言語処理100本ノック 2020 (Rev2)の「第8章: ニューラルネット」の75本目「損失と正解率のプロット」記録です。今は、コードを3行程度追加するだけでGoogle ColaboratoryでTensorBoard使えるので超楽勝です。
記事「まとめ: 言語処理100本ノックで学べることと成果」に言語処理100本ノック 2015についてはまとめていますが、追加で差分の言語処理100本ノック 2020 (Rev2)についても更新します。
参考リンク
| リンク | 備考 |
|---|---|
| 75_損失と正解率のプロット.ipynb | 回答プログラムのGitHubリンク |
| 言語処理100本ノック 2020 第8章: ニューラルネット | (PyTorchだけど)解き方の参考 |
| 【言語処理100本ノック 2020】第8章: ニューラルネット | (PyTorchだけど)解き方の参考 |
| まとめ: 言語処理100本ノックで学べることと成果 | 言語処理100本ノックまとめ記事 |
| 【Keras入門(3)】TensorBoardで見える化 | kerasとTensorBoard |
| ノートブックで TensorBoard を使用する | JupyterでのTensorBoard使い方 |
環境
後々GPUを使わないと厳しいので、Goolge Colaboratory使いました。Pythonやそのパッケージでより新しいバージョンありますが、新機能使っていないので、プリインストールされているものをそのまま使っています。
| 種類 | バージョン | 内容 |
|---|---|---|
| Python | 3.7.12 | Google Colaboratoryのバージョン |
| 2.0.3 | Google Driveのマウントに使用 | |
| tensorflow | 2.6.0 | ディープラーニングの主要処理 |
第8章: ニューラルネット
学習内容
深層学習フレームワークの使い方を学び,ニューラルネットワークに基づくカテゴリ分類を実装します.
ノック内容
第6章で取り組んだニュース記事のカテゴリ分類を題材として,ニューラルネットワークでカテゴリ分類モデルを実装する.なお,この章ではPyTorch, TensorFlow, Chainerなどの機械学習プラットフォームを活用せよ.
75. 損失と正解率のプロット
問題73のコードを改変し,各エポックのパラメータ更新が完了するたびに,訓練データでの損失,正解率,検証データでの損失,正解率をグラフにプロットし,学習の進捗状況を確認できるようにせよ.
回答
回答結果
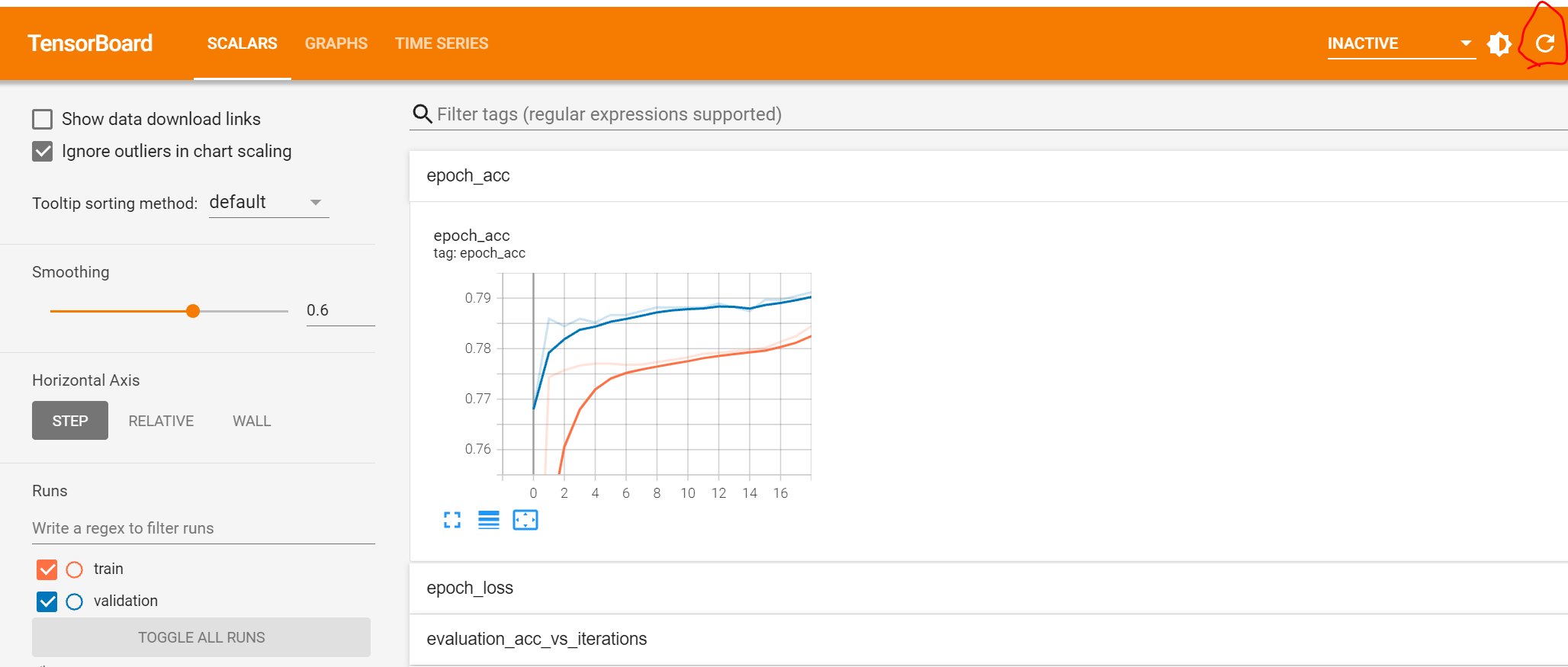
こんな感じで正解率がグラフで表示され、右上のリフレッシュアイコン押せば状況が更新されます。
回答プログラム 75_損失と正解率のプロット.ipynb
GitHubには確認用コードも含めていますが、ここには必要なものだけ載せています。Jupyterのコードなので、途中にmagicsを埋め込んでいます。
import tensorflow as tf
from google.colab import drive
drive.mount('/content/drive')
%load_ext tensorboard
def _parse_function(example_proto):
# 特徴の記述
feature_description = {
'title': tf.io.FixedLenFeature([], tf.string),
'category': tf.io.FixedLenFeature([], tf.string)}
# 上記の記述を使って入力の tf.Example を処理
features = tf.io.parse_single_example(example_proto, feature_description)
X = tf.io.decode_raw(features['title'], tf.float32)
y = tf.io.decode_raw(features['category'], tf.int32)
return X, y
BASE_PATH = '/content/drive/MyDrive/ColabNotebooks/ML/NLP100_2020/08.NeuralNetworks/'
def get_dataset(file_name):
ds_raw = tf.data.TFRecordDataset(BASE_PATH+file_name+'.tfrecord')
return ds_raw.map(_parse_function).shuffle(1000).batch(32)
train_ds = get_dataset('train')
valid_ds = get_dataset('valid')
model = tf.keras.Sequential(
[tf.keras.layers.Dense(
4, activation='softmax', input_dim=300, use_bias=False, kernel_initializer='random_uniform') ])
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['acc'])
%tensorboard --logdir './logs'
model.fit(train_ds, epochs=100, validation_data=valid_ds,
callbacks=[tf.keras.callbacks.TensorBoard(log_dir='./logs')])
回答解説
TensorBoard Extention読込
magicsを使ってTensorBoard の Extentionを読み込みます。
%load_ext tensorboard
TensorBoard起動
同じくmagicsを使ってTensorBoard 起動。簡単です。ディレクトリ.logsにあるTensorBoardのデータを読み込みます(保存は訓練時に指定します)。
今回は、訓練中にも見られるようにするために訓練開始前に実行しています。
%tensorboard --logdir './logs'
TensorBoardのコールバック指定
fit関数にコールバックでTensorBoardデータを格納するように指定します。当然、TensorBoard起動時とディレクトリを同一にします。
また、今回はvalidation_dataも指定しています。
model.fit(train_ds, epochs=100, validation_data=valid_ds,
callbacks=[tf.keras.callbacks.TensorBoard(log_dir='./logs')])