w1の続き。
目的
ICCV2025の自動運転関連の論文を読んで、最新の研究動向を理解したい。ハワイに行きたい。
調べ方
ICCV 2025 accepted papers: https://iccv.thecvf.com/Conferences/2025/AcceptedPapers
autonomous でリンク先で検索
ヒットした論文をalphaXivで要約した内容のポイントをまとめる。詳細部分を論文で確認
backgroundで書かれていた課題点
- 単一車両の自動運転性能に加えて、複数自動車で協調的にコミュニケーションすることも大事
- LLMが自動運転用に精度的に最適化されていない&計算コスト高い
3. CoLMDriver: LLM-based Negotiation Benefits
Cooperative Autonomous Driving
- LLMを活用して自動運転車を協調的に動作させるシステムを提案
協調型運転の特有の課題点
- 目的の異なる車両が同じスペースで競合する可能性がある
- 明確なコミュニケーションが無いと、譲歩しあって進まない
- 車両数が増加すると連携の複雑さが指数関数的に増加する
従来の方法
- 最適化ベース
- リアルタイムで最適な軌道を見つけるのは困難
- 深層学習ベース
- 学習データに無いシーンで精度課題
提案手法
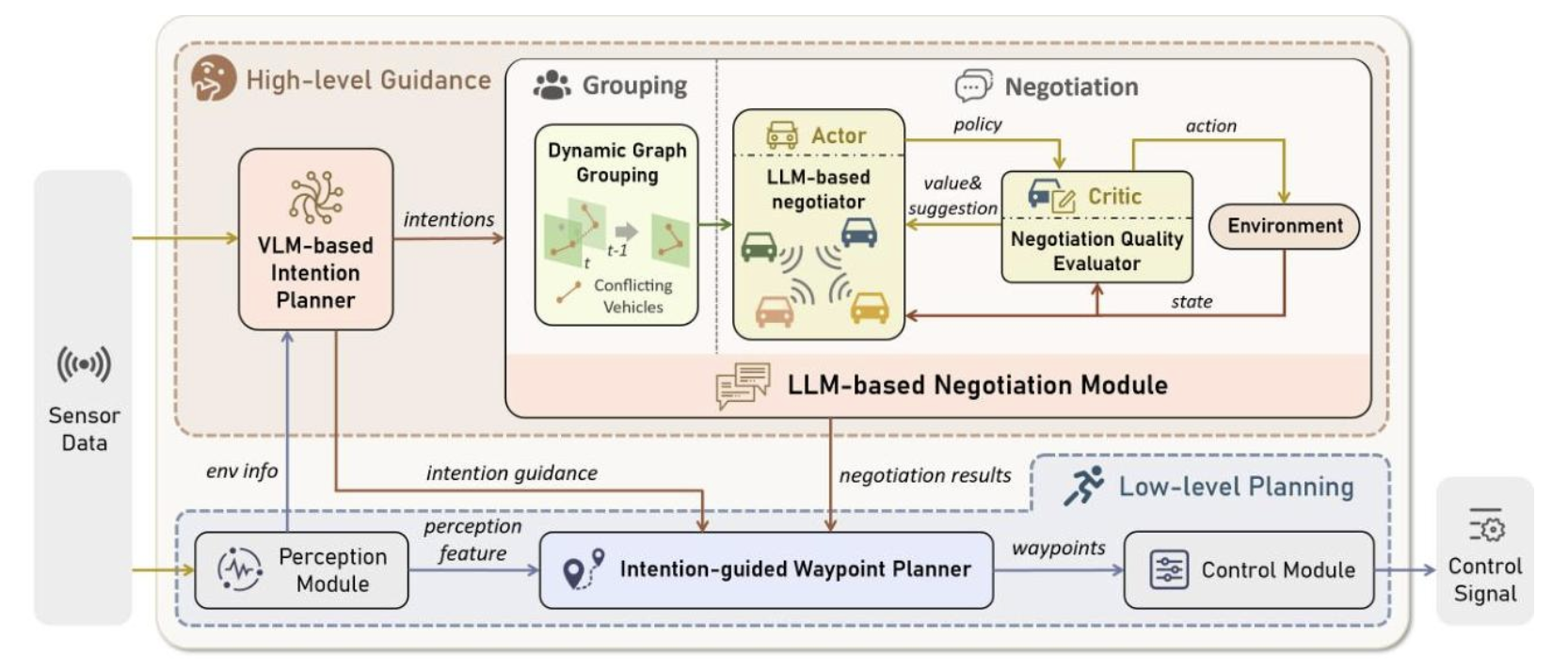
- VLMでintentionとintention guidanceを取得
- LLM-based Negotiationで協調させる
- Actor-Criticベース
- Actor: envから運転policy提案
- Critic: policyを評価し課題点提案(安全性・効率・コンセンサス・実現可能性を評価)
- 衝突可能性のある車両をグルーピングして、それぞれのグループに対して上記のプロセスを回している。
- Low-level Planningでguidanceの意図に沿った自車動作を出力。BEV、command,waypoint tokensをtransfomerで処理。(下図)
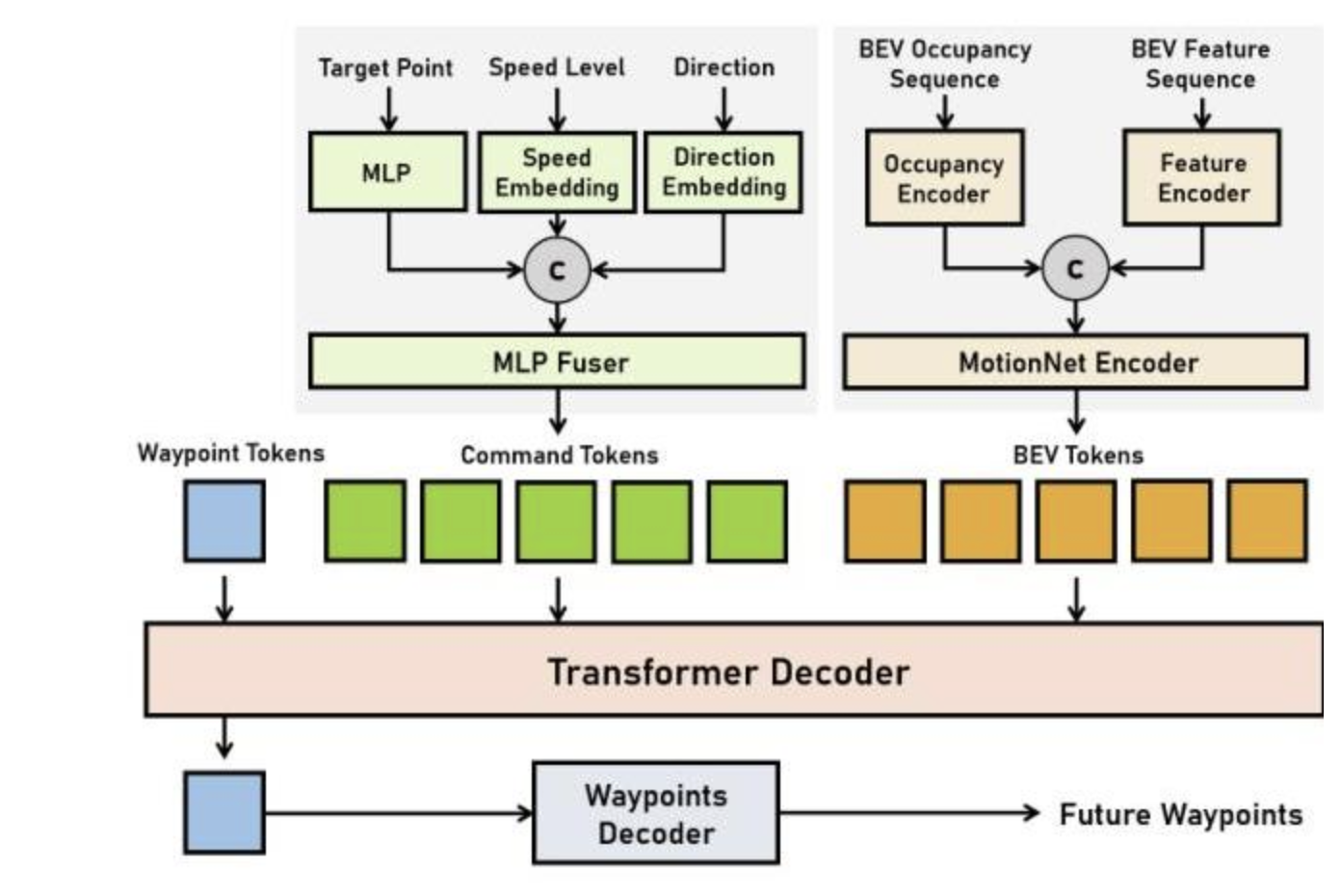
- real-time(5Hz?)でも精度少し劣化するが動作している
課題点
- V2V通信が理想的な条件で設定されている
- 実社会で未評価
- 各車両でLLM実行が計算コスト的に現状困難
4. VLDrive: Vision-Augmented Lightweight MLLMs for Efficient Language-grounded Autonomous Driving
(arxiveで論文見つからず)
LLMを使用した自動運転の課題点を提起
- カメラ情報理解が不十分
- LLMのパラメータに性能がスケールしない
→ カメラ情報のエンコーディングを強化 and LLMはパラメータ削減して精度改善
https://www.youtube.com/watch?v=B3UkRK1jH_w&t=21s
提案手法
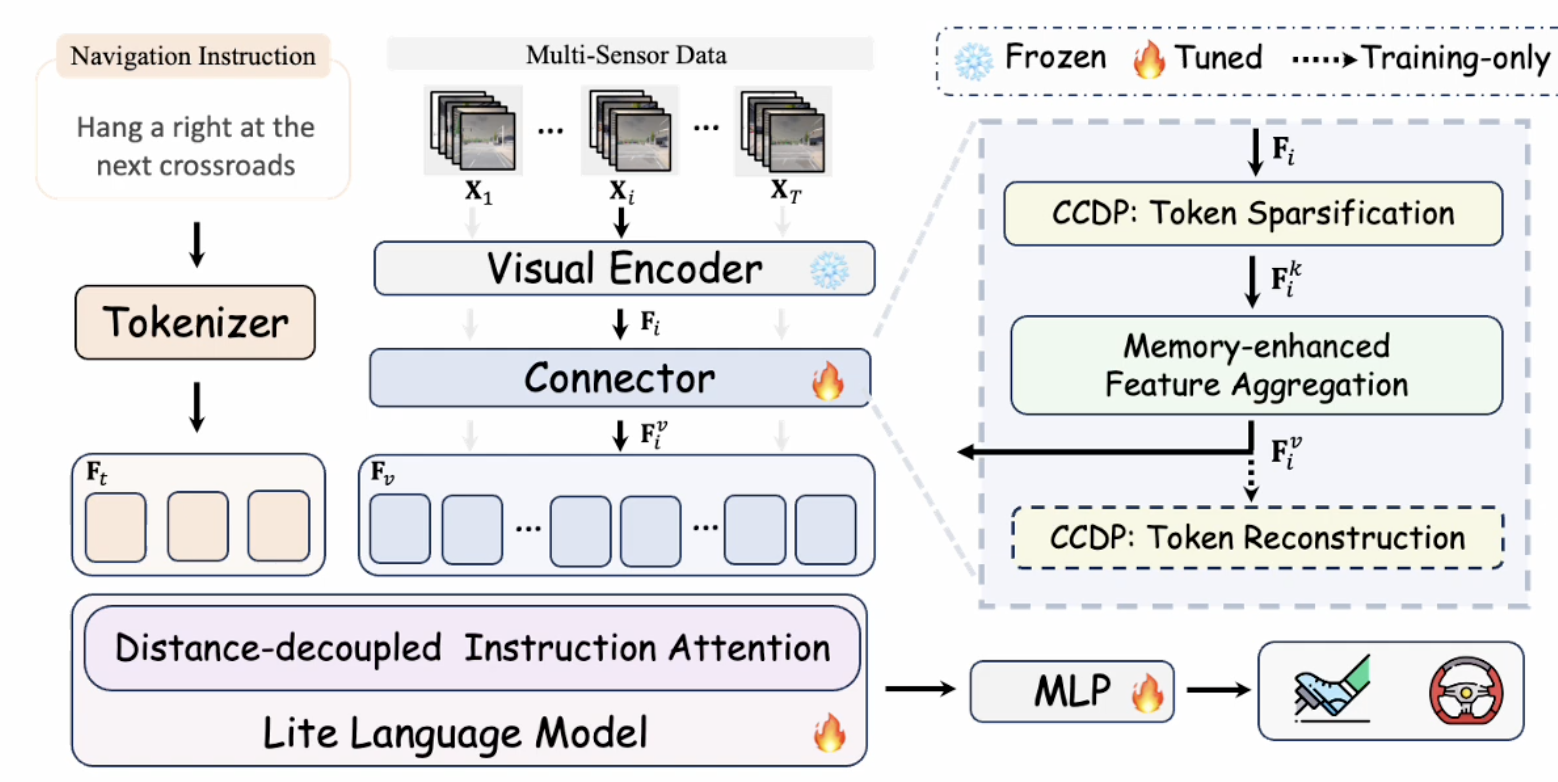
- カメラのエンコーダーの後ろに特有のモジュール追加
- CCDP: カメラのトークン量を減らしつつ情報量を強化する目的のモジュール。1. トークン毎に0 or 1の出力を作成して特定のtokenのみ取得 2.1で取得したtokenをカメラ特徴量+TrafficElementのqueryとcross attention 3. 学習時のみ、1で削除したトークンを含めてreconstruction(情報の整合性を保つ目的)
- DDIA(Distance-decoupled Instruction Attention): trajectory出力でNavi command情報をより出力に反映させる目的のモジュール。LLMでNaviのtokenとVisualのtokenでAttention方法を区別している。Navi tokenはNavi token同士でself-attentionし、Visual tokenはNaviとのCross-attention(何か工夫がありそうだが不明)とトークン順番を考慮してマスクしたVisual tokenとのcross-attention。