入門者に向けてKerasの初歩を解説します。
Google Colaboratoryを使っているのでローカルでの環境準備すらしていません。Google Colaboratoryについては「Google Colaboratory概要と使用手順(TensorFlowもGPUも使える)」の記事を参照ください。
以下のシリーズにしています。
- 【Keras入門(1)】単純なディープラーニングモデル定義 <- 本記事
- 【Keras入門(2)】訓練モデル保存(KerasモデルとSavedModel)
- 【Keras入門(3)】TensorBoardで見える化
- 【Keras入門(4)】Kerasの評価関数(Metrics)
- 【Keras入門(5)】単純なRNNモデル定義
- 【Keras入門(6)】単純なRNNモデル定義(最終出力のみ使用)
- 【Keras入門(7)】単純なSeq2Seqモデル定義
使ったPythonライブラリ
Google Colaboratoryでインストール済の以下のライブラリとバージョンを使っています。KerasはTensorFlowに統合されているものを使っているので、ピュアなKerasは使っていません。Pythonは3.6です。
- tensorflow: 1.13.1
- Numpy: 1.16.3
処理概要
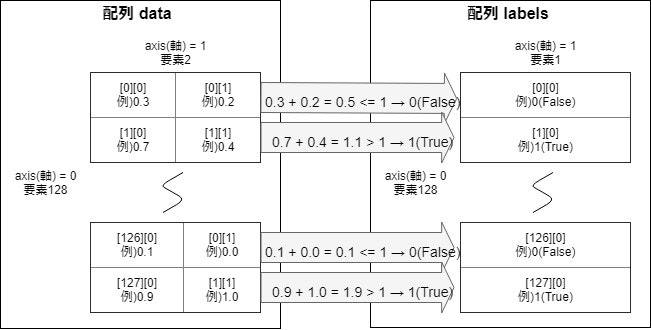
以下の2種類の配列を作って、Kerasを使ったディープラーニングで予測モデルを作ります。
| 種類 | Shape | データ |
|---|---|---|
| 説明変数(配列data) | 2 X 128 | 0から1までの乱数を全要素に入力 |
| 目的変数(配列labels) | 1 X 128 | 配列dataの2ずつの数値を合計して1以下ならば0(False)、それ以外は1(True) |
図にするとこんな感じ。
処理プログラム
プログラム全体はGitHubを参照ください。
1. ライブラリインポート
今回はnumpyとtensorflowに統合されているkerasを使います。ピュアなkerasでも問題なく、インポート元を変えるだけです。
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Input
2. 前処理
2.1. 説明変数(配列data)作成
説明変数として0から1までの乱数で128, 2の配列を作成します。
NUM_TRAIN = 128
data = np.random.rand(NUM_TRAIN,2)
2.2. 目的変数(配列labels)作成
説明変数の各行の2つの値を足した数の配列を作成します。"(np.sum(data, axis=1) > 1.0) * 1"の末尾の"* 1"を加えることでTrue/FalseのBooleanが1/0の数値に変換されます。
labels = (np.sum(data, axis=1) > 1.0) * 1
labels = labels.reshape(NUM_TRAIN,1)
3. モデル定義
モデルは図のように非常にシンプルに作っています。隠れ層が4つ程度でもAccuracy(正解率)が93%程度出ます。
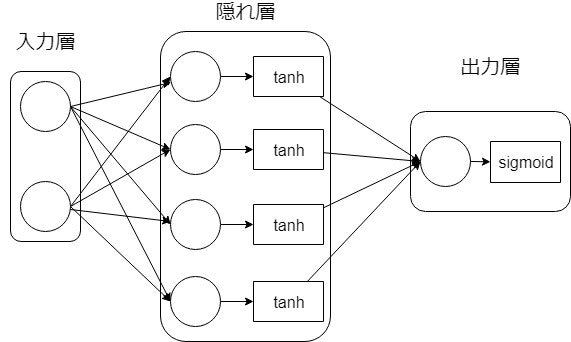
今回はSequentialモデルを使っていて、層を順番に定義していくだけのシンプルなモデルの場合に使用します。複雑なモデルを定義する場合にはFunctional APIを使用しますが、今回は使用しませんし解説もしません。
Sequentialモデルを使った場合、add関数を使って層を積み重ねていきます。Denseで層を定義していき、次元や活性化関数等を定義します。
最後にcompile関数を使って損失関数やオプティマイザを指定します。
# Sequentialモデル使用(Sequentialモデルはレイヤを順に重ねたモデル)
model = Sequential()
# 結合層(2層->4層)
model.add(Dense(4, input_dim=2, activation="tanh"))
# 結合層(4層->1層):入力次元を省略すると自動的に前の層の出力次元数を引き継ぐ
model.add(Dense(1, activation="sigmoid"))
# モデルをコンパイル
model.compile(loss="binary_crossentropy", optimizer="sgd", metrics=["accuracy"])
model.summary()
sumamry関数を使うと下記のようにモデル定義を出力してくれます。
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 4) 12
_________________________________________________________________
dense_5 (Dense) (None, 1) 5
=================================================================
Total params: 17
Trainable params: 17
Non-trainable params: 0
_________________________________________________________________
TensorBoardを使って計算グラフを表示すると、こんな感じでした。この程度のモデルでも複雑に見えてしまいますね(出力方法は「【Keras入門(3)】TensorBoardで見える化参照)。
4. 訓練実行
fit関数を使って訓練します。パラメータvalidation_splitを使うだけで訓練と評価データを割合で分けてくれるのは便利ですね。
model.fit(data, labels, epochs=300, validation_split=0.2)
訓練中に以下のようなログを出してくれます。loss, acc, val_lossとval_accの4つをEpochごとにデフォルトで出してくれるようです。評価指標に関しては別記事「【入門者向け】機械学習の分類問題評価指標解説(正解率・適合率・再現率など)」を参照ください。
WARNING:tensorflow:The `nb_epoch` argument in `fit` has been renamed `epochs`.
Train on 102 samples, validate on 26 samples
Epoch 1/300
102/102 [==============================] - 0s 1ms/sample - loss: 0.7462 - acc: 0.4314 - val_loss: 0.4325 - val_acc: 0.8462
Epoch 2/300
102/102 [==============================] - 0s 115us/sample - loss: 0.7383 - acc: 0.4314 - val_loss: 0.4373 - val_acc: 0.8462
<中略>
Epoch 299/300
102/102 [==============================] - 0s 115us/sample - loss: 0.3936 - acc: 0.9314 - val_loss: 0.5066 - val_acc: 0.8077
Epoch 300/300
102/102 [==============================] - 0s 103us/sample - loss: 0.3929 - acc: 0.9314 - val_loss: 0.5053 - val_acc: 0.8077
<tensorflow.python.keras.callbacks.History at 0x7fa1fca19550>
5. テスト
最後にテストです。
5.1. テストデータ作成
訓練データと同じ方法でテストデータを作成します。今度は50つくります。
NUM_TEST = 50
test_data = np.random.rand(NUM_TEST,2)
test_labels = (np.sum(test_data, axis=1) > 1.0) * 1
5.2. 訓練済モデルを使ったテストデータの答え合わせ
predict関数を使ってテストデータから予測値を出力します。
predict = ((model.predict(test_data) > 0.5) * 1).reshape(NUM_TEST)
print(predict)
print(test_labels)
print("Accuracy:",sum(predict == test_labels) / NUM_TEST)
68%の正解率とあまりよくはなかったですが、隠れ層の次元数を4から48くらいまで増やすと一気に正解率が増えます。
[1 0 1 1 1 1 0 1 1 1 0 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1
1 1 1 1 0 0 1 1 1 1 1 1 1]
[1 0 1 0 0 0 0 1 1 1 0 1 0 1 0 1 1 0 1 1 1 1 1 0 1 0 0 1 0 0 1 0 0 0 1 1 1
1 0 1 1 0 0 1 0 1 0 1 1 0]
Accuracy: 0.68
感想
Kerasを使うと簡単にモデルの定義や、訓練実行・推論ができます。過去に「TensorFlow理解のために柏木由紀さん顔特徴を調べてみた」などで、TensorFlowを地道に書いていたのですが、だいぶ楽にできます。
その半面、深い部分を理解するのであればKerasを使わないで勉強するのもおすすめです。各レイヤでどんなことをしているかを書いていくので、理解が深められます。
参考
ブログ記事「無から始めるKeras」のシリーズおよびKerasによる、ものすごくシンプルな深層学習の例を参考にしました。