はじめに
前回に引き続き、今回はkaggleでチュートリアルとして利用されているHouse Price(住宅価格)を予測する問題について、各種の機械学習モデルを組み合わせて予測を行っていきたいと思います。
前回
https://qiita.com/Fumio-eisan/items/061695b2e3b53ac2a750
機械学習用ライブラリ
from sklearn.linear_model import ElasticNet, Lasso, BayesianRidge, LassoLarsIC
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.kernel_ridge import KernelRidge
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from sklearn.base import BaseEstimator, TransformerMixin, RegressorMixin, clone
from sklearn.model_selection import KFold, cross_val_score, train_test_split
from sklearn.metrics import mean_squared_error
import xgboost as xgb
import lightgbm as lgb
モデルの交差検証(Cross Validation)について
交差検証(Cross validation, CV)とは、モデルの予測誤差を推測するテクニックであり、機械学習では広く使われています。
- 学習データをいくつかに分割する(それぞれをfoldと呼ぶ)
- そのうち一つをバリデーションデータ、残りを学習データとして使用し学習及び評価を行う。そしてバリデーションデータのスコアを求める。
- 分割した回数だけバリデーションデータを変えて2.を繰り返す。
- それらスコアの平均でモデルの良し悪しを評価する。
参考URL
https://note.com/naokiwifruit/n/nc90ca48f16e5
https://qiita.com/LicaOka/items/c6725aa8961df9332cc7
n_folds = 5
def rmsle_cv(model):
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(train.values)
rmse= np.sqrt(-cross_val_score(model, train.values, y_train, scoring="neg_mean_squared_error", cv = kf))
return(rmse)
今回は、folds数5で実施しています。
評価指標(RMSLE)について
今回評価指標としては、RMSLE(Root Mean Squared Logarithmic Error)を適用します。この値は、新地と予測値の対数をそれぞれとった後の差の平均の平方根によって計算されます。
- 目的変数(ここではSalePrice等)が裾の重い分布の際に適用されます。対数を取り正規分布にさせるときに用いるものです。
- 対数を取る場合に、真値が0を取るとlogで負に発散します。従い、1を加えて計算をしています。
RMSLE = \sqrt{\frac{1}{n}\sum_{i=1}^{n} (log(y_{i}+1)-log(y_{pred}+1))^2} \\
n:件数\\
y_{i}:実測の値\\
y_{pred}:予測の値
モデルの組み合わせについて
合計6つのモデルを組み合わせて予測モデルを作ります。そのイメージ図は下記です。
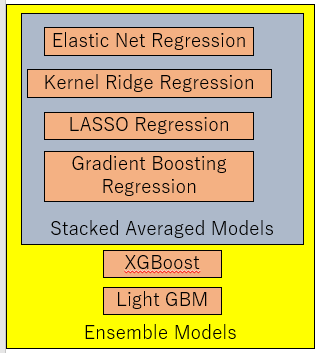
Elastic Net Regression、Kernel Ridge Regession、LASSO Regression、Gradient Boosting Regressionを組み合わせてStacked Averaged Modelとします。そして、それとXGBoostとLitht GBMを組み合わせることで最終的なEnsemble Modelsとします。
これら組み合わせの最適化については、私自身不明なところが多いので引き続き学んでまとめようと思います。
参考URL
https://blog.ikedaosushi.com/entry/2018/10/21/204842?t=0
Stacked Averaged Modelの作成
lasso = make_pipeline(RobustScaler(), Lasso(alpha =0.0005, random_state=1))
ENet = make_pipeline(RobustScaler(), ElasticNet(alpha=0.0005, l1_ratio=.9, random_state=3))
KRR = KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5)
GBoost = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05,
max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state =5)
まずは、LASSO regression、Elastic Net Regression、Kernel Ridge Regression、Gradient Boosting Regressionモデルのインスタンス化を行います。
次にモデルによるそれぞれのRMSLE値を算出します。
score = rmsle_cv(lasso)
print("\nLasso score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
score = rmsle_cv(ENet)
print("ElasticNet score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
score = rmsle_cv(KRR)
print("Kernel Ridge score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
score = rmsle_cv(GBoost)
print("Gradient Boosting score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
Lasso score: 0.1115 (0.0074)
ElasticNet score: 0.1116 (0.0074)
Kernel Ridge score: 0.1153 (0.0075)
Gradient Boosting score: 0.1177 (0.0080)
となりました。それではこれらモデルを集めたモデルを作ります。まずは単純に平均化します。
class AveragingModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, models):
self.models = models
# we define clones of the original models to fit the data in
def fit(self, X, y):
self.models_ = [clone(x) for x in self.models]
# Train cloned base models
for model in self.models_:
model.fit(X, y)
return self
#Now we do the predictions for cloned models and average them
def predict(self, X):
predictions = np.column_stack([
model.predict(X) for model in self.models_
])
return np.mean(predictions, axis=1)
averaged_models = AveragingModels(models = (ENet, GBoost, KRR, lasso))
score = rmsle_cv(averaged_models)
print(" Averaged base models score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
Averaged base models score: 0.1091 (0.0075)
単純に平均化したものだけでも値が良くなる(今回は小さいほうが良い)ことがわかります。
参考URL
https://blog.ikedaosushi.com/entry/2018/10/21/204842?t=0
class AveragingModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, models):
self.models = models
# we define clones of the original models to fit the data in
def fit(self, X, y):
self.models_ = [clone(x) for x in self.models]
# Train cloned base models
for model in self.models_:
model.fit(X, y)
return self
#Now we do the predictions for cloned models and average them
def predict(self, X):
predictions = np.column_stack([
model.predict(X) for model in self.models_
])
return np.mean(predictions, axis=1)
averaged_models = AveragingModels(models = (ENet, GBoost, KRR, lasso))
score = rmsle_cv(averaged_models)
print(" Averaged base models score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
Averaged base models score: 0.1091 (0.0075)
class StackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, base_models, meta_model, n_folds=5):
self.base_models = base_models
self.meta_model = meta_model
self.n_folds = n_folds
# We again fit the data on clones of the original models
def fit(self, X, y):
self.base_models_ = [list() for x in self.base_models]
self.meta_model_ = clone(self.meta_model)
kfold = KFold(n_splits=self.n_folds, shuffle=True, random_state=156)
# Train cloned base models then create out-of-fold predictions
# that are needed to train the cloned meta-model
out_of_fold_predictions = np.zeros((X.shape[0], len(self.base_models)))
for i, model in enumerate(self.base_models):
for train_index, holdout_index in kfold.split(X, y):
instance = clone(model)
self.base_models_[i].append(instance)
instance.fit(X[train_index], y[train_index])
y_pred = instance.predict(X[holdout_index])
out_of_fold_predictions[holdout_index, i] = y_pred
# Now train the cloned meta-model using the out-of-fold predictions as new feature
self.meta_model_.fit(out_of_fold_predictions, y)
return self
#Do the predictions of all base models on the test data and use the averaged predictions as
#meta-features for the final prediction which is done by the meta-model
def predict(self, X):
meta_features = np.column_stack([
np.column_stack([model.predict(X) for model in base_models]).mean(axis=1)
for base_models in self.base_models_ ])
return self.meta_model_.predict(meta_features)
stacked_averaged_models = StackingAveragedModels(base_models = (ENet, GBoost, KRR),
meta_model = lasso)
score = rmsle_cv(stacked_averaged_models)
print("Stacking Averaged models score: {:.4f} ({:.4f})".format(score.mean(), score.std()))
Stacking Averaged models score: 0.1085 (0.0074)
もう少し値が改善しました。
XGBoostモデルのインスタンス化
model_xgb = xgb.XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=1,
random_state =7, nthread = -1)
LightGBMモデルのインスタンス化
model_lgb = lgb.LGBMRegressor(objective='regression',num_leaves=5,
learning_rate=0.05, n_estimators=720,
max_bin = 55, bagging_fraction = 0.8,
bagging_freq = 5, feature_fraction = 0.2319,
feature_fraction_seed=9, bagging_seed=9,
min_data_in_leaf =6, min_sum_hessian_in_leaf = 11)
def rmsle(y, y_pred):
return np.sqrt(mean_squared_error(y, y_pred))
Stacking-Emsemble modelを作る
今回の学習モデルは、複数の学習モデルをアンサンブル学習として用います。これは、各学習モデルを重みづけ(係数掛け)したものを合算させたものです。
y_{prediction}=w_{1}∗XGB+w_{2}∗LGB+w_{3}∗StR\\
w_{1}+w_{2}+w_{3} = 1\\
\\
y_{prediction}:予測値\\
w_{1~3}:係数\\
XGB:XGBによる予測値\\
LGB:LightGBMによる予測値\\
StR:StackedRegressorによる予測値\\
print('RMSLE score on train data:')
print(rmsle(y_train,stacked_train_pred*0.70 +
xgb_train_pred*0.15 + lgb_train_pred*0.15 ))
ensemble = stacked_pred*0.70 + xgb_pred*0.15 + lgb_pred*0.15
RMSLE score on train data:
0.07530158653663023
非常に小さい値まで下がりました。
終わりに
今回、前半ではデータ前処理、後半では学習を行いました。
データ前処理に関しては、訓練データとテストデータを組み合わせた状態で欠損値やカテゴリー変数の取り扱いをすることがポイントであることが分かりました。特徴量を適切に扱うことがモデルの精度を決めるとても大事な手段です。
単純に欠損値を埋めるだけでなく、予想される因果関係に着目して取り組むことが大事であると感じました。
モデル学習については、スタッキングの考え方及びRMSLEの評価方法を学ぶことができました。最適なスタッキングを行うには、各モデルの特徴を深堀して理解する必要があります。
プログラム全文はこちらです。
https://github.com/Fumio-eisan/houseprice20200301