口上
『ゼロから作る Deep Learning ~ Python で学ぶディープラーニングの理論と実装』という本を買って深層学習の勉強をマターリしているのですが、
「そういえば情報検索や自然言語処理の実験でもよくやる交差検証 Cross Validation って意外に気にしてる人いないかも?」
と思ったので、自分でまとめることにしました。
もちろん、今までにも優秀な人達が記事を書いてくださっていますし(しかもググるとイパーイ出てくる)「もう知っているよ!」「やってるし!」っていう方は全く読む必要がないので、華麗にスルーして 1 回でも多く自分の学習のための Epoch を回した方がいいと思うのですが、もしお時間があって「よし粗探しでもしてやるか!」と思った奇特な方がいらっしゃったならばお読みいただいて、妙なところがあれば是非ご指摘・ご指導ください。
m(__)m
誰のための記事か?
- 「クロスバリデーションなんて聞いたことねーよ」「交差検証って何?それ美味しい?」っていう人
- 「交差検定じゃねーの?」って思う人
- 「検証データって何よ?」って思ったことがある人
- 雑に書かれた部分を見つけてそれを指摘することで日本語で書かれた情報系・技術系の記事レベル向上に貢献したい人
- 基本的には自分の備忘のため
誰のための記事ではないか?
- 機械学習のプロや専門家。初心者向けなのです。
- Python のプログラミングの深イイ話を読みたい人。プログラミング言語の学習の話ではないのです。
- 本や深層学習の解説記事だと思った人。説明のためにコードを使わせてもらっていますが、書きたいのは交差検証の話だけなのです。
- 交差検証の具体的な種類の話が読みたいと思った人。ここで言及されるのは交差検証のアイディアについての話なのです。手法の話が読みたい人は、Holdout Method, K-Fold Cross Validation, Stratified K-Fold Cross Validation あたりをググると幸せになれるかもです。
- MNIST が何であるかを知りたい人。データセットの内容に関してはこの記事では詳細なことは関知していないのです。
tl;dr
- ざっくり言うと、交差検証は比較的少ないデータセットを使って学習する場合に、過学習を防ぐ(汎化性能を上げる)ためにするものなのです。
- 統計学の用語的に
Validationの日本語訳は「検証」で、Testの日本語訳は「検定」を使うのです。 - データをすべて学習訓練に使っちゃダメ、絶対!なのです。
- この記事では主に k 分割交差検証について語ります。
- 例えば、データセット全体からテストデータを抜き、残りのデータを k で割って、一つは検証用、残りを訓練用に使うのです。
- k はむやみに増やすと大変かもなのです。
- テスト用データは訓練には絶対に使わないのです。
- テスト用データは訓練には絶対に使わないのです。大事なことなので二回書きました。
交差検証 (Cross Validation) とは
交差検証とは、Wikipedia の定義によれば、
統計学において標本データを分割し、その一部をまず解析して、残る部分でその解析のテストを行い、解析自身の妥当性の検証・確認に当てる手法
だそうなので、この記事でもその意味で使うことにします。
交差検証とは直接関係ないですが、機械学習は統計学的手法の塊なので、統計学はやっといて損はないです。
っていうか、やらないと私のように後で苦労することになります…
(;'∀')
統計学の用語的には「検定」ではなく「検証」
私も時々コダックのように混乱しますが、英語でいうところの Cross Validation の Validation は通常「検証」と訳し、「検定」というと統計学的には違う内容になってしまいます。
ここでいう検定とは「統計的仮説検定」のことで、(1)最初に仮説を立て(2)実際に起きたことを確率的に検証し(3)背理法を用いて結論を導き出す、ということを行います。大学の教養課程レベルの教科書には必ず書いてあるので、そちらをご参照ください。ググってもおK。
検証とは、統計学的には、立てた仮説と実験あるいは実際にある事象との間に「有意差があるかないか」を確認することです。詳しくは「検証」とか「バリデーション」あたりでググると幸せになれるかもしれません。
機械学習における交差検証というのは、得られたデータセットからランダムに抽出して作った K 個のグループに対して訓練・検証のデータを入れ替え差し替えしながら回して学習器を学習させ、学習によって得られたモデルを検証データを使ってさらにハイパーパラメータを決定したりということをします。
学会発表中に油断して「検定」と言ってしまい質問タイムに後ろから刺されないように、言葉遣いには気を付けましょう。
ビッグデータ初心者あるある
最初に大きいデータを扱うときによくあるのが、あまりのデータ量の多さとノイズの多さにテンション上がりすぎてヒャッハーって言ってるうちに、データを全部訓練用にぶっこむ…っていうようなことをすることです。
もちろん優秀かつ注意深い人はそんなことはしないのですが、教授の話をよく聞いてなかったり、不注意な学生によく起こるのです。
そして集めたデータを全て訓練用としてぶっこむと、「いざテスト!」という時に、教授に「追加で訓練データとは別のテスト用のデータを用意してね」と慈悲深い菩薩の笑みで宣告されるのです。オワタ...
学生のうちなら教授にどやされるだけで済みますが、どやされているうちに勉強しておくことが重要です。(そう、私のことです... orz)
交差検証する理由
ぶっちゃけ、交差検証なんて面倒なことをしなくてもいいんじゃね?みたいに思う人もいると思います。私もそうでしたし今も少し思ってる。しかし、次の理由で、比較的少ない件数のデータセットで機械学習をするときは、やっぱり交差検証は必要です。
- データセットを全部学習に使ってしまうと、その汎化性能が測定できない。
- 交差検証に限りませんが、訓練済みのデータセットをテストに使って大丈夫でしょうか?それってカンニングするようなもの、あるいは、すでに知ってる問題をもう一回解くようなものです。
- 学習・検証するデータ交差させないと、訓練された学習器が偏ってないとは言えない。
- たとえば、画像認識させるために集めたデータセットを分割して、たまたま猫多めの学習データブロックがあったとしましょう。猫多めのデータブロックで訓練させた学習器で猫と犬が認識できる学習器ができるでしょうか?猫好きには幸せな学習器が出来上がってモフり放題できるかもしれませんが、犬好きな人は猫多めのデータセットで訓練させた学習器では幸せになれないかもしれません1。
十分に大きいデータセットなら、テスト用のデータと訓練用のデータで分けちゃってもいいかもしれませんが、数万単位だったら交差検証やっといたほうがいいというのが私の理解です。ニューラルネットワーク (NN) の世界では計算コストが高くなるのであまり交差検証を使わないという話もあります。
この辺はどんなものを検証したいのかとか、マシンスペックやクラウドの予算依存になります。国立の研究所とか大企業の恵まれた環境をお持ちの方は100万件のデータであってもゴリゴリに交差検証させてもいいかもしれません。でもそんなことをしても無駄な予算と時間を使うだけかもしれないし、そんなときは普通に Hold-out でいい気もします。その辺は case-by-case でよさげな方を選択してください。
交差検証における訓練データ、検証データ、テストデータ
先ほどの項でもちらっと出ましたが、例えるなら、__訓練データ=過去問、検証データ=そっくり模試、テストデータ=本番入試__というのが近いかな~と自分では思っています2。
実際の入試では過去問が形を変えてでてくるということもありますが、それはよくあることですね。でも一字一句同じ問題が本番の入試で出てきたらそれは新聞沙汰になり炎上するケースと考えられるでしょう。同じ類のことが機械学習の時にも言えます。
というわけで、ざっくりとした言葉の意味は次の通りです。
訓練データ
一般的には、訓練データは学習器を訓練する場合に使います。学習データという場合もあります。重みやバイアスといったパラメータの学習に利用します。
検証データ
訓練済みの学習器をこれを使ってテストに利用します。これでハイパーパラメータを調整したりもします。機械学習で交差検証をするときに一番わかりづらいのがこれかも。
テストデータ
これはテスト用です。たとえ先生の机に無造作に置いてあっても絶対にカンニングしてはいけないデータです。汎化性能をチェックするために学習済みの学習器のために最後に利用します。
繰り返しになりますが、テストデータを学習器にぶち込んでやると、集めてきたデータ全体にフィットした正解率の高い学習器ができてしまいます。すると、訓練に使ったデータ__以外__が来る状態でその学習器を使うと大した性能がでない、ということになります。
交差検証を MNIST を使ってやってみよう
さて、じゃあ具体的にどうするのよ?という話ですが、ここではざっくり説明するために、みんな大好き MNIST というデータセットを使います3。MNIST とは NIST というアメリカの標準化のための研究機関が作った手書き数字のデータセットです。
データセットの構成については、日本語でもたくさん解説記事4が出ていますので、ここでは割愛します。
k 分割交差検証
交差検証にもいろんな種類がありますが、ここでは比較的単純な k 分割交差検証について見ていきます。
テストデータは訓練には使いません。自分で集めたデータセットを用いる場合は、最初からある一定の割合でデータセットから抜いておきましょう。訓練データとテストデータの割合については諸説ありますが、訓練データ 6: テストデータ 4 という人もいれば訓練データ 8: テストデータ 2 という人もいます。
k の値は、基本的に分割してしまうと 1 ブロック内のデータの件数が少なくなってしまうので、データセット全体の件数によってどのくらいの割合にするかは適宜考えた方が良さそうです。
ただ試したいだけなら適当に決めてもいいのですが、論文を書く人は、それなりの裏付けのある割合(同じような分野の論文で採用されているデータ件数とか分割数とか)を選択するのが後ろ指をさされないある一つの良い方法ですw
図で説明
文字ばかりだとイメージがつかみにくいので、図で説明します。
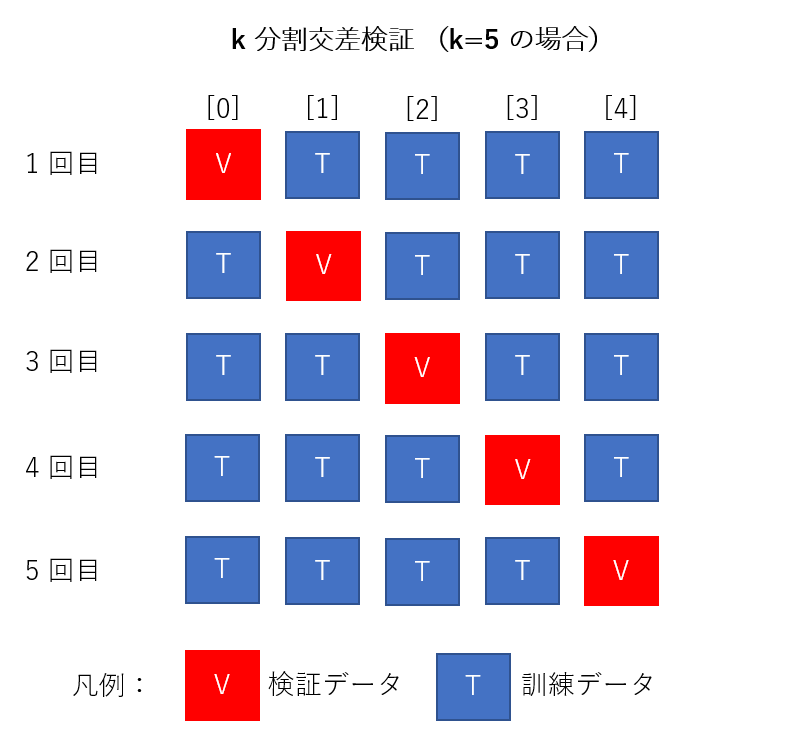
必ずしもこの順番で実行されるというわけではないですが、仮にこのような分け方になったとして、5個あるデータブロックのうち、1個を検証用データ、その他を訓練データとして使います。データブロック1個ずつ学習器に対して訓練を行い、それを k-1 = 4 個分行います。
訓練の終わりには必ず別にしておいた検証用データを用いて検証を行います。
これを繰り返し、必ず分割されたデータブロックが1回ずつ検証用データとして使われるようにするのがミソです。
サンプルコード
TensorFlow (TF) を使ってやってみたかったので TF のプログラムになります。TF には残念ながら交差検証のクラスがないので、scikit-learn の cross validation を使います。
ちょうど StackOverflow に__参考になるコード__があったので、そこから交差検証のための設定を行っている部分を抜き書きしてみます。
from sklearn.model_selection import KFold
# (snip)
def cross_validate(session, split_size=5):
results = []
kf = KFold(n_splits=split_size)
for train_idx, val_idx in kf.split(train_x_all, train_y_all):
train_x = train_x_all[train_idx]
train_y = train_y_all[train_idx]
val_x = train_x_all[val_idx]
val_y = train_y_all[val_idx]
run_train(session, train_x, train_y)
results.append(session.run(accuracy, feed_dict={x: val_x, y: val_y}))
return results
# (snip)
KFold で k = 5 分割に設定し、 kf.split で訓練データと検証データに分け、ここには引用していない run_train() で訓練データを使って訓練しています。 k の値は split_size で設定しています。train_idx, val_idx はその時に選択する訓練データと検証データのインデックスになります。kf.split がその辺を良しなにやってくれる仕組みです。
k の値はデータを余すことなく使えるキリのいい数字であれば美しいと思いますが、小さすぎると十分な交差ができないかもしれませんし、大きすぎると学習する単位が多くて大変かもしれないのでご注意ください。
テストデータはコードの最後の方でこんな感じで使っています。
with tf.Session() as session:
result = cross_validate(session)
print "Cross-validation result: %s" % result
print "Test accuracy: %f" % session.run(accuracy, feed_dict={x: test_x, y: test_y}) #<- ここ
動かしてみる
Google CoLab を使って動かしてみます。リンク先は閲覧のみになっているので、適宜コピーするなりして Google CoLab やご自身のローカル環境で動かしてみてください。
Epoch = 100 で回してみるとこんな感じになります。
Cross-validation result: [0.896, 0.904, 0.8923636, 0.8980909, 0.9087273]
Test accuracy: 0.909900
この場合は、交差検証した値よりはテストの値が若干よくなっている感じです。
__StackOverflow にあったコード__は Epoch = 10 で平均 0.8 台の accuracy だったので Epoch 数を上げればそれなりに上がるようです。しかし、99% 以上にしたい場合は、Epoch 数を増やす以外の工夫が必要と思われます。
ここで説明したかったのは「交差検証ってどうやるの?」という話なのでこれ以上は踏み込みませんが、いろいろやりようはあるので、時間がある人は試してみてはいかがでしょうか。
おわりに
交差検証っていうのはそんなに難しいアイディアではないですが、やっとかないと後で怒られる類の話ですので、機械学習でデータが少なめかな?と思うときは是非やっておきましょう。
交差検証は機械学習に限らず情報検索や自然言語処理の実験でもよくつかわれる手法です。検索エンジンでも翻訳エンジンでも、データを扱う「なにか」の性能を統計的に検証したい場合は使うので覚えておいて損はないでしょう。
間違いやほかに良い方法ある場合は遠慮なく突っ込んでください(^^;
最後まで目を通していただいて感謝ですm(__)m
2019-11-17 追記
交差検証(cross validation/クロスバリデーション)の種類を整理してみた
という記事に交差検証の種類がまとめられていたので、興味のある方、どの交差検証を使うかお悩みの方は覗いてみるといいかもしれません。
-
余談ですが、画像認識の世界には__「チワワ・マフィン問題」__というのもあります。最初にこの問題を提起した人はスゴイなと思いますw ↩
-
同様のことが書いてあるWebページもたくさんあるので、自分の理解もそんなに大きく乖離はしてないかなと。例えば__このページ__ ↩
-
例えばこの記事 => MNIST データの仕様を理解しよう ↩