初めに
この記事はHIKKYアドベントカレンダー4日目の記事です。
こんにちは!今年7月にHIKKY にAIエンジニアとして入社しましたFukuroです!
ThradTaleの開発に携わっています。
誰でも簡単にアバター改変を行える面白いサービスなので是非一度お試しください!
https://x.com/phio_alchemist/status/1725423529133486454?s=20
https://note.com/phio_alchemist/n/nf5d810d4dc3d
概要
AWSなどでAIモデルをデプロイをしようと思うと色々面倒な手続きを取る必要があります。特に、私のようなインフラ関係の知識が乏しいDLエンジニアにとっては中々に難しいものがあります。
そんな中見つけた、簡単にデプロイができ、使った分だけ料金を払う非常に使いやすいGPUサービスCerebriumについてご紹介します。
Cerebriumの特徴
公式ドキュメントに書かれているCerebriumの特徴は以下の通りです。
- 5秒以下のコールドスタート時間
- 幅広いGPUの選択肢
- 数秒で1から10,000リクエストへの自動スケーリング
- pip/condaコンテナ環境をコードで定義
- シークレットマネージャ
- ワンクリックデプロイ
- 永続ストレージ
- 利用の容易さ: 数行のコードでこれらの機能を利用可能。
- 料金
特に素晴らしいのは自動スケーリングがある点でしょう。プランによって制限はありますが、面倒なことをせずにスケーリングできるのは非常に大きな利点です。
料金について
Cerebriumでは3つの料金プランが存在します
https://www.cerebrium.ai/pricing
| プラン名 | 月額料金 | ユーザー数 | デプロイ可能モデル数 | GPU同時利用数 | ログ保持期間 | 特別サポート |
|---|---|---|---|---|---|---|
| Hobby | 無料 | 3人 | 3 | 5 | 1日 | SlackとIntercom経由 |
| Standard | $100/月 | 10人 | 無制限 | 30 | 30日 | - |
| Enterprise | カスタムプラン | 無制限 | 無制限 | 無制限 | 無制限 | 専用Slackサポート |
これとは別に推論にかかった料金が請求されます。ただし、登録時10$のクレジットが貰えるので結構動かせます。
幅広いGPUの選択肢
Cerebriumで使えるGPUは以下の通りです。
| GPUモデル | メモリ容量 | 秒間コスト |
|---|---|---|
| A100 80GB | 80GB | $0.001023 |
| A100 40GB | 40GB | $0.000954 |
| RTX A6000 | 48GB | $0.000593 |
| RTX A5000 | 24GB | $0.000356 |
| RTX A4000 | 16GB | $0.000282 |
| Quadro RTX 5000 | 16GB | $0.000264 |
| Quadro RTX 4000 | 8GB | $0.000111 |
この幅広い選択肢の中から、デプロイしたいモデルに合わせて最適なGPUを選択することができ、しかも安価です。
実際は、これとは別にCPU、メモリ、ストレージの料金が合算されますがGPUに比べれば微々たるものです。
ワンクリックデプロイ
Cerebriumはあらかじめ用意されているモデルがたくさんあり、ワンクリックでデプロイすることができます。
LLMから画像生成、Whisperもあります!有名どころが多いのが嬉しいですね!
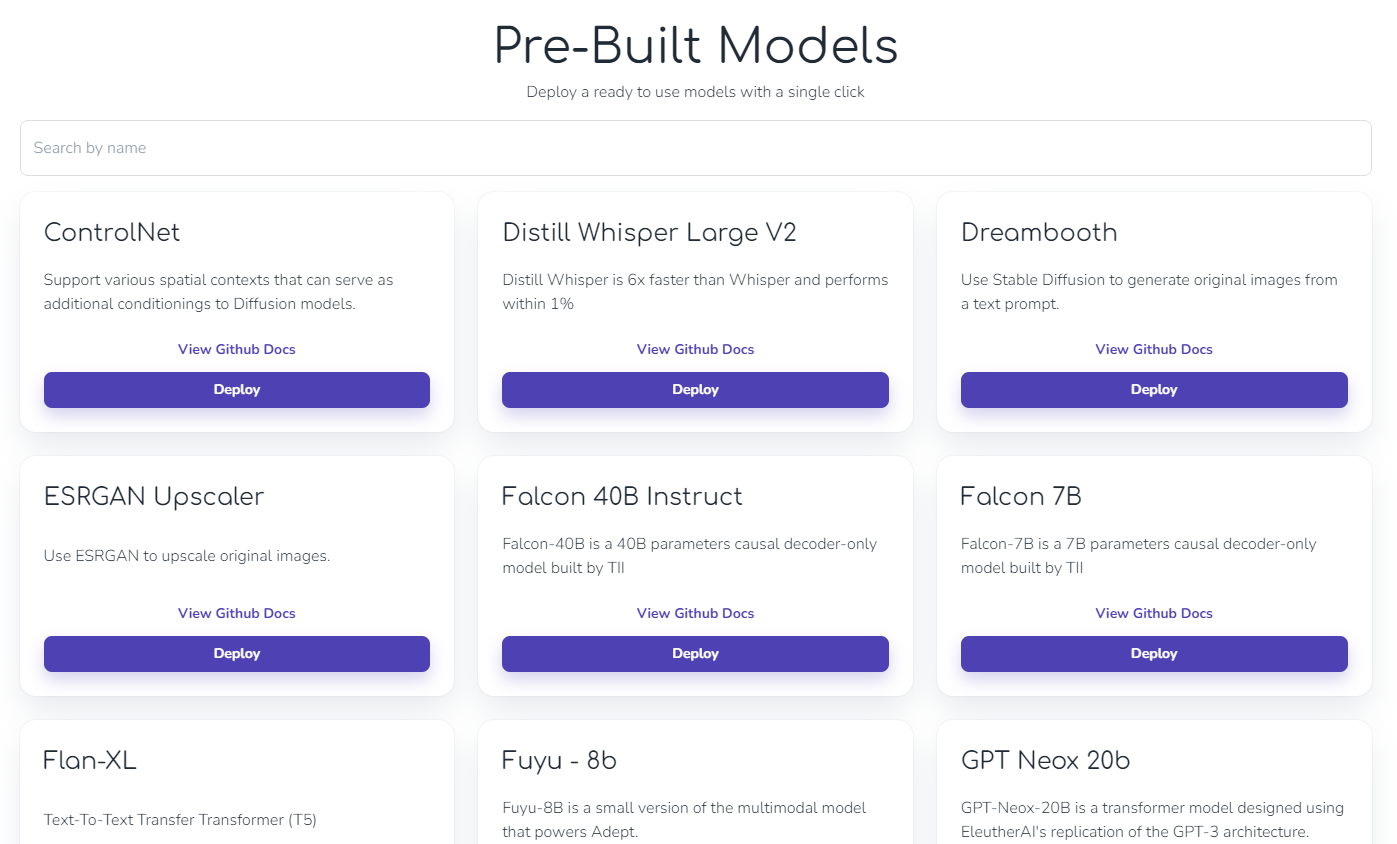
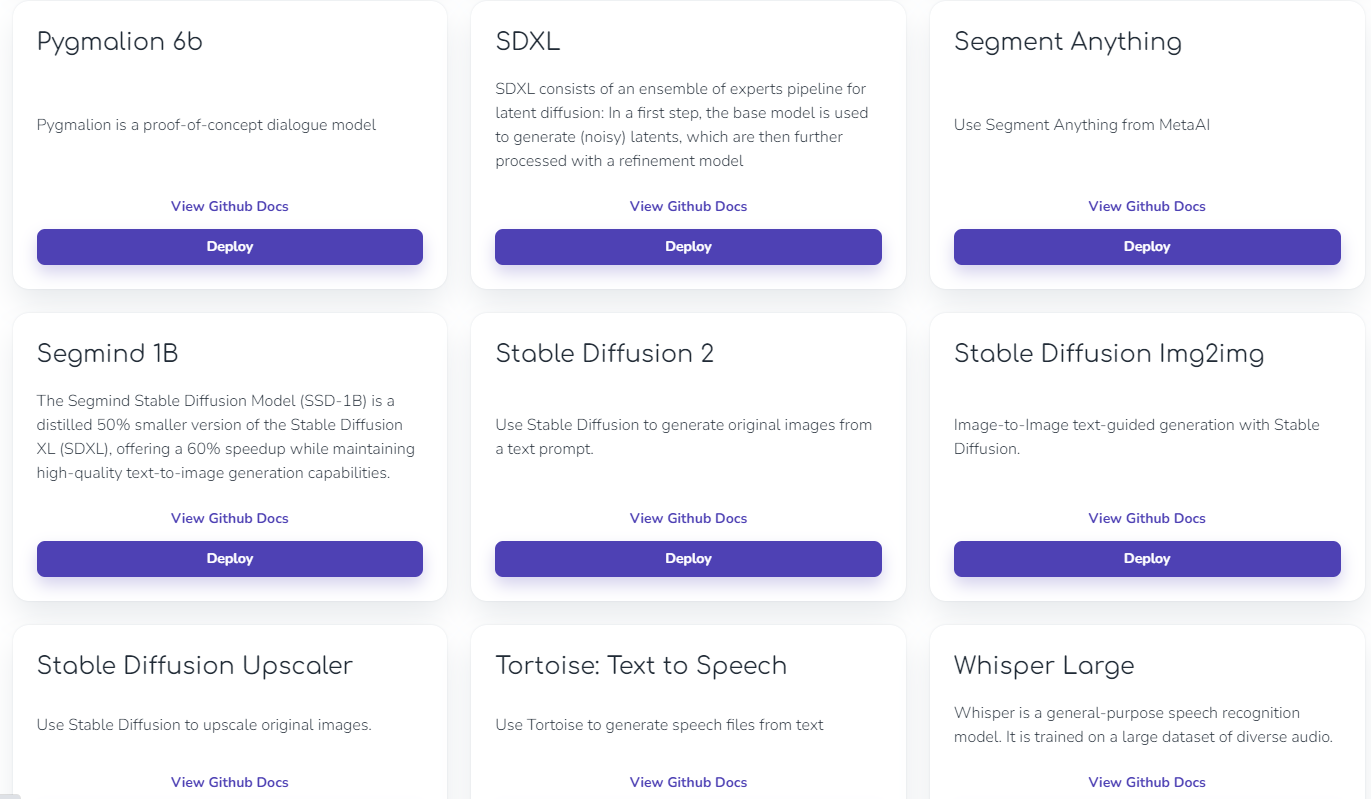
デプロイ方法
では実際にどうやってモデルをデプロイするのか見ていきましょう。
まず、サイトでユーザー登録をします。この時、クレジットカードの登録が必要になります。
Create New Projectを押して、プロジェクト名を入力し作成するとこのような画面に飛びます。
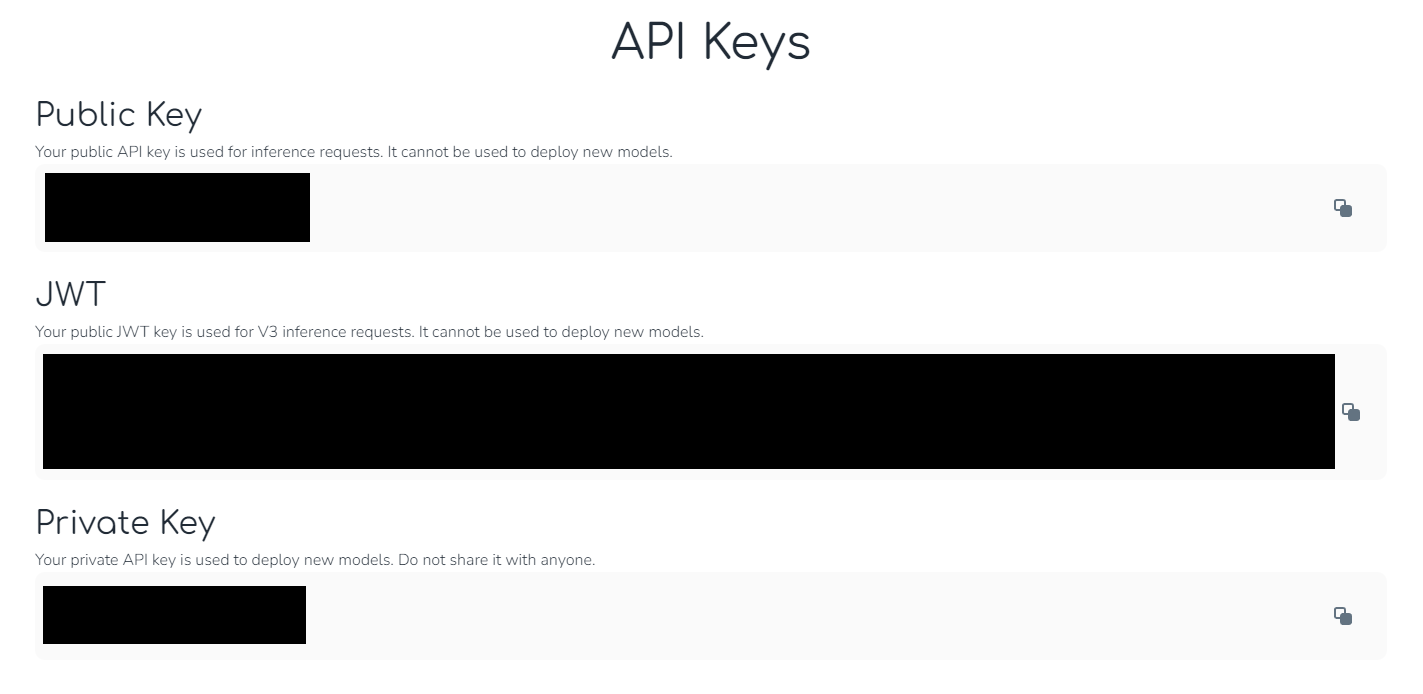
API Keysタブをクリックして、Private Keyをコピーしてください。デプロイに必要です。
推論時にはPublic KeyまたはJWTを使います(公式はJWTを使うことを推奨しています
cerebriumのライブラリをインストールします。
pip install cerebrium
次に、Private Keyを用いてログインします。
cerebrium login <YOUR_PRIVATE_API_KEY>
プロジェクトを作成します
cerebrium init sdxl-refiner
するとsdxl-refinerフォルダが作成されるので移動します。
中には必要なファイルがあらかじめ生成されており、main.pyは実際に推論する際の処理を記述し、requirments.txtには必要なライブラリを記述します。config.yaml はデプロイ環境を記述します。
具体的なコードは公式のサンプルを使います。
main.py
import base64
import io
from typing import Optional
import torch
from diffusers import StableDiffusionXLImg2ImgPipeline
from diffusers.utils import load_image
from pydantic import BaseModel
class Item(BaseModel):
prompt: str
url: str
negative_prompt: Optional[str] = None
conditioning_scale: Optional[float] = 0.5
height: Optional[int] = 512
width: Optional[int] = 512
num_inference_steps: Optional[int] = 20
guidance_scale: Optional[float] = 7.5
num_images_per_prompt: Optional[int] = 1
pipe = StableDiffusionXLImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True,
)
pipe = pipe.to("cuda")
def predict(item, run_id, logger):
item = Item(**item)
init_image = load_image(item.url).convert("RGB")
images = pipe(
item.prompt,
negative_prompt=item.negative_prompt,
controlnet_conditioning_scale=item.conditioning_scale,
height=item.height,
width=item.width,
num_inference_steps=item.num_inference_steps,
guidance_scale=item.guidance_scale,
num_images_per_prompt=item.num_images_per_prompt,
image=init_image,
).images
finished_images = []
for image in images:
buffered = io.BytesIO()
image.save(buffered, format="PNG")
finished_images.append(base64.b64encode(buffered.getvalue()).decode("utf-8"))
return {"images": finished_images}
requirements.txt
invisible_watermark
transformers
accelerate
safetensors
diffusers
config.yaml
%YAML 1.2
---
hardware: AMPERE_A5000
memory: 14
cpu: 2
min_replicas: 0
log_level: INFO
include: '[./*, main.py, requirements.txt, pkglist.txt, conda_pkglist.txt]'
exclude: '[./.*, ./__*]'
cooldown: 60
disable_animation: false
このように記述します。
その後、下記コマンドでデプロイを行います
cerebrium deploy sdxl-refiner
デプロイするとprojectページのModelsにデプロイしたモデルが表示されます。(画像のは関係ないプロジェクトです

ここでBuild statusがSuccessになっていないとデプロイがうまくいっていないので、モデルをクリックしてBuildsからLogを確認してください。

後はリクエストを投げるだけです!
curl --location 'https://run.cerebrium.ai/v3/p-xxxxx/sdxl-refiner/predict' \
--header 'Content-Type: application/json' \
--header 'Authorization: <JWT_TOKEN>' \
--data '{
"url": "https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/aa_xl/000000009.png",
"prompt": "a photo of an astronaut riding a horse on mars"
}''
これでデプロイ~推論まで行うことができました!
その他
時間がかかる処理の場合
アクセスが集中していたり、推論時間が長すぎるとタイムアウトを起こしてしまします。
そんな場合はリクエスト時にwebhook_endpointを追加することで結果が通知されるようになります。
curl --location 'https://run.cerebrium.ai/v3/p-xxxxx/sdxl-refiner/predict' \
--header 'Content-Type: application/json' \
--header 'Authorization: <JWT_TOKEN>' \
--data '{
"url": "https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/aa_xl/000000009.png",
"prompt": "a photo of an astronaut riding a horse on mars",
"webhook_endpoint":<URL>
}''
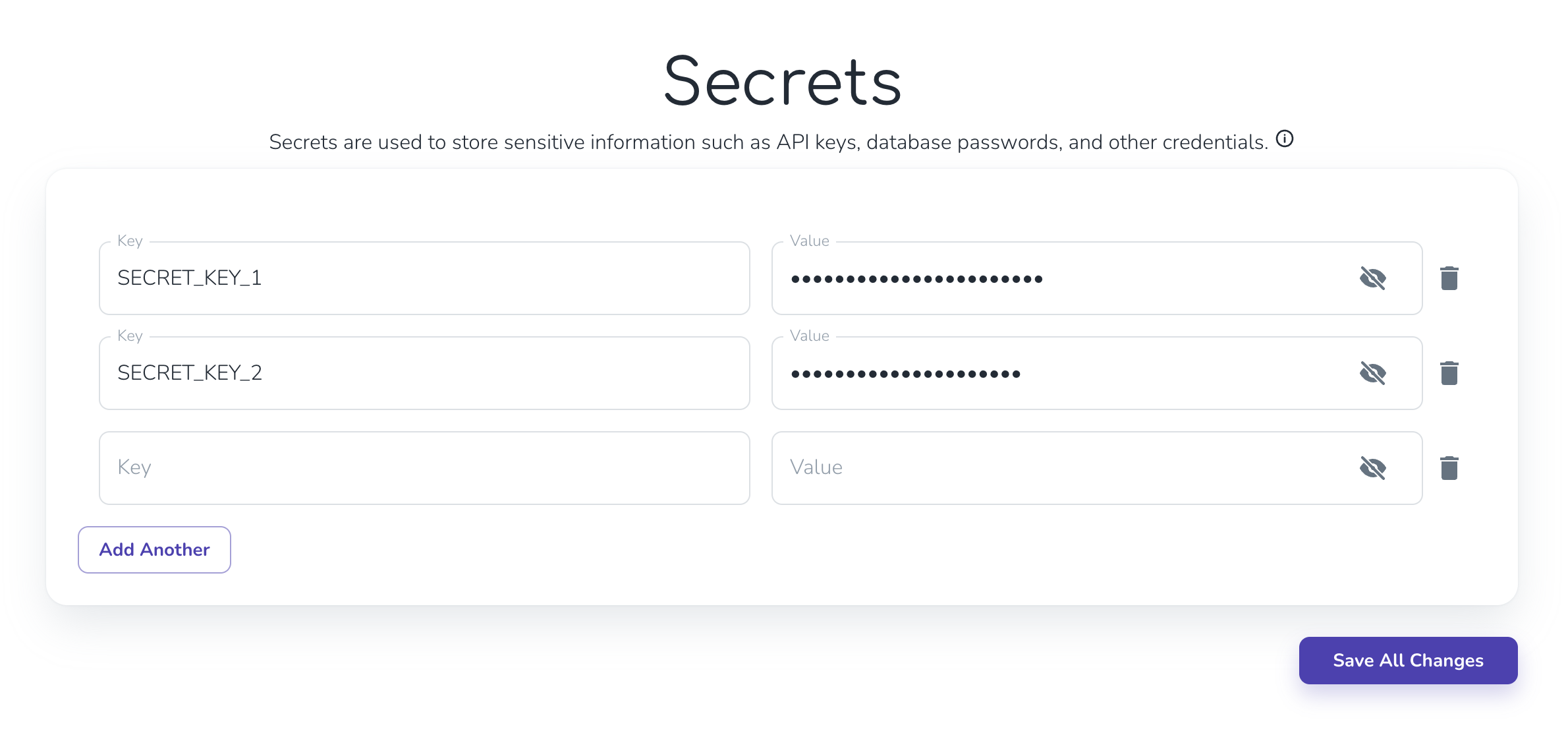
API Keyや機密情報を扱いたい
Secretsを使うことでコードに記入することなく使うことができます。
Secretsタブを開いてキーと値を入力します
後はコードで呼び出すだけです
from cerebrium import get_secret
def predict(item, run_id, logger):
item = Item(**item)
logger.info(f"Run ID: {run_id}")
my_secret = get_secret('my-secret')
logger.info("my_secret: " + my_secret)
return {"result": f"Your secret is {my_secret}"}
注意点
複雑なモデルや処理には向いていない
Cerebriumはrequirments.txtに使用するライブラリの情報を記載するので、pip経由でインストールできるものでないと構築が大変です。
また、デプロイ時に問題が起きるとその分クレジットが消費されるため、transformersやdiffusersなどで簡単に構築できるものに絞るのが良いと思います。
コードに日本語が入っているとデプロイできない
エンコードの問題かわかりませんが、日本語のコメントがあったりするとエラーでデプロイができません。
まとめ
いかかでしたでしょうか?推論GPUサービスをお探しの方は是非一度利用してみてください!