対象読者
- チャットボットを作成したい方
- QRNNがどの分野で適用可能か知りたい方
- PyTorchを試してみたい方
はじめに
Chainerで学習した対話用のボットをSlackで使用+Twitterから学習データを取得してファインチューニングがおかげ様で人気な記事になっているのでPyTorchを使用して同様のチャットボットを作成しました。
チャット例
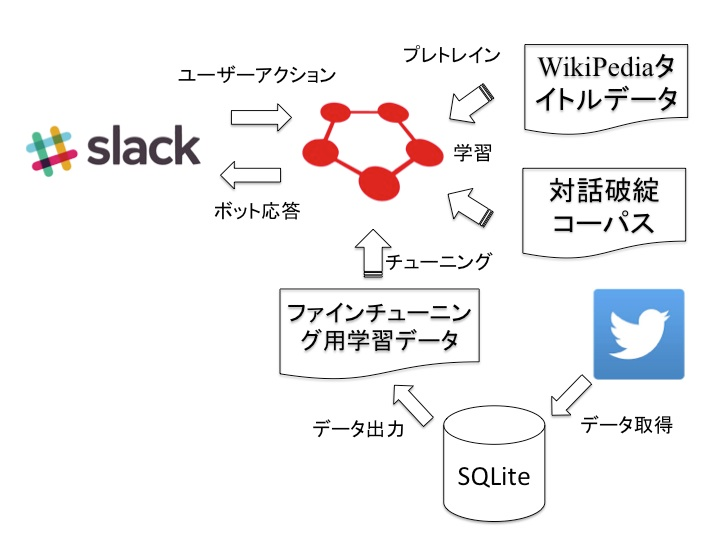
システム構成
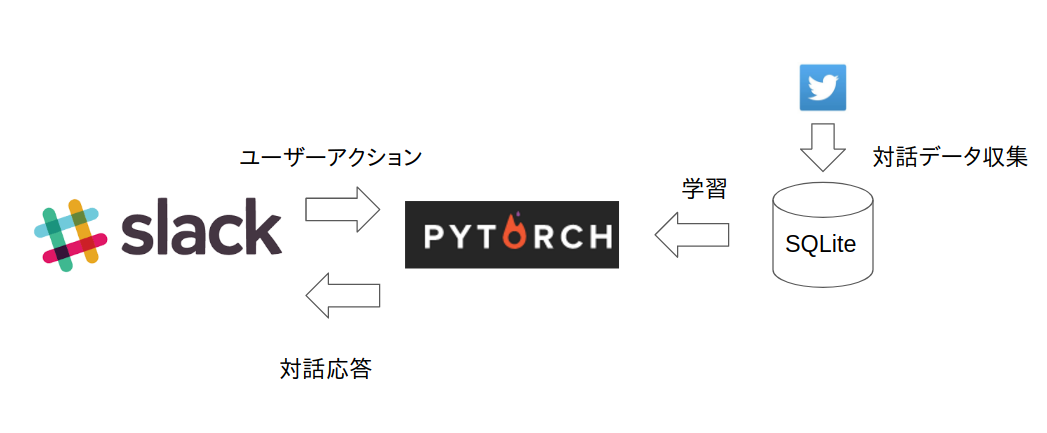
システム構成の違いは事前学習なしで学習している点です。それでも動作したQRNNはかなりのパフォーマンスを発揮できることが期待できます。
以前の構成
今回の構成
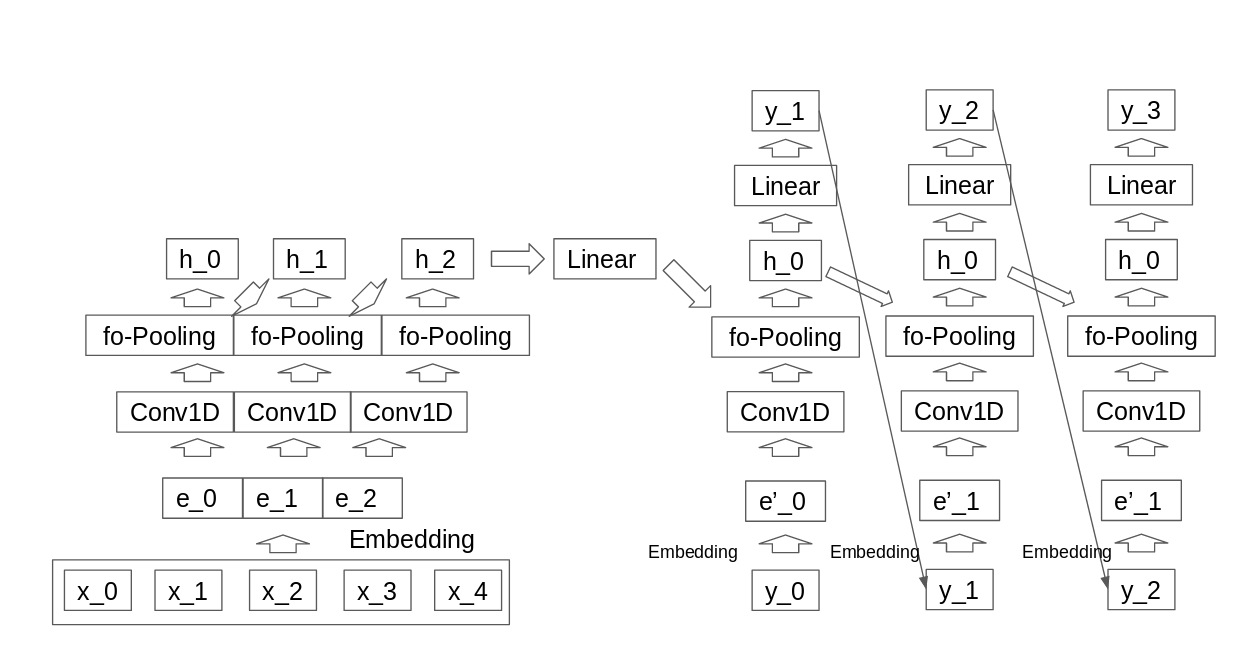
手法
QRNN
- RNN: 過去の情報を利用して学習するため長い文章生成やセンサーデータなどに対して有効に働くが構造上、過去の情報を使用するため並列化処理が難しい。
- CNN: RNNに比べて並列化が容易であり、自然言語の分野にもいくつか適用されてきているがRNNと違い過去の情報を考慮した長い文章生成やセンサーデータは苦手
両者の良い所取りをしたのがQRNNです。
QRNNに関しては良記事があるのでそちらをご参照下さい。
QRNN Encoder Decoder
QRNNはRNNの擬似モデルのため、今までRNNを使用してた領域にも使用可能です。Attentionを使用しないQRNN Encoder DecoderをPyTorchで実装しました。
Encoder部分の処理とDecoder部分の処理は通常のQRNNと同一ですがDecoderにEncoderの内容を反映させる必要があります。
ではどのように反映させるかですがEncoderの最終の隠れ層をDecoderの全出力と畳み込み処理をかけることで反映しています。
ここでVはエンコーダーの最終の隠れ層をデコーダーの次元に合わせるのに使用しています。
具体的な数式は下記です。
Z^l = tanh(W^{l}_z*X^l+V^{l}_z\tilde{h}^{l}_T) \\
F^l = \sigma(W^{l}_f*X^l+V^{l}_f\tilde{h}^{l}_T) \\
O^l = \sigma(W^{l}_o*X^l+V^{l}_o\tilde{h}^{l}_T) \\
コードで追ってみると
まずEncoder部分で最終層の状態を保持します。
c_last = c[range(len(inputs)), (input_len - 1).data, :]
h_last = h[range(len(inputs)), (input_len - 1).data, :]
cell_states.append(c_last)
hidden_states.append((h_last, h))
Decoderで保持された状態を受け取ります。
c, h = layer(h, state, memory)
状態の情報を受け取り畳み込み処理を行います。
(conv_memory, attention_memory) = memory
Z, F, O = self._conv_step(inputs, conv_memory)
下記で取得したメモリーがあれば上式のVの処理で同一空間にマップして足しています。
if memory is not None:
gates = gates + self.conv_linear(memory).unsqueeze(1)
モデル構成
Tensorboardで出力したかったのですが時間がかかりすぎて断念しました。
結果
学習例
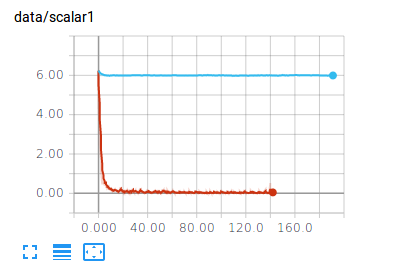
Attentionと比較しています。学習結果に差がありすぎるためAttentionの実装をチェックする必要がありますが圧倒的な差でQRNNのロスが少なくなっています。
時間の都合上、バリデーションデータ、テストデータを用意した評価は行っていません。
また正則化処理であるZoneOut、ドロップアウトは使用していないので過学習気味な気がします。
学習データはTwitterのデータを使用した対話文章をユニークな文章428文、学習データとしては不十分なため7704文にかさ増しして学習しました。(同じ文章をコピペして増やしただけです)
各種モデルのパラメータはコードを参照下さい。
茶色がQRNNで水色がAttentionです。
実際にチャットをしてみたい方へ
デモ動画
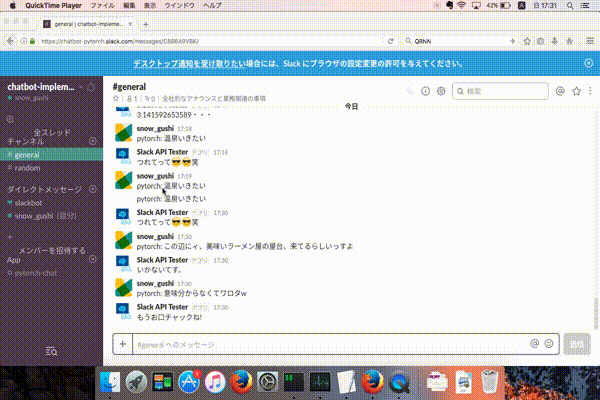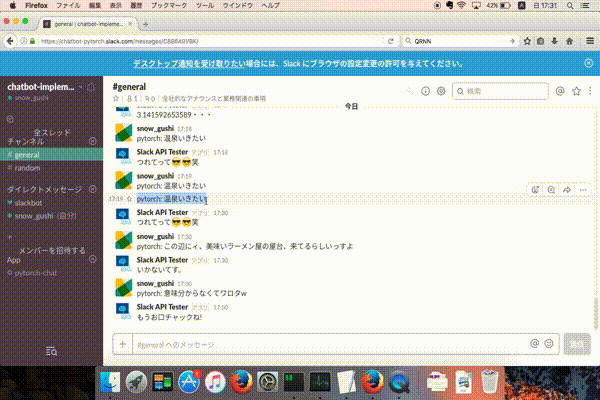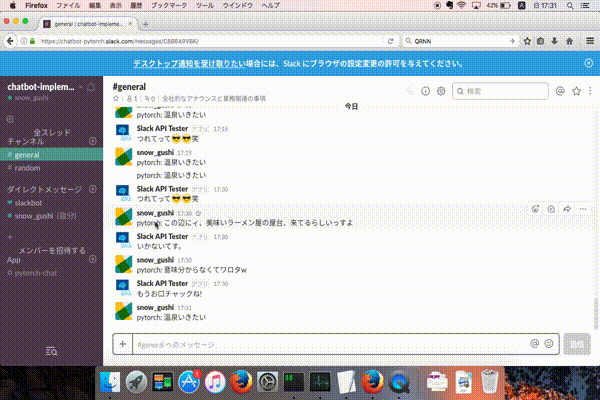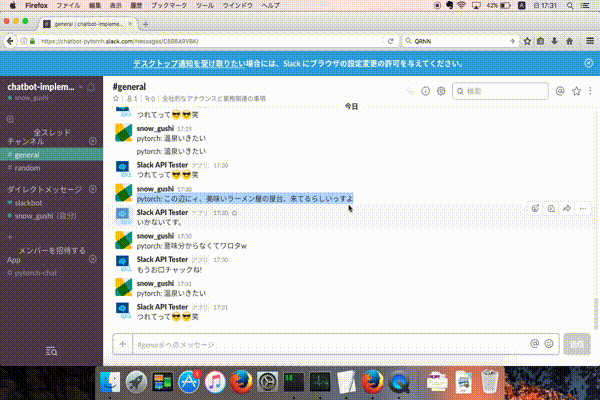
Slackで対話できるようにしました!!
下記のように入力してもらえると対話可能です。
pytorch: {対話したい内容}
今後のチャットデモの対応
- データを増やして学習したモデルの導入
- 正則化処理をいれた場合の比較し性能が良ければ導入
- QRNN+Attentionの比較し性能が良ければ導入
- 検索機能の導入
etc
コード
参考