Azure AI Searchで画像を言語化してインデックス化しました。以下のチュートリアルとほぼ同じです。
PDFファイルの画像を切り抜いて、テキスト化、ベクトル化します。
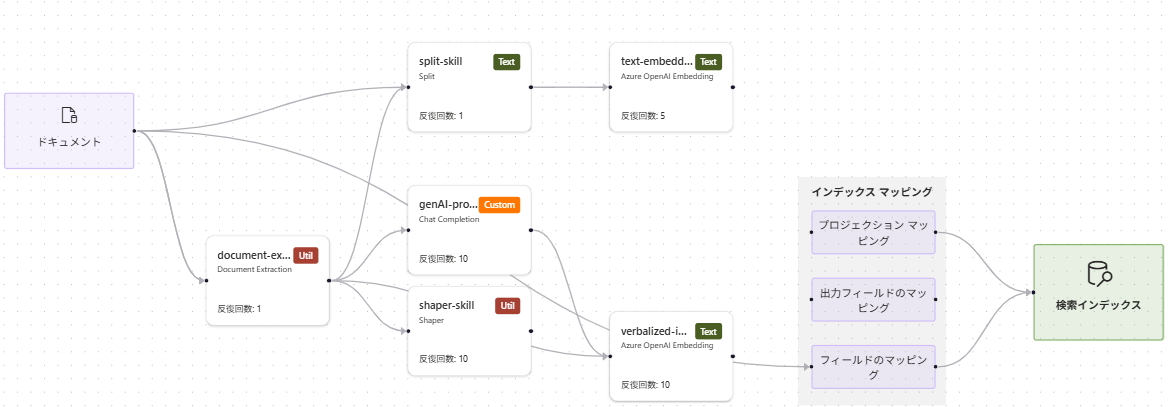
完成時のパイプライン
デバッガセッション使うとこんなパイプラインに可視化できます。
前提
REST Client 0.25.1 をVS Codeから使って実行しています。
REST Client 設定で Decode Escaped Unicode Characters を ON にするとHTTP Response Bodyの日本語がデコードされます。
また、以下の記事の1~5までのStepも前提作業です。
Steps
1. インデックス作成
1.0. 固定値定義
固定値を定義しておきます。
## Azure AI Searchのエンドポイント
@searchUrl = https://<ai searchresource name>.search.windows.net
## Azure AI SearchのAPI Key
@searchApiKey=<ai search key>
## Blob Storageの接続文字列
@storageConnection=<connection string>
## Blob Storageのコンテナ名(画像格納)
@imageProjectionContainer=images
## Blob Storageのコンテナ名(PDF格納)
@blob_container_name=rag-doc-test
# Embedding の情報
@openAIResourceUri = https://<aoai resource name>.openai.azure.com
@openAIKey = <aoai key>
# Chat Completion の情報(画像のテキスト化)
@chatCompletionResourceUri = https://<aoai researce name>.openai.azure.com/openai/deployments/gpt-4o-mini/chat/completions?api-version=2025-01-01-preview
@chatCompletionKey = <aoai key>
1.1. データ ソースを作成
公式チュートリアルと異なり、ADLS Gen2を使用。
### Create a data source
POST {{searchUrl}}/datasources?api-version=2025-08-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-extraction-image-verbalization-ds",
"description": null,
"type": "adlsgen2",
"subtype": null,
"credentials":{
"connectionString":"{{storageConnection}}"
},
"container": {
"name": "{{blob_container_name}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
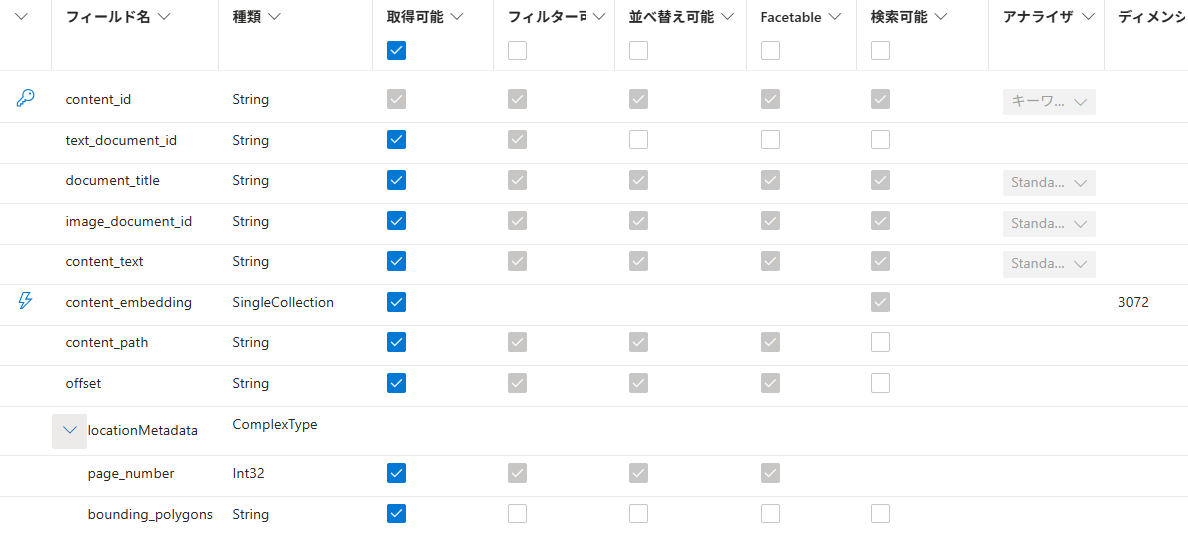
1.2. インデックスを作成
公式チュートリアルと以下を変更
-
vectorizersのKey指定修正(searchApiKeyからapiKeyに変更) -
location_metadataからlocationMetadataに項目名を修正 -
offsetは削除(不使用なので)
### Create an index
POST {{searchUrl}}/indexes?api-version=2025-08-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-extraction-image-verbalization-index",
"fields": [
{
"name": "content_id",
"type": "Edm.String",
"retrievable": true,
"key": true,
"analyzer": "keyword"
},
{
"name": "text_document_id",
"type": "Edm.String",
"searchable": false,
"filterable": true,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false
},
{
"name": "document_title",
"type": "Edm.String",
"searchable": true
},
{
"name": "image_document_id",
"type": "Edm.String",
"filterable": true,
"retrievable": true
},
{
"name": "content_text",
"type": "Edm.String",
"searchable": true,
"retrievable": true
},
{
"name": "content_embedding",
"type": "Collection(Edm.Single)",
"dimensions": 3072,
"searchable": true,
"retrievable": true,
"vectorSearchProfile": "hnsw"
},
{
"name": "content_path",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "locationMetadata",
"type": "Edm.ComplexType",
"fields": [
{
"name": "page_number",
"type": "Edm.Int32",
"searchable": false,
"retrievable": true
},
{
"name": "bounding_polygons",
"type": "Edm.String",
"searchable": false,
"retrievable": true,
"filterable": false,
"sortable": false,
"facetable": false
}
]
}
],
"vectorSearch": {
"profiles": [
{
"name": "hnsw",
"algorithm": "defaulthnsw",
"vectorizer": "demo-vectorizer"
}
],
"algorithms": [
{
"name": "defaulthnsw",
"kind": "hnsw",
"hnswParameters": {
"m": 4,
"efConstruction": 400,
"metric": "cosine"
}
}
],
"vectorizers": [
{
"name": "demo-vectorizer",
"kind": "azureOpenAI",
"azureOpenAIParameters": {
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"modelName": "text-embedding-3-large"
}
}
]
},
"semantic": {
"defaultConfiguration": "semanticconfig",
"configurations": [
{
"name": "semanticconfig",
"prioritizedFields": {
"titleField": {
"fieldName": "document_title"
},
"prioritizedContentFields": [
],
"prioritizedKeywordsFields": []
}
}
]
}
}
1.3. スキルセットを作成
skills内でsearchApiKeyとなっているKeyをapiKeyに変更
#Microsoft.Skills.Util.DocumentExtractionSkillはAzure Document Intelligenceを使わないので Azure AI Servicesリソース不要です。課金は以下の通り。
テキストの抽出は無料です。 画像抽出は 、Azure AI Search によって課金されます。 無料の検索サービスでは、1 日あたりインデクサーあたり 20 トランザクションのコストが吸収されるため、クイック スタート、チュートリアル、小規模プロジェクトを無料で完了できます。 Basic レベル以上のレベルの場合、画像の抽出は課金対象です。
サポートされるドキュメントの形式は以下の通り
- CSV (CSV BLOB のインデックス作成に関する記事を参照)
- EML
- EPUB
- GZ
- HTML
- JSON (JSON BLOB のインデックス作成に関する記事を参照)
- KML (地理的表現の XML)
- Microsoft Office 形式: DOCX/DOC/DOCM、XLSX/XLS/XLSM、PPTX/PPT/PPTM、MSG (Outlook 電子メール)、XML (2003 と 2006 両方の WORD XML)
- オープン ドキュメント形式: ODT、ODS、ODP
- プレーンテキスト ファイル (「プレーン テキストのインデックス作成」も参照)
- RTF
- XML
- ZIP
### Create a skillset
POST {{searchUrl}}/skillsets?api-version=2025-08-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-extraction-image-verbalization-skillset",
"description": "A test skillset",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Util.DocumentExtractionSkill",
"name": "document-extraction-skill",
"description": "Document extraction skill to extract text and images from documents",
"parsingMode": "default",
"dataToExtract": "contentAndMetadata",
"configuration": {
"imageAction": "generateNormalizedImages",
"normalizedImageMaxWidth": 2000,
"normalizedImageMaxHeight": 2000
},
"context": "/document",
"inputs": [
{
"name": "file_data",
"source": "/document/file_data"
}
],
"outputs": [
{
"name": "content",
"targetName": "extracted_content"
},
{
"name": "normalized_images",
"targetName": "normalized_images"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "split-skill",
"description": "Split skill to chunk documents",
"context": "/document",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 200,
"unit": "characters",
"inputs": [
{
"name": "text",
"source": "/document/extracted_content",
"inputs": []
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "text-embedding-skill",
"description": "Embedding skill for text",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "embedding",
"targetName": "text_vector"
}
],
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"dimensions": 3072,
"modelName": "text-embedding-3-large"
},
{
"@odata.type": "#Microsoft.Skills.Custom.ChatCompletionSkill",
"name": "genAI-prompt-skill",
"description": "GenAI Prompt skill for image verbalization",
"uri": "{{chatCompletionResourceUri}}",
"timeout": "PT1M",
"apiKey": "{{chatCompletionKey}}",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "systemMessage",
"source": "='You are tasked with generating concise, accurate descriptions of images, figures, diagrams, or charts in documents. The goal is to capture the key information and meaning conveyed by the image without including extraneous details like style, colors, visual aesthetics, or size.\n\nInstructions:\nContent Focus: Describe the core content and relationships depicted in the image.\n\nFor diagrams, specify the main elements and how they are connected or interact.\nFor charts, highlight key data points, trends, comparisons, or conclusions.\nFor figures or technical illustrations, identify the components and their significance.\nClarity & Precision: Use concise language to ensure clarity and technical accuracy. Avoid subjective or interpretive statements.\n\nAvoid Visual Descriptors: Exclude details about:\n\nColors, shading, and visual styles.\nImage size, layout, or decorative elements.\nFonts, borders, and stylistic embellishments.\nContext: If relevant, relate the image to the broader content of the technical document or the topic it supports.\n\nExample Descriptions:\nDiagram: \"A flowchart showing the four stages of a machine learning pipeline: data collection, preprocessing, model training, and evaluation, with arrows indicating the sequential flow of tasks.\"\n\nChart: \"A bar chart comparing the performance of four algorithms on three datasets, showing that Algorithm A consistently outperforms the others on Dataset 1.\"\n\nFigure: \"A labeled diagram illustrating the components of a transformer model, including the encoder, decoder, self-attention mechanism, and feedforward layers.\"'"
},
{
"name": "userMessage",
"source": "='Please describe this image.'"
},
{
"name": "image",
"source": "/document/normalized_images/*/data"
}
],
"outputs": [
{
"name": "response",
"targetName": "verbalizedImage"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "verbalized-image-embedding-skill",
"description": "Embedding skill for verbalized images",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "text",
"source": "/document/normalized_images/*/verbalizedImage",
"inputs": []
}
],
"outputs": [
{
"name": "embedding",
"targetName": "verbalizedImage_vector"
}
],
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"dimensions": 3072,
"modelName": "text-embedding-3-large"
},
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "shaper-skill",
"description": "Shaper skill to reshape the data to fit the index schema",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "normalized_images",
"source": "/document/normalized_images/*",
"inputs": []
},
{
"name": "imagePath",
"source": "='{{imageProjectionContainer}}/'+$(/document/normalized_images/*/imagePath)",
"inputs": []
},
{
"name": "location_metadata",
"sourceContext": "/document/normalized_images/*",
"inputs": [
{
"name": "page_number",
"source": "/document/normalized_images/*/pageNumber"
},
{
"name": "bounding_polygons",
"source": "/document/normalized_images/*/boundingPolygon"
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "new_normalized_images"
}
]
}
],
"indexProjections": {
"selectors": [
{
"targetIndexName": "doc-extraction-image-verbalization-index",
"parentKeyFieldName": "text_document_id",
"sourceContext": "/document/pages/*",
"mappings": [
{
"name": "content_embedding",
"source": "/document/pages/*/text_vector"
},
{
"name": "content_text",
"source": "/document/pages/*"
},
{
"name": "document_title",
"source": "/document/document_title"
}
]
},
{
"targetIndexName": "doc-extraction-image-verbalization-index",
"parentKeyFieldName": "image_document_id",
"sourceContext": "/document/normalized_images/*",
"mappings": [
{
"name": "content_text",
"source": "/document/normalized_images/*/verbalizedImage"
},
{
"name": "content_embedding",
"source": "/document/normalized_images/*/verbalizedImage_vector"
},
{
"name": "content_path",
"source": "/document/normalized_images/*/new_normalized_images/imagePath"
},
{
"name": "document_title",
"source": "/document/document_title"
},
{
"name": "locationMetadata",
"source": "/document/normalized_images/*/new_normalized_images/location_metadata"
}
]
}
],
"parameters": {
"projectionMode": "skipIndexingParentDocuments"
}
},
"knowledgeStore": {
"storageConnectionString": "{{storageConnection}}",
"identity": null,
"projections": [
{
"files": [
{
"storageContainer": "{{imageProjectionContainer}}",
"source": "/document/normalized_images/*"
}
]
}
]
}
}
AI 使って項目のフローをマーメイド記法で書きました。少し不足はありますが、正しいです。
ただ、Qiitaで見ると小さいので以下のツールなどを使ってみてください。
1.4. インデクサーの作成と実行
name がなかったので追加
### Create and run an indexer
POST {{searchUrl}}/indexers?api-version=2025-08-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-extraction-image-verbalization-indexer",
"dataSourceName": "doc-extraction-image-verbalization-ds",
"targetIndexName": "doc-extraction-image-verbalization-index",
"skillsetName": "doc-extraction-image-verbalization-skillset",
"parameters": {
"maxFailedItems": -1,
"maxFailedItemsPerBatch": 0,
"batchSize": 1,
"configuration": {
"allowSkillsetToReadFileData": true
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "document_title"
}
],
"outputFieldMappings": []
}
2. 検索
2.1. フル検索
フル検索
### Query the index
POST {{searchUrl}}/indexes/doc-extraction-image-verbalization-index/docs/search?api-version=2025-08-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"search": "*",
"count": true,
"select": "content_id, document_title, content_text, content_path, locationMetadata"
}
{
"@search.score": 1.0,
"content_id": "4a68c74002b5_aHR0cHM6Ly9zdG9yYWdlcmFnanBlLmJsb2IuY29yZS53aW5kb3dzLm5ldC9yYWctZG9jLXRlc3QvMDEucGRm0_normalized_images_5",
"document_title": "01.pdf",
"content_text": "The image presents financial data in a tabular format, comparing three fiscal periods: March of the third, fourth, and fifth years of the Reiwa era. The table includes various financial metrics displayed in units of hundreds of millions of yen. \n\nKey components are:\n\n1. **Insurance Income**: Increased from 266,898 million yen in the third year to 318,341 million yen in the fifth year.\n2. **Base Profit**: Slight increase from 38,380 million yen in the third year to 38,852 million yen in the fourth year, then a decrease to 27,695 million yen in the fifth year.\n3. **Capital Gains**: Grown from 4,310 million yen in the third year to 7,759 million yen in the fourth year.\n4. **Temporary Gains**: Increased from 11,808 million yen in the third year to 15,639 million yen in the fourth year but dropped to 2,642 million yen in the fifth year.\n5. **Special Gains**: Declined from 5,009 million yen in the third year to 4,070 million yen in the fifth year.\n6. **Net Profit**: Increased from 18,729 million yen in the third year to 19,452 million yen in the fifth year.\n\nThe lower section indicates \"Solvency Margin Ratio,\" showing values of 1007.4% in the third year, decreasing to 994.3% in the fourth year, then slightly rising to 944.8% in the fifth year. An additional entry denotes a year-on-year change of 49.5 points. \n\nOverall, the table reflects trends in income, profit, and solvency over specified periods, highlighting both increases and decreases across different metrics.",
"content_path": "images/aHR0cHM6Ly9zdG9yYWdlcmFnanBlLmJsb2IuY29yZS53aW5kb3dzLm5ldC9yYWctZG9jLXRlc3QvMDEucGRm0/normalized_images_5.jpg",
"locationMetadata": {
"page_number": 6,
"bounding_polygons": "[[{\"x\":410.16,\"y\":0.0},{\"x\":1487.16,\"y\":0.0},{\"x\":410.16,\"y\":404.0},{\"x\":1487.16,\"y\":404.0}]]"
}
},