第2章 命名の重要性とベストプラクティス

『AI時代のきれいなプログラムの教科書』目次
章の概要
この章の目的
プログラミングにおける命名の本質的な重要性を理解し、単なる識別子の選択を超えた「モデリングの核心」としての命名技法を習得する。Ruby作者のまつもとゆきひろ氏が「名前重要。」と断言する理由を深く理解し、実践的な命名スキルを身につける。
この章で学べること
- 命名とモデリングの密接な関係性
- 「Name and Conquer(定義攻略)」という革新的な問題解決技法
- サービス指向名前付け(SON)による効果的な設計手法
- 語彙(vocabulary)を整えることによる思考の明確化
- 命名のアンチパターンとその対策法
- 分析モデル、設計モデル、実装モデル間の一貫性維持技法
なぜ命名がこれほど重要なのか
「tmpWorkやflgといった意味不明な変数名を見るたびに、なぜこうなってしまうのか?」あなたもこんな経験があるはずである。命名は、コードの複雑さが最初に現れる場所である。この章で学ぶ命名技法は、単にコードを読みやすくするだけではない。思考を整理し、設計を明確にし、チーム開発における認識の齟齬を解決する強力な武器となる。優れた名前は、優れた設計への第一歩なのである。
2.1 説明責任(Accountability)
プログラミングでは、意図を伝えることが重要である。

例を見てみよう。
次のような日付チェックをしたいとする。
例. 「日付チェック」
- ○ 2007/02/14
- × 2007/13/32
- × 2007/02/29
- × 2100/02/29
- ○ 2000/02/29
一つ目のプログラムは、こんな感じである。
例 1. 「日付チェック (1)」
[C#]
static void ChkFunc2(int y, int m, int d)
{
string txt = "エラー: 日付が正しくありません。";
if (y < 1)
Console.WriteLine(txt);
else if (m < 1 || m > 12)
Console.WriteLine(txt);
else if (m == 2) {
if (y % 4 == 0 && y % 100 != 0 || y % 400 == 0) {
if (d < 1 || d > 29)
Console.WriteLine(txt);
} else {
if (d < 1 || d > 28)
Console.WriteLine(txt);
}
} else if (m == 4 || m == 6 || m == 9 || m == 11) {
if (d < 1 || d > 30)
Console.WriteLine(txt);
} else {
if (d < 1 || d > 31)
Console.WriteLine(txt);
}
}
[C#]
int y, m, d;
GetDat(out y, out m, out d);
ChkFunc2(y, m, d);
どうだろうか? 意図がシンプルに表現されているだろうか?
二つ目のプログラムを見てみよう。
例 2. 「日付チェック (2)」
[C#]
public class 日付
{
public int 年 { get; init; } = 2000;
public int 月 { get; init; } = 1;
public int 日 { get; init; } = 1;
public bool 日付として正しい => 年が正しい && 月が正しい && 日が正しい;
bool 年が正しい => 年 >= 1;
bool 月が正しい => 月 >= 1 && 月 <= 12;
bool 日が正しい => 日 >= 1 && 日 <= 月の最終日;
int 月の最終日 => 月 switch {
2 => 二月の最終日,
4 or 6 or 9 or 11 => 30,
_ => 31
};
int 二月の最終日 => うるう年か ? 29 : 28;
bool うるう年か => 年 % 4 == 0 && 年 % 100 != 0 || 年 % 400 == 0;
}
[C#]
var 日付 = UI.日付の取得();
if (!日付.日付として正しい)
UI.エラーメッセージ("日付が正しくありません。");
どうだろうか? どちらの意図が明確だろうか。
ソースコードは次のことが重要である:
- 意図が明確であること
- 何がやりたいのか?
- 責務の範囲が明確であること
- 何をする?
- 何をしない?
ソースコードが、自らそれらを語るように書こう。アフォーダンス(affordance)という言葉でも表現できるかもしれない。
- ソースコードは設計を語るべき
- ソースコードは意図を語るべき
ソースコード自身が説明責任を果たすように記述しよう。
2.2 命名はモデリングの核心
2.2.1 命名とモデリングの関係
「名前重要。」
プログラミングにおいて命名は根本的に重要である。Ruby の作者のまつもとゆきひろ氏 (Matz) も「プログラマが知るべき97のこと」という書籍の中で「名前重要」という言葉を使っている。
命名は単なる識別子の選択ではない。それはモデリングの中心的な行為である。プログラミングにおけるモデリングとは、現実世界の複雑さから必要な要素を抽出し、コンピュータで扱える形に抽象化することである。
よくない名前の例
- int i, i2, i3; 意図がない
- tmpWork 内容物を表していない
- lclusrdafName 読みにくい
- bool flg = false; 一体何のフラグか分らない
2.2.2 「プログラミング」という行為はモデリング
「プログラミング」という行為を次のように定義したい:
「プログラミング」という行為は設計+実装+テストである
これは単純なコーディング作業ではなく、検証可能な設計/実装モデルを作成する知的活動である。このモデルは以下の特徴を持つ:
- 人間が理解できる:開発者が意図を把握できる
- 機械が実行できる:コンピュータが処理できる
- 検証可能である:テストによって正しさを確認できる
そして、人間が理解しやすいのは、人の「頭の中のモデルにもっとも近いもの」である。
「意図をもっとも自然に、頭の中で表現するとどうなる」が、「その人のモデル」であり、その人にとって分かりやすいものになる。
カレー作り

「日本風のカレーを作る手順」の例をあげる:
玉ねぎ、じゃがいも、にんじん、肉を用意し、玉ねぎ、じゃがいも、にんじん、肉を一口大に切り、鍋で油を熱して肉→玉ねぎ→じゃがいも→にんじんの順に炒め、水を加えて沸騰させてアクを取り、弱火で15分ほど煮込んだら火を止めて市販のカレールーを加えてよく溶かし、再び弱火で10分ほど煮込んでとろみがついたら完成です。
なかなか良い感じだが、ちょっと説明が長くて、分かりにくい。
もっと簡潔に記述してみよう。
手順ごとに名前を付けて、箇条書きにすると次のようになる:
1. 材料を用意する: 玉ねぎ・じゃがいも・にんじん・肉を用意する
2. 材料を切る: 材料を一口大に切る
3. 炒める: 鍋に油を熱し、肉→玉ねぎ→じゃがいも→にんじんの順に炒める
4. 煮る:水を加えて沸騰させ、アクを取ったら弱火で15分ほど煮込む
5. カレールーを加える: 一度火を止めてルーを割り入れ、よく溶かす
6. 仕上げの煮込み: 再び弱火で10分ほど煮込んでとろみがついたら完成
ちょっとだけプログラム風に書いてみる:
カレー作り()
{
材料 = 材料を用意する();
切る(材料);
炒める(材料);
カレー = 煮る(材料);
カレールーを加える(カレー);
仕上げの煮込み(カレー);
}
材料を用意する() { return [肉, 玉ねぎ, じゃがいも, にんじん] }
切る(材料) { 材料.ForEach(each => 切る(each) }
炒める(材料) {
鍋に油を熱する
材料.ForEach(each => 炒める(each))
}
煮る(材料) {
カレー = 水を加えて沸騰させる(材料)
アクを取る(カレー)
弱火で15分ほど煮込む(カレー)
return カレー
}
カレールーを加える(カレー) {
一度火を止める
ルーを割り入れよく溶かす(カレー)
}
仕上げの煮込み(カレー) {
とろみがつくまで弱火で10分ほど煮込む(カレー)
}
名前付けにより、手順が抽象化され、同じくらいの抽象度の記述で表現されるようになったのが分かるだろうか。
抽象化というのは、「もっと簡潔に分かりやすく表現する」ために、我々がコミュニケーションの中で自然に行っていることである。
2.2.3 モデルとしてのソースコード
ソフトウェア開発には複数のモデルが存在する:
分析モデル(Analysis Model)
- 目的:顧客の問題領域を理解する
- 視点:ビジネス要求、ユーザーのニーズ
- 表現:要求仕様書、ユースケース図
設計モデル(Design Model)
- 目的:ITの世界での解決策を設計する
- 視点:アーキテクチャ、コンポーネント設計
- 表現:クラス図、シーケンス図
実装モデル(Implementation Model)
- 目的:具体的な動作するシステムを構築する
- 視点:プログラミング言語による実装
- 表現:ソースコード
これらのモデル間で一貫性を保つことが重要であり、命名はその一貫性を保つ最も重要な手段である。
[C#]
// 分析モデルの概念をそのまま実装モデルに反映
public class Customer // 顧客という分析モデルの概念
{
public void PlaceOrder(Product product) // 注文するという業務行為
{
var order = new Order(this, product); // 注文という業務概念
order.Submit(); // 提出するという業務プロセス
}
}
2.2.4 関心の分離(Separation of Concerns)
モデリングの基本原理は関心の分離である。複雑なシステムから特定の関心事を切り出し、それぞれを独立して扱うことで複雑さを管理する。
[C#]
// 悪い例:複数の関心事が混在
public class OrderProcessor
{
public void ProcessOrder(string orderData)
{
// データ解析の関心事
var parts = orderData.Split(',');
// ビジネスルールの関心事
if (decimal.Parse(parts[2]) > 1000)
{
// データ永続化の関心事
SaveToDatabase(parts);
// 通知の関心事
SendEmail(parts[0]);
}
}
}
[C#]
// 良い例:関心事を分離
public class OrderProcessor
{
private readonly IOrderParser _parser;
private readonly IOrderValidator _validator;
private readonly IOrderRepository _repository;
private readonly INotificationService _notificationService;
public void ProcessOrder(string orderData)
{
var order = _parser.Parse(orderData); // データ解析
_validator.Validate(order); // ビジネスルール
_repository.Save(order); // データ永続化
_notificationService.NotifyCustomer(order); // 通知
}
}
2.3 Name and Conquer:定義攻略の技法
2.3.1 Name and Conquerの概念
ソフトウェア開発は複雑さとの戦いの連続である。
時間とともにソフトウェアのエントロピーは増大する傾向にある。

日常生活での例:図書館の分類システム
図書館を考えてみよう。もし図書館に本が分類されずに無造作に積まれていたら、目的の本を見つけるのは不可能に近い。しかし、「文学」「歴史」「科学」といった名前を付けた分類により、膨大な情報が整理され、必要な知識にアクセスできるようになる。
これがName and Conquerの本質である。
複雑さへの対処戦略
ソフトウェア開発の複雑さに対処するための基本戦略は二つある:
-
Divide and Conquer(分割攻略):大きな問題を小さな問題に分割する
- 例:巨大な関数を複数の小さな関数に分割
-
Name and Conquer(定義攻略):注目すべきものを見つけて名前を付ける
- 例:「顧客管理に関するすべての機能」→「CustomerManager」
Name and Conquerの深い意味
Name and Conquerとは:
- 「ある注目すべきもの」を見つけ、それに名前を付ける
- 概念を切り出す。ある概念を「他のものから」切り分ける
- 混沌の中から秩序を作り出す行為
名前を付けることは、概念を確定させることである。これは単なるラベリングではなく、思考の整理そのものである。
例えば、クラス/オブジェクト/メソッドを作り、それに名前を付けるということは、プログラムにおける或る範囲の概念とそれ以外の間の境界を決めることである。
境界を決めるということは、
- それは何か?
- それは何でないか?
を決めるということである。
例えば、或るクラスに “Employee" という名前を付けるということは、
- 「システムの中のこの範囲の概念を “Employee" と呼ぶことにする」ということ
- システム全体という混沌の中から “Employee" という概念を切り出す
- “Employee" とそれ以外との間に境界を与え、“Employee" の概念の範囲を決める
-「Employee なもの」と「それ以外」を決定

そうして “Employee" という名前付けによって、概念が認識できるようになる。これは、暗黙知の形式知化であるとも言えるであろう。

暗黙知と形式知
- 暗黙知:個人が体験によって得た知識で、個人の頭の中にありうまく表現されていないもの
- 形式知:第三者に理解できるように表現された知識
2.3.2 概念の確定と境界設定
名前を付けるということは、システム全体という「混沌」の中から特定の概念を切り出し、その概念の範囲を確定させる行為である。
[C#]
// 混沌とした状態:責務が不明確
public class SystemManager
{
public void DoWork(object input)
{
// 何をするクラスなのか不明
// 何を受け取るメソッドなのか不明
}
}
[C#]
// 概念を確定:責務が明確
public class CustomerOrderValidator // 「顧客注文検証」という概念を確定
{
public ValidationResult Validate(CustomerOrder order) // 境界を明確に設定
{
// この範囲の概念を「CustomerOrderValidator」と呼ぶことを定義
// 「顧客注文検証」に関することと「それ以外」の境界が明確
}
}
2.3.3 概念の抽象化レベル
Name and Conquerを効果的に適用するには、適切な抽象化レベルで概念を切り出すことが重要である。抽象化レベルが高すぎると概念が曖昧になり、低すぎると実装の詳細に縛られてしまう。
[C#]
// 抽象化レベルが高すぎる例:概念が曖昧
public class DataProcessor // 何のデータを処理するのか不明
{
public void Process(object data) { } // 何をする処理なのか不明
}
// 抽象化レベルが低すぎる例:実装詳細に縛られている
public class SqlServerCustomerTableSelecter // データベースの実装詳細を含む
{
public DataTable SelectFromCustomerTable(string sql) { } // SQL実行に特化しすぎ
}
// 適切な抽象化レベルの例
public class CustomerRepository // ドメイン概念を適切に表現
{
public Customer FindById(int customerId) { } // ビジネス操作を表現
public void Save(Customer customer) { } // 実装詳細は隠蔽
}
適切な抽象化レベルの指針:
- ドメイン概念: ビジネス領域の自然な概念に対応
- 操作の意図: 技術的な手段ではなく、何をしたいかを表現
- 実装非依存: 特定の技術や実装方法に依存しない
2.3.4 名前による責務の限定
適切な名前は、そのコンポーネントが何をするかと同時に何をしないかを明確にする。
[C#]
// 名前による責務の限定の例
public class PriceCalculator // 価格計算に責務を限定
{
public decimal CalculateTotal(List<OrderItem> items)
{
// 価格計算に関することのみを実装
// データ保存や通知は責務外
return items.Sum(item => item.Price * item.Quantity);
}
// 以下のようなメソッドは責務外なので含めない
// void SaveOrder(Order order) ← データ保存は別の責務
// void SendEmail(string email) ← 通知も別の責務
}
2.3.5 概念階層の構築
Name and Conquerを適用することで、概念の階層構造を構築できる:
[C#]
// 概念階層の例
namespace OrderManagement // 注文管理という大きな概念
{
// 注文処理という中レベルの概念
public class OrderProcessor
{
private readonly OrderValidator _validator; // 注文検証という小さな概念
private readonly PriceCalculator _calculator; // 価格計算という小さな概念
private readonly InventoryChecker _inventory; // 在庫確認という小さな概念
}
// 各概念がさらに細かい概念に分解される
public class OrderValidator
{
private readonly CustomerValidator _customerValidator; // 顧客検証
private readonly ProductValidator _productValidator; // 商品検証
private readonly PaymentValidator _paymentValidator; // 支払い検証
}
}
2.4 名前付けで 語彙 (vocabulary) を整える
「サブルーチンは『似たような処理をまとめる』為じゃなく『名前を付ける』為にある」
型やメソッド、変数を作るときに、適切な名前を付ける。そうすることで、プログラムの一部を抽象化し、部品として扱えるようにする。そして、それらでプログラムを記述できるようにする。つまり、型やメソッド、変数が、プログラムを記述するための語彙になるのである。
設計で重要な行為が、この「プログラムを記述する語彙を作る作業」である。クラスやメソッド、変数を設計するときに、関心事を切り出して (或いは分割して) 名前を付ける。それは、プログラムを記述する語彙を作ってることになる。名前付けによって、語彙を整えるのである。
「どんな語彙で記述したいか」
プログラムをどういう語彙で記述したいか、という基準で型やメソッド、変数を切り出すようにする。
例えば、
[C#]
if (name.Length > 0) …
ではなく、
[C#]
if (IsValid(name)) …
とわざわざ IsValid メソッドを作ってまで書くのは、「このロジックをその語彙で書きたい」時、つまり「その抽象度で書きたい」時である。
「では、どの抽象度で書きたいのか?」といえば、それは「人がそれを記述するときにもっとも自然な抽象度」ということになる。例えば、「最寄りの空港に行く」というメソッド内部は、それを自然言語で「もっとも簡潔に」記述するときの粒度で書きたい。
何故かというと、「それが我々には解りやすい」からである。
例. 三角形
三角形の周囲(周の長さ)を求めるプログラムを例にあげてみよう。
三角形の周囲は、3辺の長さの合計であり、各辺の長さは、「三平方の定理(ピタゴラスの定理)」で求められる。
最初のサンプルは、次のものである。
[C#]
public static double GetTrianglePerimeter(double x1, double y1, double x2, double y2, double x3, double y3)
=> Math.Sqrt((x1 - x2) * (x1 - x2) + (y1 - y2) * (y1 - y2)) +
Math.Sqrt((x2 - x3) * (x2 - x3) + (y2 - y3) * (y2 - y3)) +
Math.Sqrt((x3 - x1) * (x3 - x1) + (y3 - y1) * (y3 - y1));
次では、このメソッドを使って、三角形の周囲を求めている:
[C#]
var perimeter = GetTrianglePerimeter(x1: 1.0, y1: -1.0, x2: 5.0, y2: -1.0, x3: 5.0, y3: 2.0);
ここから、名前付けで、語彙を作ってみよう。
x と y のペアを「二次元ベクトル」と名付けてみよう。
[C#]
public struct Vector2D
{
public double X { get; init; }
public double Y { get; init; }
}
すると、元のプログラムはこうなる:
[C#]
public static double GetTrianglePerimeter(Vector2D vector1, Vector2D vector2, Vector2D vector3)
=> Math.Sqrt((vector1.X - vector2.X) * (vector1.X - vector2.X) + (vector1.Y - vector2.Y) * (vector1.Y - vector2.Y)) +
Math.Sqrt((vector2.X - vector3.X) * (vector2.X - vector3.X) + (vector2.Y - vector3.Y) * (vector2.Y - vector3.Y)) +
Math.Sqrt((vector3.X - vector1.X) * (vector3.X - vector1.X) + (vector3.Y - vector1.Y) * (vector3.Y - vector1.Y));
[C#]
var perimeter = GetTrianglePerimeter(new() { X = 1.0, Y = -1.0}, new() { X = 5.0, Y = -1.0 }, new() { X = 5.0, Y = 2.0 });
ここで、数学的なモデルによって、処理を抽象化してみよう。
二次元ベクトルの絶対値
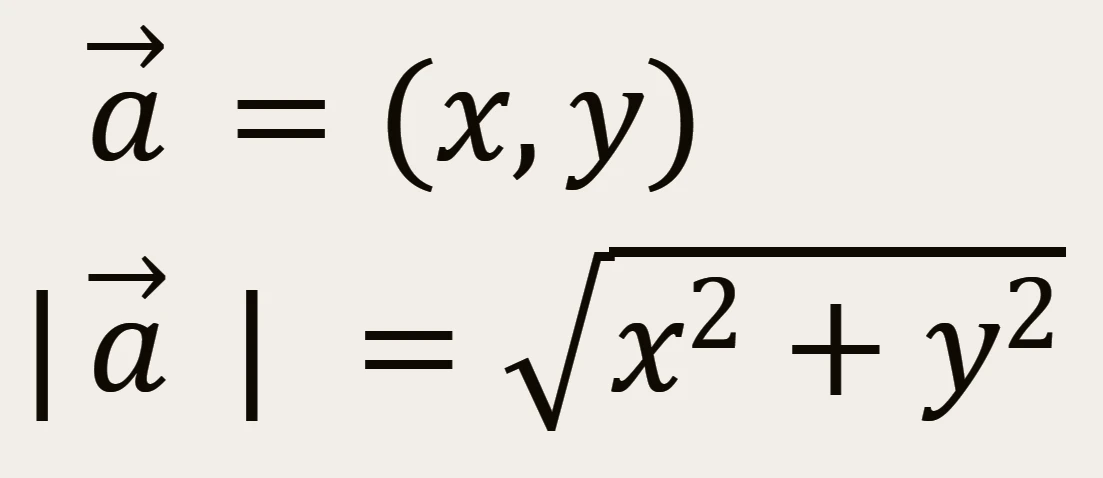
2点 a とb の距離 d
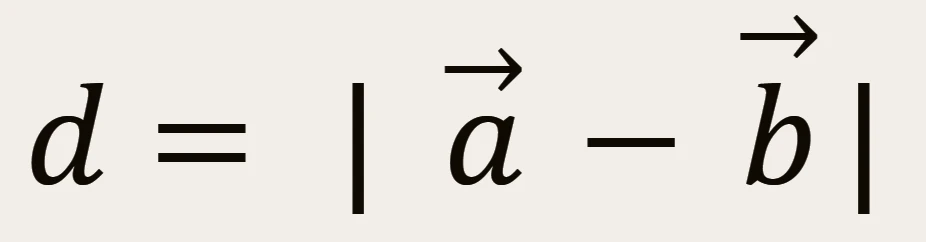
これを、Vector2D の責務として、追記する:
[C#]
public struct Vector2D
{
public double X { get; init; }
public double Y { get; init; }
public double Absolute => Math.Sqrt(X * X + Y * Y);
public static Vector2D operator -(Vector2D vector1, Vector2D vector2)
=> new Vector2D { X = vector1.X - vector2.X,
Y = vector1.Y - vector2.Y };
public static double GetDistance(Vector2D vector1, Vector2D vector2)
=> (vector1 - vector2).Absolute;
}
すると、プログラムはこうなる:
[C#]
public static double GetTrianglePerimeter(Vector2D vector1, Vector2D vector2, Vector2D vector3)
=> Vector2D.GetDistance(vector1, vector2) +
Vector2D.GetDistance(vector2, vector3) +
Vector2D.GetDistance(vector3, vector1);
更に、3点を「三角形」と名付けよう:
[C#]
public struct Triangle
{
public Vector2D Vertex1 { get; init; }
public Vector2D Vertex2 { get; init; }
public Vector2D Vertex3 { get; init; }
public double Perimeter
=> Vector2D.GetDistance(Vertex1, Vertex2) +
Vector2D.GetDistance(Vertex2, Vertex3) +
Vector2D.GetDistance(Vertex3, Vertex1);
}
すると、こうなる:
[C#]
var perimeter = new Triangle { Vertex1 = new() { X = 1.0, Y = -1.0 }, Vertex2 = new() { X = 5.0, Y = -1.0 }, Vertex3 = new() { X = 5.0, Y = 2.0 } }.Perimeter;
数学的なモデルを記述したい場合は、このような記述の方が意図を表現できていると言える。
2.5 サービス指向名前付け(Service Oriented Naming: SON)
2.5.1 インターフェイスによる名前付け
考えてみよう。
- 「テレビ」って何?
- 「電話」って何?
本来は、
tele-vision、tele-phone
⇒「遠くに映像や音声をとどけるシステム全体の名前」
の筈である。
では、次の認識は間違いなのだろうか?
これがテレビ? これが電話?

いや、そうではない。それこそがエンジニアの持つべき視点なのである。
それらは、システムがユーザーに提供するインターフェイスである。
ユーザー インターフェイスが名前になっている。
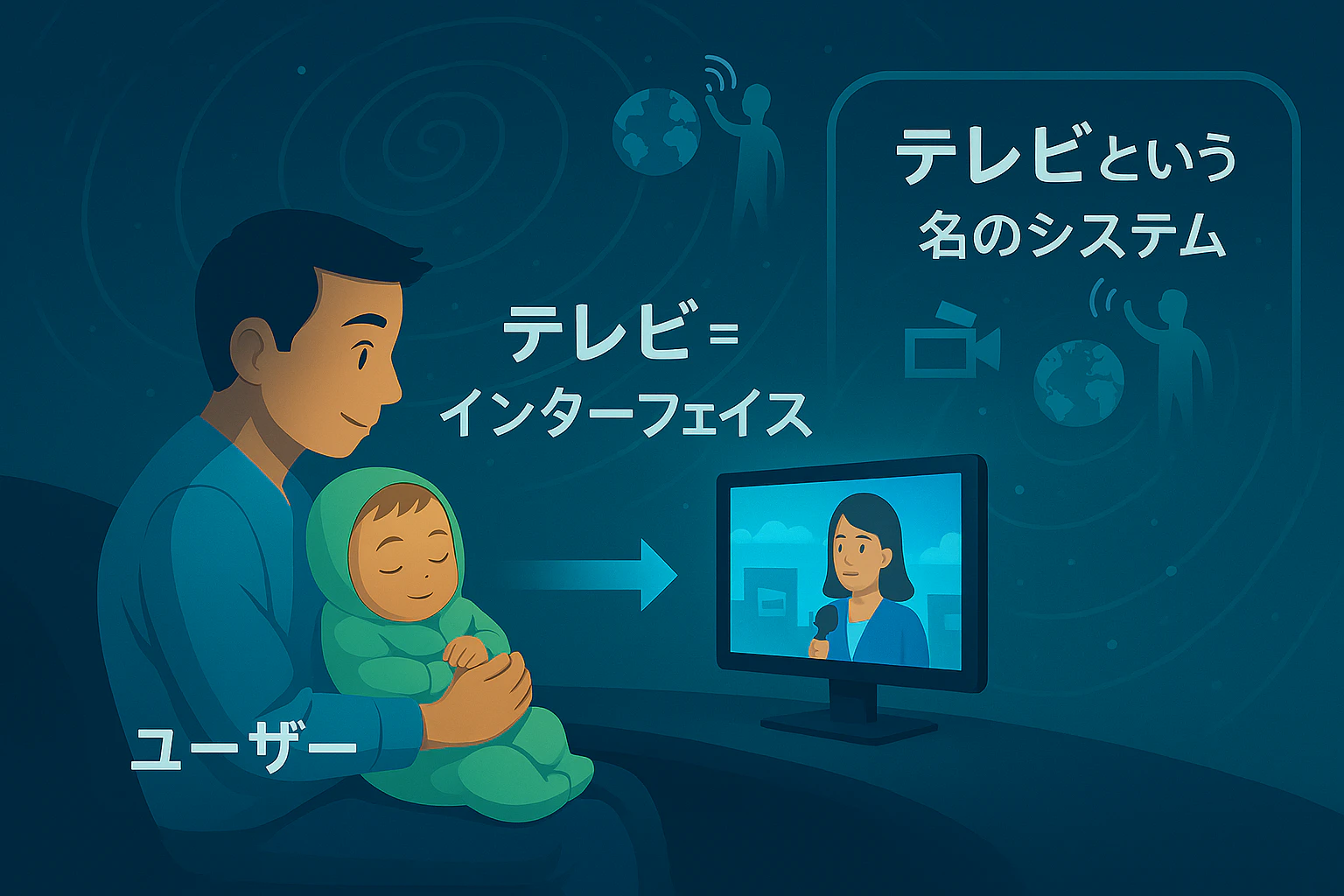
つまり、ユーザーにとっては、ユーザー インターフェイスの名前がそのものの名前となるのである。
ところで、システムを開発する目的は、顧客の問題をITで解決することである。
従って、目的 (=顧客の問題解決) が手段 (=開発) を駆動するべきであり、クライアント視点が重要である。

プログラムの内部でも同様に考えてみよう。利用する側のモジュールがクライアントであり、利用される側がサービス提供側である。
例えば、メソッドを呼ぶ側がクライアント モジュールであり、呼ばれるメソッドはサービス提供側である。
クライアントにサービスを提供

クライアント視点でみると、プログラムで使われている名前は、サービス提供モジュールがクライアント モジュールに提供するインタフェイスであり、クライアントに提供するサービスの名称である。
- 名前=インタフェイス
- 名前=サービス
名前重要。
名前はクライアント視点で付けよう。
名前は顧客側の視点で決定

サービス指向の名前付け

Service Oriented Naming

2.5.2 SONの基本思想
Service Oriented Naming(SON)は、クライアント(利用者)の視点で名前を決定するアプローチである。重要なのは「提供者がどう実装するか」ではなく、「利用者がどう使いたいか」である。
2.5.3 ユーザーインターフェースとしての名前
プログラムの名前は、そのコンポーネントのユーザーインターフェースである:
[C#]
// 実装者視点の命名(悪い例)
public class SqlCustomerDataAccessObject
{
public DataTable ExecuteSqlQuery(string sql) { }
public int ExecuteSqlNonQuery(string sql) { }
}
// クライアント視点の命名(良い例)
public class CustomerRepository
{
public Customer FindById(int customerId) { }
public List<Customer> FindByName(string name) { }
public void Save(Customer customer) { }
public void Delete(int customerId) { }
}
クライアントコードを比較すると違いは明確である:
[C#]
// 実装者視点の名前を使ったクライアントコード
var dao = new SqlCustomerDataAccessObject();
var table = dao.ExecuteSqlQuery("SELECT * FROM Customers WHERE Id = " + customerId);
// クライアントがSQLを書く必要がある
// データベースの実装詳細が露出している
// ユーザー視点の名前を使ったクライアントコード
var repository = new CustomerRepository();
var customer = repository.FindById(customerId);
// クライアントはビジネス概念で操作できる
// 実装詳細は隠蔽されている
2.5.4 サービスとしてのメソッド
各メソッドは、クライアントに対するサービスとして設計すべきである:
[C#]
public class EmailService // クライアントにメール機能を提供
{
// クライアントが欲しいサービス:「お客様に通知する」
public void NotifyCustomer(Customer customer, string message)
{
// 実装詳細(SMTPサーバー、メールテンプレートなど)は隠蔽
}
// クライアントが欲しいサービス:「管理者に警告する」
public void AlertAdministrator(string alertMessage)
{
// 実装詳細は隠蔽
}
}
2.5.5 ドメイン固有の語彙
サービス指向の命名では、そのドメイン(問題領域)で使われる自然な語彙を採用する:
[C#]
// 銀行システムの例:銀行業界の語彙を使用
public class Account // 口座
{
public void Deposit(decimal amount) // 預金
public void Withdraw(decimal amount) // 引き出し
public decimal GetBalance() // 残高照会
public void Transfer(Account to, decimal amount) // 振込
}
// ECサイトの例:小売業界の語彙を使用
public class ShoppingCart // ショッピングカート
{
public void AddItem(Product product) // 商品をカートに追加
public void RemoveItem(Product product) // 商品をカートから削除
public void Checkout() // レジに進む
public decimal GetTotal() // 合計金額
}
2.6 命名のアンチパターンと対策
ここでは、よくない名前付けのパターンをあげていく。
2.6.1 数字を付ける
アンチパターン
[C#]
public class CustomerService1
{
public void ProcessCustomer1(Customer customer) { }
}
public class CustomerService2
{
public void ProcessCustomer2(Customer customer) { }
}
問題点
- 違いが分からない
- 責務の境界が不明確
- どちらを使うべきか判断できない
対策
[C#]
public class CustomerRegistrationService
{
public void RegisterNewCustomer(Customer customer) { }
}
public class CustomerNotificationService
{
public void NotifyCustomerStatusChange(Customer customer) { }
}
2.6.2 省略する
アンチパターン
[C#]
public class CustMgr
{
public void ProcOrd(Ord ord) { }
private List<Cust> custs;
private Dict<string, Prod> prods;
}
問題点
- 読みにくい
- 意味の推測が必要
- チーム内で解釈が分かれる
対策
[C#]
public class CustomerManager
{
public void ProcessOrder(Order order) { }
private List<Customer> customers;
private Dictionary<string, Product> products;
}
2.6.3 意味不明な名前
アンチパターン
[C#]
public class Thing
{
public object Data { get; set; }
public void DoStuff(object input) { }
public List<object> Items { get; set; }
}
問題点
- 何をするクラスか分からない
- 責務が特定できない
- 保守が困難
対策
[C#]
public class OrderValidationResult
{
public List<ValidationError> Errors { get; set; }
public bool IsValid => !Errors.Any();
public void AddError(ValidationError error) { }
}
2.6.4 型名を含める
アンチパターン
[C#]
public class CustomerList : List<Customer> { }
public class OrderDictionary : Dictionary<int, Order> { }
public class ProductInterface { }
public class OrderClass { }
問題点
- 実装の詳細が名前に漏れている
- 実装変更時に名前も変更が必要
- 抽象化レベルが適切でない
対策
[C#]
public class Customers : IEnumerable<Customer> // 概念を表現
{
private readonly List<Customer> _customers = new();
public void Add(Customer customer) => _customers.Add(customer);
public Customer FindByEmail(string email) =>
_customers.FirstOrDefault(c => c.Email == email);
}
public interface IOrderLookup // 振る舞いを表現
{
Order FindById(int orderId);
}
2.6.5 統一感がない
アンチパターン
[C#]
public class CustomerService
{
public Customer GetCustomer(int id) { } // Get prefix
public Order RetrieveOrder(int id) { } // Retrieve prefix
public Product FetchProduct(int id) { } // Fetch prefix
public void SaveCustomer(Customer c) { } // Save verb
public void StoreOrder(Order o) { } // Store verb
public void PersistProduct(Product p) { } // Persist verb
}
問題点
- 学習コストが高い
- 予測できない
- チーム内で混乱が生じる
対策
[C#]
public class CustomerService
{
// 統一されたFind/Saveパターン
public Customer FindById(int customerId) { }
public Order FindOrderById(int orderId) { }
public Product FindProductById(int productId) { }
public void Save(Customer customer) { }
public void Save(Order order) { }
public void Save(Product product) { }
}
2.6.6 直訳で付ける
プログラミングでは、英語を使うことが一般的であるが、型やメソッド、変数等の名前を英語で付けるときに、例えば、"大きさ"の意味を和英辞典で調べて"size"と書いてあったから"size"と付ける、みたいな安易なのは、あまりよろしくない。
日本語と英語では、言葉の範囲が異なることがほとんどである。確かに、"大きさ"と"size"には意味の重なりがあるが、常に同じ意味で使えるわけではない。
「表現したかったこと」が、"大きさ"の意味の範囲には入っているが、"size"の意味の範囲に入っていない場合、"size"と付けるのは不適切である。

ニュアンスまで考えて意味が近いものを適切に選ぶのが良い。そのためには、英語を勉強することも必要になると思う。
なお、プログラミングを始めてから英語を復習するのはまだ楽だが、国語力がない人がプログラミングをマスターするのは結構大変である。プログラミングは、厳密に自分の語彙を作り、それで何をやるかを記述する、という作業だからである。
2.7 実践演習:効果的な命名技法
2.7.1 命名の段階的改善
Step 1: 現状分析
以下のコードの命名上の問題点を特定せよ:
[C#]
public class DataProcessor
{
private List<object> list1;
private Dictionary<string, object> dict1;
public void Process(object input)
{
// データ処理
var result = DoWork(input);
Save(result);
Send(result);
}
private object DoWork(object data)
{
// 複雑な処理
return null;
}
private void Save(object obj) { }
private void Send(object obj) { }
}
Step 2: 問題点の特定
-
意味不明な名前:
DataProcessor,DoWork -
一般的すぎる名前:
Process,Save,Send -
型情報の不足: すべて
object型 -
番号付け:
list1,dict1 - 責務が不明確: 何のデータを処理するのか不明
Step 3: 段階的改善
段階1: 意味のある名前に変更
[C#]
public class OrderProcessor // より具体的な名前
{
private List<Order> pendingOrders; // 具体的な型と意味
private Dictionary<string, Product> productCatalog; // 意味のある名前
public void ProcessOrder(Order order) // 具体的な引数型
{
var validatedOrder = ValidateOrder(order); // 明確な処理内容
SaveOrder(validatedOrder);
SendConfirmation(validatedOrder);
}
private Order ValidateOrder(Order order) // 処理内容が明確
{
// 注文検証処理
return order;
}
private void SaveOrder(Order order) { }
private void SendConfirmation(Order order) { }
}
段階2: 責務をさらに分離
[C#]
public class OrderProcessingWorkflow // ワークフロー全体を管理
{
private readonly IOrderValidator _validator;
private readonly IOrderRepository _repository;
private readonly ICustomerNotificationService _notificationService;
public async Task<OrderProcessingResult> ProcessNewOrder(Order order)
{
var validationResult = await _validator.ValidateAsync(order);
if (!validationResult.IsValid)
return OrderProcessingResult.ValidationFailed(validationResult.Errors);
await _repository.SaveAsync(order);
await _notificationService.SendOrderConfirmationAsync(order);
return OrderProcessingResult.Success(order);
}
}
2.7.2 ドメイン概念の抽出
演習: ECサイトの概念モデリング
以下の要求から適切なクラス名とメソッド名を抽出せよ:
要求:
「顧客は商品をショッピングカートに追加し、決済を行い、注文を確定する。注文が確定すると在庫から商品が引き当てられ、出荷準備が開始される。」
解答例:
[C#]
// ドメイン概念を自然な名前で表現
public class Customer
{
public ShoppingCart CreateShoppingCart() { }
public Order PlaceOrder(ShoppingCart cart, PaymentMethod payment) { }
}
public class ShoppingCart
{
public void AddProduct(Product product, int quantity) { }
public void RemoveProduct(Product product) { }
public void UpdateQuantity(Product product, int newQuantity) { }
public CheckoutSession StartCheckout() { }
}
public class CheckoutSession
{
public PaymentResult ProcessPayment(PaymentMethod method) { }
public Order ConfirmOrder() { }
}
public class Order
{
public OrderStatus Status { get; private set; }
public void Confirm() { }
public void Cancel() { }
}
public class InventoryService
{
public ReservationResult ReserveProducts(Order order) { }
public void ReleaseReservation(Order order) { }
}
public class ShippingService
{
public void PrepareShipment(Order order) { }
public TrackingNumber CreateShipment(Order order) { }
}
2.7.3 メタファ(隠喩)の活用
概念
抽象的すぎて伝わりにくい概念は、身近なメタファで表現することで理解しやすくなる。
例1: デザインパターンのメタファ
[C#]
// Factory(工場)のメタファ
public class CustomerFactory
{
public Customer CreatePremiumCustomer(string name, string email) { }
public Customer CreateRegularCustomer(string name, string email) { }
}
// Observer(観察者)のメタファ
public interface IOrderStatusObserver
{
void OnOrderStatusChanged(Order order, OrderStatus newStatus);
}
// Strategy(戦略)のメタファ
public interface IDiscountStrategy
{
decimal ApplyDiscount(decimal originalPrice);
}
例2: ビジネス概念のメタファ
[C#]
// Pipeline(パイプライン)のメタファ
public class DataProcessingPipeline
{
public void AddStage(IProcessingStage stage) { }
public ProcessingResult Execute(InputData data) { }
}
// Cache(キャッシュ)のメタファ
public class ProductCatalogCache
{
public Product Get(int productId) { }
public void Invalidate(int productId) { }
public void Refresh() { }
}
2.7.4 命名の一貫性チェックリスト
以下のチェックリストを使用して命名の品質を評価せよ:
意図の表現
- 名前を見ただけで何をするか分かるか?
- Why(なぜ)、What(何を)が表現されているか?
- How(どうやって)の詳細は隠蔽されているか?
責務の明確性
- 単一の明確な責務を表現しているか?
- その責務の境界が明確か?
- 責務外のことは含まれていないか?
ドメイン適合性
- ドメインエキスパートが使う用語と一致しているか?
- ビジネス概念を適切に表現しているか?
- 技術的詳細ではなくビジネス価値を表現しているか?
一貫性
- 同じ概念には同じ名前を使っているか?
- 異なる概念には異なる名前を使っているか?
- プロジェクト全体で命名ルールが統一されているか?
発見可能性
- 他の開発者が容易に見つけられるか?
- 推測可能な名前になっているか?
- 略語や暗号的な表現を避けているか?
2.7.5 実践的命名パターン
以下の総合的な比較表を参考に、プロジェクトに適した命名戦略を選択できる:
命名パターンとアンチパターンの比較
基本的な命名パターン
変数・フィールド命名
| パターン | 良い例 | 悪い例 | 理由 |
|---|---|---|---|
| 意図を表現 | customerCount |
count |
何をカウントするかが明確 |
| 型情報を避ける | customers |
customerList |
実装詳細ではなく概念を表現 |
| 略語を避ける | calculatedTotal |
calcTot |
完全な単語で意図を明確に |
| 否定形を避ける | isValid |
isNotInvalid |
肯定的な表現で理解しやすく |
| 文脈を活用 |
name (Customer内) |
customerName (Customer内) |
クラス内では冗長な修飾子不要 |
メソッド命名
| パターン | 良い例 | 悪い例 | 理由 |
|---|---|---|---|
| 動作を表現 | calculateTotal() |
getTotal() |
計算を行うことが明確 |
| 副作用を明示 | updateAndSave() |
update() |
複数の動作があることを明示 |
| 戻り値を示唆 | findCustomer() |
getCustomer() |
nullの可能性を示唆 |
| 質問形を活用 | isEmpty() |
checkEmpty() |
Boolean戻り値を自然に表現 |
| 一貫した動詞 | create/update/delete |
create/modify/remove |
操作の一貫性を保つ |
クラス命名
| パターン | 良い例 | 悪い例 | 理由 |
|---|---|---|---|
| 責務を表現 | CustomerValidator |
CustomerManager |
具体的な責務が明確 |
| 抽象度を統一 | EmailNotificationService |
EmailService |
抽象度レベルを明確に |
| 役割を示す接尾辞 | OrderRepository |
OrderData |
データアクセスパターンを明示 |
| ドメイン用語 | ShoppingCart |
ItemContainer |
ビジネスドメインの用語を使用 |
| 実装詳細を避ける | CustomerRepository |
CustomerDatabase |
実装手法ではなく役割を表現 |
アンチパターンとその対策
典型的なアンチパターン
悪いパターン 改善後
──────────────────────────────────────────────
Manager, Handler 具体的な責務名
data, info, obj 具体的な概念名
temp, tmp, work 一時的でも意図を表現
flag, flg 状態を具体的に表現
process, handle 具体的な動作を表現
i, j, k (ループ以外) 意味のある名前
get/set (副作用あり) 実際の動作を表現
言語別命名規約
| 言語 | クラス | メソッド | 変数 | 定数 | 例 |
|---|---|---|---|---|---|
| C# | PascalCase | PascalCase | camelCase | UPPER_SNAKE |
CustomerService, GetCustomer, customerName, MAX_RETRY_COUNT
|
| Java | PascalCase | camelCase | camelCase | UPPER_SNAKE |
CustomerService, getCustomer, customerName, MAX_RETRY_COUNT
|
| Python | PascalCase | snake_case | snake_case | UPPER_SNAKE |
CustomerService, get_customer, customer_name, MAX_RETRY_COUNT
|
| JavaScript | PascalCase | camelCase | camelCase | UPPER_SNAKE |
CustomerService, getCustomer, customerName, MAX_RETRY_COUNT
|
文脈に応じた命名戦略
レイヤー別命名パターン
プレゼンテーション層
├─ Controller: CustomerController, OrderController
├─ ViewModel: CustomerViewModel, OrderSummaryViewModel
└─ View: CustomerListView, OrderDetailView
ビジネス層
├─ Service: CustomerService, OrderProcessingService
├─ Domain: Customer, Order, Product
└─ Policy: PricingPolicy, DiscountPolicy
データアクセス層
├─ Repository: CustomerRepository, OrderRepository
├─ DAO: CustomerDao, OrderDao
└─ Entity: CustomerEntity, OrderEntity
設計パターン別命名
| パターン | 命名例 | 説明 |
|---|---|---|
| Factory |
CustomerFactory, OrderFactory
|
オブジェクト生成の責務 |
| Builder |
CustomerBuilder, QueryBuilder
|
段階的なオブジェクト構築 |
| Strategy |
PricingStrategy, SortingStrategy
|
アルゴリズムの切り替え |
| Observer |
OrderObserver, CustomerObserver
|
状態変化の監視 |
| Decorator |
LoggingDecorator, CachingDecorator
|
機能の装飾・拡張 |
命名の品質評価チェックリスト
自己評価項目
| 評価観点 | チェック項目 | ⭕ | ❌ |
|---|---|---|---|
| 明確性 | 名前だけで役割が理解できるか | UserValidator |
UserChecker |
| 一意性 | システム内で概念が重複していないか |
EmailSender vs NotificationService
|
EmailSender vs EmailService
|
| 一貫性 | 同様の概念に同様の命名ルールが適用されているか | create/update/delete |
create/modify/remove |
| 簡潔性 | 必要十分な長さか | calculateOrderTotal |
calculateTheOrderTotalAmount |
| 発音可能性 | 声に出して読めるか | customerInfo |
custInfo |
| 検索可能性 | IDEで検索しやすいか | CustomerValidator |
Validator |
チーム評価項目
- ドメインエキスパートが理解できる用語を使用している
- 新しいチームメンバーが名前から役割を推測できる
- コードレビューで名前について質問が出ない
- ドキュメントを読まずにAPIの使い方が分かる
- ユニットテストの名前が自然に決まる
パターン1: 正しい英語文法の適用
プログラミングにおいて、普通の英語の文法規則を適用することで、自然で理解しやすい命名ができる。
SV構造(主語-動詞):自動詞の使用
[C#]
// 正しい例:自動詞の使用
public class Line
{
// 自動詞 + 前置詞の形
public bool IntersectsWith(Line anotherLine) { } // ✓ 正しい
public bool CollidesWith(Shape shape) { } // ✓ 正しい
public bool ConnectsTo(Point point) { } // ✓ 正しい
}
// 間違った例:文法的に不正確
public class Line
{
public bool Intersect(Line anotherLine) { } // × 自動詞なのに目的語を取っている
public bool Collide(Shape shape) { } // × 自動詞なのに目的語を取っている
}
SVO構造(主語-動詞-目的語):他動詞の使用
[C#]
// 正しい例:他動詞の使用
public class OrderProcessor
{
public void ProcessOrder(Order order) { } // ✓ 他動詞 + 目的語
public void ValidateInput(UserInput input) { } // ✓ 他動詞 + 目的語
public Order CreateOrder(Customer customer) { } // ✓ 他動詞 + 目的語
}
// 日本語的発想による間違った例
public class OrderProcessor
{
public void OrderProcess(Order order) { } // × 日本語語順
public void InputValidate(UserInput input) { } // × 日本語語順
}
三人称単数形の注意
[C#]
// 正しい例:三人称単数のsを付ける
public class GeometryChecker
{
public bool ContainsPoint(Point point) { } // ✓ Contains (三人称単数)
public bool IntersectsWith(Line line) { } // ✓ Intersects (三人称単数)
public decimal CalculatesArea() { } // ✓ Calculates (三人称単数)
}
// 間違った例:三人称単数のsがない
public class GeometryChecker
{
public bool ContainPoint(Point point) { } // × Contain (sがない)
public bool IntersectWith(Line line) { } // × Intersect (sがない)
}
自然な英語による命名例
[C#]
// ファイル操作:自然な英語表現
public class FileManager
{
// ファイルが存在するかチェック
public bool FileExists(string filePath) { } // ✓ 自然な表現
// ファイルを削除する
public void DeleteFile(string filePath) { } // ✓ SVO構造
// ファイルをコピーする
public void CopyFile(string source, string destination) { } // ✓ SVO構造
// ファイルが別のファイルと同じかチェック
public bool FileEqualsWith(string file1, string file2) { } // ✓ 自動詞+前置詞
}
// データベース操作:自然な英語表現
public class CustomerRepository
{
// 顧客を見つける
public Customer FindCustomer(int id) { } // ✓ SVO構造
// 顧客が存在するかチェック
public bool CustomerExists(int id) { } // ✓ 自然な表現
// 顧客を保存する
public void SaveCustomer(Customer customer) { } // ✓ SVO構造
// 顧客と関連するかチェック
public bool RelatesTo(Order order) { } // ✓ 自動詞+前置詞
}
パターン2: レイヤー別命名
[C#]
// プレゼンテーション層
public class CustomerController // ~Controller
public class OrderViewModel // ~ViewModel
public class ProductDisplayModel // ~DisplayModel
// ビジネス層
public class OrderProcessingService // ~Service
public class PriceCalculationEngine // ~Engine
public class InventoryManager // ~Manager
// データ層
public class CustomerRepository // ~Repository
public class OrderDataAccess // ~DataAccess
public class ProductDao // ~Dao (Data Access Object)
パターン3: 処理タイプ別命名
[C#]
// 生成・作成
public class OrderBuilder // ~Builder
public class CustomerFactory // ~Factory
public class ReportGenerator // ~Generator
// 変換・処理
public class OrderProcessor // ~Processor
public class DataTransformer // ~Transformer
public class MessageHandler // ~Handler
// 検証・判定
public class OrderValidator // ~Validator
public class EligibilityChecker // ~Checker
public class SecurityGuard // ~Guard
パターン4: 状態・結果別命名
[C#]
// 結果クラス
public class ValidationResult // ~Result
public class ProcessingOutcome // ~Outcome
public class OperationStatus // ~Status
// 設定クラス
public class DatabaseConfiguration // ~Configuration
public class EmailSettings // ~Settings
public class SecurityOptions // ~Options
2.8 AI時代の命名戦略 - プロンプトエンジニアリングとの融合
2.8.1 AIプロンプト設計における命名の重要性
AI時代において、効果的なプロンプト設計は命名技法と密接に関連している。AIに対して明確で具体的な指示を与えるには、ドメイン固有の語彙と適切な抽象化レベルでの命名が不可欠である。
AIプロンプトの命名パターン
従来の「抽象的なプロンプト」から「具体的なドメイン語彙を使ったプロンプト」への変化:
❌ 抽象的なプロンプト例
「データを処理するクラスを作ってください」
「リストを操作する関数を作ってください」
「エラーをチェックする処理を作ってください」
✅ 具体的なドメイン語彙を使ったプロンプト例
「顧客の購買履歴から、リピート購入可能性を分析するCustomerRetentionAnalyzerクラスを作成してください」
「注文の妥当性を検証し、InvalidOrderExceptionをスローするOrderValidatorを実装してください」
「在庫不足の商品を特定し、RestockNotificationを生成するInventoryMonitoringServiceを作ってください」
2.8.2 AIペアプログラミングにおける命名協調
AIとの協調開発では、人間の命名意図をAIに正確に伝える技術が重要になる:
プロンプト設計の命名原則
1. ドメイン固有語彙の明示
[プロンプト例]
「ECサイトで以下のドメイン概念を使用してクラス設計してください:
- Customer (顧客)
- ShoppingCart (ショッピングカート)
- Order (注文)
- PaymentMethod (支払い方法)
- ShippingAddress (配送先住所)
各クラスには、責務を明確に表現するメソッド名を付けてください。
例: PlaceOrder(), AddProductToCart(), ProcessPayment()」
2. 責務分離の指示
[プロンプト例]
「注文処理システムを以下の責務で分離してください:
- OrderValidator: 注文内容の妥当性検証
- PaymentProcessor: 決済処理の実行
- InventoryManager: 在庫の引当と更新
- ShippingService: 出荷指示の生成
- CustomerNotificationService: 顧客への通知
各クラスのメソッド名は、そのクラスがクライアントに提供するサービスを表現してください。」
3. 型安全性の要求
[プロンプト例]
「以下の具体的な型を使用してタイプセーフなコードを生成してください:
- List<Customer> ではなく CustomerCollection
- string ではなく EmailAddress、PhoneNumber
- int ではなく CustomerId、OrderId、ProductId
汎用的な型(object, string, int)ではなく、ドメインを表現する型を使用してください。」
2.8.3 AI生成コードの命名品質向上技法
AIが生成したコードを「美しいコード」に改善するための命名フィードバックパターン:
フィードバック例1: 汎用的な名前の具体化
[AI生成コード]
public class DataProcessor
{
public void ProcessData(List<object> data)
{
foreach (var item in data)
{
if (item != null)
DoSomething(item);
}
}
}
[人間によるフィードバック指示]
「このコードを以下の観点で改善してください:
1. DataProcessor → 具体的なドメイン責務を表現 (例: CustomerAnalyzer)
2. ProcessData → 具体的な処理内容を表現 (例: AnalyzeCustomerBehavior)
3. List<object> → 型安全な具体型を使用 (例: List<Customer>)
4. DoSomething → 具体的な動作を表現 (例: UpdateCustomerSegment)」
[改善後のコード]
public class CustomerBehaviorAnalyzer
{
public void AnalyzeCustomerPurchasePatterns(List<Customer> customers)
{
var activeCustomers = customers.Where(IsActiveCustomer);
foreach (var customer in activeCustomers)
{
UpdateCustomerSegmentation(customer);
CalculateLifetimeValue(customer);
GeneratePersonalizedRecommendations(customer);
}
}
private bool IsActiveCustomer(Customer customer) =>
customer.LastPurchaseDate >= DateTime.Now.AddMonths(-6);
}
2.8.4 AIコードレビューと命名改善
AI時代のコードレビューでは、命名の意図確認が重要なプロセスになる:
AIコードレビュープロンプト例
「以下のコードを命名の観点でレビューしてください:
レビュー観点:
1. 責務が名前に正確に反映されているか
2. ドメイン固有の語彙が使用されているか
3. クライアント視点での命名になっているか
4. 一貫した命名規則が適用されているか
5. 英語文法として正しいか
改善提案も含めて回答してください。」
人間とAIの協調による命名改善フロー
ステップ1: AI初期実装
// AI生成初期版
public class Manager
{
public void Process(object data) { }
}
ステップ2: 人間による意図明確化
「このクラスは顧客の購買データを分析して、
マーケティングキャンペーンの対象顧客を特定する責務を持ちます。
クラス名とメソッド名を、この責務を正確に表現するように修正してください。」
ステップ3: AI改善提案
// AI改善版
public class MarketingCampaignTargetAnalyzer
{
public CampaignTargetResult IdentifyTargetCustomers(CustomerPurchaseData data)
{
// 実装...
}
}
ステップ4: 人間による最終調整
// 最終版
public class CampaignTargetSelector
{
public TargetCustomerGroup SelectTargetCustomers(PurchaseHistoryAnalysis analysis)
{
var eligibleCustomers = analysis.Customers.Where(MeetsTargetCriteria);
return new TargetCustomerGroup(eligibleCustomers);
}
private bool MeetsTargetCriteria(Customer customer) =>
HasRecentPurchase(customer) &&
HasHighLifetimeValue(customer) &&
ShowsEngagementPatterns(customer);
}
2.8.5 AI時代の命名ベストプラクティス
1. AI指示の構造化
効果的なAIプロンプト構造:
┌─ ドメイン文脈の説明
├─ 責務の明確化
├─ 命名規則の指定
├─ 型安全性の要求
└─ 期待する品質レベルの明示
2. 段階的命名改善
命名改善プロセス:
AI生成 → 意図明確化 → 責務分離 → ドメイン語彙適用 → 一貫性確認
3. AI時代固有の命名考慮事項
- プロンプト再現性: 同じプロンプトで一貫した命名が得られるか
- 説明容易性: AIに対して命名意図を説明しやすいか
- 拡張指示性: 機能追加時のプロンプト指示が明確になるか
- 品質評価性: AIによる命名品質評価が可能か
2.8.6 実践演習: AIペアプログラミング命名
演習問題
以下のAI生成コードを、本章で学んだ命名原則を使って改善せよ:
[AI生成初期コード]
public class Manager
{
public void Handle(object input)
{
var result = Process(input);
Save(result);
Notify();
}
private object Process(object data) { return null; }
private void Save(object result) { }
private void Notify() { }
}
解答例
[改善後コード]
public class CustomerOrderProcessor
{
private readonly IOrderValidator _validator;
private readonly IOrderRepository _repository;
private readonly ICustomerNotificationService _notificationService;
public async Task<OrderProcessingResult> ProcessCustomerOrder(Order order)
{
var validationResult = await _validator.ValidateOrderAsync(order);
if (!validationResult.IsValid)
return OrderProcessingResult.ValidationFailed(validationResult.Errors);
var savedOrder = await _repository.SaveOrderAsync(order);
await _notificationService.SendOrderConfirmationAsync(savedOrder);
return OrderProcessingResult.Success(savedOrder);
}
}
🤖 AI時代における本章の重要性
命名によるAI協働の効率化
AI時代において、適切な命名は人間とAIのコラボレーションを劇的に向上させる。AIは文脈を理解してコードを生成するため、良い命名はAIが期待通りの実装を生成する確率を大幅に高める。
AIが理解しやすい命名例
// ❌ AIが混乱しやすい命名
public void Process(object data) { /* AIは何を生成すべきか判断困難 */ }
// ✅ AIが適切なコードを生成しやすい命名
public void ValidateAndSaveCustomerOrder(CustomerOrder order)
{
/* AIはバリデーション→保存の流れを理解し、適切な実装を提案 */
}
AIとのペアプログラミングにおける命名戦略
- 意図明確命名: AIに実装の方向性を伝える
- ドメイン語彙の使用: 業務特有の用語で文脈を提供
- 型情報の活用: ジェネリクスや詳細な型で制約を明示
AI時代の命名は、人間だけでなくAIパートナーとのコミュニケーション手段でもある。
💡 筆者が20年の経験から学んだ教訓
- 曖昧な名前は責務の境界を曖昧にし、設計の劣化を招く。
- 命名の品質がプロジェクトの成功を左右する決定的要因である。
🎯 セルフチェック:命名スキル診断
レベル別診断チェックリスト
レベル1: 基本的命名(初心者)
-
変数名に意味がある(
tmp,dataを使わない) - メソッド名が動作を表している
- クラス名が責務を表現している
- 略語を避けて完全な単語を使用している
- 命名規則(PascalCase/camelCase)を統一している
レベル2: 意図的命名(中級者)
- メソッド名から戻り値の型が推測できる
-
ブール値の命名が適切(
Is...,Has...,Can...) - 例外クラスの名前が原因を示している
- インターフェース名が契約を表現している
- パッケージ/名前空間名が階層を表している
レベル3: 戦略的命名(上級者)
- ドメイン語彙を積極的に使用している
- 境界文脈(Bounded Context)が名前に反映されている
- 利用者視点での命名(SON戦略)を実践している
- 名前の変更に対するリファクタリング戦略がある
- チーム全体での命名ガイドラインを策定・運用している
スコアリング
- 13-15点: 命名マスター(チームの命名リーダーとして活躍可能)
- 10-12点: 命名上級者(個人レベルでは十分、チーム指導も可能)
- 7-9点: 命名中級者(基本は身についている、戦略的命名を学習)
- 4-6点: 命名初級者(意識的な命名練習が必要)
- 0-3点: 命名基礎(命名の重要性から理解を始める)
まとめ
第2章では、命名がプログラミングにおける最も重要な活動の一つであることを学んだ。効果的な命名により、コードは「検証可能な設計モデル」となり、チーム全体でのコミュニケーションが向上する。
重要なポイント
- 命名はモデリング:名前を付けることで概念を確定し、境界を明確にする
- サービス指向:利用者の視点で名前を決定する
- 一貫性が重要:プロジェクト全体で統一されたルールを適用する
- 継続的改善:命名は一度決めて終わりではなく、理解が深まるにつれて改善していく
- 🎯 AI時代の戦略的価値:良い命名はAIとの協働効率を飛躍的に向上させる
- 💪 チーム力の向上:命名規則の統一はチーム全体の技術力底上げに直結する
次章では、この命名の技法を基盤として、「モデリングとしてのプログラミング」について詳しく学ぶ。プログラミングが単なる実装作業ではなく、現実世界をソフトウェアで表現するモデリング活動であることを理解していく。
※ 筆者が書いた「AI時代の美しいプログラムの教科書 〜20年間Microsoft MVPとして教えてきたプログラミング〜」(日本語版) 「Beautiful Programming in the AI Era —20 Years of Teaching Programming as Microsoft MVP—」(英語版) より
※ その他のリクエストは、X (旧Twitter) で @Fujiwo にいただければ幸いです。