pythonの機械学習ライブラリKerasを使ってDCGANを構築し猫の画像を生成してみました。
左が実際の画像/右が生成された画像


DCGANって何?
-
そもそもGANとは
GANは生成ネットワークと識別ネットワークの2つのネットワークで構成されています。GANでは生成ネットワークと識別ネットワークを競わせるように学習させることで、本物の様な入力を偽造することができます。
例えるならば、生成ネットワークは偽物を作り出す偽造屋、識別ネットワークは偽物を見つけ出す鑑定士のような役割を担っています。

-
DCGANとGANとの違い/メリット
DCGANとは- 畳み込み層を利用する
- Leaky ReLUを活性化関数とする
- 各層でバッチ正則化を行う
という3つの改良をGANに加えることで安定した学習を可能にしているモデルです。
学習データの用意
kaggleでアップロードされている「Cat Dataset」というデータセットを利用します。

このデータセットには
- 9000枚を超える猫の画像
- 猫の顔パーツが画像上のどこにあるかの情報
- 左目の位置
- 右目の位置
- 口の位置
- 左耳の位置
- 右耳の位置
が含まれています。

本記事ではこのデータセットを用いて猫の顔部分を抽出し、それを学習データとして用いたいと思います。
学習データの前処理
学習を始めたいところですが、DCGANは固定的なサイズの画像しか作ることができません。
先に述べたようにデータセットには顔パーツの座標が含まれているので、今回はこれを用いて猫の顔部分を抽出し学習に適した正方形の画像を作成します。
今回は両目の座標の中点を顔の中心として、その周辺を切り取りました。
- 目の位置が水平になるように回転

- 目の間の距離が32pxになるように拡大/縮小

- 両目の中点を中心として64×64pxで切り抜き

pillowのimageを用いて変形するためのプログラムを実装しました。
import glob
from PIL import Image
import os
import math
#~~部はデータをダウンロードしたパスに書き換えてください
for f in glob.glob("~~~~~/archive/*/*.jpg"):
#画像をPILで読み込む
img = Image.open(f)
#猫の顔パーツの位置を読み込む
fp = open( f + ".cat", "r")
posi = [int(x) for x in fp.read().strip().split()]
fp.close()
#目が水平に来るように回転
mid_x = (posi[1]+posi[3])/2 #回転の中心x
mid_y = (posi[2]+posi[4])/2 #回転の中心y
angle = math.degrees( math.atan2((posi[4]-posi[2]),(posi[3]-posi[1])) ) #回転させる角度
img = img.rotate(angle,center=(mid_x,mid_y))
#目と同じ位置に来るように拡大
length = math.sqrt((posi[4]-posi[2])**2 + (posi[3]-posi[1])**2)
ratio = 32/length
img = img.resize((int(img.width*ratio), int(img.height*ratio)))
#トリミング
mid_x*=ratio
mid_y*=ratio
img = img.crop((mid_x-32, mid_y-32, mid_x+32, mid_y+32))
#指定したディレクトリに保存(任意に変更してください)
file_name = os.path.basename(str(f))
img.save("~~~~~~~~/cat_face/" + file_name)
完成した成型済みデータがこちらです。

さらに機械学習で扱いやすくするために画像をnumpy配列に直し、pickleライブラリを用いてpkl形式で保存します。
pkl形式とはオブジェクトの状態を読み込み/保存が簡単にできる形式のことです。
import numpy as np
from PIL import Image
import pickle
import glob
dataset = []
#先ほど保存したディレクトリのパス
for f in glob.glob("~~~~~~~/cat_face/*.jpg"):
img = np.array(Image.open(f))
dataset.append(img)
#保存したいディレクトリのパスに変更してください
with open("~~~~~~/cat_face.pkl", "wb") as f:
pickle.dump(dataset, f, -1)
実際に学習してみる
モデルはオライリーの「pythonで始める教師なし学習」を参考に実装しました。
モデルの全体は以下のようになっています。
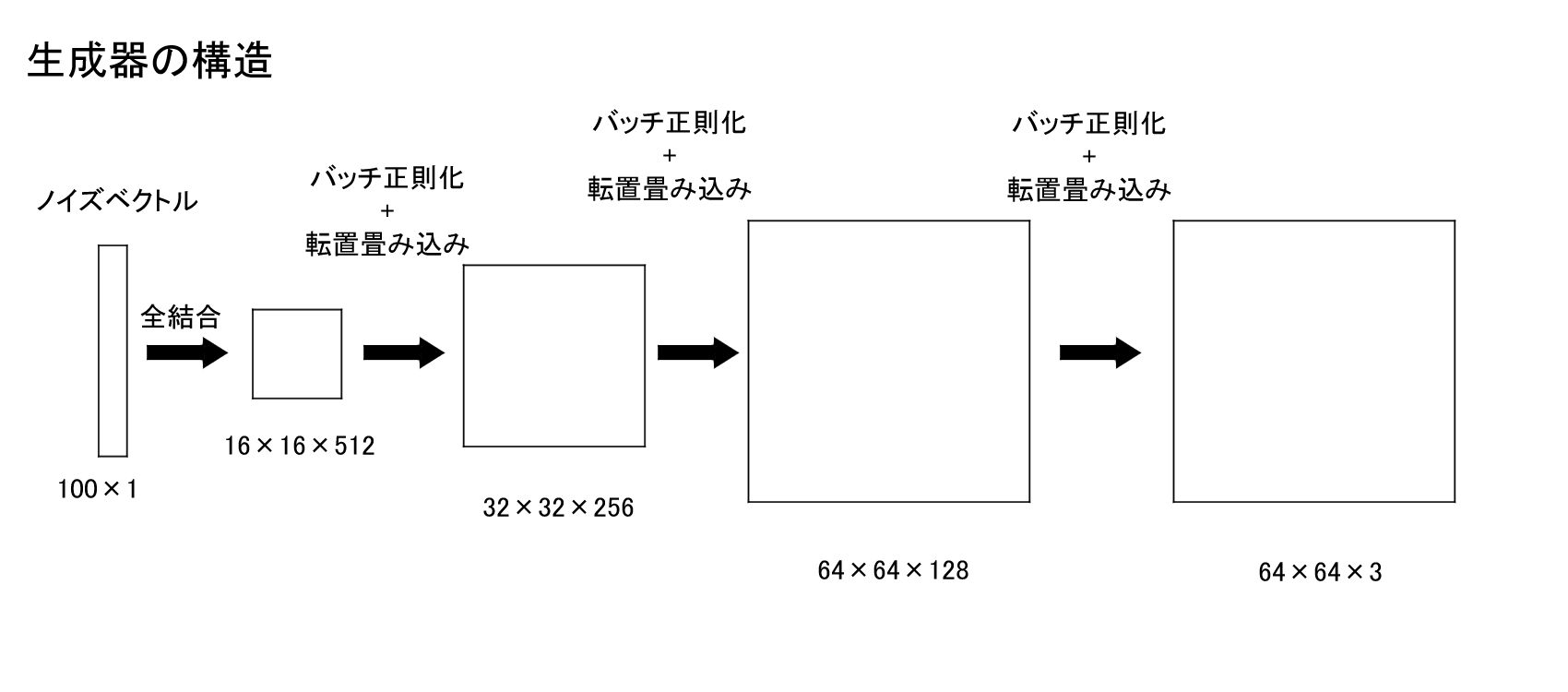
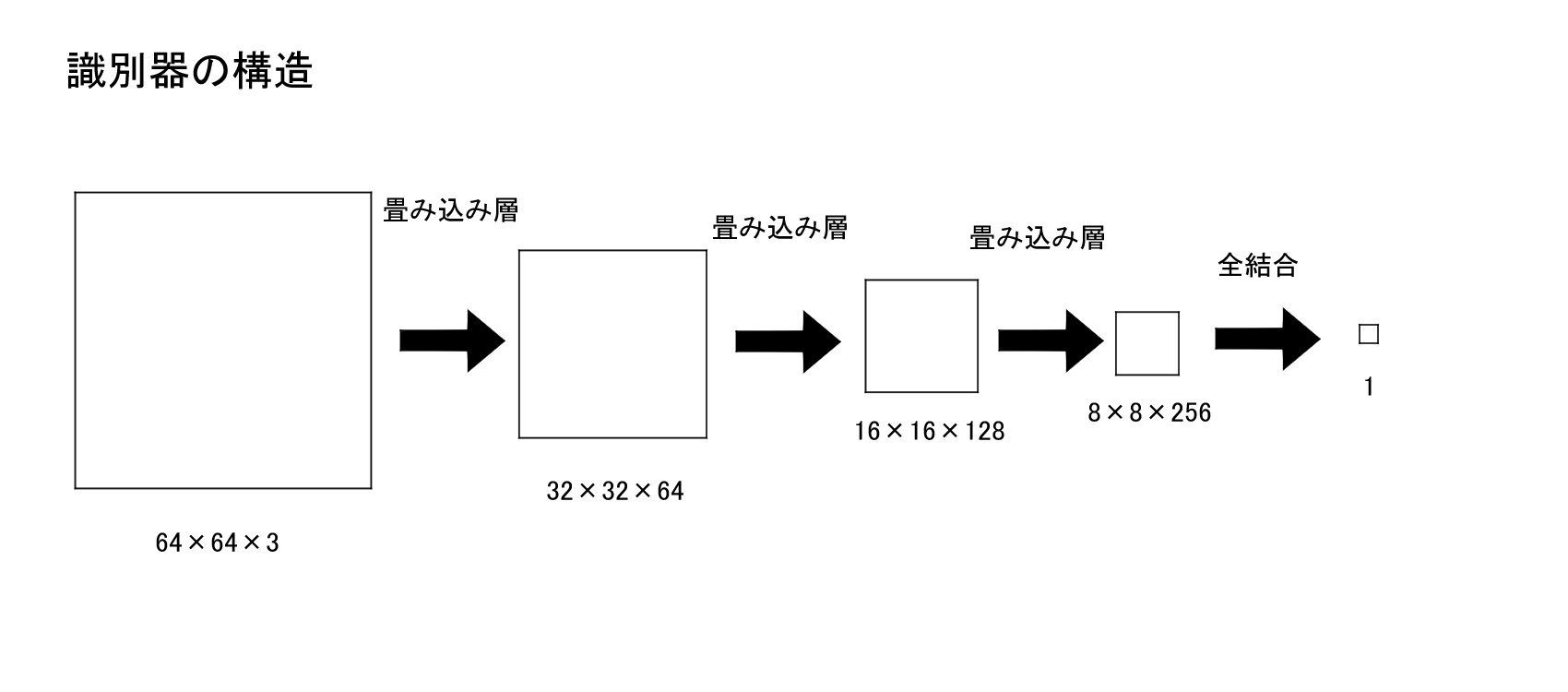
import pickle
from PIL import Image
import numpy as np
import keras
import keras
from keras import Sequential
from keras.layers import *
from keras.optimizers import RMSprop
import os
import matplotlib.pyplot as plt
#モデルを保存するファイル名
generator_filename = "generator.h5"
discriminator_filename = "discriminator.h5"
def generator():
if os.path.isfile(generator_filename):
return keras.models.load_model(generator_filename)
noise_shape = (100,)
model = Sequential()
#全結合 100→16*16*512
model.add(Dense(512 * 16 * 16, activation="relu", input_shape=noise_shape))
model.add(Reshape((16, 16, 512)))
model.add(BatchNormalization(momentum=0.8))
#転置畳み込み 16*16*512→32*32*256
model.add(UpSampling2D())
model.add(Conv2D(256, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
#転置畳み込み 32*32*256→64*64*128
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
#転置畳み込み 64*64*128→64*64*3
model.add(Conv2D(3, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
model.summary()
return model
def discriminator():
if os.path.isfile(discriminator_filename):
return keras.models.load_model(discriminator_filename)
model = Sequential()
#畳み込み 64*64*3->32*32*64
model.add(Conv2D(64, kernel_size=3, strides=2, input_shape=(64,64,3), padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
#畳み込み 32*32*64->16*16*128
model.add(Conv2D(128, (5,5), strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
#畳み込み 16*16*128->8*8*256
model.add(Conv2D(256, (5,5), strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
#平坦化
model.add(Flatten())
#全結合
model.add(Dense(1))
model.add(Activation("sigmoid"))
model.summary()
return model
def dis_model(d):
model = Sequential()
model.add(d)
model.compile(optimizer=RMSprop(lr=0.0002, decay=0.0), loss='binary_crossentropy', metrics=['accuracy'])
return model
def adv_model(g,d):
d.trainable = False
model = Sequential([g, d])
model.compile(optimizer=RMSprop(lr=0.0002, decay=0.0), loss='binary_crossentropy', metrics=['accuracy'])
return model
#バッチ/データサイズはお使いのGPUとデータの大きさによって変えてください
#学習データは乱択で選択するので正確には指定エポック学習できるわけではありません
EPOCH = 1000
DATA_SIZE = 9993
BATCH = 256
if __name__ == "__main__":
#pklファイルを格納しているパスに書き換えてください
with open("./kaggle_cat/data.pkl", "rb") as f:
dataset = pickle.load(f)
fixed_noise = np.random.uniform(-1.0, 1.0, size=[25,100])
#-1~1で正則化
dataset = (dataset-127.5)/127.5
g = generator()
d = discriminator()
dm = dis_model(d)
am = adv_model(g,d)
for i in range(int(DATA_SIZE/BATCH*EPOCH)):
#識別器を学習させる
noise = np.random.uniform(-1.0, 1.0, size=[BATCH,100])
fake = g.predict(noise)
true = dataset[np.random.randint(0, dataset.shape[0], BATCH)]
train_img = np.concatenate([true, fake])
train_label = np.concatenate([np.ones([BATCH,1]), np.zeros([BATCH,1])])
d_loss = dm.train_on_batch(train_img, train_label)
#生成器を学習させる
train_noise = np.random.uniform(-1.0, 1.0, size=[BATCH,100])
train_label = np.ones([BATCH])
a_loss = am.train_on_batch(train_noise, train_label)
#結果を表示
log_mesg = "%d: [D loss: %f acc: %f] [A loss: %f acc: %f]" % (i+1, d_loss[0], d_loss[1], a_loss[0], a_loss[1])
print(log_mesg)
#500バッチごとに画像を生成してモデルを保存
if i % 500 == 0:
d.save("discriminator.h5")
g.save("generator.h5")
check_img = g.predict(fixed_noise)
#生成された画像データを0-255の8bitのunsigned int型に収めます
check_img = check_img*127.5+127.5
check_img = check_img.astype("uint8")
# タイル状に num × num 枚配置
num = 5
# 空の入れ物(リスト)を準備
d_list = []
for j in range(len(check_img)):
img = Image.fromarray(check_img[j])
img = np.asarray(img)
d_list.append(img)
# タイル状に画像を一覧表示
fig, ax = plt.subplots(num, num, figsize=(10, 10))
fig.subplots_adjust(hspace=0, wspace=0)
for j in range(num):
for k in range(num):
ax[j, k].xaxis.set_major_locator(plt.NullLocator())
ax[j, k].yaxis.set_major_locator(plt.NullLocator())
ax[j, k].imshow(d_list[num*j+k], cmap="bone")
#いい感じの保存名をつけましょう
fig.savefig("~~~~~~~"+ str(i) + ".png")
学習結果
バッチサイズ256で15000バッチほど学習させてみた結果が以下のようになっています。
0バッチ学習後

500バッチ学習後

3000バッチ学習後

15000バッチ学習後

1部歪んでいる画像もありますが、基本的にはちゃんとした猫の顔画像が生成できていることがわかります。
生成された画像を見てみると片眼を閉じている猫やオッドアイの猫が生成される確率が学習データにおける割合よりもなぜか高くなっています。なんででしょうか?
学習過程はこんな感じ(1000バッチごとの生成結果)

生成器は長さ100のランダムなノイズベクトルを基に画像を生成しています。なのでこのベクトルをいじることで様々な画像を作成できます。例えば画像生成のもととなるノイズベクトルを少しずつ変えていくことで以下の様な画像も作成できます。よく見る奴ですね。

今回Kerasを用いてDCGANを構築し様々な猫の画像を生成することが出来ました。
今後は同じくGANの派生形でいあるstyleGANやSAGANなども挑戦してみて記事にしたいと思います。
補足情報
python 3.9.7
Keras 2.9.0
参考サイト/文献
機械学習で猫を創造する(失敗)
[画像自動生成] DCGANでISSEY MIYAKEをデザインする
Ankur A. Patel, 2019, Hands-On-Unsupoervised-Learning-Using-Python, O'REILLY (アンクル A. パテル, 2020,『pythonで始める教師なし学習』, 中田 秀基(訳), オライリージャパン)