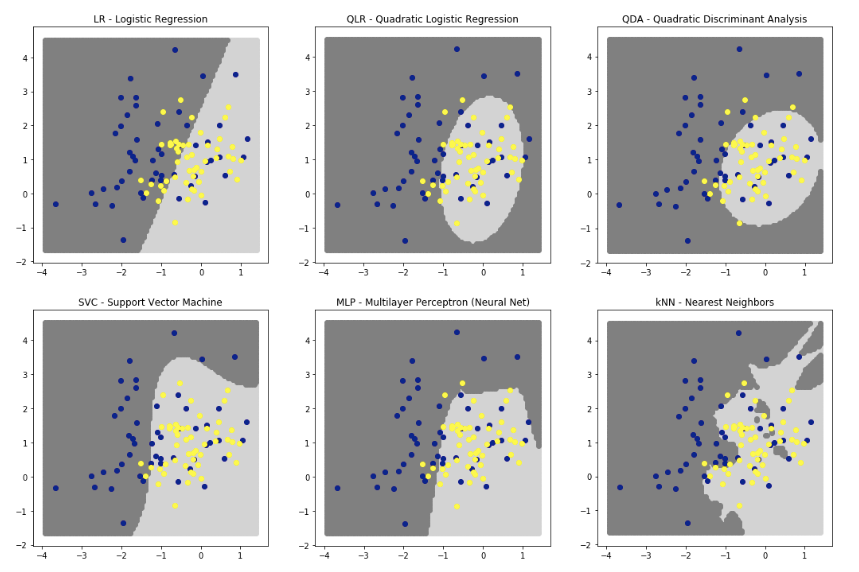
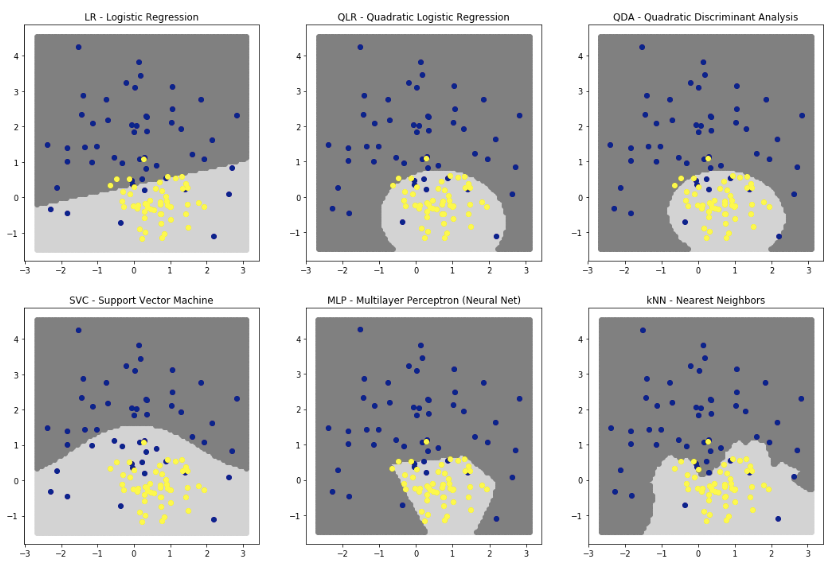
コンペ上位6つの分類器の分類結果を判別境界で確認してみましょう。
1:ロジスティク回帰
分類には超平面を使用する。
2:二次ロジスティク回帰
3:二次判別分析(QDA)
どちらも曲面・円・楕円・双曲線などを使用する
4:サポートペクトルマシン
多項式曲面を使用。
5:ニューラルネット
多数の直線を使用。ReLUを使っています。
ハイパボリックtanや、シグモイドで滑らかになる。
6:近傍法
ギザギザな面を使う。
これまでのところ、
3番QDAは、超楕円形にデータが存在するため、最高のパフォーマンスを発揮してくれます。
QDAを使うことが最善と考えます。
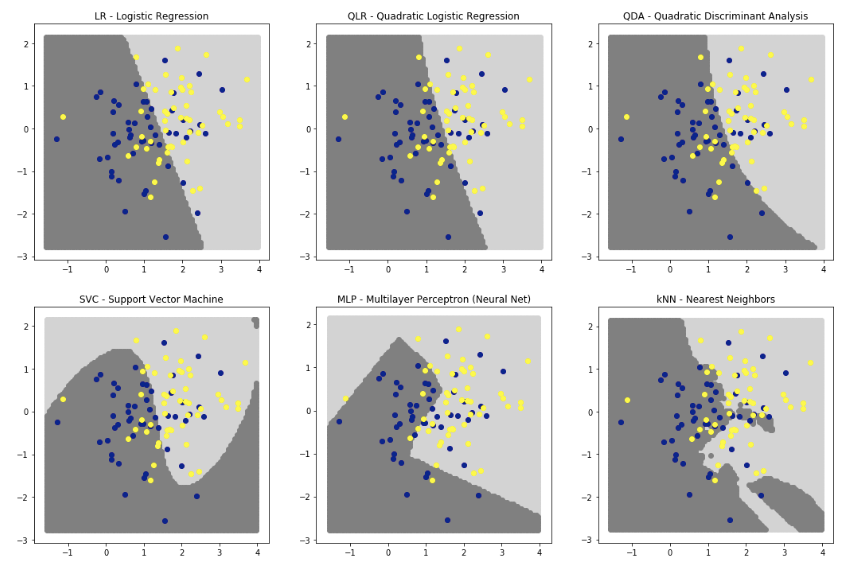
QDAとQLRを比較するためのplotも作成しました。
どちらもシグモイド関数で予測しますが、係数はそれぞれ異なったものを使用しています。
sigmoid(a1x1^2 + a2x2^2 + a3x1x2 + a4x1 + a5x2 + b)
よく似た曲線になっていることがわかります。
QDAは多変量ガウス分布の分離には精度よく対応してくれます。
None-the-less QLRも非常にいいです。
vladislavさんのQDAカーネルと、YirunさんのQLRのカーネルや、Bojanさんのカーネルを参考にしましょう。
https://www.kaggle.com/tunguz/ig-pca-nusvc-knn-qda-lr-stack
https://www.kaggle.com/gogo827jz/pseudo-labelled-polylr-and-qda
https://www.kaggle.com/speedwagon/quadratic-discriminant-analysis
図の出し方はこんな感じ
xres = 100
yres = 100
xx = np.linspace(xmin,xmax,xres)
yy = np.linspace(ymin,ymax,yres)
grid = np.zeros((xres*yres,2))
for i in range(yres):
grid[i*xres:(i+1)*xres,0] = xx
for i in range(yres):
for j in range(xres):
grid[i*xres+j,1] = yy[i]
clf = QuadraticDiscriminantAnalysis()
clf.fit(X,y)
preds = clf.predict(grid)
from matplotlib.colors import LinearSegmentedColormap
colors = [(0.5, 0.5, 0.5), (0.65, 0.65, 0.65), (0.8, 0.8, 0.8)]
cm = LinearSegmentedColormap.from_list('mycolors', colors, N=100)
plt.scatter(grid[:,0], grid[:,1], c=preds, cmap=cm)
plt.scatter(X[:,0], X[:,1], c=y)
plt.show()
またまた本編にもどって
コンペデータに疑似ラベルを試す
import numpy as np, pandas as pd, os
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.model_selection import StratifiedKFold
from sklearn.feature_selection import VarianceThreshold
from sklearn.metrics import roc_auc_score
train = pd.read_csv('../input/train.csv')
test = pd.read_csv('../input/test.csv')
train.head()
step 1, 2
# INITIALIZE VARIABLES
cols = [c for c in train.columns if c not in ['id', 'target']]
cols.remove('wheezy-copper-turtle-magic')
oof = np.zeros(len(train))
preds = np.zeros(len(test))
# BUILD 512 SEPARATE MODELS
for i in range(512):
# ONLY TRAIN WITH DATA WHERE WHEEZY EQUALS I
train2 = train[train['wheezy-copper-turtle-magic']==i]
test2 = test[test['wheezy-copper-turtle-magic']==i]
idx1 = train2.index; idx2 = test2.index
train2.reset_index(drop=True,inplace=True)
# FEATURE SELECTION (USE APPROX 40 OF 255 FEATURES)
sel = VarianceThreshold(threshold=1.5).fit(train2[cols])
train3 = sel.transform(train2[cols])
test3 = sel.transform(test2[cols])
# STRATIFIED K-FOLD
skf = StratifiedKFold(n_splits=11, random_state=42, shuffle=True)
for train_index, test_index in skf.split(train3, train2['target']):
# MODEL AND PREDICT WITH QDA
clf = QuadraticDiscriminantAnalysis(reg_param=0.5)
clf.fit(train3[train_index,:],train2.loc[train_index]['target'])
oof[idx1[test_index]] = clf.predict_proba(train3[test_index,:])[:,1]
preds[idx2] += clf.predict_proba(test3)[:,1] / skf.n_splits
#if i%64==0: print(i)
# PRINT CV AUC
auc = roc_auc_score(train['target'],oof)
print('QDA scores CV =',round(auc,5))
結果
QDA scores CV = 0.96541
step3,4
# INITIALIZE VARIABLES
test['target'] = preds
oof = np.zeros(len(train))
preds = np.zeros(len(test))
# BUILD 512 SEPARATE MODELS
for k in range(512):
# ONLY TRAIN WITH DATA WHERE WHEEZY EQUALS I
train2 = train[train['wheezy-copper-turtle-magic']==k]
train2p = train2.copy(); idx1 = train2.index
test2 = test[test['wheezy-copper-turtle-magic']==k]
# ADD PSEUDO LABELED DATA
test2p = test2[ (test2['target']<=0.01) | (test2['target']>=0.99) ].copy()
test2p.loc[ test2p['target']>=0.5, 'target' ] = 1
test2p.loc[ test2p['target']<0.5, 'target' ] = 0
train2p = pd.concat([train2p,test2p],axis=0)
train2p.reset_index(drop=True,inplace=True)
# FEATURE SELECTION (USE APPROX 40 OF 255 FEATURES)
sel = VarianceThreshold(threshold=1.5).fit(train2p[cols])
train3p = sel.transform(train2p[cols])
train3 = sel.transform(train2[cols])
test3 = sel.transform(test2[cols])
# STRATIFIED K FOLD
skf = StratifiedKFold(n_splits=11, random_state=42, shuffle=True)
for train_index, test_index in skf.split(train3p, train2p['target']):
test_index3 = test_index[ test_index<len(train3) ] # ignore pseudo in oof
# MODEL AND PREDICT WITH QDA
clf = QuadraticDiscriminantAnalysis(reg_param=0.5)
clf.fit(train3p[train_index,:],train2p.loc[train_index]['target'])
oof[idx1[test_index3]] = clf.predict_proba(train3[test_index3,:])[:,1]
preds[test2.index] += clf.predict_proba(test3)[:,1] / skf.n_splits
#if k%64==0: print(k)
# PRINT CV AUC
auc = roc_auc_score(train['target'],oof)
print('Pseudo Labeled QDA scores CV =',round(auc,5))
結果
Pseudo Labeled QDA scores CV = 0.97033
予測値を出力
sub = pd.read_csv('../input/sample_submission.csv')
sub['target'] = preds
sub.to_csv('submission.csv',index=False)
import matplotlib.pyplot as plt
plt.hist(preds,bins=100)
plt.title('Final Test.csv predictions')
plt.show()

まとめ
このカーネルでは、疑似ラベルについて、なぜ機能するのか、使いかたを学びました。
コンペのデータに使用してみると、スコアが0.005増加しました。
疑似ラベリングとQDAはCV=0.970,LB=0.969でした。
疑似ラベルが無しならCV=0.965,LB=0.965でした。
カーネルをローカルで実行すると、パブリックのtestにのみ適応されるので、CVとLBは異なるのです。