LightGBM で競馬予想するために、前回までにモデルの構築と馬券の回収率の計算まで行った。
機械学習の精度と馬券の回収率は必ずしも一致しないため、回収率を向上するためにモデルを改良してみるのだ。
前回:【第6回】Python で競馬予想してみる ~ LightGBM :馬券の回収率 ~
特徴量の選択
前回までのモデルの特徴量の重要度を算出してみると下位に、クラス名がずらーっと並ぶ
また、最も重要度が高いのが騎手コード
騎手の重要度が高いということは、
必然的に人気騎手の乗る馬を選ぶ確率が高くなり、馬の実力以上に馬券の期待値は下がるのではないかと
まずは、クラス名と騎手コードを削除してみるのだ
Out
feature importance
6 騎手コード 0.027956
75 1_単勝オッズ 0.018516
80 1_上り3F 0.018176
79 1_Ave-3F 0.017381
77 1_着差 0.014908
9 間隔 0.014568
136 2_単勝オッズ 0.013705
140 2_Ave-3F 0.013479
83 1_補正 0.013479
141 2_上り3F 0.013297
319 5_単勝オッズ 0.013047
69 1_騎手コード 0.013025
84 1_補9 0.012866
130 2_騎手コード 0.012843
201 3_Ave-3F 0.012730
191 3_騎手コード 0.012321
(中略)
293 4_クラス名_JG1 0.000000
233 3_クラス名_JG2 0.000000
287 4_クラス名_未出走 0.000000
294 4_クラス名_JG2 0.000000
228 3_クラス名_重賞 0.000000
234 3_クラス名_JG3 0.000000
289 4_クラス名_重賞 0.000000
112 1_クラス名_JG3 0.000000
221 3_クラス名_3勝 0.000000
173 2_クラス名_JG3 0.000000
106 1_クラス名_重賞 0.000000
356 5_クラス名_JG3 0.000000
307 4_脚質_マクリ 0.000000
354 5_クラス名_JG1 0.000000
172 2_クラス名_JG2 0.000000
350 5_クラス名_重賞 0.000000
346 5_クラス名_OP(L) 0.000000
281 4_クラス名_2勝 0.000000
343 5_クラス名_3勝 0.000000
163 2_クラス名_OP(L) 0.000000
167 2_クラス名_重賞 0.000000
171 2_クラス名_JG1 0.000000
特徴量:クラス名と騎手コードを使わない
AUC
削除前とほとんど変化なし
Out
train roc_auc_score = 0.8051300460369071
eval roc_auc_score = 0.7694635088393545
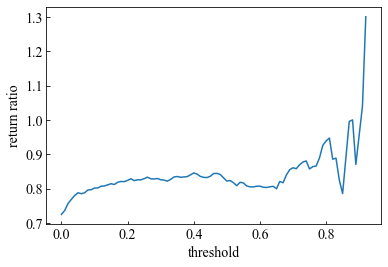
単勝の回収率と閾値
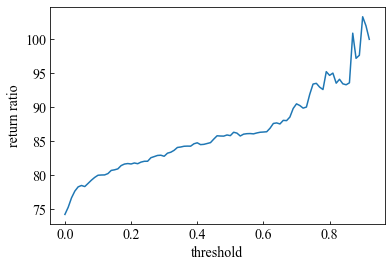
複勝の回収率と閾値
特徴量:直近レースに前走レースID(新)がないものは削除
特徴量:直近レースが障害レースも削除 (追記)
今まで、直近データ中に過去競争データの存在しない新馬戦のデータも残してあった
まぁ、いらんだろうということで、前走レースデータがないものは削除
(追記)障害レースも削除した。結果はほとんど変わらなかった
AUC
0.01 ほど良化
Out
train roc_auc_score = 0.8178481632636547
eval roc_auc_score = 0.7780708903721912
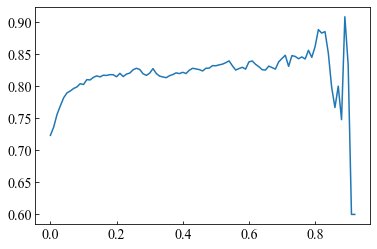
単勝の回収率と閾値
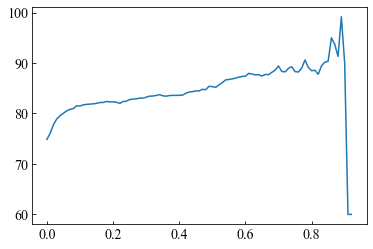
複勝の回収率と閾値
混同行列
アンダーサンプリングした方が良いのかな?
Out
混同行列 labels=[1, 0]
[[ 9207 30515]
[ 6083 140858]]
適合率 0.602158273381295
再現率 0.2317859120890187
F値 0.334726968661383
不均衡データの修正
LightGBM と 不均衡データについて調べてみたが、よく分からないのだ
とりあえず、3着以内とそれ以外のデータの比率が 1:5 くらいなので 1:2 にアンダーサンプリングしてみる
build.ipynb
# 学習データをアンダーサンプリング
f_count = y_train.value_counts()[1] * 2
t_count = y_train.value_counts()[1]
rus = RandomUnderSampler(sampling_strategy={0:f_count, 1:t_count})
X_train, y_train = rus.fit_sample(X_train, y_train)
AUC
さらに 0.02 良化
Out
train roc_auc_score = 0.8179002016664295
eval roc_auc_score = 0.7803210916978204
単勝の回収率と閾値
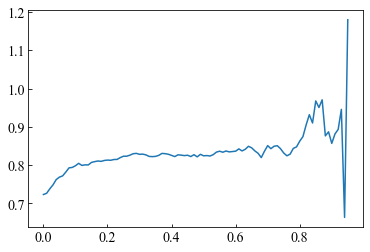
複勝の回収率と閾値
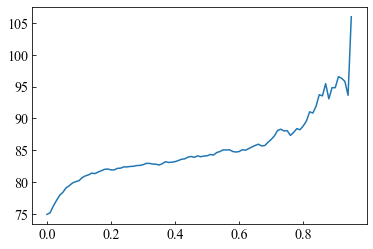
混同行列
アンダーサンプリングした方が、断然良い!
馬券を買う対象数も倍以上増えて、取りこぼしも改善
Out
混同行列 labels=[1, 0]
[[ 18782 20940]
[ 19515 127426]]
適合率 0.49043005979580645
再現率 0.4728362116711142
F値 0.48147246183621933
少しずつだが、良化中
今回はここまで![]()