はじめに
前回に引き続きnetkeiba.comからの競馬データを使って予想プログラムを作っています。予想プログラムを作ることより、スクレイピングの内容が学べましたので備忘でまとめます。
Pandasを使って競馬のデータベースを取得してみた
https://qiita.com/Fumio-eisan/items/1c1c429746a3a0add055
競馬予想プログラム自体はこちらの方の動画を御覧ください。非常に丁寧に解説されており、初学者でも十分に理解することができます。
競馬予想で始めるデータ分析・機械学習
https://www.youtube.com/channel/UCDzwXAWu1zIfJuPTTZyWthw
javascriptで書かれている場所のスクレイピング(Selenimum活用)
htmlから出走表や馬名、騎手などの情報を取る際にpandasを活用して取得できることは前回まとめました。これだけでは十分でない場合があります。javascriptで記述されている部分に関しては、スクレイピングに一手間掛ける必要があります。
Seleniumとは
SeleniumとはWebブラウザの操作を自動化するためのフレームワークになります。ChromeでもFireFoxでも、IEなどでも使えるようです。今回はChromeを使います。
こちらでお使いのChromeバージョンのseleniumをダウンロードください。
from selenium.webdriver import Chrome, ChromeOptions
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
URLを開く
単純にURLを開く方法は下記です。
options= ChromeOptions()
driver = Chrome(executable_path=r'(chromedriver.exe)のパスを指定下さい',options=options)
driver.get(url)
ここではchoromedriverのpathを入れています。システム環境設定にてchoromedriverのpathを指定すればこのプログラム上での記述は要らないようなのですが、設定しても動作しませんでした。従い、わざわざexecutable_pathを指定しています。
出走情報を取るクラス定義
以下に出走情報をスクレイピングするクラスを定義します。pandasのデータフレームに入れてやります。
from tqdm import tqdm_notebook as tqdm
import pandas as pd
import time
class ShutubaTable:
def __init__(self):
self.shutuba_table = pd.DataFrame()
def scrape_shutuba_table(self, race_id_list):
options= ChromeOptions()
driver = Chrome(executable_path=r'C:\Users\lllni\Documents\Python\20200528_keiba\chromedriver_win32\chromedriver.exe',options=options)
for race_id in tqdm(race_id_list):
url = 'https://race.netkeiba.com/race/shutuba.html?race_id=' + race_id
driver.get(url)
elements = sample_driver.find_elements_by_class_name('HorseList')
for element in elements:
tds = element.find_elements_by_tag_name('td')
row = []
for td in tds:
row.append(td.text)
if td.get_attribute('class') in ['HorseInfo', 'Jockey']:
href = td.find_element_by_tag_name('a').get_attribute('href')
row.append(re.findall(r'\d+', href)[0])
self.shutuba_table = self.shutuba_table.append(pd.Series(row, name=race_id))
time.sleep(1)
driver.close()
ポイントとして、
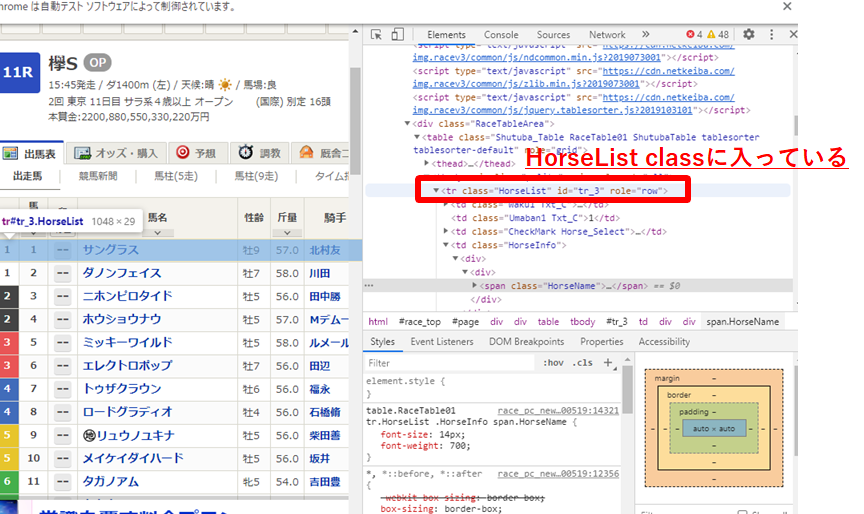
- 'HorseList`classにほしいデータが入っているので以下のように取り出す。
elements = sample_driver.find_elements_by_class_name('HorseList')
2)tdタグごとに馬名、オッズなどそれぞれの情報を取り出す。
for element in elements:
tds = element.find_elements_by_tag_name('td')
row = []
for td in tds:
row.append(td.text)
self.shutuba_table = self.shutuba_table.append(pd.Series(row, name=race_id))
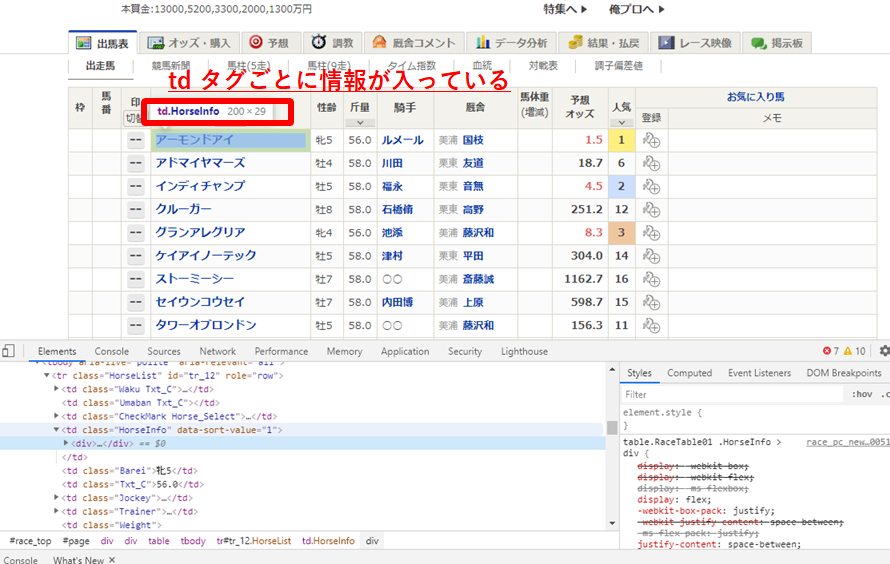
このtdタグをそれぞれ記載することでjavascriptで記載された情報も取り出すことができます。また、elementは馬ごととなっています。つまり、馬が変わるごとにrowは空になってtdタグの情報がまた一から入れることができるのです。
インスタンス化して読み込む
st = ShutubaTable1()
sample_driver = Chrome(executable_path=r'C:\Users\lllni\Documents\Python\20200528_keiba\chromedriver_win32\chromedriver.exe',options=options)
sample_driver.get(url
st.scrape_shutuba_table(['202005030211'])#予想したいrace_idを入れる
st.shutuba_table
レースidはnetkeiba.comであれば出走表のURLの末尾に数値が入っていますので、見たいレースidの数値だけ取り出して貼ってください。
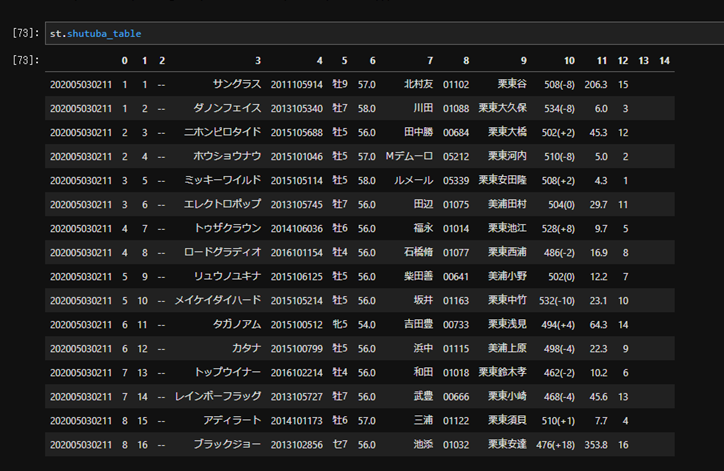
無事に取り出すことができました。
終わりに
スクレイピングについてまた一つ理解が深まりました。