皆さん、こんにちは!
TTD-DRは、旧来のAIリサーチエージェントを拡散モデルの考え方をベースに拡張し、より深い考察・柔軟な構成でレポートを作成できるようにした技術です。
今回はTTD-DRの技術検証を行うデモアプリを作るにあたり、いわゆる 「AI駆動開発」(生成AIを全面活用した開発) に挑戦してみました。
この記事ではTTD-DRの技術的な概要と、AI駆動開発を導入した実装で感じたことをご紹介します。
TTD-DRとは? 反復的な全体改善でレポートの質を高めるフレームワーク
今回実装に取り組んだ「TTD-DR (Test-Time Drafter with Diverse Reference)」は、旧来のDeep Researchなどを拡張したAIリサーチエージェント技術になります。
元論文: Deep Researcher with Test-Time Diffusion - Arxiv.org
TTD-DRの特徴
TTD-DRの特徴は、主にエージェント型AI、コンポーネント自己進化、反復的修正プロセスに集約されます。
-
エージェント型AI
最近のトレンドである、自律的に目標達成のため動くAIエージェント機能を搭載
必要な情報を自動判定し、自律的に情報収集を行ってレポートを作り上げる -
各コンポーネントの自己進化
各コンポーネント(部品)で使われているプロンプト自体もタスクに合わせて最適化することで、より効果的な調査が可能となる -
拡散モデルを参考にした反復的全体修正プロセス
最初に大まかな全体構成を作り、段階的に全体をアップデートすることでより一貫性のあるレポートを作成できる- ※拡散モデル: 画像処理などに使われる技術 ノイズの多い画像から徐々に鮮明な画像にアップデートしていくアプローチ
TTD-DRの大まかな仕組み
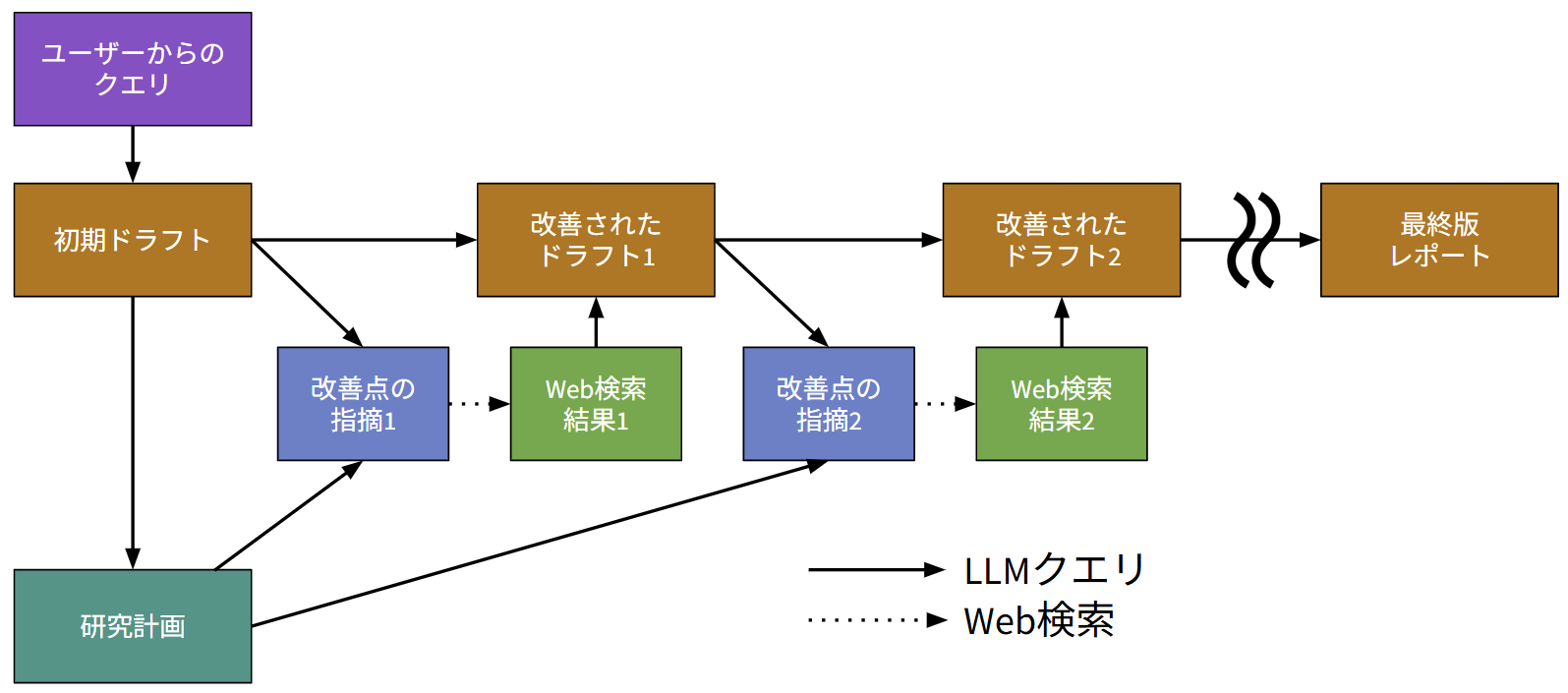
TTD-DRは、ユーザーからの指示を元に、質の高いレポートを生成するためのフレームワークです。そのプロセスは大きく分けて以下のブロックで構成されます。
ステップ1. 初期ドラフトと研究計画の作成:
ユーザーからの情報を受け取り、まずレポートの 初期ドラフト(草案) と、全体の指針となる 研究計画(項目立て) を作成します。
- 初期ドラフト: Web検索を行わず、推論だけで書いたレポート もちろん内容に不完全な部分が多いので後のステップで修正していく
- 研究計画: レポートの項目立て リサーチの基本方針であり、これは今後のステップでも修正しない
ステップ2. 研究計画に沿った反復的な改善:
全体修正のサイクルを回し、レポートをブラッシュアップしていきます。
- 改善点の指摘: 現状のドラフト全体と研究計画を生成AIに提示し、まずどこを修正すべきか指示を受ける
- 関連情報の収集: 指摘された内容に基づき、Web検索を行う
- 全体の更新: 集めた情報を元に、ドラフトをアップデートする
このサイクルを繰り返すことで、レポートがどんどん改善されていきます。
コンポーネントの自己進化:
各タスク(ドラフト作成、情報収集のクエリ作成など)に使用するプロンプト自体も、自己進化プロセスで随時アップデートします。
- 改善点の指摘: 現在のプロンプトとユーザーからの情報を生成AIに渡し、改善点を洗い出してもらう
- プロンプト候補の作成: 改善点を元に、プロンプトの改善案を複数生成する
- プロンプト改善候補の評価: それぞれの候補をLLMに評価させる
- クロスオーバー: それぞれの改善案の良いところを合わせて一つの改善版プロンプトを出力する
…こうすることで、よりそのタスクのドメインに適合したプロンプトを使うことが可能になる

既存技術との比較:メリットとデメリット
メリット
- 調査途中の疑問にも対応可能: 最初に調査項目を決めてしまう直線的な手法(例: GPT Researcher)と違い、反復プロセスの中で新たに生まれた疑問や深掘りしたい点にも柔軟に対応できます
- 論理的な一貫性の維持: 毎回ドラフト全体を見直してアップデートするため、セクションごとに修正する他の手法(例: Open Deep Research)に比べて、レポート全体の一貫性・整合性が失われにくいという利点があります
デメリット
- 高コスト・長時間: 各ステップで何度も生成AIに問い合わせるため、時間とコストがかかります
- 初期計画のズレ: 最初に立てた研究計画は変化しないため、実情と大きく異なると修正が難しいという課題があります
- 出典の不明確さ: 全体を更新するため、どの情報がどこに影響したのかが分かりにくくなる(=出典がわからない)という欠点もあります
TTD-DR技術の各部についての考察
最初に初期ドラフトと研究計画を分ける理由:
TTD-DRでは修正サイクルにおいて毎回全体を修正していきます。これは論理的な一貫性を保持するために非常に有効ですが、それだけでは方向性が定まらずあまり重要でない部分を過剰に深掘りしたりして、求めているレポートと異なるものを出力してしまう可能性も同時に生まれます。
そこで研究計画という項目立てを置くことで、当初の目的から逸脱しないようコントロールしていると考えられます。言ってみればチームを統括するPMのような役割でしょうか。
検索する情報源について:
論文内では情報を補強する手段としてWeb検索を行っていましたが、理論的には情報源はなんでもいいと考えられます。
そこで今回のデモアプリではWeb検索に加え、ベクトルデータベース検索も選択できるように設計しました。
初期設定とのズレ:
前述の通り最初に推論で設定した研究計画は最後まで変わらないので、最初に行った予想が大きく外れているとそれに囚われてレポートが不自然な形になったりする可能性もあります。
研究計画はガイドラインなのであまり頻繁に変えては本来の意味が失われると思いますが、それでも得られた情報により変える必要があると判断すれば変更できるような仕組みにした方がいいのかもしれません。
ただ、それらを比較したデータは論文中に見当たりませんでした。
その他:
それ以外にも、論文に明記されていない技術的な課題がいくつかあり、
- 最初の各コンポーネントのプロンプトをどうやって用意するか
- 同じ改善点から改善案を作るとあまり差がないのでどうやってばらけさせるか
- 反復的改善過程で、過去に調べたデータはどの程度保持するか(回数が増えると検索情報全て保持しておくと差し障りが出るかもしれない)…など
これらは開発者が実際に触りながらチューニングしていくべき課題かもしれません。
TTD-DR技術の応用
この技術は論文執筆やレポート作成などを想定して作られているようです。
しかし技術自体はシンプルなので、それ以外の分野にも応用が出来そうです。
- 資料の修正や、提案書作成などにも使えそう
- Web検索をベクトル検索に変えることで、自社資料を活用することもできそう
- これは今回の実装で実際にやってみました
- 時間・コストがかかるため、それが問題とならないような分野に向いている
- 研究分野・法律分野など、高い正確さが求められるがリアルタイム性はそれほど重要ではない分野など
生成AIを駆使した開発プロセス:アジャイル寄りな生成AIコーディング
今回は、生成AIを全面的に活用して開発を進めました。
今までもGitHubなどのコーディング補助ツールなどは使っていましたが、今回は論文読解と計画立て・雛形の作成・モックアップUIなど、ほぼ全工程にわたって生成AIを活用しました。
(今回の記事では、実際にどのようなシステムを構築したかではなく、生成AIを活用した開発過程についてレポートします)
開発体制
自分(エンジニア)一人で読解から開発まで行いました…
活用したAIツール
- 翻訳: DeepL
- 論文読解: Gemini, Deep Research
- UI作成: Gemini
- コーディング支援: Gemini, GitHub Copilot
システム構成
- クラウドプラットフォーム: Google Cloud
- フロントエンド・バックエンドシステム基盤: Cloud Run
- ベクトルデータベース: Vertex AI Search
- オブジェクトストレージ: Google Cloud Storage
- LLM API: Gemini API
開発フロー
-
論文の理解: まず、GeminiとDeep Researchを使ってTTD-DRの論文を読み込み、そのロジックについて対話形式で質問を重ね、理解を深めました。
※今回は対話だけではなく、DeepLで翻訳した論文自体にも目を通しています。

- フロントエンド開発: GeminiでモックアップUIを生成。そのコードをGeminiに渡し、バックエンドサーバー(Python Flaskベース)と連携できるように修正を依頼しました。細かな修正はGeminiからの提案に従って行いました。
- バックエンド開発: Cloud RunとVertex AI Searchをメインに構成しました。ここではロジックを自分でしっかり把握したかったため、Geminiに大まかな構成を伝えて 関数の骨組み(I/Oのみ) を作成してもらい、各関数の具体的な処理はGitHub Copilotの支援を受けながら自分で組み込みました。またパッケージ的な関数(GCSへのアップロード、Web検索など)はGeminiに質問して組んでもらった部分もあります。

- クラウド環境構築: これに関しては(自分が慣れていたので)生成AIの手はほぼ借りませんでしたが、あまり知識がなくても今回やりたいことを相談すればサービス構成やその操作方法などを案内してくれると思います。
苦労したこと
ハルシネーション:
最初の論文読解では大まかな内容を斜め読みした際の先入観にとらわれていたため、Geminiの説明を自分の予想の方に誘導してしまったのが良くなかったです(Geminiもこちらの質問に誘導されて曲解してしまっていた)
その結果、コンポーネントの自己進化がなく、なぜかドラフトの修正過程に自己進化を導入する…というロジックになってしまい、それっぽかったので実装を進めてしまいました(途中で誤りに気付いた)
- 対策: ソースを随時チェックさせること(論文中に根拠があるかどうかの確認)、そして 定期的にチャットをリセットする(新しい会話に移行する) ことが有効なようです。
後からの大幅な仕様変更の難しさ:
途中で「進捗をストリーミング表示したい」という仕様変更をGeminiに丸投げしたところ、変更が大規模だったためかコードが全く動かなくなってしまいました。その後対話で問題点を尋ねて修正しようとしたのですが悪化する一方…
おそらくGeminiでも一度に考えられるデータ量に限界があるため、コードが複雑・大規模になった状態からさらに全体に及ぶような修正をするのは難しいのかもしれません。
- 対策: 結局、一度元に戻し、やり方を教わりながら手動で機能を追加しました。こんな風に、AIに任せきりにせず人間が主導権を握るべき場面も未だあるようです。
- あるいはこの場合、一度現在の実装範囲を仕様に戻して、改めて一から生成させた方が速かったかもしれないとも思います。
まとめ: 生成AI開発の可能性と今後の展望
今回の経験を通じて、開発スピードにおいて生成AIは間違いなく手動を上回ると感じました。特に、コード全体を読み込ませて整合性を見ながらアドバイスをもらえる点は大きな魅力です。
開発スタイルとしては、まず動くものを作り、そこから機能追加やフィードバックを通じた修正を重ねていくという意味でアジャイル開発に近い形で進めることが出来ました。仕様が固まっていない実験的な段階では、このアイデアを随時反映できる柔軟性は大きな武器になります。
一方で、AIに任せきりにしてしまうことでどんどんエンジニアが理解を放棄し、最終的に何をやっているのか人間が全く理解できなくなってしまうリスクもあると思います(言ってみれば、人間が開発エンジニアではなく営業の立場になってしまう)
これはつまり、ノーコードツール(最近ブームが下火になってきた気がする)などと同様に、エンジニアが手を加えたくても限られた範囲でしか触ることが出来ない、という状況が生まれる気がします。
(概念的にはベンダーロックインなどに近いのかもしれない)
まだまだ生成AIによる開発が完璧とは呼べない今、 「人間がどこまでを握り、どこからをAIに任せるか」 というバランス感覚を養うことが生成AI時代のエンジニアにとって重要なスキルになると感じました。
今回は一人で行っていた開発過程の一部を任せる形で生成AIを取り入れてみましたが、もっと効果的な形で取り入れる、あるいは複数人での開発への導入など、まだまだ試していない世界があると思っています。
次回以降は、コーディング全体を任せられるスタイルのClaude Codeなど、新しいツールにもどんどん挑戦していきたいと考えています。
最後までお読みいただき、ありがとうございました!