負荷テストとサーバレス
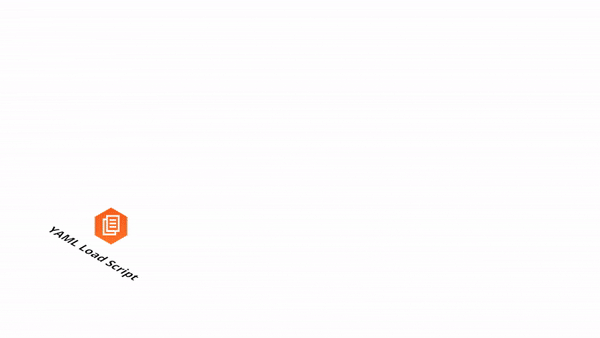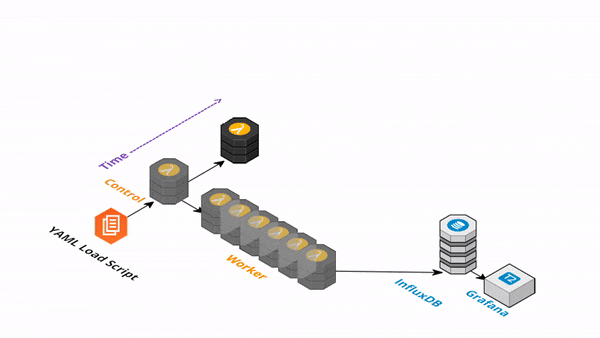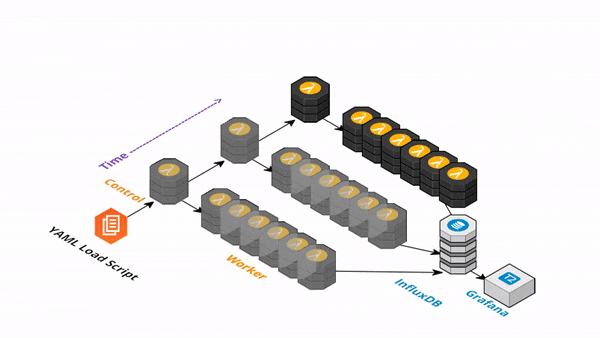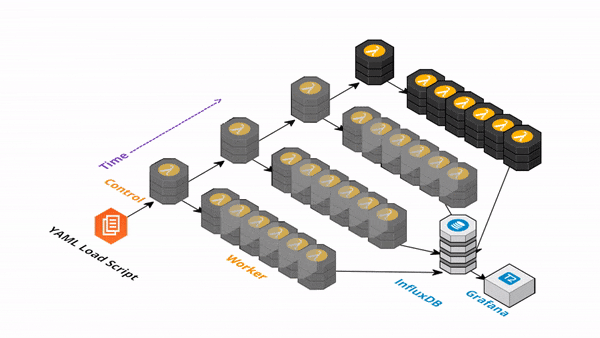
負荷テストに対する考え方は時代とともに変化してきました。従来はサーバスペックやシステムの限界性能を測るという考え方でしたが、クラウドネイティブなシステムではそれに加えて、システムの弾力性(スケールアウトのしやすさ)も考慮する必要があります。
本記事では、負荷テストによるシステムの弾力性の評価と、改善する方法についてツールの具体的な使用方法やアプリケーションのチューニング Tips を交えて説明します。システムの弾力性を評価するために、プロダクション環境でのユーザからのリクエストを想定したロードテストを検討します。
ロードテストでは以下の項目を検証します。
ドリップテスト
ドリップテストは通常、数日間にわたって行われます。通常のバックグラウンド負荷レベルをシミュレートします。遅延またはエラー率の増加が見られる処理を特定します。
スラムテスト
スラムテストは、トラフィックの突然のスパイクをシミュレートします。これにより、オートスケーリングが適切に処理するのが従来困難であったトラフィックに直面したときのシステムの動作を確認できます。
ランプテスト
ランプテストでは、キャンペーン期間中などを想定した日々トラフィックが増加する負荷をシミュレートします。システムが正常にスケールアウトすることを確認します。
負荷テストツールの選定
上記のテストが実行できるように最良の負荷テストツールを選定します。
Apache ab
Apache の ab コマンドはコマンドラインから Web リクエストの負荷をかけることができるシンプルなツールです。手軽に導入できますが、単一のサーバからしか実行できないため、大量のリクエストを送ることができません。こちらの記事が参考になります。
Apache JMeter

Apache JMeter は言わずと知れた負荷テストツールです。マスタスレーブ構成を構築し、マスタとなるサーバにはスレーブの情報(ip アドレスなど)を登録しておきます。GUI でシナリオを作り、マスタからスレーブに指示を送ることでロードテストを実行します。スレーブを増やすことで大量のリクエスト数を送ることができます。
JMeter は確かに多機能で操作性も良く、手に馴染んでいるツールですが負荷をかけるためのサーバを構築したり、GUI からシナリオを作成する手間があります。
Locust

Locust は Python 製の負荷テストツールです。
JMeter 同様、GUI が提供されており、マスタスレーブ構成を取り大量リクエストを生成できます。またテストシナリオを Python で記述でき、柔軟に対応できます。
Locust のシナリオの記述は容易ですが、 JMeter と同様にサーバを構築する必要があります。
アプリケーションがサーバレスで構築できるようになったのに負荷テストのためにサーバを立てなければいけないというのは残念なところです。
宣言的な負荷テストツールをサーバレスで実行するという選択
最近では JAMStack な構成を採用する場合が増え、バックエンドは Web API として提供することが多くなりました。
Web API だけを対象とするならば、画面の表示を想定せずシンプルなテストシナリオを作成できます。
つまり、テストしたい API のエンドポイントと Header, Body などを宣言的に羅列しておくだけ負荷テストを実行できるようなツールがあると幸せです。
Artillery
Artillery は yaml ファイルに宣言的にシナリオを記述し、シンプルなインタフェースで負荷をかけることができる Nodejs 製のツールです。
ローカル実行
npm コマンドでインストールします。
$ npm install -g artillery
ab コマンドのようにワンライナーが用意されています。
以下のコマンドは、10 人の仮想ユーザーを作成し、それぞれが 20 回の HTTP GET リクエストを https://artillery.io/ に送信することを意味しています。
$ artillery quick --count 10 -n 20 https://artillery.io/
実際には以下のように script.yml にテストシナリオを記述して使用します。
config:
target: 'https://artillery.io'
phases:
- duration: 60
arrivalRate: 20
defaults:
headers:
x-my-service-auth: '987401838271002188298567'
scenarios:
- flow:
- get:
url: "/docs"
HTTP 経由で通信する https://artillery.io のエンドポイントのテストシナリオです。 phases には、20 人の新しい仮想ユーザーで 60 秒負荷テストを実行することを記述しています。リクエストは平均で 1 秒ごとに到達します。
以下のコマンドでテストシナリオを実行します。
$ artillery run script.yml
以下のように結果が出力されます。
Complete report @ 2019-01-02T17:32:36.653Z
Scenarios launched: 300
Scenarios completed: 300
Requests completed: 600
RPS sent: 18.86
Request latency:
min: 52.1
max: 11005.7
median: 408.2
p95: 1727.4
p99: 3144
Scenario counts:
0: 300 (100%)
Codes:
200: 300
302: 300
| 項目 | 説明 |
|---|---|
| Scenarios launched | 直前の 10 秒間に作成された仮想ユーザーの数(または合計) |
| Scenarios completed | 直前の 10 秒間(またはテスト全体)でシナリオを完了した仮想ユーザーの数 |
| Requests completed | 送信された HTTP リクエストとレスポンスまたは WebSocket メッセージの数 |
| RPS sent | 直前の 10 秒間(またはテスト全体)に完了した 1 秒あたりのリクエストの平均数 |
| Request latency | p99: 500 は 100 リクエスト中 99 リクエストが完了するまでに 500 ミリ秒以下かかったことを意味 |
| Codes | 受信した HTTP 応答コードの内訳 |
Lambda を使用して大量のリクエストを生み出す
Artillery だけでは単一のサーバ上から実行するため、大量のリクエストを生成できませんが、方法があります。Artillery をサーバレスな実行環境に乗せてスケールさせる serverless-artillery が公開されています。
同様のコンセプトを持ったツールにGoadがあります。Goad は、Go で構築された AWS Lambda 搭載の高度に分散された負荷テストツールです。ここでは名前だけの紹介に留めます。
serverless-artillery は Artillery を serverless framework を使用して AWS Lambda にデプロイします。低コストかつ短時間で大量リクエストを生成する負荷テスト環境を構築できます。
デプロイ
デプロイすると CloudFormation にスタックが作成されます。—stage オプションを使用することで複数の環境に対応させることができます。
$ slsart deploy --stage dev
実行
script.yml に記述されたシナリオを実行します。script.yml 以外の名前のファイルを実行したい場合は -o オプションをつけてシナリオファイルを指定します。
$ slsart invoke --stage dev
CloudWatch にダッシュボードを作成しておくことをおすすめします。
片付け
デプロイされた AWS Lambda と関連するリソースおよびスタックを削除します。
$ slsart remove
プラグインの追加
Artillery には様々なプラグインが用意されています。
artillery-plugin-cloudwatch
artillery-plugin-cloudwatch を追加することで、テスト結果を AWS CloudWatch に記録できます。
他にも DataDog 用のプラグインなどが用意されています。
$ npm install --save artillery-plugin-cloudwatch
以下に serverless.yml の一部を抜粋します。
service: serverless-artillery
provider:
name: aws
runtime: nodejs8.10
region: ap-northeast-1
iamRoleStatements:
- Effect: "Allow"
Action:
- "lambda:InvokeFunction"
Resource:
"Fn::Join":
- ":"
- - "arn:aws:lambda"
- Ref: "AWS::Region"
- Ref: "AWS::AccountId"
- "function"
- "${self:service}-${opt:stage, self:provider.stage}-loadGenerator*" # must match function name
- Effect: "Allow"
Action:
- "sns:Publish"
Resource:
Ref: monitoringAlerts
- Effect: "Allow"
Action:
- "cloudwatch:PutMetricData"
Resource:
- "*"
継続的に負荷テストをするという考え方
従来の開発プロセスでは、アプリケーションを開発し、決められたサーバスペックの VM にデプロイ、最終的に負荷テストを実施することでサーバスペックを決定していました。
クラウド、さらにはサーバレスなアプリケーションの開発プロセスにこの方法は最適でしょうか。
仮想マシン(VM)のスペックの決定、ワークロードに応じた VM 数の調整、障害や災害に備えた可用性の確保などの作業さえもクラウドに任せ、開発者はアプリケーションの開発に専念できるサーバレス。サーバレスはクラウドのあるべき姿を体現しています。素晴らしい技術です。
しかし、その一方で制限がある条件下でのアプリケーション開発は決して容易ではありません。
例えばサーバレスを代表とする Lambda が Web API としてユーザリクエストを受けるアーキテクチャを考えます。この構成がプロダクション環境での性能に耐えうるか、開発プロセスの早い段階で判断したいものです。もし仮にどうしてもプロダクション環境での性能を満たせなかった場合は Fargate に移植するなどの選択肢をとるべきです。
開発プロセスのなるべく早い段階で性能検証をするために CI のプロセスに負荷テストを組み込むアプローチをとります。
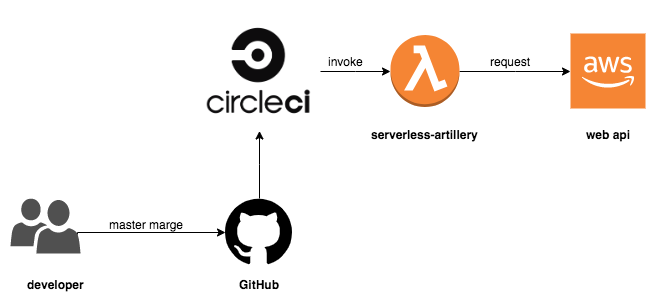
CircleCI から負荷テストを実行する
Artillery の宣言的なシナリオとシンプルな実行インタフェースにより、容易に CI に組み込むことができます。以下のようなフローを想定しています。
- アプリケーションのソースコードを master ブランチにマージする
- アプリケーションが AWS 上にデプロイされる
- 構築済みの serverless-artillery を使用して負荷テストが実行される
- CloudWatch のダッシュボードを確認する
.circleci/config.ymlは以下のようになります。説明の簡単化のためにキャッシュやユニットテストなどは割愛しましたがより詳細なソースはこちらに保管しています。
version: 2
jobs:
build:
docker:
- image: circleci/node:7.10
working_directory: ~/repo
steps:
- checkout
- run: npm install
- run: npm run deploy:stg
loadtest:
docker:
- image: circleci/node:7.10
working_directory: ~/repo
steps:
- checkout
- run: npm --prefix ./loadtester install
- run: npm --prefix ./loadtester run loadtest
workflows:
version: 2
workflow:
jobs:
- build
- loadtest:
requires:
- build
負荷にランダム性を持たせる
CircleCI から継続的に負荷テストを実行できるようになったので開発フェーズにおいて、常にある程度の負荷をかけ続けることができるようになりました。通常のバックグラウンド負荷レベルをシミュレートするドリップテストが継続的に実行できています。さらに、ある程度ユーザリクエストにゆらぎ(ランダム性)を持たせておくとより多くのケースをテストできます。
phases の項目を動的に変更してみましょう。
config:
target: https://gatjk9gwc4.execute-api.ap-northeast-1.amazonaws.com/dev/
phases:
- duration: 10 # この部分を
arrivalRate: 1000000 # ランダムに変化させる
scenarios:
- flow:
- get:
url: "/"
シナリオをランダムに変更する簡単なツールを作成します。
function rand(min, max) {
min = Math.ceil(min);
max = Math.floor(max);
return Math.floor(Math.random() * (max - min)) + min; //The maximum is exclusive and the minimum is inclusive
}
function generatePhases(phases, duration, arrivalRate) {
const generatedPhases = [];
for (let i = 0; i < rand(phases.min, phases.max); i++) {
generatedPhases.push({
duration: rand(duration.min, duration.max),
arrivalRate: rand(arrivalRate.min, arrivalRate.max)
});
}
return generatedPhases;
}
function generateScript() {
fs = require("fs");
yaml = require("js-yaml");
const script = yaml.safeLoad(fs.readFileSync("./script.yml", "utf-8"));
const phases = {
min: 1,
max: 50
};
const duration = {
min: 10,
max: 100
};
const arrivalRate = {
min: 10,
max: 10000
};
script.config.phases = generatePhases(phases, duration, arrivalRate);
fs.writeFileSync("./converted.yml", yaml.safeDump(script));
}
generateScript();
シンプルに node コマンドで実行しても良いですが、以下のように npm スクリプトで実行できるようにしておくと CircleCI の設定を記述する際に見通しがよくなります。
$ node generateSenario.js
version: 2
jobs:
build:
docker:
- image: circleci/node:7.10
working_directory: ~/repo
steps:
- checkout
- run: npm install
- run: npm run deploy:stg
loadtest:
docker:
- image: circleci/node:7.10
working_directory: ~/repo
steps:
- checkout
- run: npm --prefix ./loadtester install
- run: npm --prefix ./loadtester run generate:senario # <--- これを追加してランダム性を持たせる
- run: npm --prefix ./loadtester run loadtest
workflows:
version: 2
workflow:
jobs:
- build
- loadtest:
requires:
- build
実行結果は以下のようになります。このようにしてランダムに生成された script.yml を CI から実行します。今回のサンプルソースではスパイクがかかるようなケースを生成しませんでした。ランダムに生成する値をうまく調整することで、通常時の負荷を想定したドリップテストとスパイクアクセスを想定したスラムテストを同時に継続的に実行できます。
config:
target: 'https://gatjk9gwc4.execute-api.ap-northeast-1.amazonaws.com/dev/'
phases:
- duration: 78
arrivalRate: 6184
- duration: 94
arrivalRate: 4583
- duration: 73
arrivalRate: 6991
- duration: 82
arrivalRate: 2664
- duration: 92
arrivalRate: 5239
- duration: 33
arrivalRate: 1596
- duration: 51
arrivalRate: 9621
- duration: 94
arrivalRate: 4155
- duration: 51
arrivalRate: 3145
- duration: 36
arrivalRate: 802
- duration: 90
arrivalRate: 6286
- duration: 46
arrivalRate: 5219
- duration: 29
arrivalRate: 8020
scenarios:
- flow:
- get:
url: /
負荷テスト CI の環境下でアプリケーションを開発する
想定するアプリケーション
シンプルな CRUD 操作ができる API を開発します。
TODO リストアプリケーションです。ユーザからのリクエストを受け、TODO タスクを登録、更新、一覧表示、削除します。リクエストは APIGateway 経由で Lambda が処理します。データベースには DynamoDB を選択します。
アプリケーションのソースコードはこちらに保管しています。
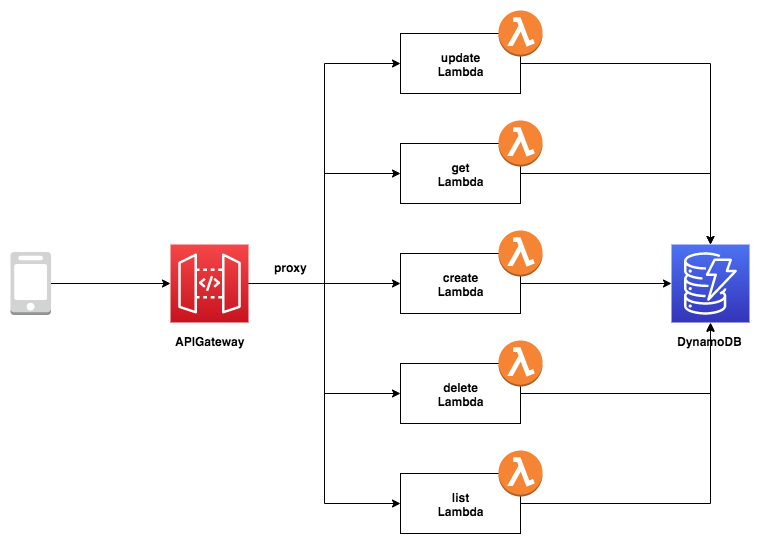
テストシナリオ
- タスクを登録 取得したデータの 1 番目の id を保持する
- 全件表示
- 1件表示
- タスクを更新(id 指定)
- タスクを削除(id 指定)
- タスクを登録 データが増大し続けることを想定してさらに登録するシナリオを入れておく
シナリオを作成して CircleCI から実行する
テストシナリオを作成してローカルでテスト実行します。
Artillary の設定では、 capture に引き受ける変数を指定することでレスポンスの値を次のシナリオに引き継ぐことができます。
config:
target: https://35vbyy1dxd.execute-api.ap-northeast-1.amazonaws.com/dev
phases:
- duration: 10
arrivalRate: 10
scenarios:
- flow:
- post:
url: /todos
json:
text: "my todo"
capture:
json: "$.id"
as: "id"
- get:
url: /todos
- get:
url: /todos/{{ id }}
- put:
url: /todos/{{ id }}
json:
text: "my todo finished"
checked: true
- delete:
url: /todos/{{ id }}
json:
id: { { id } }
$ artillary run script.yml
All virtual users finished
Summary report @ 04:14:49(+0900) 2019-12-12
Scenarios launched: 100
Scenarios completed: 100
Requests completed: 500
RPS sent: 46
Request latency:
min: 71.7
max: 1580.8
median: 123.4
p95: 687.9
p99: 870.6
Scenario counts:
0: 100 (100%)
Codes:
200: 500 # <-- 正常にシナリオが実行できていることを確認
問題がすぐに検知できる
GitHub にソースをマージして CircleCI を動かしましょう。負荷テストが実行されます。
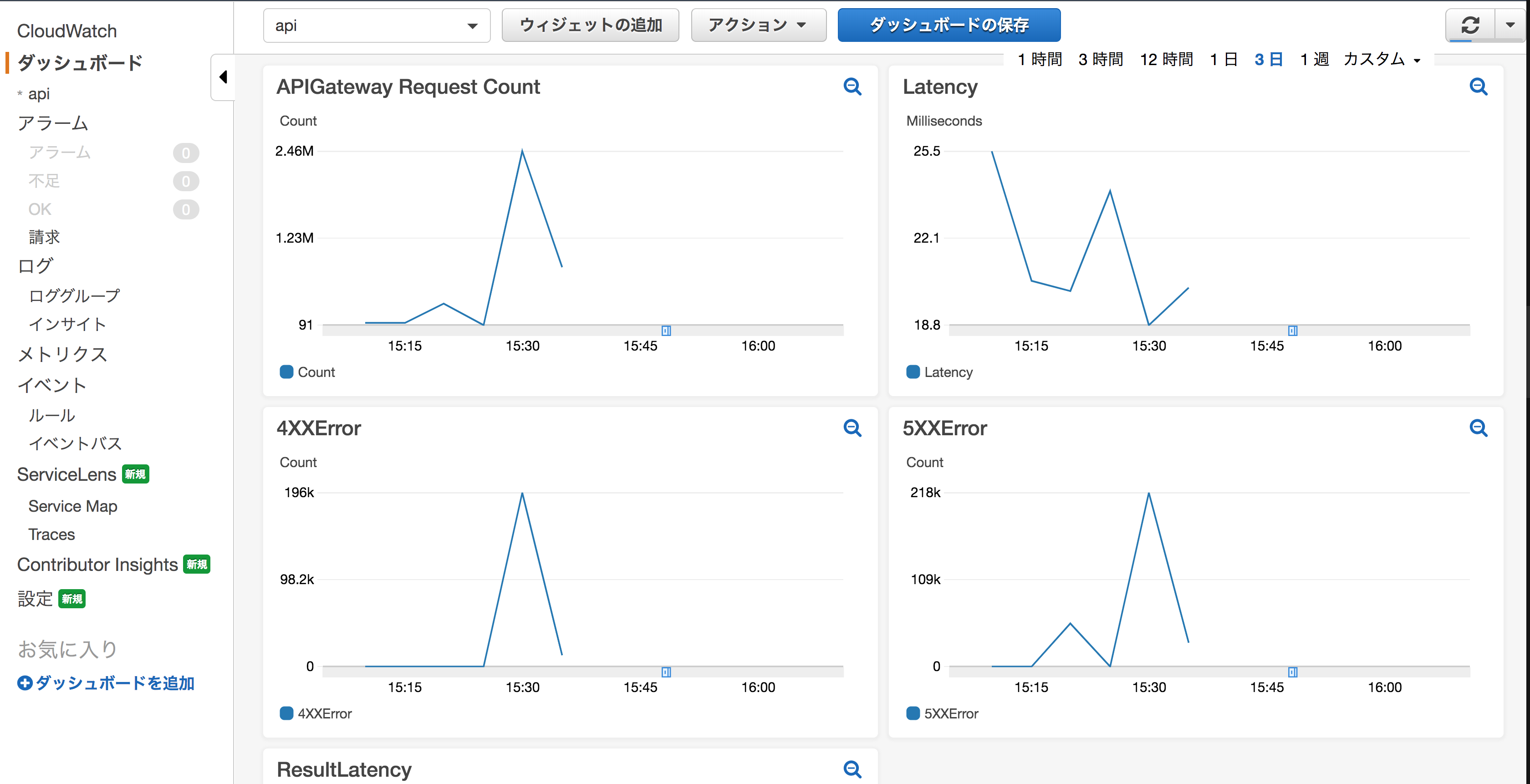
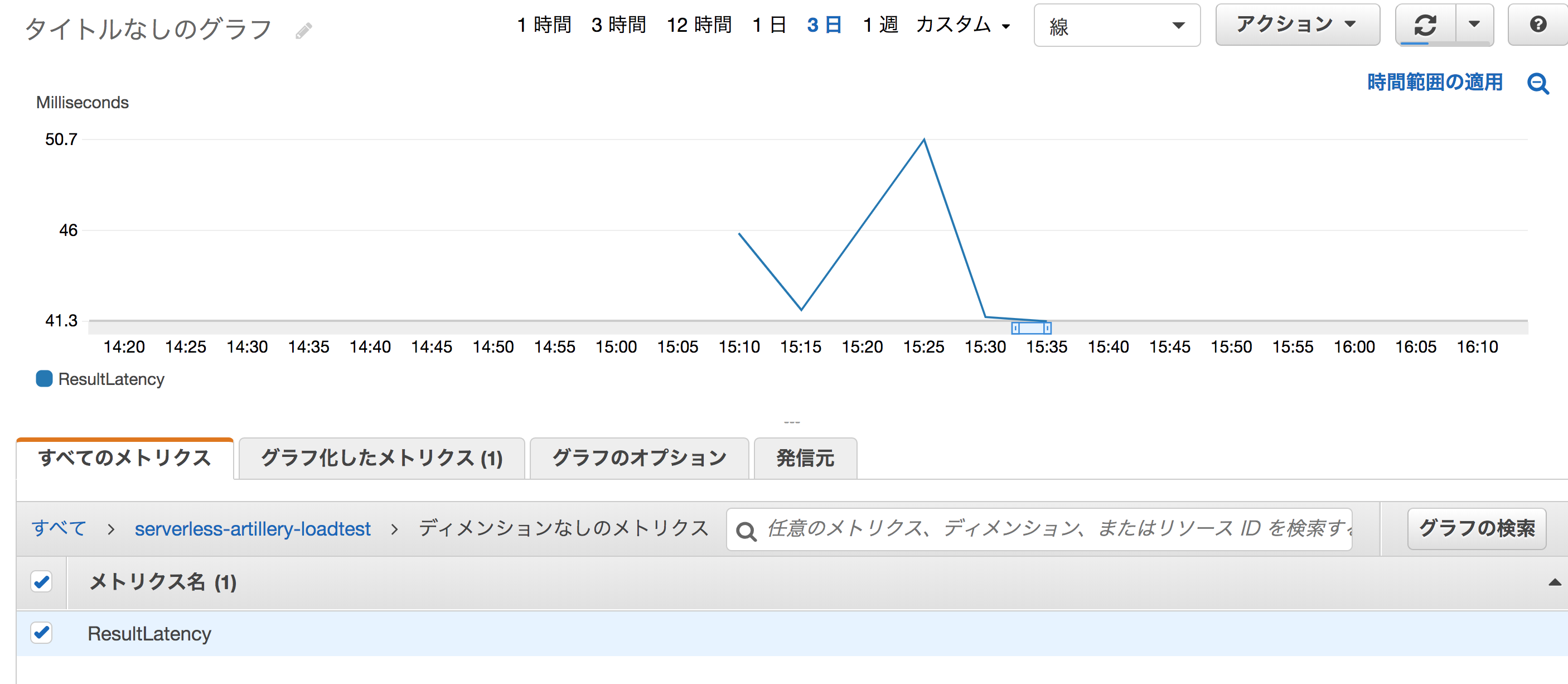
以下は、負荷テスト実施時の APIGateway のメトリクスです。
リクエスト数、レイテンシー、4xxError, 5xxError を表示しています。
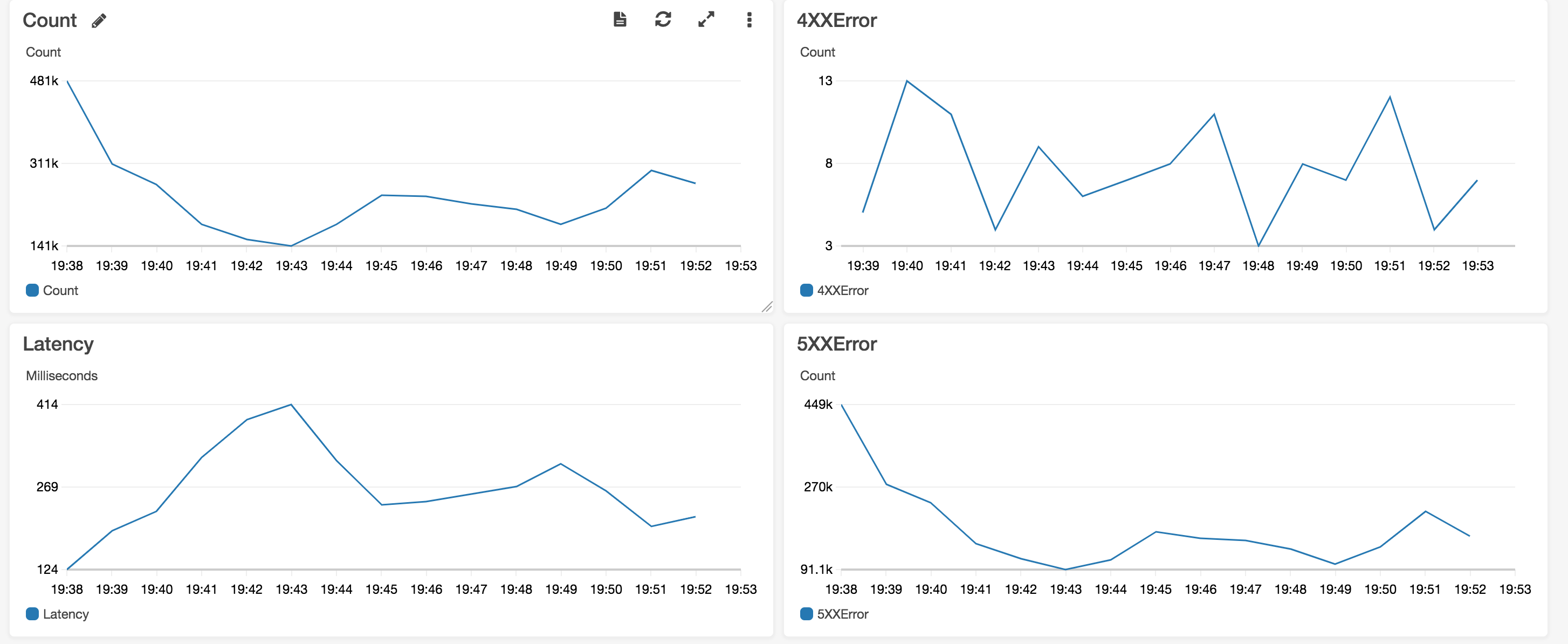
CI によって自動的に負荷がかけられるようになり、開発プロセスの早い段階からパフォーマンスの問題が検知できるようになりました。まず初めに以下のプログラムの問題を特定しました。TODO タスクの一覧を取得する処理ですが DynamoDB のスキャンを使用しており、全件検索になってしまっています。APIGateway の制限 29 秒以上かかってしまうため 5xx エラーが多発しています。とても使い物になりません。
'use strict';
const dynamodb = require('./dynamodb');
module.exports.list = (event, context, callback) => {
const params = {
TableName: process.env.DYNAMODB_TABLE,
Limit: 10 // <-- まずは取得する件数を制限してみる
};
// fetch all todos from the database
dynamodb.scan(params, (error, result) => {
// handle potential errors
if (error) {
console.error(error);
callback(null, {
statusCode: error.statusCode || 501,
headers: { 'Content-Type': 'text/plain' },
body: 'Couldn\'t fetch the todo item.',
});
return;
}
// create a response
const response = {
statusCode: 200,
body: JSON.stringify(result.Items),
};
callback(null, response);
});
};
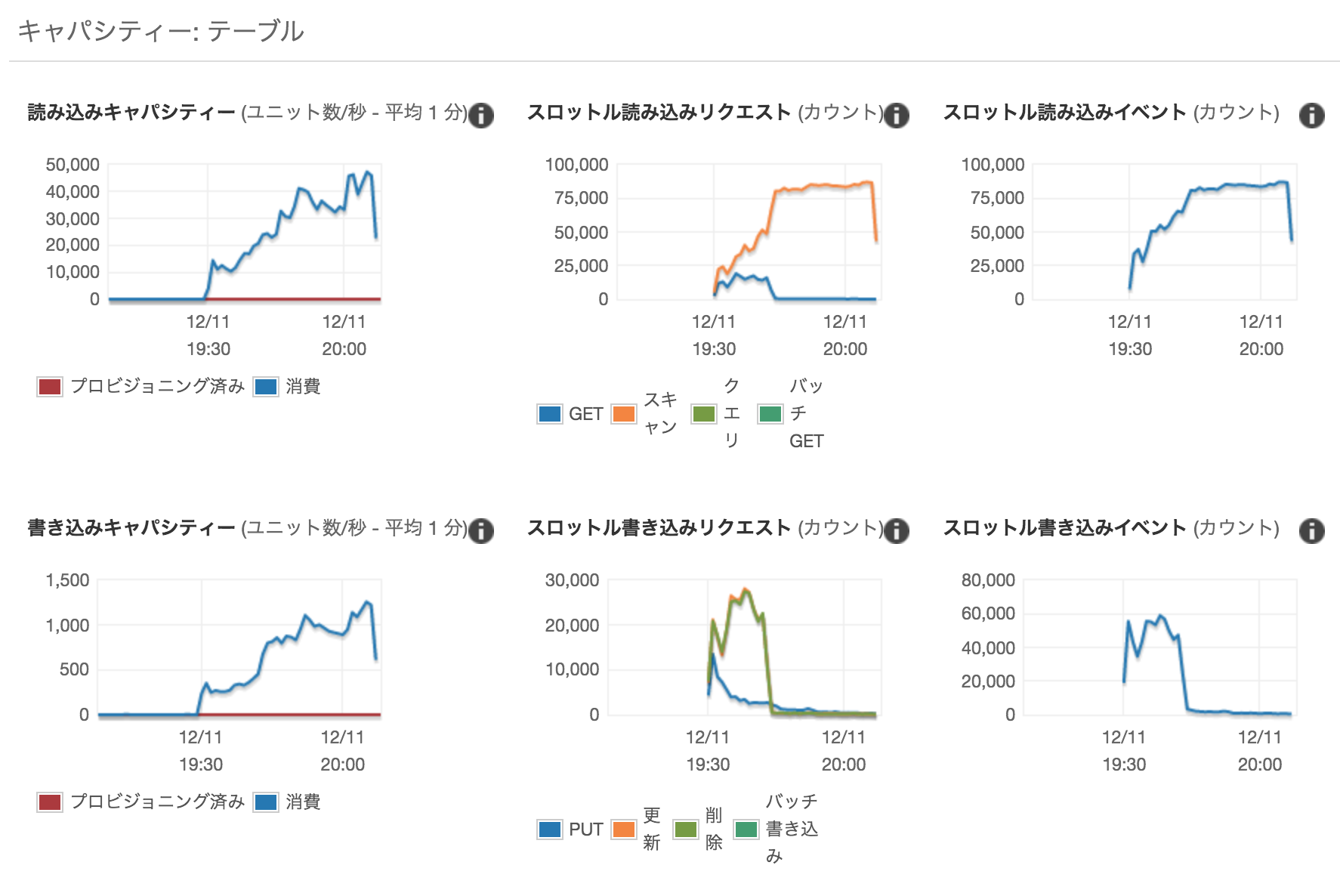
また、DynamoDB のキャパシティユニットが圧倒的に足りません。デフォルト値のままでしたから、当然といえば当然ですが。これも解消しましょう。オートスケーリングの設定をします。
分散トレーシング
複数の Lambda Function や DynamoDB を使用したアプリケーションでは、分散トレーシングを有効活用することで、そのシステムの振る舞いを可視化できます。
AWS の分散トレーシングサービスである x-ray を使用します。必要なライブラリをインストールします。
$ npm install --save-dev serverless-plugin-tracing
$ npm install --save aws-xray-sdk
serverless.yml に必要な情報を追加します。
provider:
name: aws
runtime: nodejs8.10
region: ap-northeast-1
environment:
DYNAMODB_TABLE: ${self:service}-${opt:stage, self:provider.stage}
tracing:
apiGateway: true
lambda: true
iamRoleStatements:
- Effect: Allow
Action:
- dynamodb:Query
- dynamodb:Scan
- dynamodb:GetItem
- dynamodb:PutItem
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource: "arn:aws:dynamodb:${opt:region, self:provider.region}:*:table/${self:provider.environment.DYNAMODB_TABLE}"
- Effect: Allow
Action:
- xray:PutTraceSegments # <-- 追加
- xray:PutTelemetryRecords # <-- 追加
Resource: "*"
アプリケーションに aws-xray-sdk を追加し、トレース可能にします。
"use strict";
- const AWS = require('aws-sdk');
+ const awsXRay = require("aws-xray-sdk");
+ const AWS = awsXRay.captureAWS(require("aws-sdk"));
let options = {};
// connect to local DB if running offline
if (process.env.IS_OFFLINE) {
options = {
region: "localhost",
endpoint: "http://localhost:8000"
};
}
const client = new AWS.DynamoDB.DocumentClient(options);
module.exports = client;
この変更をコミットし、GitHub に PUSH します。負荷テストが始まると AWS の X-Ray コンソールに以下のようにマップやトレーシング情報が作成され始めます。
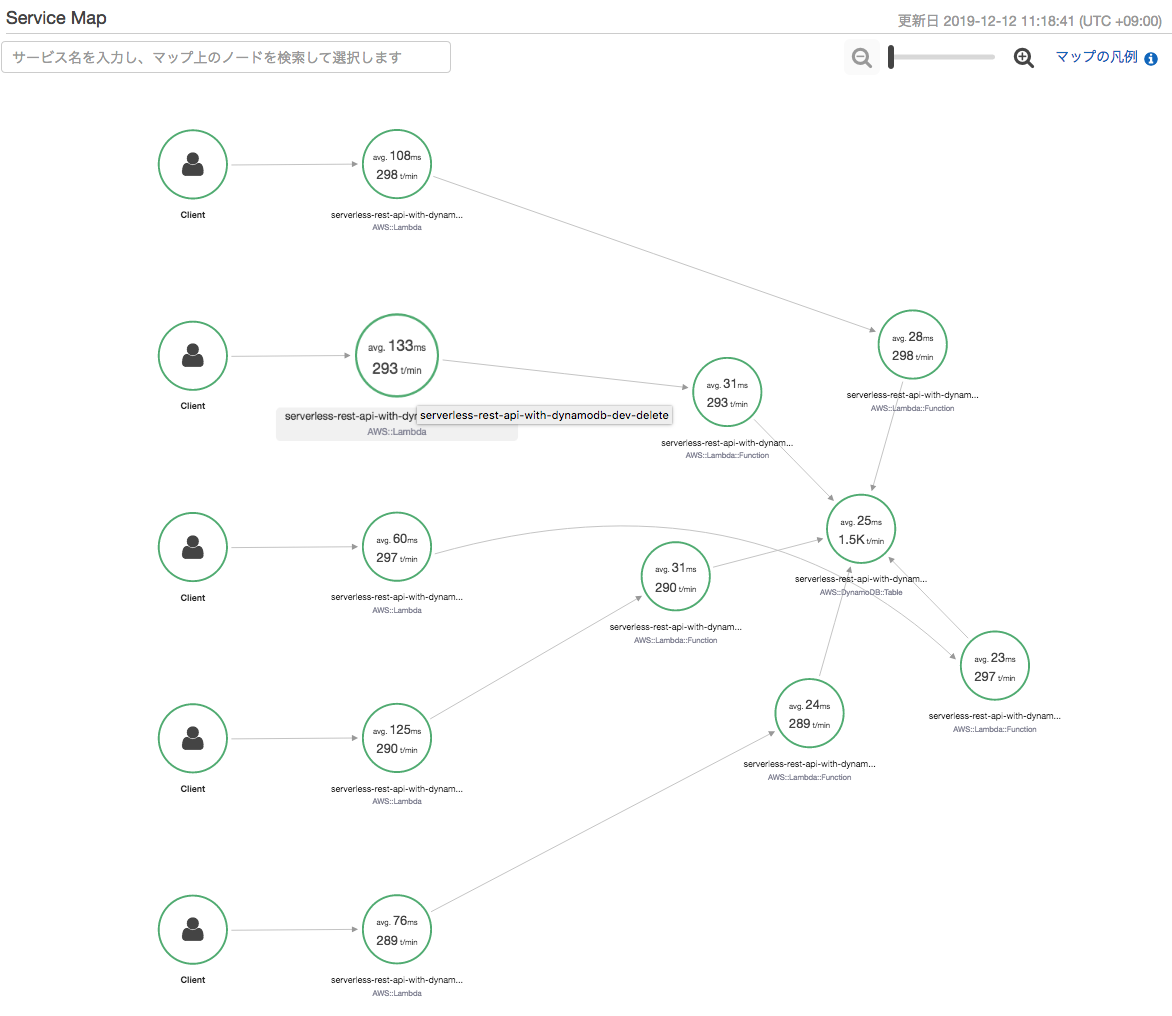
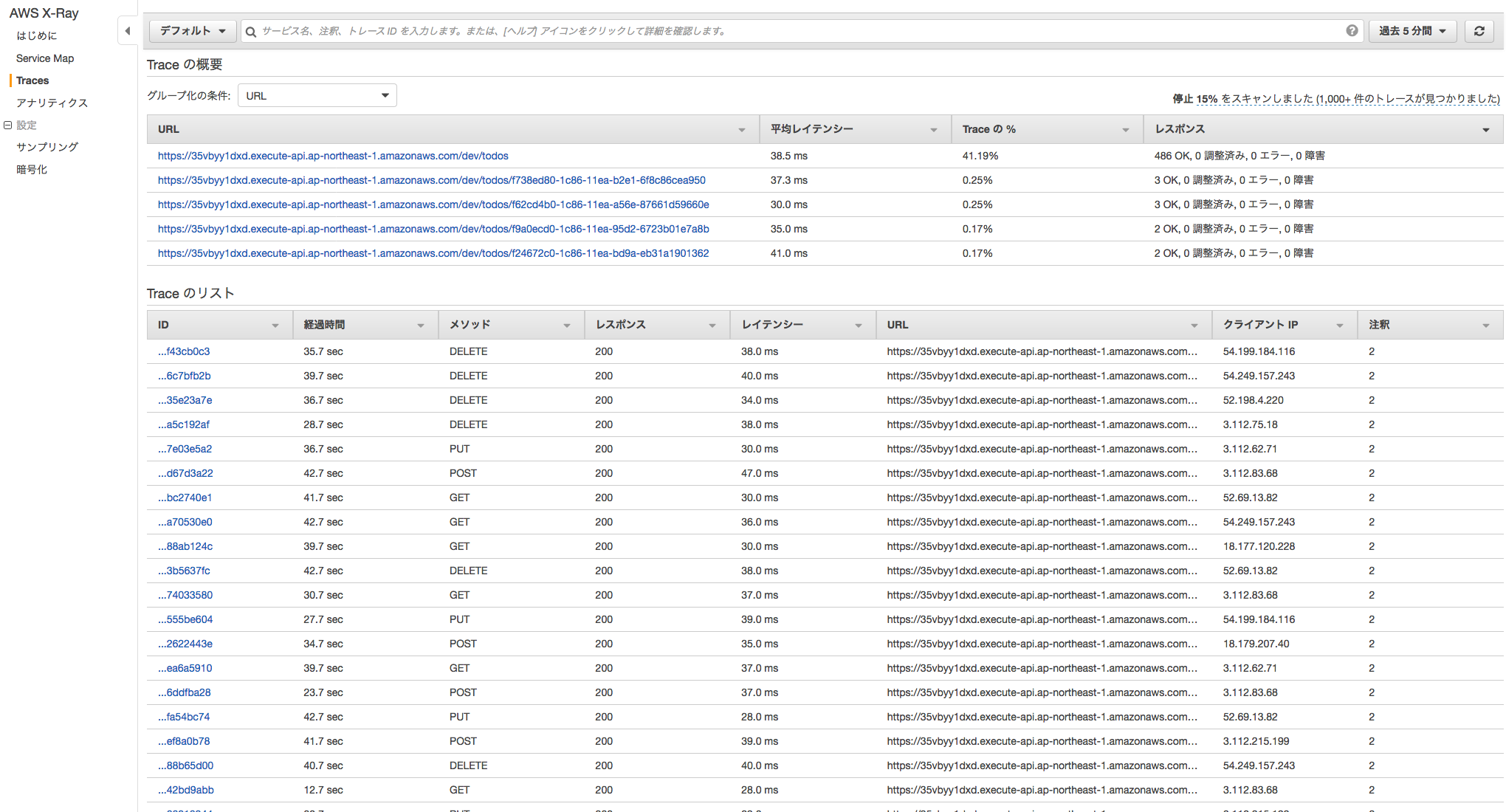
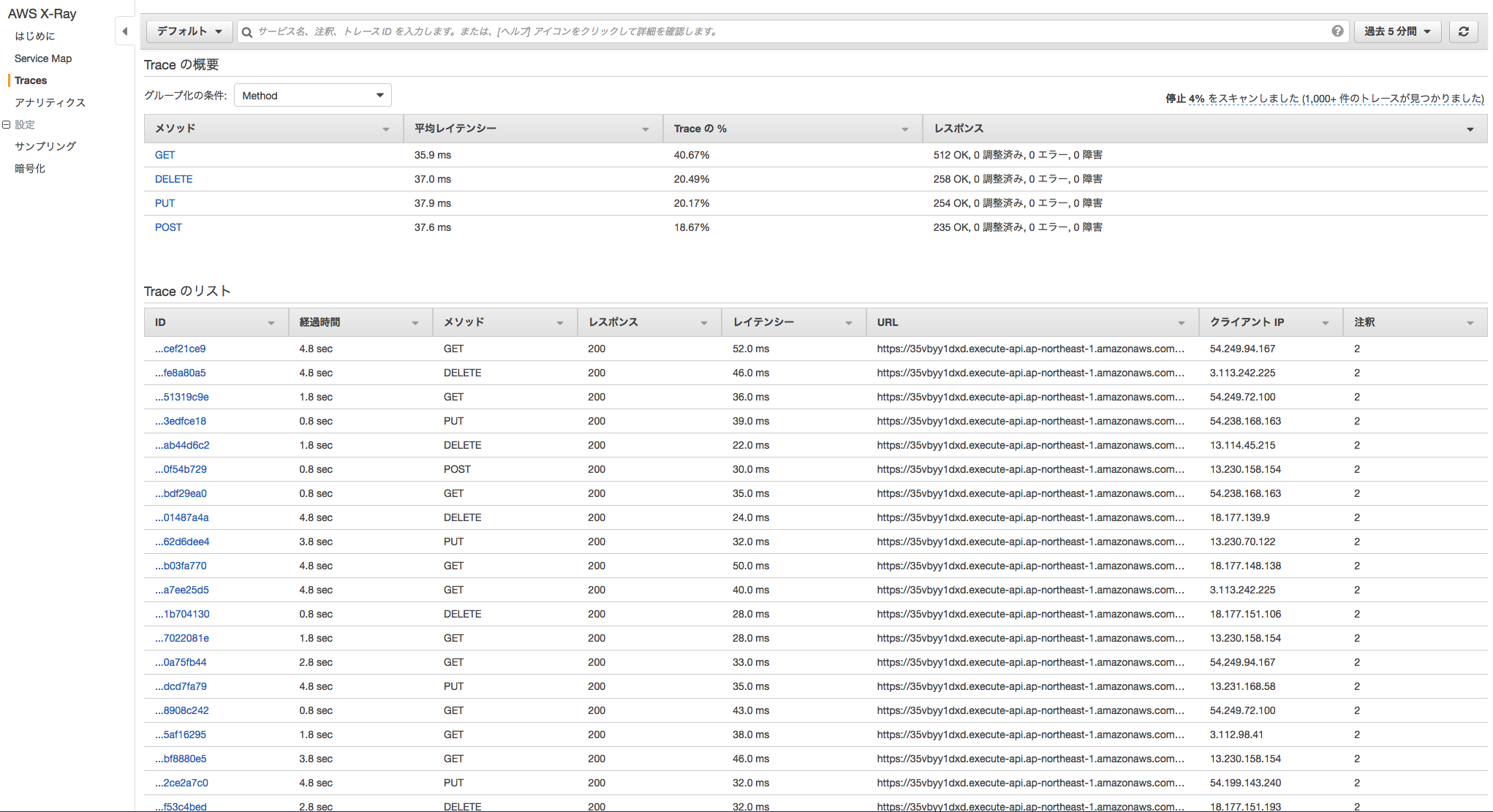
随分と性能改善ができました。
まとめ
serverless-artillery を使用することで低コストかつ短時間で負荷テストの実行環境を用意できました。さらに、CircleCIと組み合わせることで継続的に負荷を与え続けながら開発を進めることも可能です。AWS X-Rayなどの分散トレーシングのサービスを使用することで、高度に分散したアーキテクチャのボトルネックを特定することができました。
サーバレスがクラウドの未来だと信じています。全てがサーバレスになる時代はもうすぐ手の届くところにあります。この先もこの技術領域を開拓して、最良の開発ができるように務めていきたいです。