あらすじ
以前、海外旅行中、子猫を抱えた現地の人に英語で話しかけられた時の話。
外国の人「How to say "kitchen" in Japanese ?」
自分「(?? なんでいきなりそんなこと聞くんだろう…)DAIDOKORO」
外国の人「?? … ? What?」
自分「DAIDOKORO !」
外国の人「…Oh, DAIDOKORO! OK! DAIDOKORO!」
後日
自分「こうゆうことがあってさ。なんであんなこと聞いてきたんだろうな」
友達「それ、kitchenじゃなくてkittenって言ったんじゃない?
子猫抱えてたんでしょ?」
自分「ああそっか、kittenか!子猫のことね!
kitchenと発音が似てるから間違えてしまったよ!hahaha」
自分・友達「…」
自分「英語、勉強しよう…」
作りたいもの
発音が似ている2つの単語を画面上に表示し、
どちらかの音声ファイルをランダムで再生する。
発音されたとユーザーが判断した方の単語を選択し、
正解もしくは不正解を画面上に表示する。
また、発音記号が似ている様々な単語のペアは
発音記号ごとにまとめ、どの発音記号の聞き分けに
挑むか、ユーザーが選択できるようにする。
例えば、私も含め多くの人が悩む'r'と'l'の違いを
学習するとする。
ゲームを開始すると、例えばlightかrightのどちらの音声が
ランダムで再生がされ、再生されたと思う方を選択する。
すると、正解 or 不正解が表示されるようにする。
因みに下記のように、lightとrightという単語は、最初の
発音記号がlとrという以外、全く同じである。
| 単語 | 発音記号 |
|---|---|
| light | lάɪt |
| right | rάɪt |
開発環境
- PC:windows10
- 言語 :python 3.7.3
- IDE :pycharm
- GUI :Tkinter
- 英単語情報の格納:json
また、本ツールで使用する英語単語の音声ファイルはweblio様からダウンロードさせて
いただくが、多くの英単語のファイルを1つずつダウンロードするのは非常に手間が
かかる。
そこで、webスクレイピングで英単語を自動でダウンロードするツールを作った。↓
https://qiita.com/Fuminori_Souma/private/60ce627e66209763d4f2
このツールを使用すれば、欲しい音声ファイルが簡単にダウンロードできる。
ただし本ツールのjsonファイルに記載している単語の音声ファイルはGoogle driveにて公開(後述)
実際に作ったもの
実行直後の画面はこんな感じ。
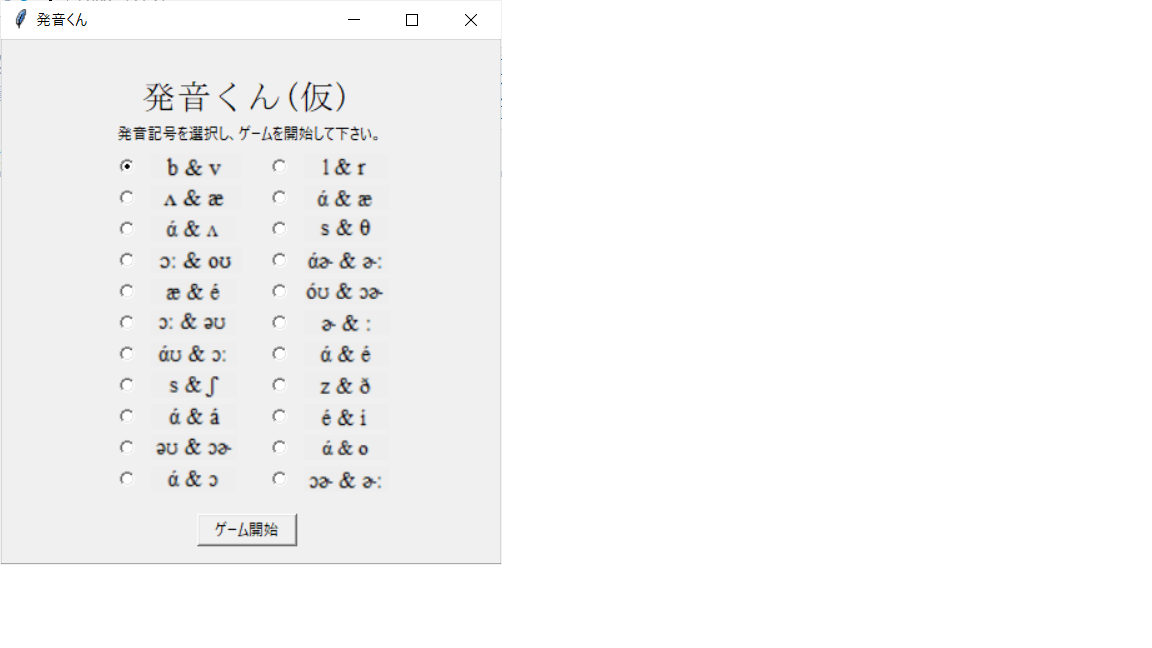
今日はこれまた日本人が苦手とする、's'と'th'の聞き分けに挑戦するぞ。
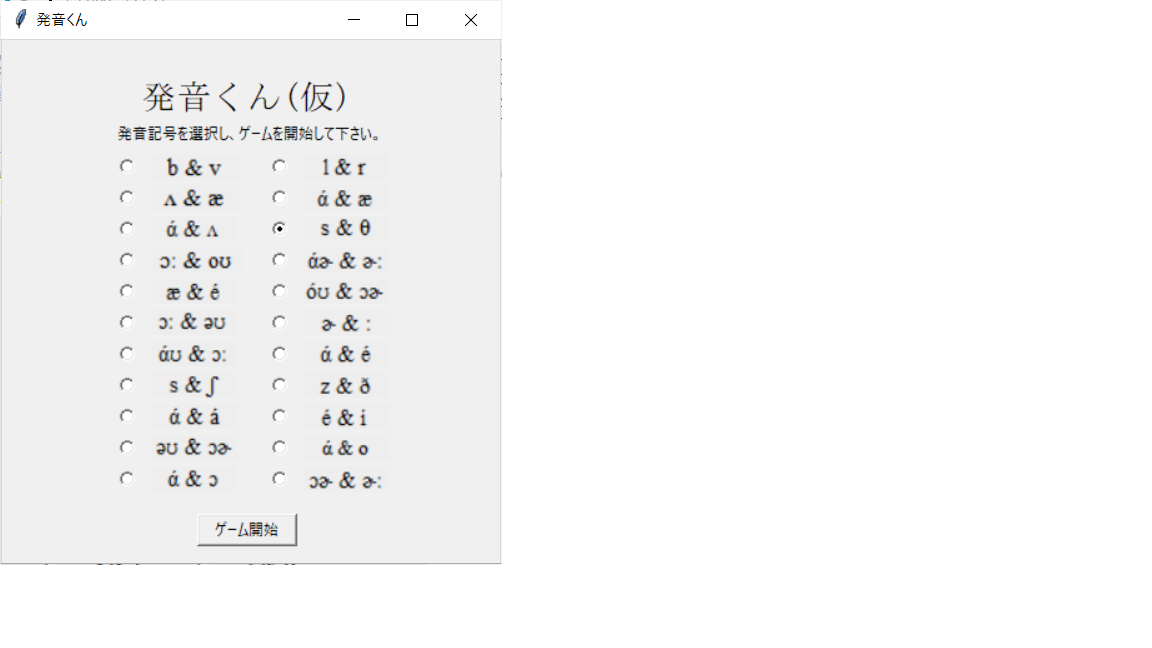
「ゲーム開始」ボタンを押すと、ゲーム画面に変化。問題は全部で14問か。
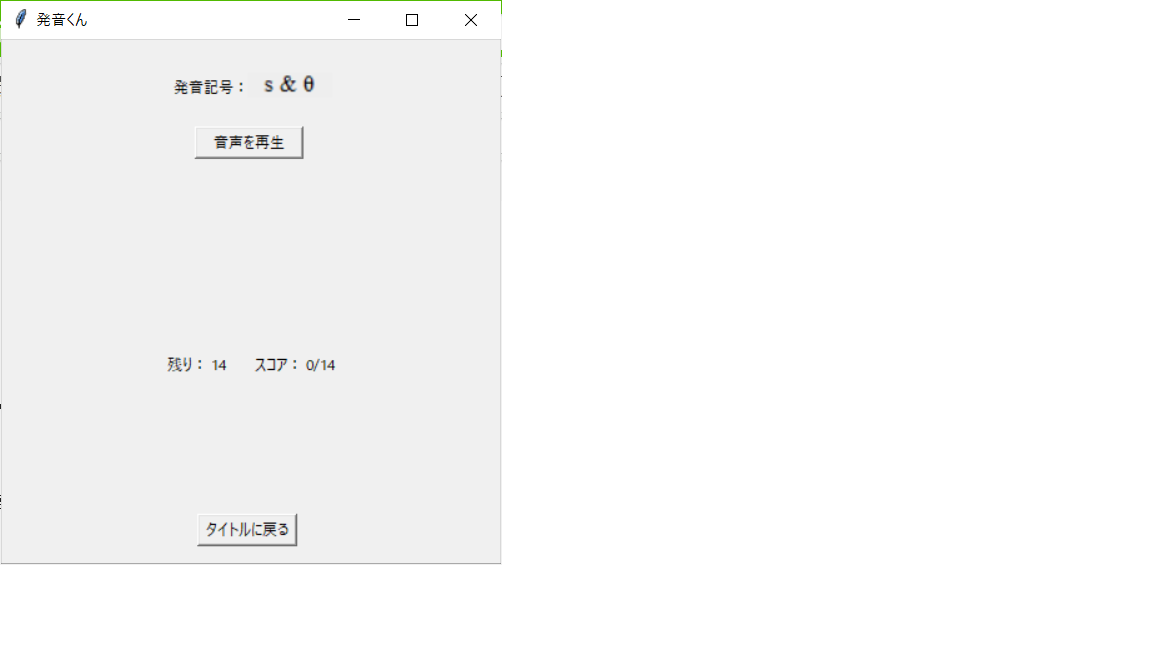
さっそく「音声を再生」ボタンを押すと、音声ファイルが再生され、選択肢が2つ出てきた。
むっ、どっちが発音されたのかな。。「もう一度再生」ボタンを押して、もう一回聞いてみよう。
分かった、左のtenseだ!「tense」テキストをクリックして回答しよう。
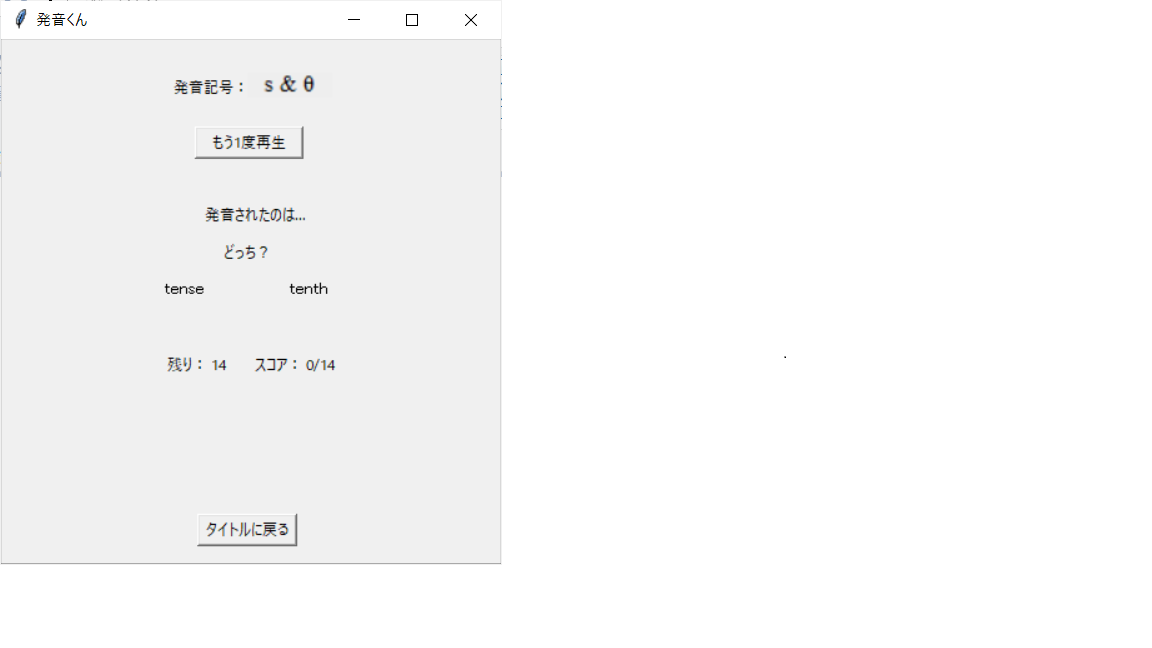
見事正解!やったね。「tense」と「tenth」をクリックして再生し、それぞれの
音声の違いを確認しておこう。
それが終わったら「次の問題を開始」ボタンを押そう。
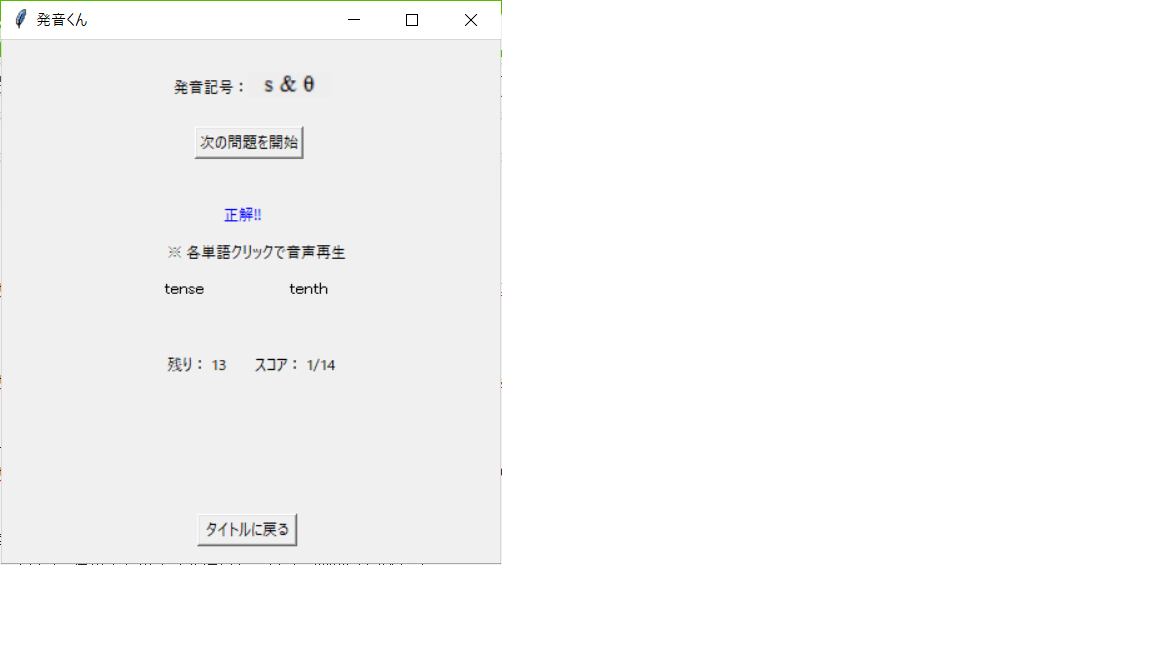
今度は「mouse」と「mouth」か。分かった、mouthだ!
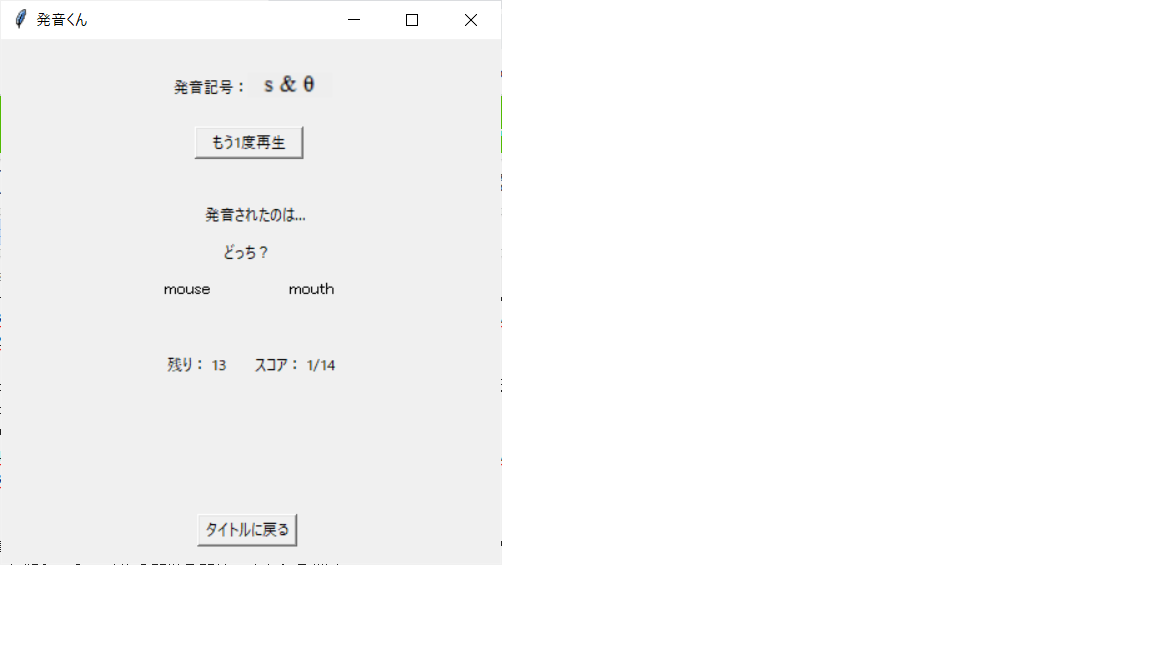
…違うじゃないか。畜生!
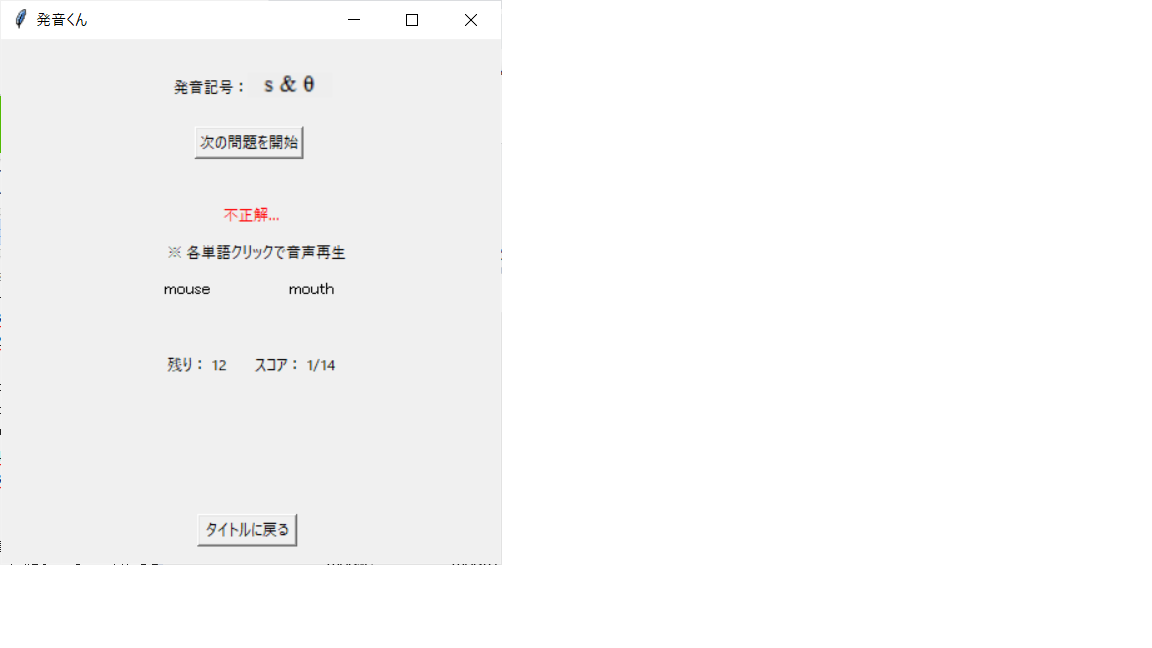
…全部終わったぞ。14問中7問正解か。ま、まあまあだな(汗)
「タイトルに戻る」ボタンを押そう。
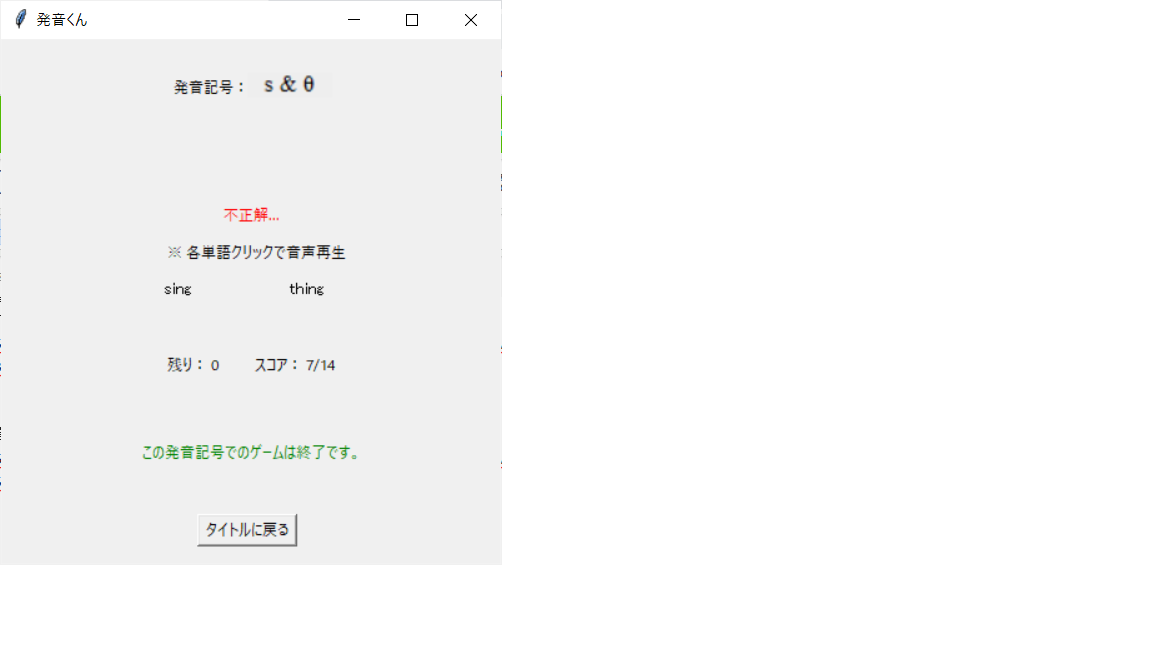
じゃあ次は'b'と'v'の聞き分けに挑戦してみようか。
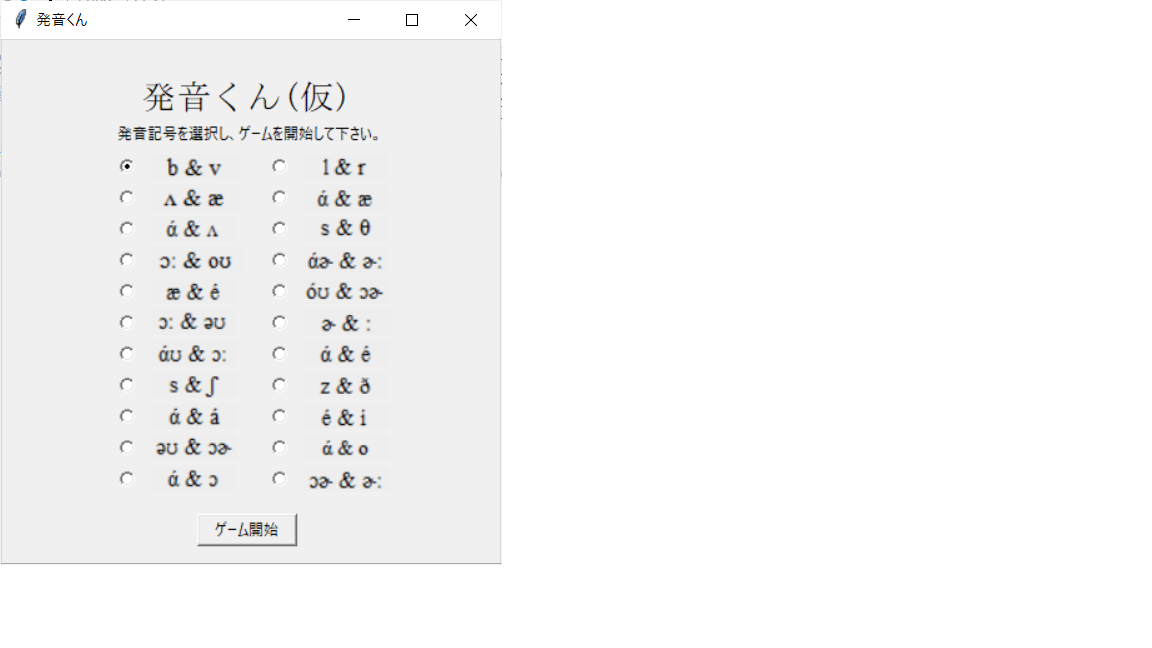
こんな感じで使用します。
ソースファイル
import sys
import tkinter
from tkinter import messagebox
from mutagen.mp3 import MP3 as mp3
from tkinter import *
import pygame
import time
import json
import random
from PIL import Image, ImageTk
def ques_start_next(event): # 問題を開始/もう一度音声を再生/次の問題を開始
if bttn_repnxt['text'] == '音声を再生':
global word1
global word2
global rep_word # 実際に発音された単語
global id
text_res["text"] = '' # 前回の問題への答えをリセット
group = ps
words = random.choice(list(wordlist['Wordlist'][group]))
id = 'id' + str(quorder[qunum - renum])
word1 = (wordlist['Wordlist'][group][id]['word1'])
word2 = (wordlist['Wordlist'][group][id]['word2'])
rep_word = wordlist['Wordlist'][group][id][random.choice(list(wordlist['Wordlist'][group][words]))]
rep_mp3(rep_word) # 音声ファイルを再生
# オブジェクト状態の変更
text_w1["text"] = word1
text_w2["text"] = word2
text_ques1["text"] = '発音されたのは…'
text_ques2["text"] = 'どっち?'
bttn_repnxt['text'] = 'もう1度再生'
text_adc.place_forget()
elif bttn_repnxt['text'] == 'もう1度再生':
rep_mp3(rep_word) # 音声ファイルを再生
else: # '次の問題を開始'
# オブジェクト状態を変更
bttn_repnxt['text'] = '音声を再生'
text_res.place_forget()
# 次の問題を開始 (音声ファイルを再生)
ques_start_next(event)
def rep_mp3(tgt_word): # 音声を再生
filename = 'C:/Users/fumin/OneDrive/デスクトップ/English_words/' + tgt_word + '.mp3' # 再生したいmp3ファイル
pygame.mixer.init()
pygame.mixer.music.load(filename) # 音源を読み込み
mp3_length = mp3(filename).info.length # 音源の長さ取得
pygame.mixer.music.play(1) # 再生開始。1の部分を変えるとn回再生(その場合は次の行の秒数も×nすること)
time.sleep(mp3_length + 0.25) # 再生開始後、音源の長さだけ待つ(0.25待つのは誤差解消)
pygame.mixer.music.stop() # 音源の長さ待ったら再生停止
def enlarge_word(event): # マウスポインタを置いたwordを大きく表示
if str(event.widget["text"]) == word1:
text_w1["font"] = ("", 12) # 文字を大きく表示
text_w1["cursor"] = "hand2" # マウスポインタを人差し指型に変更
else:
text_w2["font"] = ("", 12) # 文字を大きく表示
text_w2["cursor"] = "hand2" # マウスポインタを人差し指型に変更
def undo_word(event): # マウスポインタから外れたwordを元のサイズに戻す
if str(event.widget["text"]) == word1:
text_w1["font"] = ("", 10) # 文字を最初のサイズで表示
else:
text_w2["font"] = ("", 10) # 文字を最初のサイズで表示
def choose_word(event): # ユーザが選択したwordが正解かどうか判定
global oknum
global renum
if bttn_repnxt['text'] == 'もう1度再生':
# 正解と注意書きを表示
text_res.place(x=175, y=130)
text_adc.place(x=130, y=160)
if str(event.widget["text"]) == word1: # 左側の単語を選択した場合
if rep_word == word1:
text_res["text"] = '正解!!'
else:
text_res["text"] = '不正解…'
else: # 右側の単語を選択した場合
if rep_word == word2:
text_res["text"] = '正解!!'
else:
text_res["text"] = '不正解…'
if text_res["text"] == '正解!!':
oknum = oknum + 1 # 正解数を加算
text_res["foreground"] = 'blue'
else:
text_res["foreground"] = 'red'
renum -= 1 # 残りの問題数を減算
# オブジェクト状態を変更
text_scr['text'] = 'スコア: ' + str(oknum) + '/' + str(qunum)
text_rest['text'] = '残り: ' + str(renum)
text_ques1["text"] = ''
text_ques2["text"] = ''
bttn_repnxt["text"] = '次の問題を開始'
if renum == 0: # 全問題が終わった場合
bttn_repnxt.place_forget()
text_end.place(x=110, y=320)
elif bttn_repnxt['text'] == '次の問題を開始': # 次の問題の音声を再生
if str(event.widget["text"]) == word1:
rep_mp3(wordlist['Wordlist'][ps][id]['word1'])
else:
rep_mp3(wordlist['Wordlist'][ps][id]['word2'])
def create_radioboutton(row, column, pdx, num, value): # タイトル画面のラジオボタンを生成
rdbtn[num] = tkinter.Radiobutton(frame, value=value, command=rb_clicked, variable=var, text=u'')
rdbtn[num].grid(row=row, column=column, padx=0, ipadx=pdx, pady=yinvl)
def create_picture(row='df', column='df', pdx='df', num='df'): # タイトル画面の発音記号(画像)を生成
if row == 'df' and column == 'df'and pdx == 'df'and num == 'df': # タイトル画面の場合
cv[rbnum] = Canvas(width=70, height=20)
cv[rbnum].create_image(1, 1, image=pngfile[rbnum], anchor=NW)
cv[rbnum].place(x=195, y=25)
else: # ゲーム開始画面の場合
cv[num] = Canvas(frame, width=70, height=20)
cv[num].create_image(1, 1, image=pngfile[num], anchor=NW)
cv[num].grid(row=row, column=column, ipadx=pdx, pady=yinvl)
def rb_clicked(): # 勉強する発音記号を選択
global rbnum
global ps
rbnum = int(var.get()) # 選択したラジオボタン(=発音記号)の番号を格納
ps = list(wordlist['Wordlist'])[rbnum] # 選択した発音記号を選択
def switch_mode(event): # ゲームを開始 / タイトル画面に戻る
global qunum # 全問題の数
global oknum # 正解した問題の数
global renum # 残りの問題の数
global quorder # 問題出題の順番
if bttn_swmode['text'] == 'ゲーム開始':
# 最初の画面にあったオブジェクトを非表示
frame.place_forget()
text_title.place_forget()
text_ques3.place_forget()
# ゲーム用のオブジェクトを表示
bttn_repnxt.place(x=155, y=70)
text_scr.place(x=200, y=250)
text_rest.place(x=130, y=250)
text_w1.place(x=128, y=190)
text_w2.place(x=228, y=190)
text_ps.place(x=135, y=28)
text_ques1.place(x=160, y=130)
text_ques2.place(x=175, y=160)
create_picture()
# 各種設定
oknum = 0
qunum = len(wordlist['Wordlist'][ps])
renum = qunum
text_scr['text'] = 'スコア: ' + str(oknum) + '/' + str(qunum)
text_rest['text'] = '残り: ' + str(renum)
quorder = random.sample(range(1, qunum + 1), k=qunum)
bttn_swmode['text'] = 'タイトルに戻る'
text_w1["text"] = ''
text_w2["text"] = ''
text_ques1["text"] = ''
text_ques2["text"] = ''
bttn_repnxt['text'] = '音声を再生'
else: # タイトル画面に戻る
if renum == 0 or (renum != 0 and messagebox.askyesno('確認', 'まだ問題が残っています。タイトル画面に戻りますか?')):
# if messagebox.askyesno('確認', 'まだ問題が残っています。タイトル画面に戻りますか?'):
# ゲーム画面にあったオブジェクトを非表示
bttn_repnxt.place_forget()
text_scr.place_forget()
text_rest.place_forget()
text_w1.place_forget()
text_w2.place_forget()
text_ps.place_forget()
text_ques1.place_forget()
text_ques2.place_forget()
text_end.place_forget()
text_res.place_forget()
text_adc.place_forget()
cv[rbnum].place_forget()
# タイトル画面用のオブジェクトを表示
frame.place(x=90, y=90)
text_title.place(x=110, y=30)
text_ques3.place(x=90, y=65)
bttn_swmode['text'] = 'ゲーム開始'
# 画面の表示
root = tkinter.Tk()
root.title(u"発音くん")
root.geometry("400x420")
root.columnconfigure(0, weight=1)
root.rowconfigure(0, weight=1)
# Frame
frame = tkinter.Frame(root)
frame.place(x=90, y=90)
frame.columnconfigure(0, weight=1)
frame.rowconfigure(0, weight=1)
# ラベルの設定
text_w1 = tkinter.Label(text=u'', font=("", 10))
text_w1.bind("<Enter>", enlarge_word)
text_w1.bind("<Leave>", undo_word)
text_w1.bind("<Button-1>", choose_word)
text_w2 = tkinter.Label(text=u'', font=("", 10))
text_w2.bind("<Enter>", enlarge_word)
text_w2.bind("<Leave>", undo_word)
text_w2.bind("<Button-1>", choose_word)
text_ques1 = tkinter.Label(text=u'')
text_ques2 = tkinter.Label(text=u'')
text_ques3 = tkinter.Label(text=u'発音記号を選択し、ゲームを開始して下さい。')
text_ques3.place(x=90, y=65)
text_ps = tkinter.Label(text=u'発音記号:')
text_adc = tkinter.Label(text=u'※ 各単語クリックで音声再生')
text_res = tkinter.Label(text=u'')
text_scr = tkinter.Label(text=u'')
text_rest = tkinter.Label(text=u'')
text_title = tkinter.Label(text=u'発音くん(仮)', font=(u'MS 明朝', 20))
text_title.place(x=110, y=30)
text_end = tkinter.Label(text=u'この発音記号でのゲームは終了です。')
text_end["foreground"] = 'green'
# プッシュボタンの設定
bttn_repnxt = tkinter.Button(text=u'音声を再生', width=11)
bttn_repnxt.bind("<Button-1>", ques_start_next) # (Button-2でホイールクリック、3で右クリック)
bttn_swmode = tkinter.Button(text=u'ゲーム開始', width=10)
bttn_swmode.bind("<Button-1>", switch_mode) # (Button-2でホイールクリック、3で右クリック)
bttn_swmode.place(x=157, y=380)
# ラジオボタンの配置に使用するパラメータの設定
xinvl = 30
yinvl = 0
var = StringVar()
var.set('0') # ラジオボタンを「チェックしていない状態」に設定
f = open("C:/Users/fumin/OneDrive/デスクトップ/Wordlist.json", 'r')
wordlist = json.load(f)
oknum = 0
rb_clicked() # 初期状態で選択しているラジオボタン
# 画像情報及びラジオボタン情報を格納する変数の初期化
pngfile = [''] * len(wordlist['Wordlist'])
cv = [''] * len(wordlist['Wordlist'])
rdbtn = [''] * len(wordlist['Wordlist'])
# ラジオボタン/発音記号の設定
for i in range(int(len(wordlist['Wordlist'])/2)):
ipadx = 10
pngfile[i*2] = PhotoImage(file="C:/Users/fumin/OneDrive/画像/" + list(wordlist['Wordlist'])[i * 2] + ".PNG")
pngfile[i*2+1] = PhotoImage(file="C:/Users/fumin/OneDrive/画像/" + list(wordlist['Wordlist'])[i * 2 + 1] + ".PNG")
create_radioboutton(i+1, 1, 0, i*2, i*2)
create_picture(i+1, 2, ipadx, i*2)
create_radioboutton(i+1, 3, 0, i*2+1, i*2+1)
create_picture(i+1, 4, ipadx, i*2+1)
root.mainloop()
英単語情報格納ファイル
{
"Wordlist": {
"b_v" : {
"id1" : {
"word1": "boat",
"word2": "vote"
},
"id2" : {
"word1": "bury",
"word2": "vary"
},
"id3" : {
"word1": "base",
"word2": "vase"
},
"id4" : {
"word1": "bent",
"word2": "vent"
},
"id5" : {
"word1": "ban",
"word2": "van"
},
"id6" : {
"word1": "best",
"word2": "vest"
},
"id7" : {
"word1": "bat",
"word2": "vat"
}
},
"l_r" : {
"id1" : {
"word1": "light",
"word2": "right"
},
"id2" : {
"word1": "lice",
"word2": "rice"
},
"id3" : {
"word1": "long",
"word2": "wrong"
},
"id4" : {
"word1": "lock",
"word2": "rock"
},
"id5" : {
"word1": "lane",
"word2": "rain"
},
"id6" : {
"word1": "lend",
"word2": "rend"
},
"id7" : {
"word1": "lead",
"word2": "read"
},
"id8" : {
"word1": "loom",
"word2": "room"
},
"id9" : {
"word1": "lace",
"word2": "race"
},
"id10" : {
"word1": "lack",
"word2": "rack"
},
"id11" : {
"word1": "lake",
"word2": "rake"
},
"id12" : {
"word1": "lamp",
"word2": "ramp"
},
"id13" : {
"word1": "lank",
"word2": "rank"
},
"id14" : {
"word1": "late",
"word2": "rate"
},
"id15" : {
"word1": "law",
"word2": "raw"
},
"id16" : {
"word1": "clown",
"word2": "crown"
},
"id17" : {
"word1": "folk",
"word2": "fork"
},
"id18" : {
"word1": "glamour",
"word2": "grammar"
},
"id19" : {
"word1": "flee",
"word2": "free"
},
"id20" : {
"word1": "allow",
"word2": "arrow"
},
"id21" : {
"word1": "belly",
"word2": "berry"
},
"id22" : {
"word1": "blanch",
"word2": "branch"
},
"id23" : {
"word1": "bland",
"word2": "brand"
},
"id24" : {
"word1": "bravely",
"word2": "bravery"
},
"id25" : {
"word1": "bleach",
"word2": "breach"
},
"id26" : {
"word1": "bleed",
"word2": "breed"
},
"id27" : {
"word1": "blink",
"word2": "brink"
},
"id28" : {
"word1": "bully",
"word2": "burly"
},
"id29" : {
"word1": "collect",
"word2": "correct"
},
"id30" : {
"word1": "flesh",
"word2": "fresh"
}
},
"crt_ash" : {
"id1" : {
"word1": "bug",
"word2": "bag"
},
"id2" : {
"word1": "fun",
"word2": "fam"
},
"id3" : {
"word1": "tusk",
"word2": "task"
},
"id4" : {
"word1": "much",
"word2": "match"
},
"id5" : {
"word1": "buck",
"word2": "back"
},
"id6" : {
"word1": "crush",
"word2": "crash"
},
"id7" : {
"word1": "suck",
"word2": "sack"
},
"id8" : {
"word1": "stuff",
"word2": "staff"
},
"id9" : {
"word1": "mud",
"word2": "mad"
},
"id10" : {
"word1": "musk",
"word2": "mask"
},
"id11" : {
"word1": "lump",
"word2": "lamp"
},
"id12" : {
"word1": "bung",
"word2": "bang"
},
"id13" : {
"word1": "hut",
"word2": "hat"
},
"id14" : {
"word1": "rump",
"word2": "ramp"
},
"id15" : {
"word1": "uncle",
"word2": "ankle"
},
"id16" : {
"word1": "muster",
"word2": "master"
},
"id17" : {
"word1": "bund",
"word2": "band"
},
"id18" : {
"word1": "puppy",
"word2": "pappy"
},
"id19" : {
"word1": "double",
"word2": "dabble"
},
"id20" : {
"word1": "hunk",
"word2": "hank"
},
"id21" : {
"word1": "stunned",
"word2": "stand"
}
},
"ash_alfa" : {
"id1" : {
"word1": "pappy",
"word2": "poppy"
},
"id2" : {
"word1": "adapt",
"word2": "adopt"
},
"id3" : {
"word1": "bag",
"word2": "bog"
},
"id4" : {
"word1": "back",
"word2": "bock"
},
"id5" : {
"word1": "sack",
"word2": "sock"
},
"id6" : {
"word1": "mask",
"word2": "mosque"
},
"id7" : {
"word1": "hat",
"word2": "hot"
},
"id8" : {
"word1": "ramp",
"word2": "romp"
},
"id9" : {
"word1": "band",
"word2": "bond"
},
"id10" : {
"word1": "possible",
"word2": "passable"
},
"id11" : {
"word1": "sad",
"word2": "sod"
},
"id12" : {
"word1": "tap",
"word2": "top"
},
"id13" : {
"word1": "nat",
"word2": "not"
},
"id14" : {
"word1": "hank",
"word2": "honk"
},
"id15" : {
"word1": "bax",
"word2": "box"
},
"id16" : {
"word1": "valley",
"word2": "volley"
},
"id17" : {
"word1": "sax",
"word2": "sox"
}
},
"alfa_crt" : {
"id1" : {
"word1": "body",
"word2": "buddy"
},
"id2" : {
"word1": "wander",
"word2": "wonder"
},
"id3" : {
"word1": "soccer",
"word2": "sucker"
},
"id4" : {
"word1": "poppy",
"word2": "puppy"
},
"id5" : {
"word1": "bond",
"word2": "bund"
},
"id6" : {
"word1": "romp",
"word2": "rump"
},
"id7" : {
"word1": "hot",
"word2": "hut"
},
"id8" : {
"word1": "mosque",
"word2": "musk"
},
"id9" : {
"word1": "sock",
"word2": "suck"
},
"id10" : {
"word1": "bock",
"word2": "buck"
},
"id11" : {
"word1": "bog",
"word2": "bug"
},
"id12" : {
"word1": "collar",
"word2": "color"
},
"id13" : {
"word1": "rob",
"word2": "rub"
},
"id14" : {
"word1": "honk",
"word2": "hunk"
},
"id15" : {
"word1": "calm",
"word2": "come"
},
"id16" : {
"word1": "coddle",
"word2": "cuddle"
}
},
"s_th" : {
"id1" : {
"word1": "sink",
"word2": "think"
},
"id2" : {
"word1": "sick",
"word2": "thick"
},
"id3" : {
"word1": "sing",
"word2": "thing"
},
"id4" : {
"word1": "sought",
"word2": "thought"
},
"id5" : {
"word1": "sank",
"word2": "thank"
},
"id6" : {
"word1": "seam",
"word2": "theme"
},
"id7" : {
"word1": "sin",
"word2": "thin"
},
"id8" : {
"word1": "mouse",
"word2": "mouth"
},
"id9" : {
"word1": "tense",
"word2": "tenth"
},
"id10" : {
"word1": "force",
"word2": "forth"
},
"id11" : {
"word1": "worse",
"word2": "worth"
},
"id12" : {
"word1": "face",
"word2": "faith"
},
"id13" : {
"word1": "boss",
"word2": "both"
},
"id14" : {
"word1": "mass",
"word2": "math"
}
},
"oo-lvc_ou" : {
"id1" : {
"word1": "called",
"word2": "cold"
},
"id2" : {
"word1": "raw",
"word2": "row"
},
"id3" : {
"word1": "law",
"word2": "low"
},
"id4" : {
"word1": "call",
"word2": "coal"
},
"id5" : {
"word1": "hall",
"word2": "hole"
},
"id6" : {
"word1": "tall",
"word2": "toll"
},
"id7" : {
"word1": "bawl",
"word2": "bowl"
},
"id8" : {
"word1": "tall",
"word2": "tole"
},
"id9" : {
"word1": "lawn",
"word2": "loan"
},
"id10" : {
"word1": "pawl",
"word2": "pole"
},
"id11" : {
"word1": "ball",
"word2": "bole"
},
"id12" : {
"word1": "caught",
"word2": "coat"
}
},
"alfa-hschwa_hschwa-lvc" : {
"id1" : {
"word1": "heart",
"word2": "hurt"
},
"id2" : {
"word1": "hard",
"word2": "heard"
},
"id3" : {
"word1": "carve",
"word2": "curve"
},
"id4" : {
"word1": "lark",
"word2": "lurk"
},
"id5" : {
"word1": "bard",
"word2": "bird"
},
"id6" : {
"word1": "far",
"word2": "fur"
},
"id7" : {
"word1": "park",
"word2": "perk"
}
},
"ash_e" : {
"id1" : {
"word1": "adapt",
"word2": "adept"
},
"id2" : {
"word1": "parish",
"word2": "perish"
},
"id3" : {
"word1": "marry",
"word2": "merry"
},
"id4" : {
"word1": "back",
"word2": "beck"
},
"id5" : {
"word1": "band",
"word2": "bend"
},
"id6" : {
"word1": "nat",
"word2": "net"
},
"id7" : {
"word1": "bag",
"word2": "beg"
},
"id8" : {
"word1": "hat",
"word2": "het"
}
},
"ou_oo-hschwa" : {
"id1" : {
"word1": "motor",
"word2": "mortar"
},
"id2" : {
"word1": "load",
"word2": "lord"
},
"id3" : {
"word1": "bode",
"word2": "board"
},
"id4" : {
"word1": "coat",
"word2": "court"
},
"id5" : {
"word1": "boa",
"word2": "bore"
},
"id6" : {
"word1": "hose",
"word2": "hoarse"
},
"id7" : {
"word1": "woe",
"word2": "war"
}
},
"oo-lvc_schwa-u" : {
"id1" : {
"word1": "walk",
"word2": "woke"
},
"id2" : {
"word1": "bought",
"word2": "boat"
},
"id3" : {
"word1": "cost",
"word2": "coast"
},
"id4" : {
"word1": "flaw",
"word2": "flow"
},
"id5" : {
"word1": "hall",
"word2": "whole"
},
"id6" : {
"word1": "nought",
"word2": "note"
}
},
"hschwa_lvc" : {
"id1" : {
"word1": "fort",
"word2": "fought"
},
"id2" : {
"word1": "sort",
"word2": "sought"
},
"id3" : {
"word1": "source",
"word2": "sauce"
},
"id4" : {
"word1": "lorn",
"word2": "lawn"
},
"id5" : {
"word1": "there",
"word2": "their"
},
"id6" : {
"word1": "court",
"word2": "caught"
}
},
"alfau_oo" : {
"id1" : {
"word1": "brown",
"word2": "brawn"
},
"id2" : {
"word1": "drown",
"word2": "drawn"
},
"id3" : {
"word1": "down",
"word2": "dawn"
},
"id4" : {
"word1": "sow",
"word2": "saw"
},
"id5" : {
"word1": "sough",
"word2": "saw"
},
"id6" : {
"word1": "tout",
"word2": "taught"
}
},
"alfa_e" : {
"id1" : {
"word1": "not",
"word2": "net"
},
"id2" : {
"word1": "adopt",
"word2": "adept"
},
"id3" : {
"word1": "bog",
"word2": "beg"
},
"id4" : {
"word1": "hot",
"word2": "het"
},
"id5" : {
"word1": "bock",
"word2": "beck"
},
"id6" : {
"word1": "bond",
"word2": "bend"
}
},
"s_esh" : {
"id1" : {
"word1": "seat",
"word2": "sheet"
},
"id2" : {
"word1": "see",
"word2": "she"
},
"id3" : {
"word1": "seep",
"word2": "sheep"
},
"id4" : {
"word1": "seer",
"word2": "sheer"
},
"id5" : {
"word1": "sip",
"word2": "ship"
}
},
"z_eth" : {
"id1" : {
"word1": "wiz",
"word2": "with"
},
"id2" : {
"word1": "zen",
"word2": "then"
},
"id3" : {
"word1": "breeze",
"word2": "breathe"
},
"id4" : {
"word1": "tease",
"word2": "teethe"
},
"id5" : {
"word1": "closing",
"word2": "clothing"
}
},
"alfa_a" : {
"id1" : {
"word1": "drier",
"word2": "dryer"
},
"id2" : {
"word1": "find",
"word2": "fined"
},
"id3" : {
"word1": "guise",
"word2": "guys"
},
"id4" : {
"word1": "lime",
"word2": "lyme"
}
},
"e_i" : {
"id1" : {
"word1": "wary",
"word2": "weary"
},
"id2" : {
"word1": "emigrant",
"word2": "immigrant"
},
"id3" : {
"word1": "desert",
"word2": "dessert"
},
"id4" : {
"word1": "tear",
"word2": "tier"
}
},
"schwa-u_oo-hschwa" : {
"id1" : {
"word1": "woe",
"word2": "war"
},
"id2" : {
"word1": "foam",
"word2": "form"
},
"id3" : {
"word1": "foe",
"word2": "four"
}
},
"alfa_o" : {
"id1" : {
"word1": "dow",
"word2": "dough"
},
"id2" : {
"word1": "wow",
"word2": "woe"
},
"id3" : {
"word1": "allow",
"word2": "alow"
}
},
"alfa_oo" : {
"id1" : {
"word1": "noun",
"word2": "known"
},
"id2" : {
"word1": "farm",
"word2": "form"
},
"id3" : {
"word1": "what",
"word2": "wat"
}
},
"oo-hschwa_hschwa-lvc" : {
"id1" : {
"word1": "warm",
"word2": "worm"
},
"id2" : {
"word1": "ward",
"word2": "word"
},
"id3" : {
"word1": "torn",
"word2": "turn"
}
},
"other" : {
"id1" : {
"word1": "with",
"word2": "width"
},
"id2" : {
"word1": "breathe",
"word2": "breadth"
},
"id3" : {
"word1": "father",
"word2": "further"
},
"id4" : {
"word1": "borrow",
"word2": "borough"
},
"id5" : {
"word1": "hole",
"word2": "whole"
},
"id6" : {
"word1": "toe",
"word2": "tow"
},
"id7" : {
"word1": "bill",
"word2": "beer"
},
"id8" : {
"word1": "all",
"word2": "oar"
},
"id9" : {
"word1": "shock",
"word2": "shook"
},
"id10" : {
"word1": "crock",
"word2": "crook"
},
"id11" : {
"word1": "aren't",
"word2": "ant"
},
"id12" : {
"word1": "parse",
"word2": "pass"
},
"id13" : {
"word1": "some",
"word2": "sum"
},
"id14" : {
"word1": "discus",
"word2": "discuss"
},
"id15" : {
"word1": "gall",
"word2": "girl"
},
"id16" : {
"word1": "walk",
"word2": "work"
}
}
}
}
アプリの使用に必要なファイルについて()
以下に格納しました。
https://drive.google.com/open?id=1u4l5wo-6SC00Ys0xBZO_am1v2yPjb_NU
本当はこんなことせずにGithubで管理が効率的と思いますが。。勉強中なので暫定的にGoogle driveに格納しました。
上記ドライブに格納したファイルをローカルにダウンロードし、ローカルでの置き場所に合わせて下記のように.pyに記載されているディレクトリを変更します。(面倒ですが)
| 置き場所 | ソースの変更箇所 |
|---|---|
| 音声ファイル(mp3) | 変数「filename」右辺のディレクトリ |
| jsonファイル | 変数「f」右辺のディレクトリ |
| 画像ファイル(png) | 変数「pngfile」右辺のディレクトリ |
英単語情報格納ファイル(json)について
上記の通り、jsonファイルは発音記号の違いごとに単語のペアをまとめてある。発音記号はそのまま書いても扱えないため、下記のように英語で書いて対応した。
| 発音記号 | 名称 | 上記のjsonでの書き方 |
|---|---|---|
| æ | アッシュ | ash |
| ʃ | エッシュ | esh |
| ə | シュワー | schwa |
| ɚ | 鉤付き(hooked)シュワー | hschwa |
| ɔ | 開いた(open)o | oo |
| α | アルファ | alfa |
| ː | 長母音コロン(long vowel colon) | lvc |
| ʌ | キャレット、ウェッジ、ハット | crt |
| ð | エズ | eth |
| θ | シータ | th |
例えば「ɚ」と「ː」のペアの場合は「hschwa_lvc」と記載した。
因みにaやrやvなどは、そのまま記載した。
備考
実は以前、pythonではなく、下記書籍を参考にしながら、C++を.NET用に拡張したC++/CLIで同様のアプリを作成したことがあります。
しかしC++/CLRという仕様が複雑かつ情報がないという難儀な言語の前に悪戦苦闘し、何とか本投稿と似たようなものは作ったものの、メンテ性に欠ける扱いづらい代物と化してしまったため、pythonで作り直して本記事にて投稿しました。
参考にさせていただいた情報
特に下記にお世話になりました。いつも有益な情報を下さり、大変感謝しております。
最後に
GUIやソースに対して改善案など、フィードバックいただけると大変嬉しいです!!