はじめに

MATLAB R2021a でリリースされた強化学習を GUI から実行可能な強化学習デザイナーアプリは、直感的に小難しい強化学習の
- 設定
- 学習
- シミュレーション
が実行できるとして、MATLAB ユーザーが乱舞狂乱したのは記憶に新しいことかと思います。本記事は、この機能を使って楽して OpenAI Gym の環境を強化学習するという試みをご披露します。
なお、当該アプリを使うと MATLAB/Simulink 下での強化学習はもはや Challenging でも何でもないため、ここではあえていばらの道、 Python (OpenAI Gym) 連携 に取り組みたいと思います。
強化学習デザイナーアプリ:
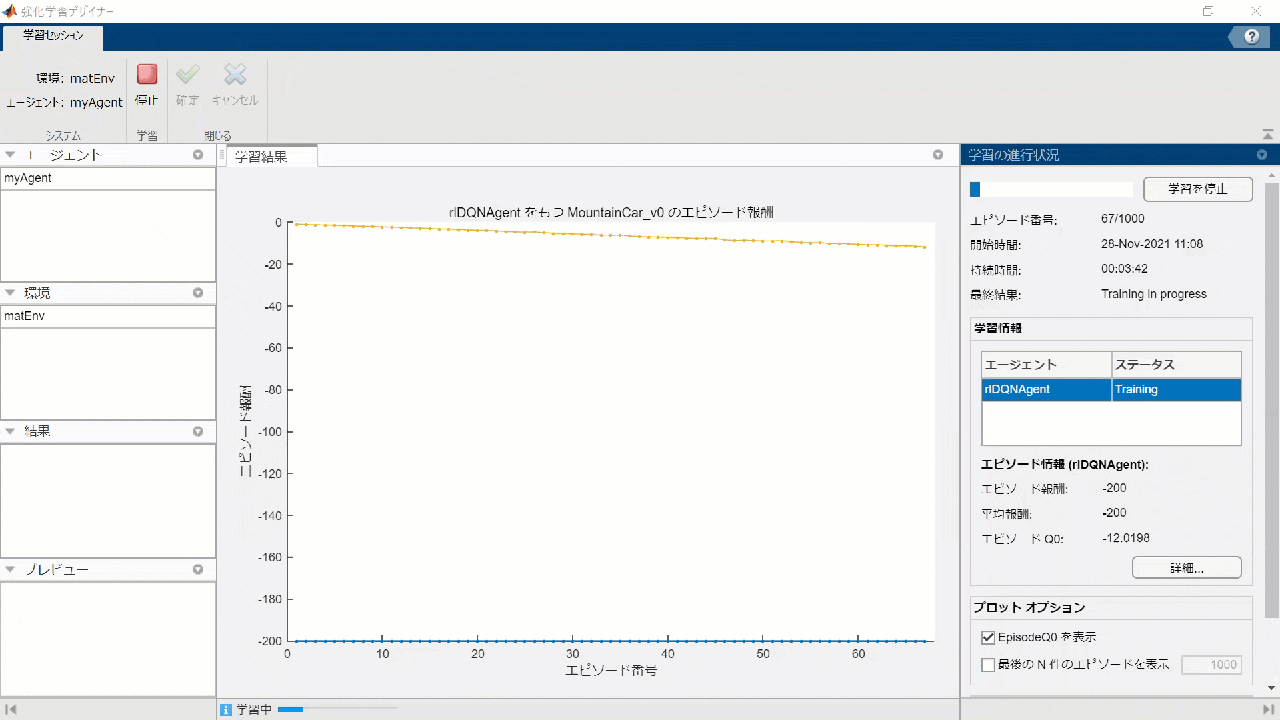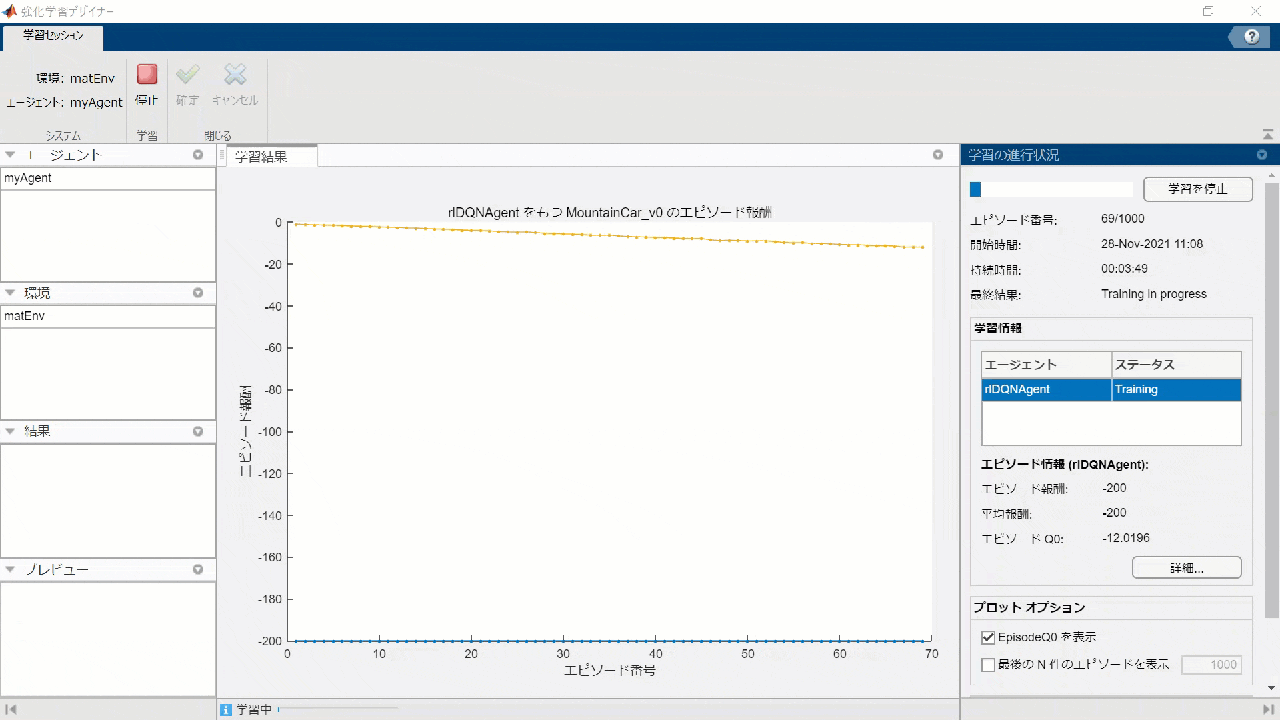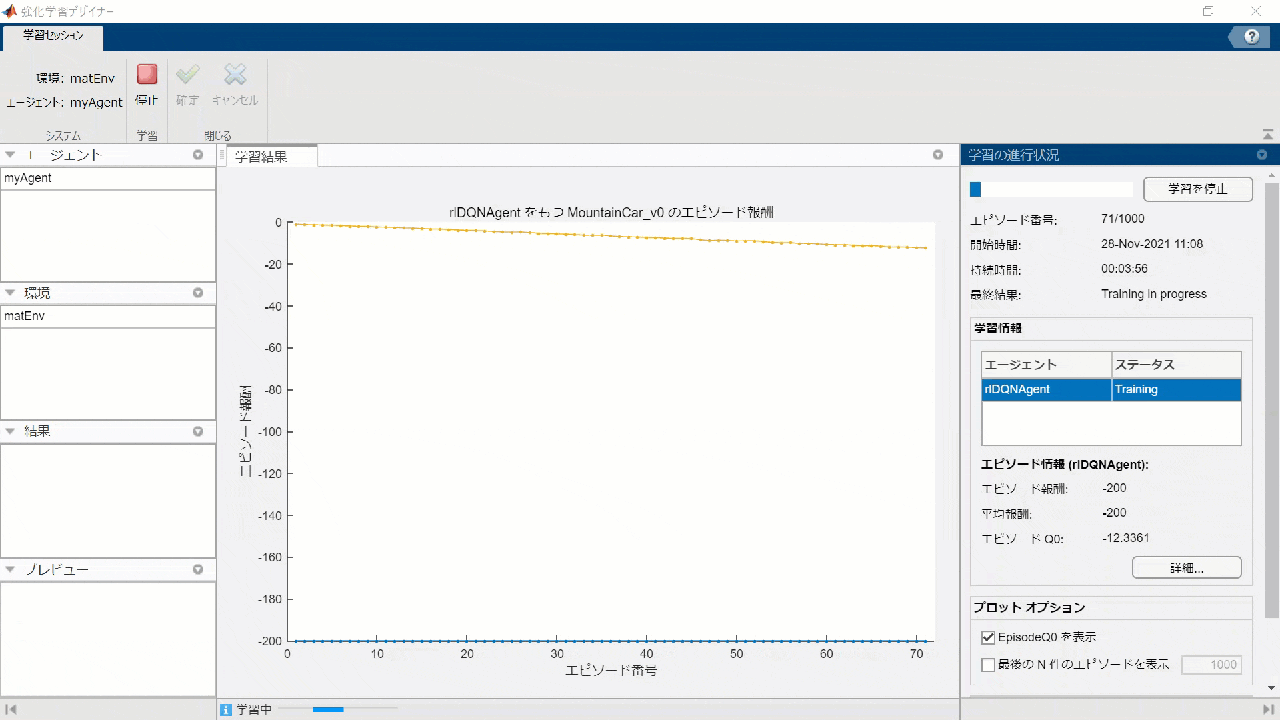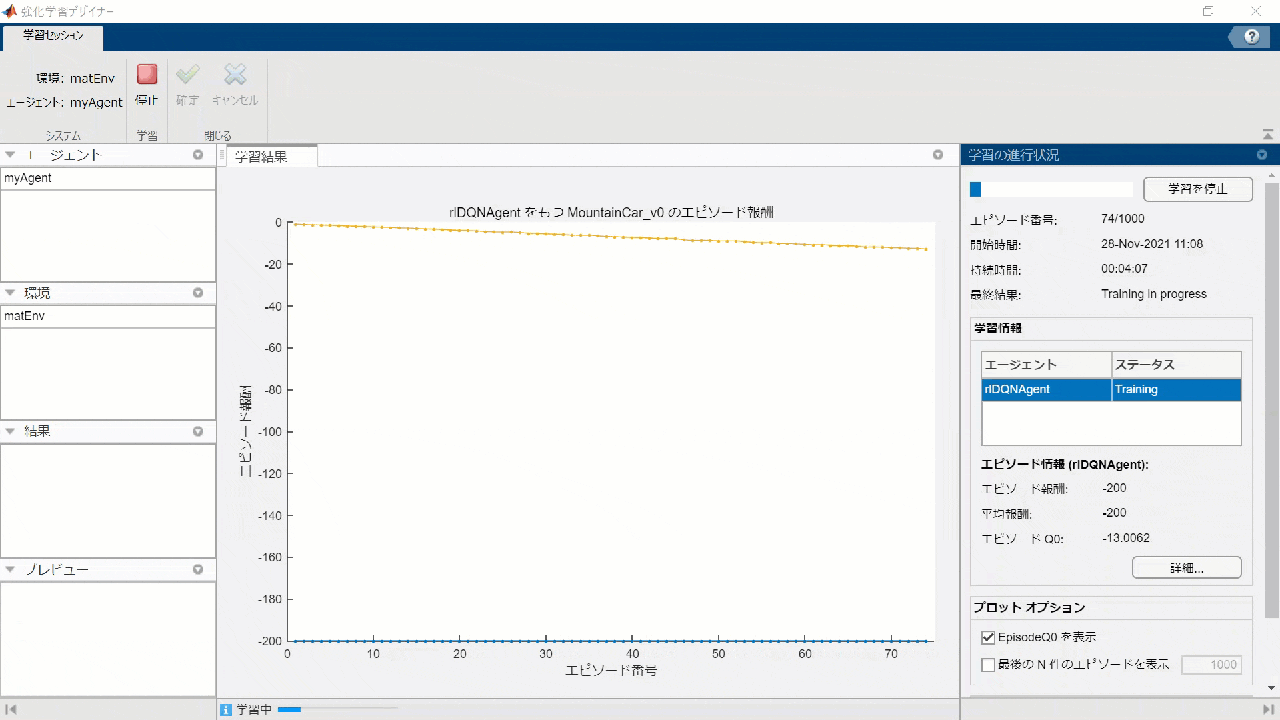

強化学習用に Python の仮想環境を用意する
デフォルトでの MATLAB の Python 設定は以下のような感じ:
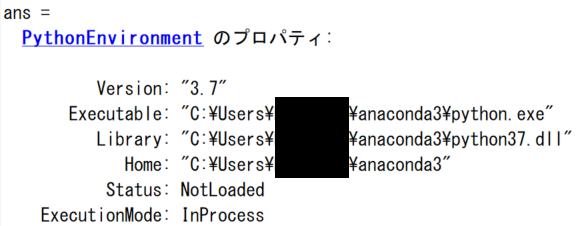
注意
MATLAB から Python を操作することが可能ですが、この準備ができているのが大大大前提です*
*Python の MATLAB からの利用についてはこちら
この環境に OpenAI Gym ライブラリをインストールしても良いのですが、Python のライブラリ間の依存関係 (ヴァージョン揃えたり) の解決には時間がかかるので、ここではあっさり以下のようにターミナルから強化学習用に Python の仮想環境を用意します。因みに anaconda 使っています:
conda create --name matlab-rl python=3.7
Open AI Gym をインストールします。
- conda
- pip
がありますが、conda でインストールに苦戦したので、”えいや”で pip で以下のような感じでインストール:
pip install gym==[version]
pip install gym[atari]
ここで、MATLAB から Python 連携を行うために pyenv コマンドを使いますが、上で作成した Python 仮想環境を MATLAB で使うために:
rlPython = {'Version','C:\Users\HYCE\anaconda3\envs\matlab-rl\python.exe'};
pyenv(rlPython{:})
 と Python を切り替えておきます。
と Python を切り替えておきます。
OpenAI Gym 環境

Open AI Gym から1つ強化学習用の環境を引っ張ってきます:
myenv = py.gym.make('MountainCar-v0')
Python での実装は GitHub OpenAI Gym をご覧ください。
環境の絵を見てお分かりいただける通り、車を左右に加速させて、 山を登りきることを目指すための単純な環境です。観測は(x,y) 座標と、速度、そして報酬信号、と終了条件達成フラグ (isdone 信号)が得られると考えられます。
この環境の詳細
結局、環境の I/O だけ分かれば良いので情報を集めます:

環境の"観測"を行う
上の情報に依ると入手できる情報は以下の2つ:
- Car position
- Car velocity
確認しましょう。
Python オブジェクトのプロパティを表示するために、details 関数を使います。
details(myenv.reset())

アクション後のオブジェクトにある data プロパティが恐らく、観測データと睨む:
res = myenv.reset();
res.data

間違いない... こいつらが観測データの2つだ。
ランダムな行動に対する応答をレンダリングして表示する
myenvオブジェクトを触っていると、"いかにも"なメソッドが見つかります
- step
- render
あたりのメソッドがアヤシイので、これを使ってランダムな行動に対して、
- Position (観測1: 位置)
- Velocity (観測2: 速度)
- Reward (報酬)
- isdone (終了条件達成フラグ)
を確認できるはずです。
for i = 1:1000
action = int16(randi([0,2],1));
myenv.step(action);
myenv.render();
end
あ、動いた...
環境から戻ってきたデータを受け取る準備
動作確認ができたので、最後の1つの行動 (action) を使って出力を確認:
result = myenv.step(action)

きっとこれが、[Position, Velocity, Reward, isdone] だ! これを MATLAB で受け取る。
ここで、MATLAB <--> Python 技: "とりあえず cell で受ける" を使う:
% Python の結果をとりあえず cell で受けておく
result = cell(result)
% 観測 (Observation) だけ MATLAB に渡すことができるか確認
Observation = double(result{1})'
% 報酬
Reward = double(result{2})
% isdone?
IsDone = boolean(double(result{3}))
これでとりあえず、MATLAB で扱うことができる変数型に変換することができました。ここまでくればあとは MATLAB World での作業なので大分楽になります。
% 最後に閉じる
myenv.close();
以上で実験終了。MATLAB で強化学習を実行する準備が整いました。
カスタム環境ラッパークラスを作成する
今までやってきたことを念頭に置いて、Python で作成した"環境" >> MATLAB の"環境" とする必要があるので、カスタム環境を作成します。次のリンクから作り方を真似します:Create Custom MATLAB Environment from Template
rlCreateEnvTemplate("MountainCar_v0");
と実行すると、MountainCar_v0 環境クラスのテンプレートが作成されます。ここがスタートポイントです。上記の情報を引き抜く技をテンプレートに適用し、MountainCar_v0.mを次のように定義します。
MountainCar_v0 クラス
classdef MountainCar_v0 < rl.env.MATLABEnvironment
%MOUNTAINCAR_V0: Template for defining custom environment in MATLAB.
%% Properties (set properties' attributes accordingly)
properties
open_env = py.gym.make('MountainCar-v0');
end
properties
% Initialize system state [x,dx/dt]'
end
properties(Access = protected)
% Initialize internal flag to indicate episode termination
IsDone = false;
end
%% Necessary Methods
methods
% Contructor method creates an instance of the environment
% Change class name and constructor name accordingly
function this = MountainCar_v0()
% Initialize Observation settings
ObservationInfo = rlNumericSpec([2 1]);
ObservationInfo.Name = 'Mountain Car States';
ObservationInfo.Description = 'Position x, Velocity dx/dt';
% Initialize Action settings
ActionInfo = rlFiniteSetSpec([0 1 2]);
ActionInfo.Name = 'Mountain Car Action';
% The following line implements built-in functions of RL env
this = this@rl.env.MATLABEnvironment(ObservationInfo,ActionInfo);
end
% Apply system dynamics and simulates the environment with the
% given action for one step.
function [Observation,Reward,IsDone,LoggedSignals] = step(this,Action)
LoggedSignals = [];
% Observation
result = cell(this.open_env.step(int16(Action)));
Observation = double(result{1})'; % ndarray >> MATLAB double
% Reward
Reward = double(result{2});
% is Done?
IsDone = boolean(double(result{3}));
if (Observation(1) >= 0.4)
Reward = 0;
IsDone = true;
end
this.IsDone = IsDone;
% (optional) use notifyEnvUpdated to signal that the
% environment has been updated (e.g. to update visualization)
notifyEnvUpdated(this);
end
% Reset environment to initial state and output initial observation
function InitialObservation = reset(this)
result = this.open_env.reset();
InitialObservation = double(result)';
% (optional) use notifyEnvUpdated to signal that the
% environment has been updated (e.g. to update visualization)
notifyEnvUpdated(this);
end
end
%% Optional Methods (set methods' attributes accordingly)
methods
% Helper methods to create the environment
end
methods (Access = protected)
% (optional) update visualization everytime the environment is updated
% (notifyEnvUpdated is called)
%function envUpdatedCallback(this)
%end
end
end
環境インスタンスをカスタム環境クラスから作成する
ではカスタム環境クラスからインスタンスを作成します。これが今回学習する MATLAB での環境の定義になります。
matEnv = MountainCar_v0();
一応チェックしておきます。カスタムで作った場合は、この関数 validateEnvironmentを使います。
validateEnvironment(matEnv)
これは、
- 初期の観測と行動を作成
- 1-2 step だけ、環境をシミュレーション
を実行し、強化学習の学習が大丈夫か事前にチェックできます。問題が無ければそのまま進みます。
学習
以降は強化学習デザイナーアプリを使って実施。以下の流れです
- 学習のセットアップ
- 学習
- アプリ内でのシミュレーション
- Critic & Agent のエクスポート
- エクスポートしたものを使ってシミュレーション
1-4 までアプリ内で実行可能です。
設定
環境は先ほど作った matEnvです。agent は以下のように指定:
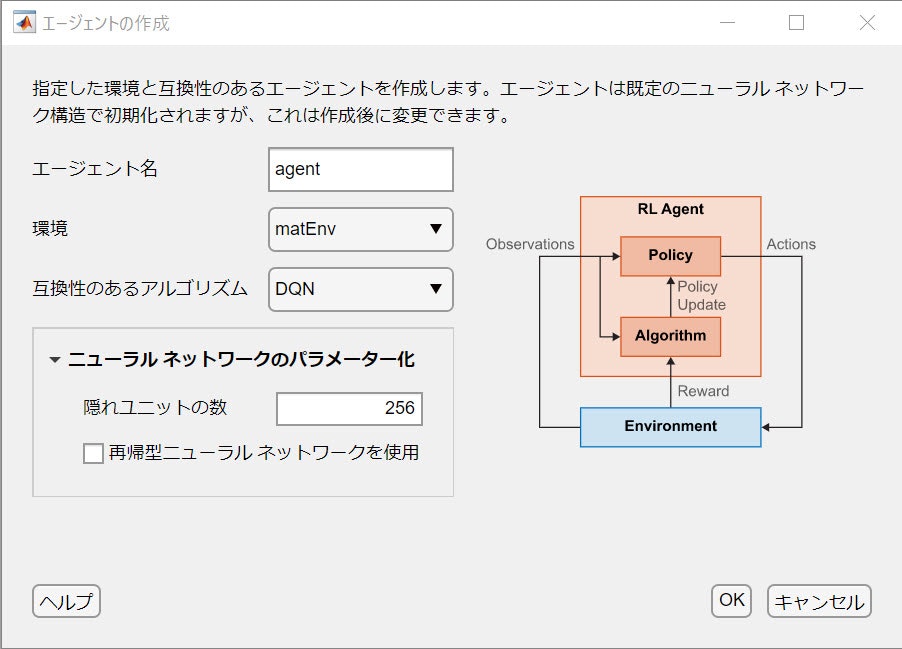
- DQN
- Critic ネットワークの幅は 256
学習の設定は次のようにします:
学習実行
実行ボタンをクリックして、あとは学習終了まで待ちましょう ....
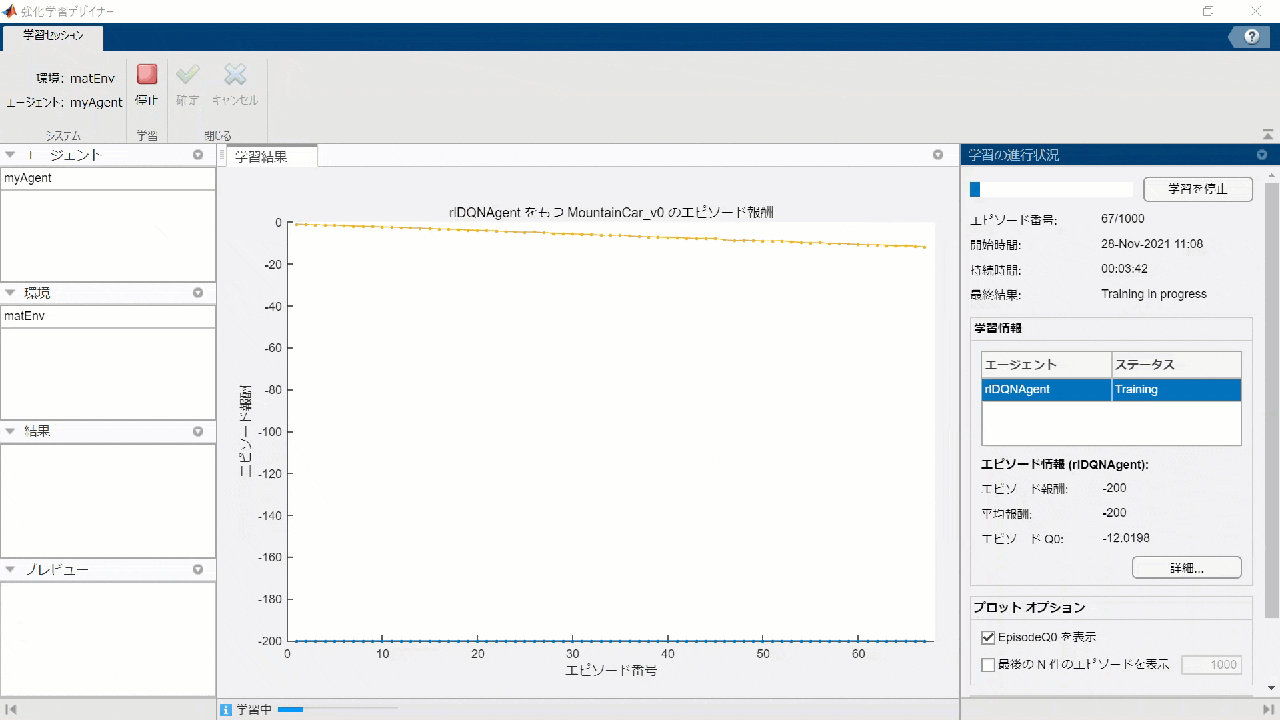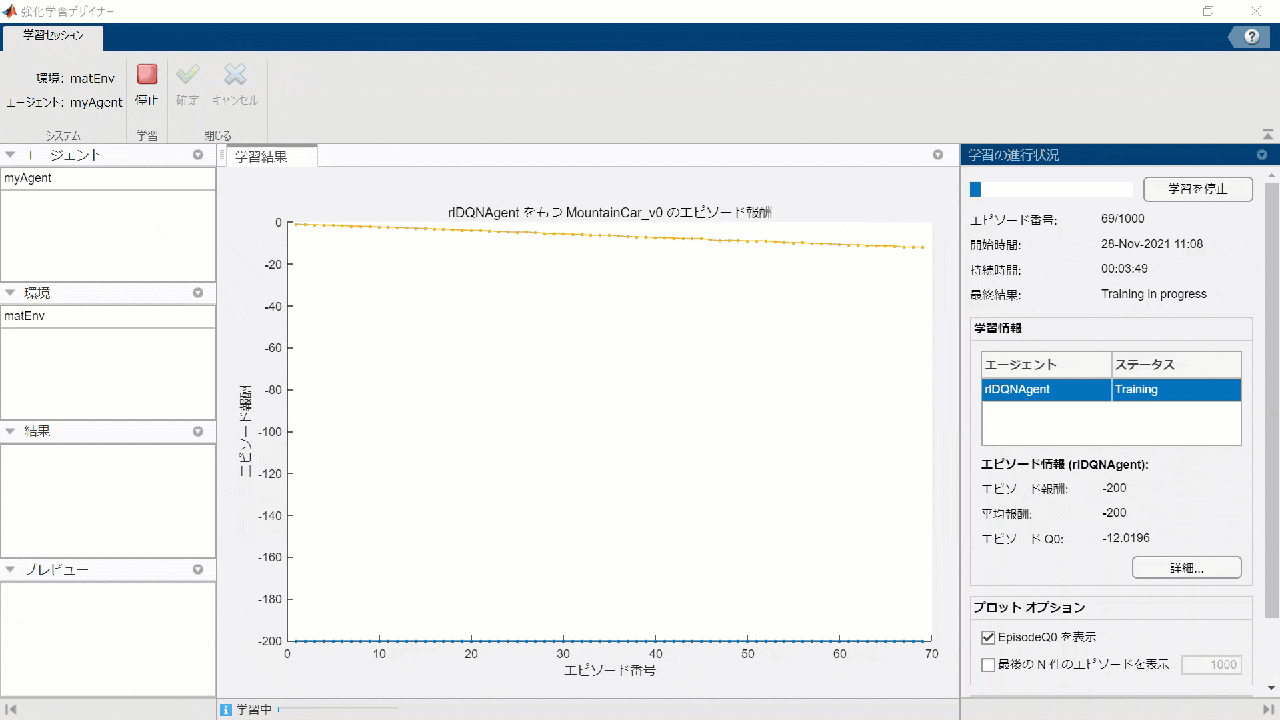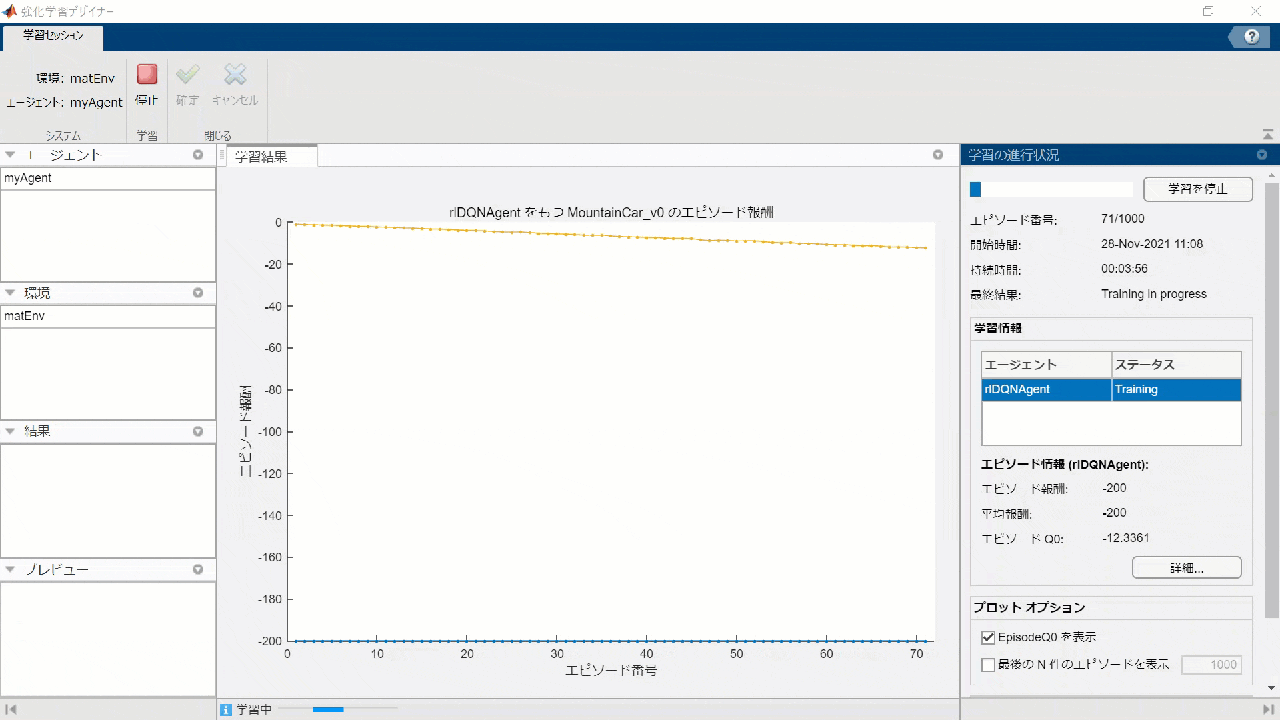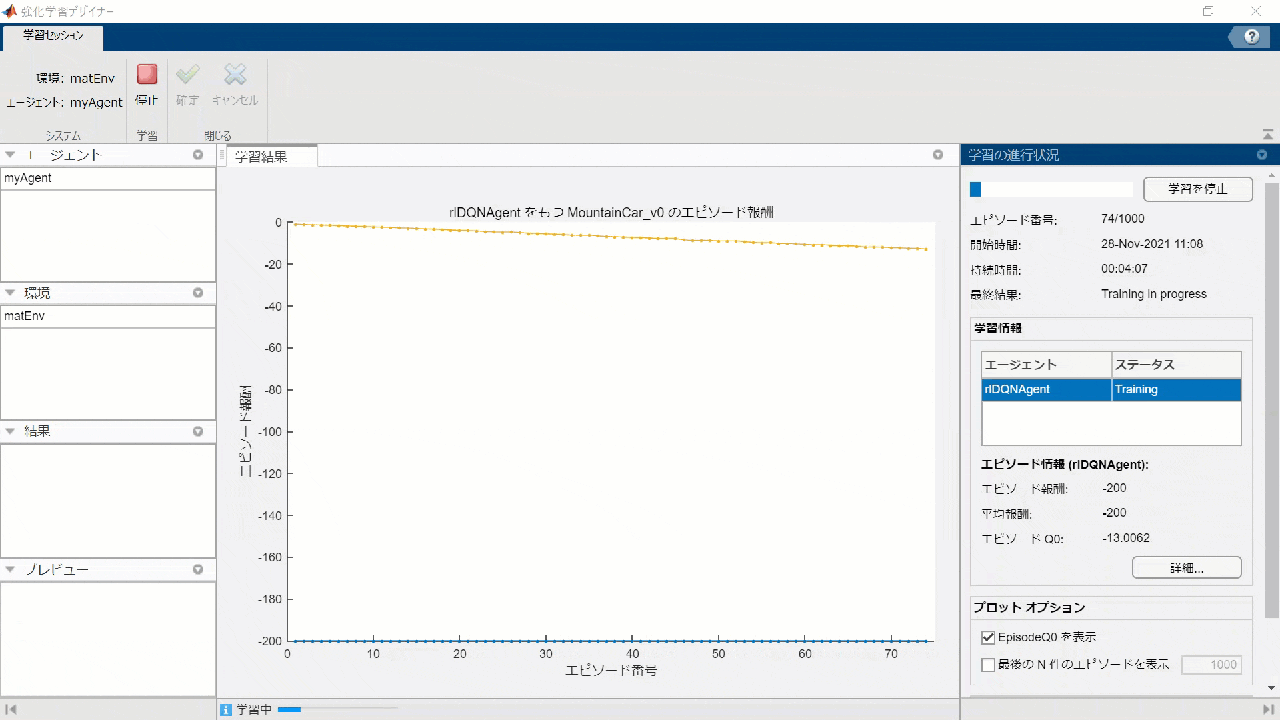
シミュレーションと可視化
学習終了したら、アプリからシミュレーションを実行しても良いですが、この場合レンダリングされず、車が動いている様子が見えないためモデルをエクスポートして、マニュアルシミュレーションを実行します。
学習後にモデルをエクスポート
agent や agent の要素をエクスポートできます。深層強化学習のネットワークだけエクスポート:
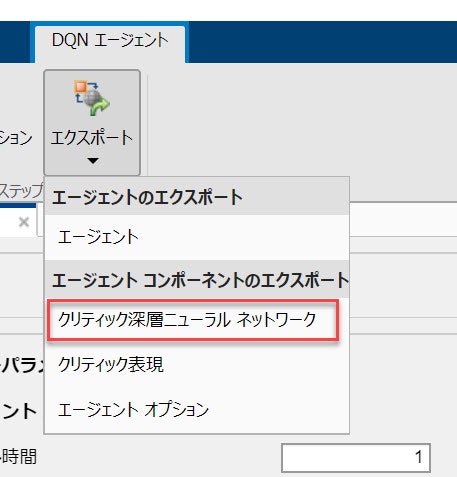
Critic のネットワークがワークスペースに落ちてきます。この設定だと agent_criticNetwork のはずです。
R2021a ではエクスポートされたネットワークは DAGnetwork オブジェクトでしたが、R2021b では dlnetwork オブジェクトです。そのため、ネットワークに渡す変数型がR2021b のものでは dlarray が要求されます。以下の可視化プログラムではそこに配慮を入れて、どちらでも動作するようにしています。
マニュアルシミュレーションを実行して車が登るか確認
可視化するコードを用意して、無理やり Gym のレンダリングをさせます。このあたりは、MATLAB と Python を連携させる際に、一手間必要なところになってしまいますが、本丸の強化学習の方で楽できるので、Qiita ユーザーなら屁でもないでしょう。
- 環境
- 学習したネットワーク (Critic)
- シミュレーション回数
を渡します:
visSim(matEnv,trainedCritic,5);
visSim.m コード内容こちら
function visSim(env,net,numSim)
% Run Simulation using "step" method
%
%
if isa(net,"dlnetwork") % in case of dlnetwork
dlnetFlag = true;
end
for i=1:numSim
state = single(env.open_env.reset()); % initial [x, dx/dt]
if dlnetFlag % dlnetwork
state = dlarray(state,"BC");
end
isDone = false; % Break criterion
steps = 0; % step counts
while(~isDone && steps < 200)
% Take the best action according to state
% Note that the network accepts S --> Q(S,A)
[~,action] = max(predict(net,state));
if dlnetFlag
action = extractdata(action);
end
% Recieve result from the environment: action \in {0,1,2}
result = cell(env.open_env.step(int16(action-1)));
% Display OpenAI Gym environment
env.open_env.render();
% new [x, dx/dt]
new_state = single(result{1});
% isDone signal
isDone = boolean(single(result{3}));
% stop criterion
if (new_state(1) >=0.49)
isDone = true;
end
state = new_state; % update [x, dx/dt]
if dlnetFlag % dlnetwork
state = dlarray(state,"BC");
end
steps = steps + 1;
end
env.open_env.close(); % Close OpenAI Gym environment
end
end
おー上手く動いた動いた:
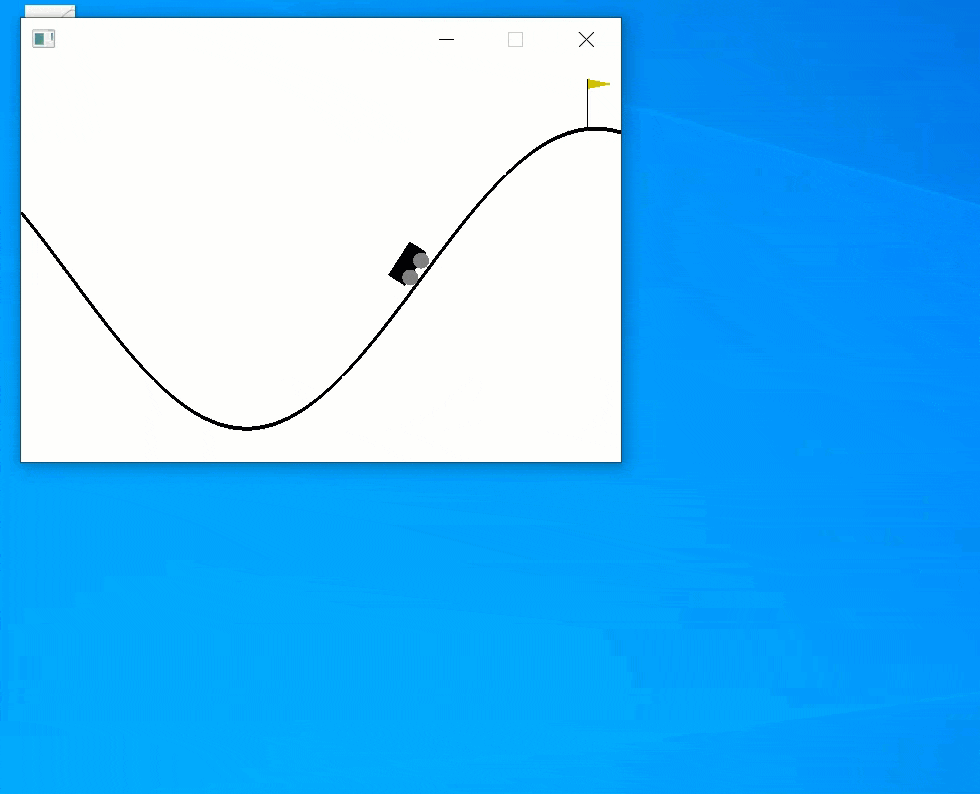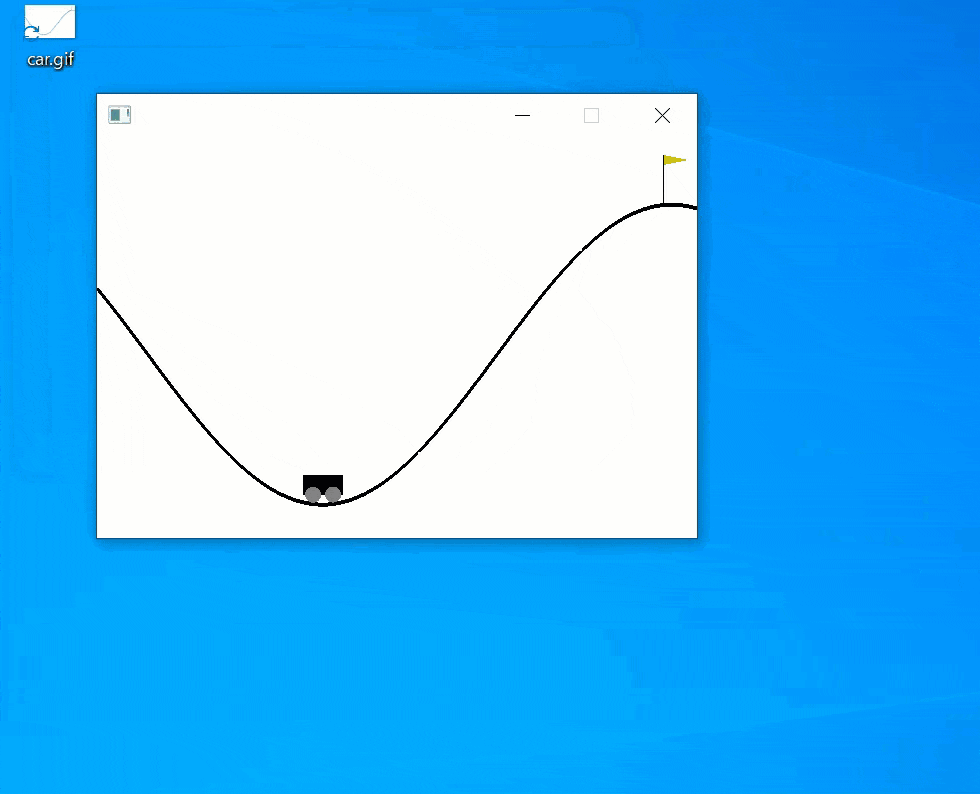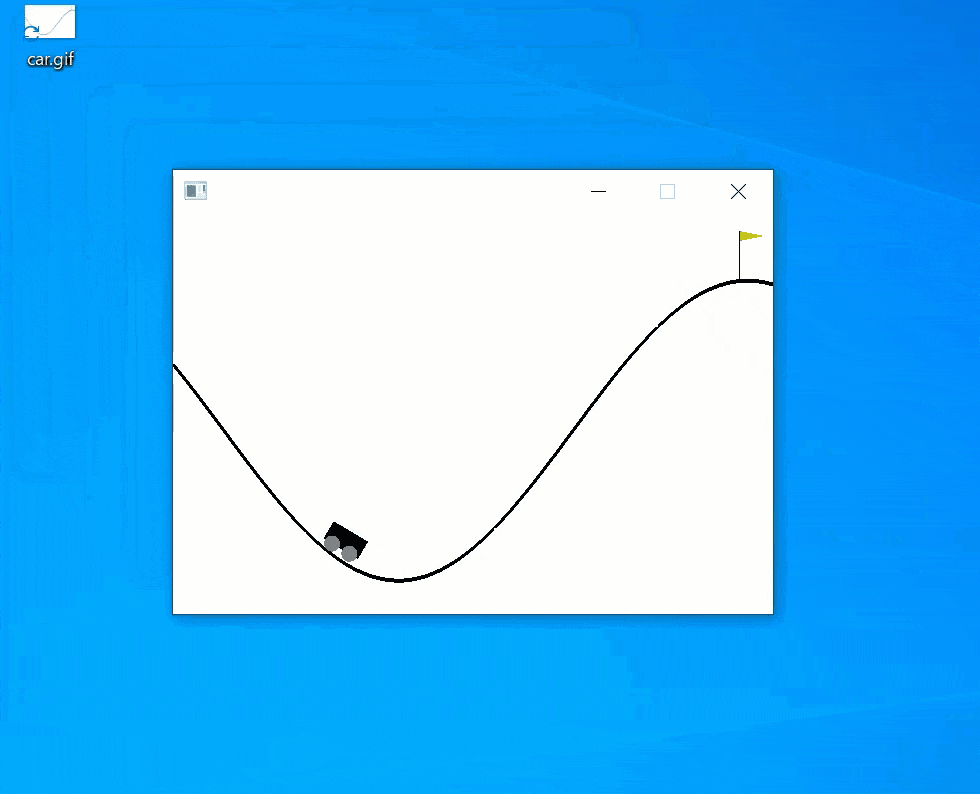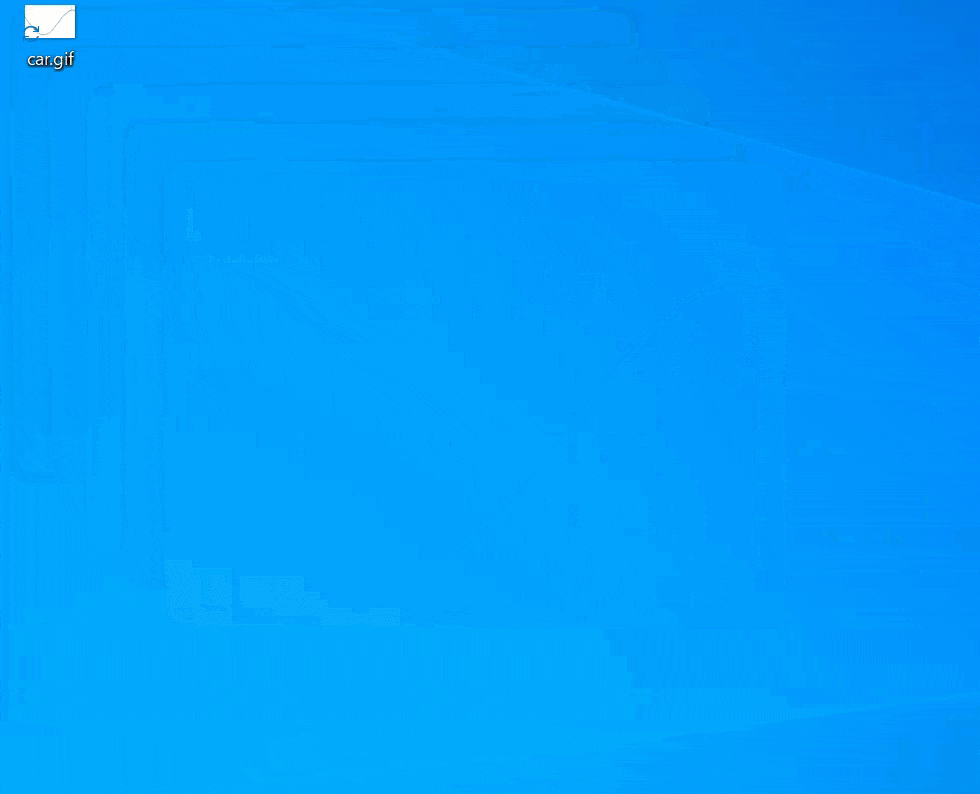
まとめ
- MATLAB の強化学習アプリを使って、OpenAI Gym の環境を学習しました
- Python のレンダリングを生かすには、マニュアルシミュレーションが必要でした
- 強化学習アプリのお陰で、かなり作業が楽になります。その分、Python での環境を使ってみようかなと、元気が出ました
では、みなさん LGTMをしていただいて、良いお年をお迎えください