超軽量LLMのflan-t5-baseをGoogle Colaboratory無料枠でファインチューニングしてみました。今回の目的はプログラムを動かすことなので訓練のハイパーパラメータやモデル改善度など基本的に見ていません。いずれファインチューニングする時の足がかりに、と思ってやりました。
CPUでは実行できませんでしたが、無料のT4 GPUで実行できました。動かすことを目的としているので、精度などはあまり見ていません(やった後に無料から Colab Pro契約しました。制限少なくGPU使えるのが楽すぎて・・・)。
| 種別 | 内容 | 備考 |
|---|---|---|
| データ | knkarthick/dialogsum | 文章要約 |
| ベースモデル | flan-t5-base | Encoder-Decoderの248Mパラメータ |
| チューニング | フルとPEFT/LoRa | |
| 評価 | ROUGE |
実行環境
2024/4/4時点のGoogle Colab で、Python3.10.12で、以下のパッケージを使っています。
| Package | Version | 備考 |
|---|---|---|
| torch | 2.2.1+cu121 | Google Colabにプリインストールされていたバージョン |
| transformers | 4.38.2 | Google Colabにプリインストールされていたバージョン |
| datasets | 2.18.0 | 追加でpip install |
| evaluate | 0.4.1 | 追加でpip install |
| rouge_score | 0.1.2 | 追加でpip install |
| loralib | 0.1.2 | 追加でpip install |
| peft | 0.10.0 | 追加でpip install |
結果サマリ
訓練はmax_steps=600で実行しています(num_train_epochsの条件は無視)。max_stepsはバッチ単位みたいです(よく調べていないので未確認)。
訓練データは1246件、テストデータは50件で実施。PEFTの方がTraining Lossが圧倒的に良いですが、学習率を上げているからでしょうか?今回はこの辺を細かく追求しません。
| 種別 | 訓練時間 | Training Loss |
|---|---|---|
| フルファインチューニング | 30分 | 40.01 |
| PEFT | 24分 | 0.15 |
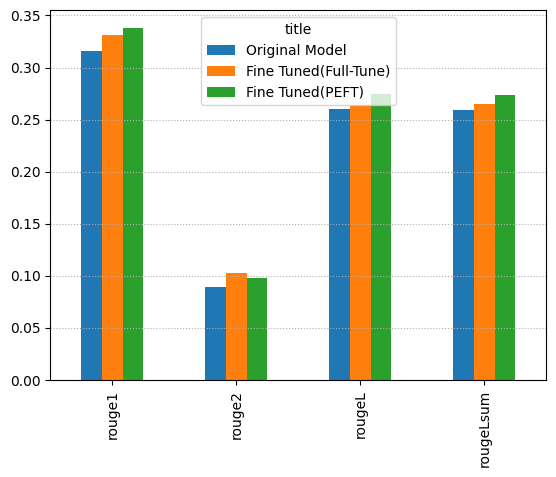
ROUGEの比較です。教科書どおりにすべてFull Fine Tuneが良いとはならなかったですが、ざっとプログラム流しただけなので気にしません。
実行プログラム
1. pip intall と import
Google Colab にプレインストールされていないdatasetsをインストール。出力が長くて邪魔だったので--quietオプションつけています。
!pip install datasets evaluate rouge_score loralib peft --quiet
from datasets import load_dataset
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig, TrainingArguments, Trainer
import torch
import time
import evaluate
import pandas as pd
import numpy as np
from peft import LoraConfig, get_peft_model, TaskType
DASH_LINE = '-'*100 # ターミナル出力の区切り
LOGGING_STEPS = 100
MAX_STEPS = 600
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
2. 文章要約データロード
knkarthick/dialogsumをダウンロードします。
dataset = load_dataset('knkarthick/dialogsum')
print(dataset)
DatasetDict({
train: Dataset({
features: ['id', 'dialogue', 'summary', 'topic'],
num_rows: 12460
})
validation: Dataset({
features: ['id', 'dialogue', 'summary', 'topic'],
num_rows: 500
})
test: Dataset({
features: ['id', 'dialogue', 'summary', 'topic'],
num_rows: 1500
})
})
データの中身は他記事でも少し触れています。
3. モデル flan-t5 ロード
def print_number_of_trainable_model_parameters(model):
trainable_model_params = 0
all_model_params = 0
for _, param in model.named_parameters():
all_model_params += param.numel()
if param.requires_grad:
trainable_model_params += param.numel()
print(f"訓練可能パラメータ: {trainable_model_params:,}")
print(f"全パラメータ: {all_model_params:,}")
print(f"訓練可能パラメータ割合: {100 * trainable_model_params / all_model_params:.2f}%")
def load_model(model_name):
model = AutoModelForSeq2SeqLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(model_name)
print_number_of_trainable_model_parameters(model)
model = model.to(device)
return model, tokenizer
original_model, tokenizer = load_model('google/flan-t5-base')
パラメータ情報出します。当然、フルファインチューニングする前提なのですべて訓練可能です。
訓練可能パラメータ: 247,577,856
全パラメータ: 247,577,856
訓練可能パラメータ割合: 100.00%
4. サンプルモデル実行
サンプルでモデルを実行します。
def get_summary_prompt(dialogue, tokenizer):
prompt = f"""
Summarize the following conversation.
{dialogue}
Summary:
"""
return tokenizer(prompt, return_tensors="pt").input_ids, prompt
def show_dialogue(index, tokenizer, model):
input_ids, prompt = get_summary_prompt(dataset['test'][index]['dialogue'], tokenizer)
print(f"Model device: {original_model.device}")
print(f"Input device: {input_ids.device}")
output = tokenizer.decode(
model.generate(
input_ids.to(model.device),
max_new_tokens=200,
)[0],
skip_special_tokens=True
)
print(DASH_LINE)
print(f'プロンプト:\n{prompt}')
print(DASH_LINE)
print(f"要約正解ラベル:\n{dataset['test'][index]['summary']}\n")
print(DASH_LINE)
print(f'モデル生成結果 Zero Shot:\n{output}')
show_dialogue(200, tokenizer, original_model)
言葉足らずな感じですが、悪くもないです。
Model device: cuda:0
Input device: cpu
----------------------------------------------------------------------------------------------------
プロンプト:
Summarize the following conversation.
#Person1#: Have you considered upgrading your system?
#Person2#: Yes, but I'm not sure what exactly I would need.
#Person1#: You could consider adding a painting program to your software. It would allow you to make up your own flyers and banners for advertising.
#Person2#: That would be a definite bonus.
#Person1#: You might also want to upgrade your hardware because it is pretty outdated now.
#Person2#: How can we do that?
#Person1#: You'd probably need a faster processor, to begin with. And you also need a more powerful hard disc, more memory and a faster modem. Do you have a CD-ROM drive?
#Person2#: No.
#Person1#: Then you might want to add a CD-ROM drive too, because most new software programs are coming out on Cds.
#Person2#: That sounds great. Thanks.
Summary:
----------------------------------------------------------------------------------------------------
要約正解ラベル:
#Person1# teaches #Person2# how to upgrade software and hardware in #Person2#'s system.
----------------------------------------------------------------------------------------------------
モデル生成結果 Zero Shot:
#Person1#: I'm thinking of upgrading my computer.
5. データ編集
データに以下の編集をします。
- プロンプト化
- Tokenize
- 不要列削除
- 件数削減(1/10に削減)
def tokenize_function(example):
start_prompt = 'Summarize the following conversation.\n\n'
end_prompt = '\n\nSummary: '
prompt = [start_prompt + dialogue + end_prompt for dialogue in example["dialogue"]]
example['input_ids'] = tokenizer(prompt, padding="max_length", truncation=True, return_tensors="pt").input_ids
example['labels'] = tokenizer(example["summary"], padding="max_length", truncation=True, return_tensors="pt").input_ids
return example
def edit_datasets(dataset):
# プロンプト化とTokenize
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 不要列削除
tokenized_datasets = tokenized_datasets.remove_columns(['id', 'topic', 'dialogue', 'summary',])
# 1/10に削減
tokenized_datasets = tokenized_datasets.filter(lambda example, index: index % 10 == 0, with_indices=True)
print(f"Shapes of the datasets:")
print(f"Training: {tokenized_datasets['train'].shape}")
print(f"Validation: {tokenized_datasets['validation'].shape}")
print(f"Test: {tokenized_datasets['test'].shape}")
print(tokenized_datasets)
return tokenized_datasets
tokenized_datasets = edit_datasets(dataset)
データの行列が削減されたのがわかります。
Shapes of the datasets:
Training: (1246, 2)
Validation: (50, 2)
Test: (150, 2)
6. 訓練実施
6.1. フルファインチューニング
まずはフルファインチューニング実施。30分かかりました。
%%time
def full_fine_tune(model, datasets):
output_dir = f'./dialogue-summary-training-{str(int(time.time()))}'
training_args = TrainingArguments(
output_dir=output_dir,
learning_rate=1e-5,
num_train_epochs=20,
weight_decay=0.01,
logging_steps=LOGGING_STEPS,
max_steps=MAX_STEPS
)
trainer = Trainer(
model=original_model,
args=training_args,
train_dataset=datasets['train'],
eval_dataset=datasets['validation']
)
trainer.train()
return trainer.model
instruct_model = full_fine_tune(original_model, tokenized_datasets)
訓練時のLossです。
Step Training Loss
100 46.617500
200 43.337500
300 41.237500
400 40.525000
500 40.057500
600 40.017500
6.2. PEFT/LoRaでファインチューニング
PEFT/LoRaのモデルをロードしてファインチューニング実施。Learning Rateはフルファインチューニングより高めに設定(それが普通なのか調べていないです)。
%%time
def peft_fine_tune(model, datasets):
output_dir = f'./peft-dialogue-summary-training-{str(int(time.time()))}'
lora_config = LoraConfig(
r=32, # Rank
lora_alpha=32,
target_modules=["q", "v"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.SEQ_2_SEQ_LM # FLAN-T5
)
peft_training_args = TrainingArguments(
output_dir=output_dir,
auto_find_batch_size=True,
learning_rate=1e-3, # Higher learning rate than full fine-tuning.
num_train_epochs=20,
logging_steps=LOGGING_STEPS,
max_steps=MAX_STEPS
)
peft_model = get_peft_model(model, lora_config)
print_number_of_trainable_model_parameters(peft_model)
peft_trainer = Trainer(
model=peft_model,
args=peft_training_args,
train_dataset=datasets["train"],
eval_dataset=datasets['validation']
)
peft_trainer.train()
return peft_trainer.model
peft_model = peft_fine_tune(original_model, tokenized_datasets)
モデルのパラメータ情報も出しています。3.5Mのパラメータを訓練します。
訓練ロスが圧倒的にフルファインチューニングより小さいです。学習率を上げているからでしょうか。
訓練可能パラメータ: 3,538,944
全パラメータ: 251,116,800
訓練可能パラメータ割合: 1.41%
Step Training Loss
100 4.282900
200 0.206200
300 0.164400
400 0.156700
500 0.153600
600 0.147700
Evaluation
evaluation_strategyを指定することで、Evaluationも同時にできます。どの単位でするかはeval_stepsで決めます。ただ、evaluation_strategyを指定すると、trainer.modelやpeft_trainer.modelを使って推論しても訓練済の情報が消失していました。バグなのか、保存したモデルから読み込むべきなのかはわからなかったですが、今回は先を急ぎたかったので、evaluation_strategyを指定しないで進めました。
7. 訓練済モデルでテスト実施
訓練済モデルで文書要約して比較。
def get_three_outputs(input_ids, model1, model2, model3):
config = GenerationConfig(max_new_tokens=200, num_beams=1)
model1_outputs = model1.generate(input_ids=input_ids.to(model1.device), generation_config=config)
model1_text_output = tokenizer.decode(model1_outputs[0], skip_special_tokens=True)
model2_outputs = model2.generate(input_ids=input_ids.to(model2.device), generation_config=config)
model2_text_output = tokenizer.decode(model2_outputs[0], skip_special_tokens=True)
model3_outputs = model3.generate(input_ids=input_ids.to(model3.device), generation_config=config)
model3_text_output = tokenizer.decode(model3_outputs[0], skip_special_tokens=True)
return model1_text_output, model2_text_output, model3_text_output
def show_result(dataset, tokenizer, original_model, instruct_model, peft_model):
input_ids, _ = get_summary_prompt(dataset['dialogue'], tokenizer)
print(input_ids.device)
original_model_text_output, instruct_model_text_output, peft_model_text_output = \
get_three_outputs(input_ids, original_model, instruct_model, peft_model)
print(DASH_LINE)
print(f"要約正解ラベル:\n{dataset['summary']}")
print(DASH_LINE)
print(f'訓練前モデル:\n{original_model_text_output}')
print(DASH_LINE)
print(f'訓練後モデル:\n{instruct_model_text_output}')
print(DASH_LINE)
print(f'PEFTモデル:\n{peft_model_text_output}')
show_result(dataset['test'][200], tokenizer, original_model, instruct_model, peft_model)
PEFTはフルファインチューニングより文は長いのですが、正確とは言えないですね。
----------------------------------------------------------------------------------------------------
要約正解ラベル:
#Person1# teaches #Person2# how to upgrade software and hardware in #Person2#'s system.
----------------------------------------------------------------------------------------------------
訓練前モデル:
#Person2# and #Person2# are discussing the importance of a computer upgrade.
----------------------------------------------------------------------------------------------------
訓練後モデル:
#Person2# proposes adding a painting program to the software. #Person2# advises to upgrade hardware and hardware.
----------------------------------------------------------------------------------------------------
PEFTモデル:
#Person2# and #Person2# are discussing the future of the computer system. #Person1# suggests that #Person2# should upgrade the hardware and software.
8. ROUGE での評価
ROUGE で100件だけ評価します。
def rouge_compute(rouge, title, human_baseline_summaries, predictions):
model_results = rouge.compute(
predictions=predictions,
references=human_baseline_summaries[0:len(predictions)],
use_aggregator=True,
use_stemmer=True,
)
print(f'{title}:')
print(model_results)
model_results['title'] = title
return model_results
def show_summaries(dataset, tokenizer, original_model, instruct_model, peft_model):
rouge = evaluate.load('rouge')
human_baseline_summaries = dataset['summary']
original_model_summaries = []
instruct_model_summaries = []
peft_model_summaries = []
for dialogue in dataset['dialogue']:
input_ids, _ = get_summary_prompt(dialogue, tokenizer)
original_model_text_output, instruct_model_text_output, peft_model_text_output = \
get_three_outputs(input_ids, original_model, instruct_model, peft_model)
original_model_summaries.append(original_model_text_output)
instruct_model_summaries.append(instruct_model_text_output)
if peft_model:
peft_model_summaries.append(peft_model_text_output)
zipped_summaries = list(zip(human_baseline_summaries, original_model_summaries, instruct_model_summaries, peft_model_summaries))
df = pd.DataFrame(zipped_summaries,
columns = ['human_baseline_summaries', 'original_model_summaries', 'instruct_model_summaries', 'peft_model_summaries'])
display(df[0:10])
original_model_results = rouge_compute(rouge, 'Original Model', human_baseline_summaries, original_model_summaries)
instruct_model_results = rouge_compute(rouge, 'Fine Tuned(Full-Tune)', human_baseline_summaries, instruct_model_summaries)
peft_model_results = rouge_compute(rouge, 'Fine Tuned(PEFT)', human_baseline_summaries, peft_model_summaries)
model_results = []
model_results.append(original_model_results)
model_results.append(instruct_model_results)
model_results.append(peft_model_results)
pd.DataFrame(model_results).set_index('title').transpose().plot(kind='bar')
print("モデル改善率(訓練済モデル(Full-Tune):訓練前モデル)")
improvement = (np.array(list(instruct_model_results.values())) - np.array(list(original_model_results.values())))
for key, value in zip(instruct_model_results.keys(), improvement):
print(f'{key}: {value*100:.2f}%')
print("モデル改善率(訓練済モデル(PEFT):訓練前モデル)")
improvement = (np.array(list(peft_model_results.values())) - np.array(list(original_model_results.values())))
for key, value in zip(peft_model_results.keys(), improvement):
print(f'{key}: {value*100:.2f}%')
print("モデル改善率(訓練済モデル(PEFT):訓練済モデル(Full-Tune):)")
improvement = (np.array(list(peft_model_results.values())) - np.array(list(instruct_model_results.values())))
for key, value in zip(peft_model_results.keys(), improvement):
print(f'{key}: {value*100:.2f}%')
show_summaries(dataset['test'][0:10], tokenizer, original_model, instruct_model, peft_model)
3件の結果並べています。
