対象読者
- Tensorboardを使っている人
おまけ
Kerasに関する書籍を翻訳しました。画像識別、画像生成、自然言語処理、時系列予測、強化学習まで幅広くカバーしています。
直感 Deep Learning ―Python×Kerasでアイデアを形にするレシピ
Tensorboardとは
モデルの値を確認する可視化ツールであり、日々確認できる項目が増えています。
これを使いこなせると機械学習エンジニアの仕事がスムーズになると思います。
この記事で紹介するTensorboardの機能
- SCALARS: ロスや精度などの学習中の挙動を確認するために使用
- IMAGES:各層の重みやバイアスの遷移が確認できる
- GRAPHS:モデルの構成を確認するために使用
- DISTRIBUTIONS:各層の値の分布
- HISTOGRAMS:各層の重みのヒストグラム
- PROJECTOR:識別などで潜在空間が適切に識別できる空間になっているかを可視化して確認
場合別の使い分け
ざっくりと傾向を把握したい時に使用
- SCALARS
細かい値を見て検証したい
- IMAGES:各層の重みやバイアスの遷移が確認できる
- DISTRIBUTIONS:各層の値の分布
- HISTOGRAMS:各層の重みのヒストグラム
- PROJECTOR:識別などで潜在空間が適切に識別できる空間になっているかを可視化して確認
モデルの構造を確認したい
- GRAPH
下記ですべての機能が使用可能です。ただしGRAPHとPROJECTORに関係するembeddings_layer_namesとembeddings_metadataは注意が必要になります。その点については後述します。
TensorBoard(log_dir=log_dir,
histogram_freq=1,
write_grads=True,
write_images=1,
embeddings_freq=1,
embeddings_layer_names=layer_name,
embeddings_metadata=metadata_file
)
SCALARS
下記のように学習データとバリデーションデータのロスと精度の遷移を確認できます。
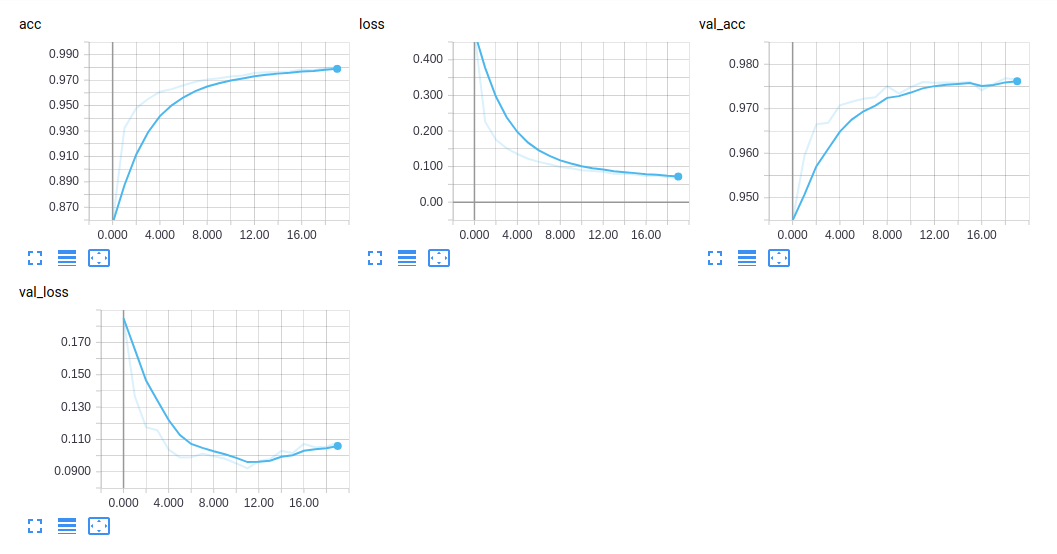
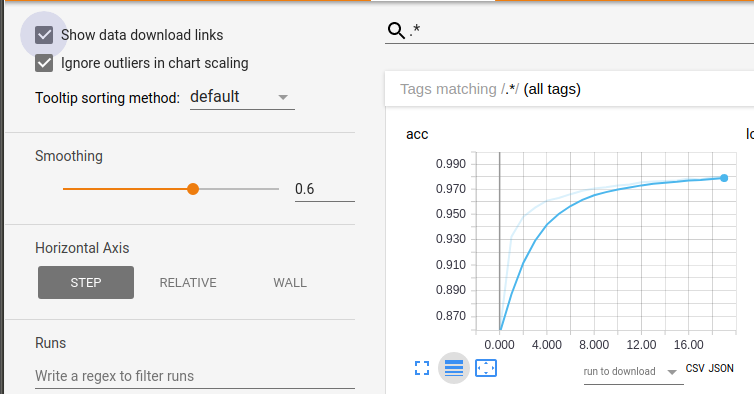
ここでのTipsはこのグラフはcsvやjsonでダウンロード可能です。'Show data download links'をクリックするとcsvとjson用のダウンロードリンクを取得できます
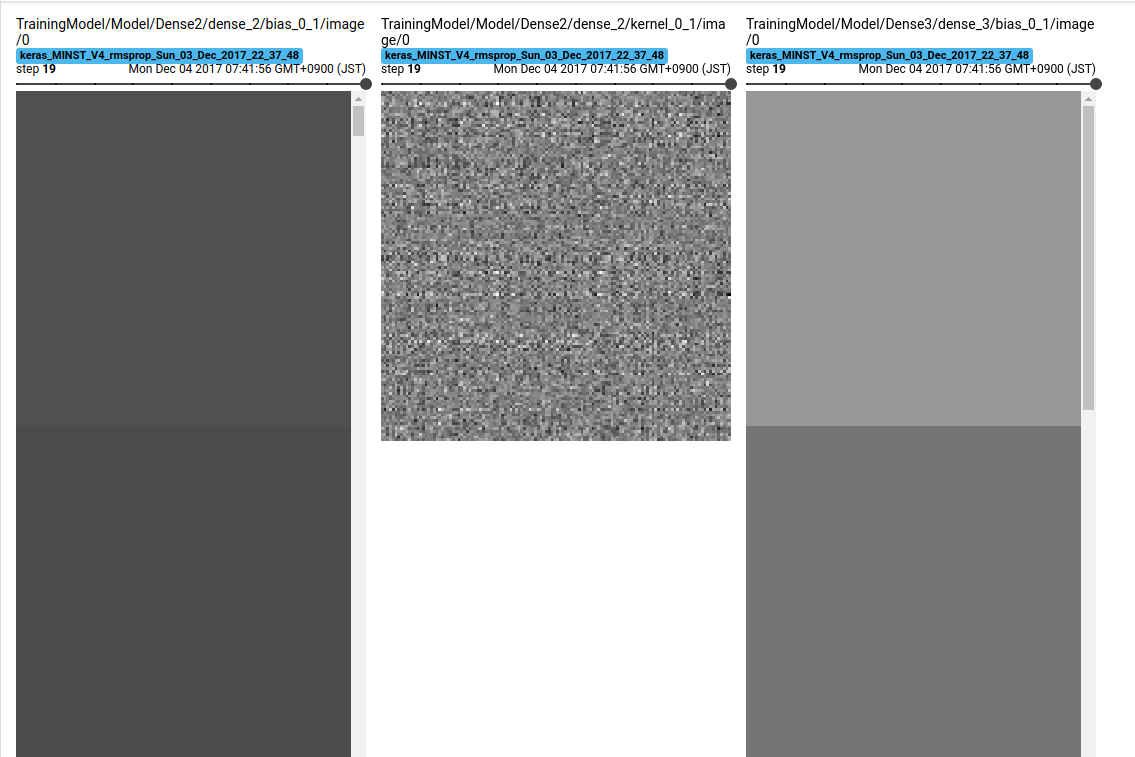
IMAGES
下記で各層の値の遷移が確認できます。
GRAPHS
下記のようにモデルの構造を確認できます。
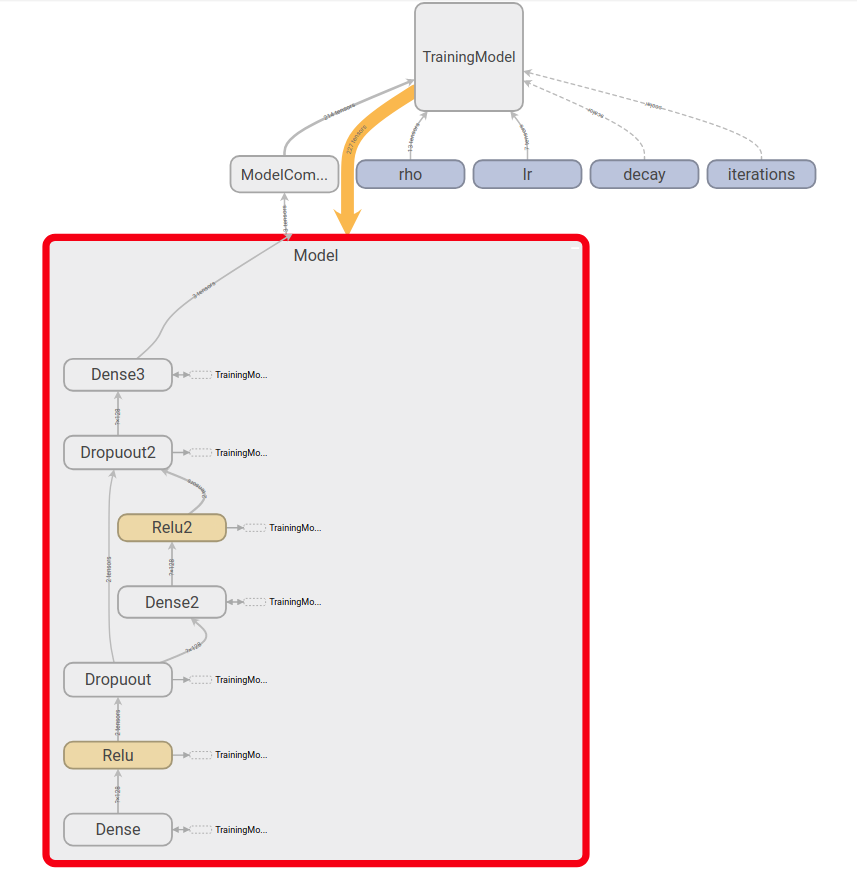
下記のようにスコープを決めてモデルを設定しないと上記のようにまとめて表示してくれないので注意が必要です。
with tf.name_scope('Model') as scope:
model = Sequential()
with tf.name_scope('Dense') as scope:
model.add(Dense(N_HIDDEN, input_shape=(RESHAPED,)))
with tf.name_scope('Relu') as scope:
model.add(Activation('relu'))
with tf.name_scope('Dropuout') as scope:
model.add(Dropout(DROPOUT))
with tf.name_scope('Dense2') as scope:
model.add(Dense(N_HIDDEN))
with tf.name_scope('Relu2') as scope:
model.add(Activation('relu'))
with tf.name_scope('Dropuout2') as scope:
model.add(Dropout(DROPOUT))
with tf.name_scope('Dense3') as scope:
model.add(Dense(NB_CLASSES, activation='softmax'))
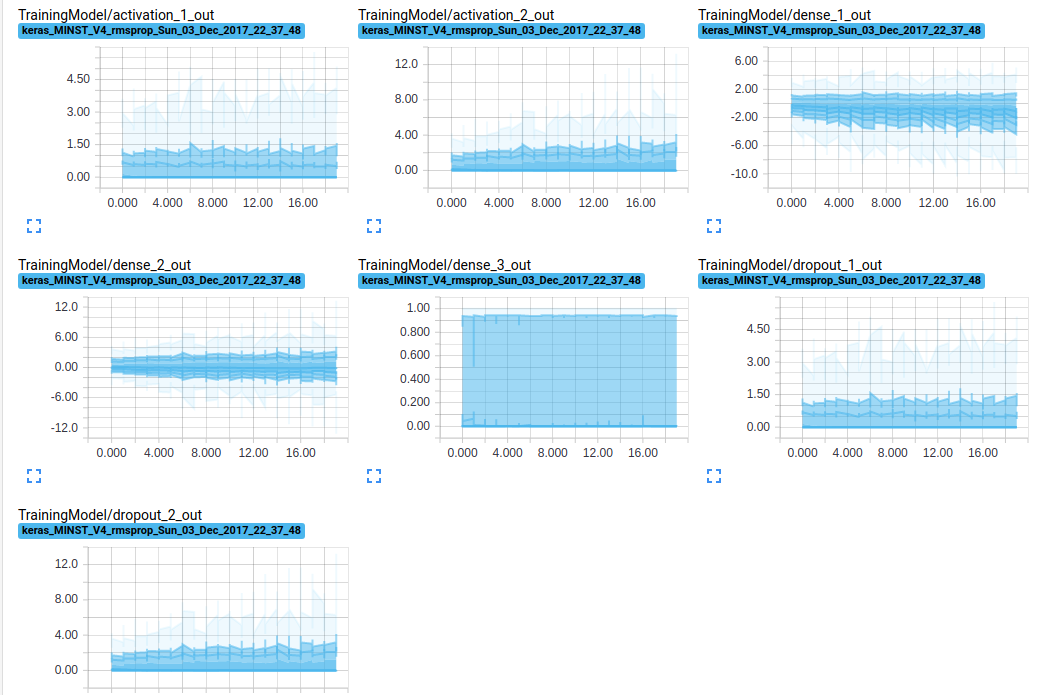
DISTRIBUTIONS
各値の分布です。
横軸がエポック数で縦軸が値です。
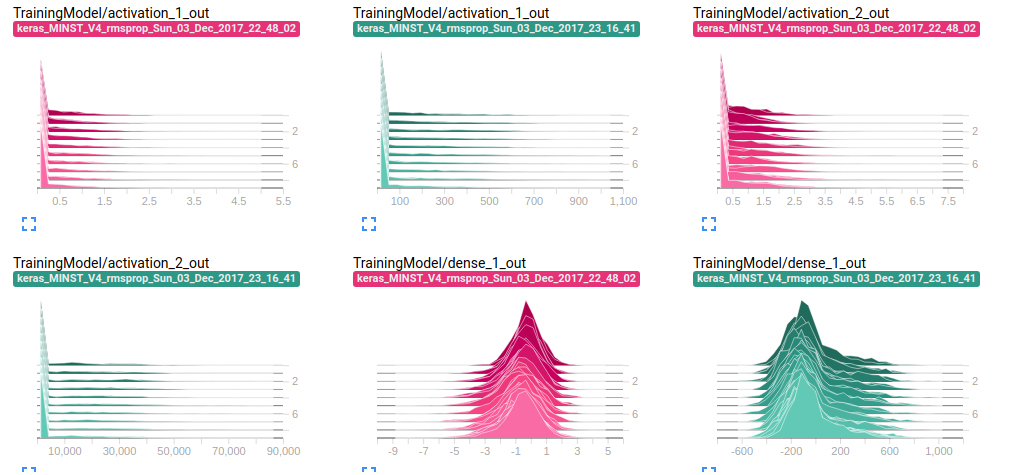
HISTOGRAMS
各層の値のヒストグラムです。奥に行けば行くほど最初のエポックの値になります。
横軸が値の範囲で縦軸が値の頻度になります。
- 緑が学習率を極端にして学習して精度が10%程度のMNIST
- ピンクが通常の精度が95%程度のMNIST
場合です。値の範囲がピンクに比べて大きくまた桁が3桁ほど違います。
このように極端に値の範囲が広い、大きな値に集中しているなどの場合に学習が上手く行っていないことが確認できます。
PROJECTOR
潜在空間をマッピングして可視化する手法です。

通常のKerasの機能を使用する場合にMetafileを用意する必要がありますが潜在空間がどのラベルとマッチしているか分からないと作成できません。
そこで下記のTensorboardを継承したクラスを作成して使用します。
class TensorResponseBoard(TensorBoard):
def __init__(self, val_size, img_path, img_size, **kwargs):
super(TensorResponseBoard, self).__init__(**kwargs)
self.val_size = val_size
self.img_path = img_path
self.img_size = img_size
def set_model(self, model):
super(TensorResponseBoard, self).set_model(model)
if self.embeddings_freq and self.embeddings_layer_names:
embeddings = {}
for layer_name in self.embeddings_layer_names:
# initialize tensors which will later be used in `on_epoch_end()` to
# store the response values by feeding the val data through the model
layer = self.model.get_layer(layer_name)
output_dim = layer.output.shape[-1]
response_tensor = tf.Variable(tf.zeros([self.val_size, output_dim]),
name=layer_name + '_response')
embeddings[layer_name] = response_tensor
self.embeddings = embeddings
self.saver = tf.train.Saver(list(self.embeddings.values()))
response_outputs = [self.model.get_layer(layer_name).output
for layer_name in self.embeddings_layer_names]
self.response_model = Model(self.model.inputs, response_outputs)
config = projector.ProjectorConfig()
embeddings_metadata = {layer_name: self.embeddings_metadata
for layer_name in embeddings.keys()}
for layer_name, response_tensor in self.embeddings.items():
embedding = config.embeddings.add()
embedding.tensor_name = response_tensor.name
# for coloring points by labels
embedding.metadata_path = embeddings_metadata[layer_name]
# for attaching images to the points
embedding.sprite.image_path = self.img_path
embedding.sprite.single_image_dim.extend(self.img_size)
projector.visualize_embeddings(self.writer, config)
def on_epoch_end(self, epoch, logs=None):
super(TensorResponseBoard, self).on_epoch_end(epoch, logs)
if self.embeddings_freq and self.embeddings_ckpt_path:
if epoch % self.embeddings_freq == 0:
# feeding the validation data through the model
val_data = self.validation_data[0]
response_values = self.response_model.predict(val_data)
if len(self.embeddings_layer_names) == 1:
response_values = [response_values]
# record the response at each layers we're monitoring
response_tensors = []
for layer_name in self.embeddings_layer_names:
response_tensors.append(self.embeddings[layer_name])
K.batch_set_value(
list(zip(response_tensors, response_values)))
# finally, save all tensors holding the layer responses
self.saver.save(self.sess, self.embeddings_ckpt_path, epoch)
下記の部分でヴァリデーションデータごとにプロジェクションに必要なEmbeddingのTensorを導出しています。
if self.embeddings_freq and self.embeddings_ckpt_path:
if epoch % self.embeddings_freq == 0:
# feeding the validation data through the model
val_data = self.validation_data[0]
response_values = self.response_model.predict(val_data)
if len(self.embeddings_layer_names) == 1:
response_values = [response_values]
# record the response at each layers we're monitoring
response_tensors = []
for layer_name in self.embeddings_layer_names:
response_tensors.append(self.embeddings[layer_name])
K.batch_set_value(
list(zip(response_tensors, response_values)))
# finally, save all tensors holding the layer responses
self.saver.save(self.sess, self.embeddings_ckpt_path, epoch)
バリデーションデータ分だけ潜在空間を用意できたので画像データの作成とmetaファイルをヴァリデーションサイズ分作成すればマッピングが可能です。
img_array = X_test.reshape(100, 100, 28, 28)
img_array_flat = np.concatenate([np.concatenate([x for x in row], axis=1) for row in img_array])
img = Image.fromarray(np.uint8(255 * (1. - img_array_flat)))
img.save(os.path.join(log_dir, 'images.jpg'))
np.savetxt(os.path.join(log_dir, 'metadata.tsv'), np.where(Y_test)[1], fmt='%d')
クラスの設定とmerada.tsvの作成ができたら下記のようにcallbackモジュールを作成して使用します。
# MNIST
tb = TensorResponseBoard(log_dir=log_dir, histogram_freq=1, batch_size=10,
write_graph=True, write_grads=True, write_images=True,
embeddings_freq=1,
embeddings_layer_names=['dense_1'],
embeddings_metadata='metadata.tsv',
val_size=len(X_test), img_path='images.jpg', img_size=[28, 28])
with tf.name_scope('TrainingModel') as scope:
model.fit(X_train, Y_train,
batch_size=BATCH_SIZE, epochs=NB_EPOCH,
callbacks=[tb],
verbose=VERBOSE, validation_split=VALIDATION_SPLIT)
おまけ
保存するlog_dirの名前に使用したOptimizerのパラメータや実験条件を加えておくと確認が早くなります。モデルのパラメータはグラフに保存されますがその他の情報は保存されないのでここを使用すると良いと思います。
参考