はじめに
optunaフレームワークを用いて分類機のハイパーパラメータチューニングを行いハイパーパラメータチューニングの流れをざっくり把握します。
doc
github
フレームワークのインストール
!pip -q install optuna
本記事の実装は以下の公式の実装例を参考にしてます。
https://github.com/optuna/optuna-examples/blob/main/pytorch/pytorch_simple.py
モデルは多層パーセプトロンによるFasionMNIST分類機をpytorchで作成してます。
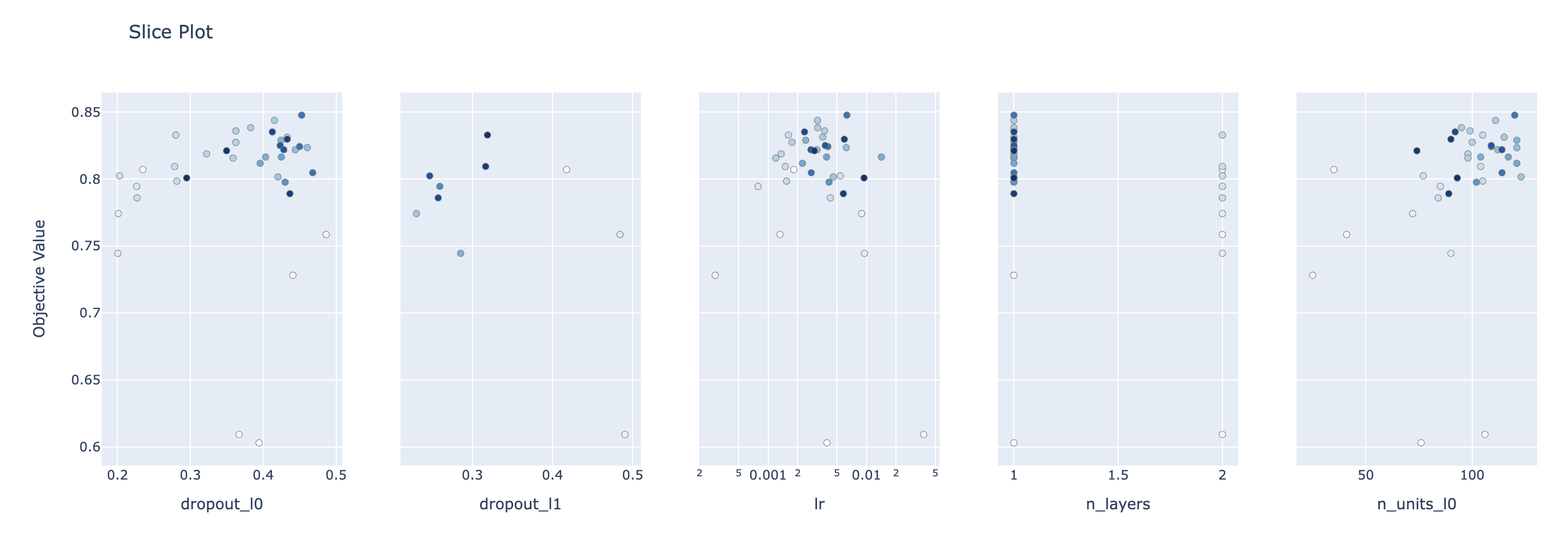
optunaによって以下のハイパーパラメータを最適化してます。
- 層の深さ
- 各層のノード数
- ドロップアウト率
- 最適化手法の種類(Adam, RMSprop, SGD)
- 学習率
ハイパーパラメータの探索
必要なライブラリのインポート
import os
import optuna
from optuna.trial import TrialState
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data
from torchvision import datasets
from torchvision import transforms
各種グローバル変数の定義
DEVICE = torch.device("cpu")
BATCHSIZE = 128
CLASSES = 10
DIR = os.getcwd()
EPOCHS = 10
LOG_INTERVAL = 10
N_TRAIN_EXAMPLES = BATCHSIZE * 30
N_VALID_EXAMPLES = BATCHSIZE * 10
モデルの定義
trial.suggest_intやtrial.suggest_floatなどで検証するハイパーパラメータを指定しています。
def define_model(trial):
n_layers = trial.suggest_int("n_layers", 1, 3)
layers = []
in_features = 28 * 28
for i in range(n_layers):
out_features = trial.suggest_int("n_units_l{}".format(i), 4, 128)
layers.append(nn.Linear(in_features, out_features))
layers.append(nn.ReLU())
p = trial.suggest_float("dropout_l{}".format(i), 0.2, 0.5)
layers.append(nn.Dropout(p))
in_features = out_features
layers.append(nn.Linear(in_features, CLASSES))
layers.append(nn.LogSoftmax(dim=1))
return nn.Sequential(*layers)
学習データの定義
def get_mnist():
train_loader = torch.utils.data.DataLoader(
datasets.FashionMNIST(DIR, train=True, download=True, transform=transforms.ToTensor()),
batch_size=BATCHSIZE,
shuffle=True,
)
valid_loader = torch.utils.data.DataLoader(
datasets.FashionMNIST(DIR, train=False, transform=transforms.ToTensor()),
batch_size=BATCHSIZE,
shuffle=True,
)
return train_loader, valid_loader
ハイパーパラメータ検証手順の定義
ハイパーパラメータを検証する1サイクルの定義。1組のハイパーパラメータの組み合わせに対して以下の関数内で定義された手順を行い、組み合わせを評価する。
trial.suggest_categoricalを用いて検証する最適化手法を指定してます。
def objective(trial):
# モデルを作成
model = define_model(trial).to(DEVICE)
# オプティマイザを作成
optimizer_name = trial.suggest_categorical("optimizer", ["Adam", "RMSprop", "SGD"])
lr = trial.suggest_float("lr", 1e-5, 1e-1, log=True)
optimizer = getattr(optim, optimizer_name)(model.parameters(), lr=lr)
# データセット取得
train_loader, valid_loader = get_mnist()
# モデルを訓練
for epoch in range(EPOCHS):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# 高速化のため訓練データ数を制限
if batch_idx * BATCHSIZE >= N_TRAIN_EXAMPLES:
break
data, target = data.view(data.size(0), -1).to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
# モデルの検証(validation)
model.eval()
correct = 0
with torch.no_grad():
for batch_idx, (data, target) in enumerate(valid_loader):
# 高速化のためため検証データ数を制限
if batch_idx * BATCHSIZE >= N_VALID_EXAMPLES:
break
data, target = data.view(data.size(0), -1).to(DEVICE), target.to(DEVICE)
output = model(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
accuracy = correct / min(len(valid_loader.dataset), N_VALID_EXAMPLES)
# epoch終了時点での正答率をもとにハイパーパラメータの検証を打ち切るか判断する
# https://optuna.readthedocs.io/en/stable/reference/generated/optuna.trial.Trial.html?highlight=report#optuna.trial.Trial.report
trial.report(accuracy, epoch)
if trial.should_prune():
raise optuna.exceptions.TrialPruned()
return accuracy
ハイパーパラメータ検証の実行
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=100, timeout=600)
pruned_trials = study.get_trials(deepcopy=False, states=[TrialState.PRUNED])
complete_trials = study.get_trials(deepcopy=False, states=[TrialState.COMPLETE])
print("Study statistics: ")
print(" Number of finished trials: ", len(study.trials))
print(" Number of pruned trials: ", len(pruned_trials))
print(" Number of complete trials: ", len(complete_trials))
print("Best trial:")
trial = study.best_trial
print(" Value: ", trial.value)
print(" Params: ")
for key, value in trial.params.items():
print(" {}: {}".format(key, value))
実行結果
Study statistics:
Number of finished trials: 100
Number of pruned trials: 62
Number of complete trials: 38
Best trial:
Value: 0.84765625
Params:
n_layers: 1
n_units_l0: 120
dropout_l0: 0.45274406131527256
optimizer: Adam
lr: 0.006311944229638178
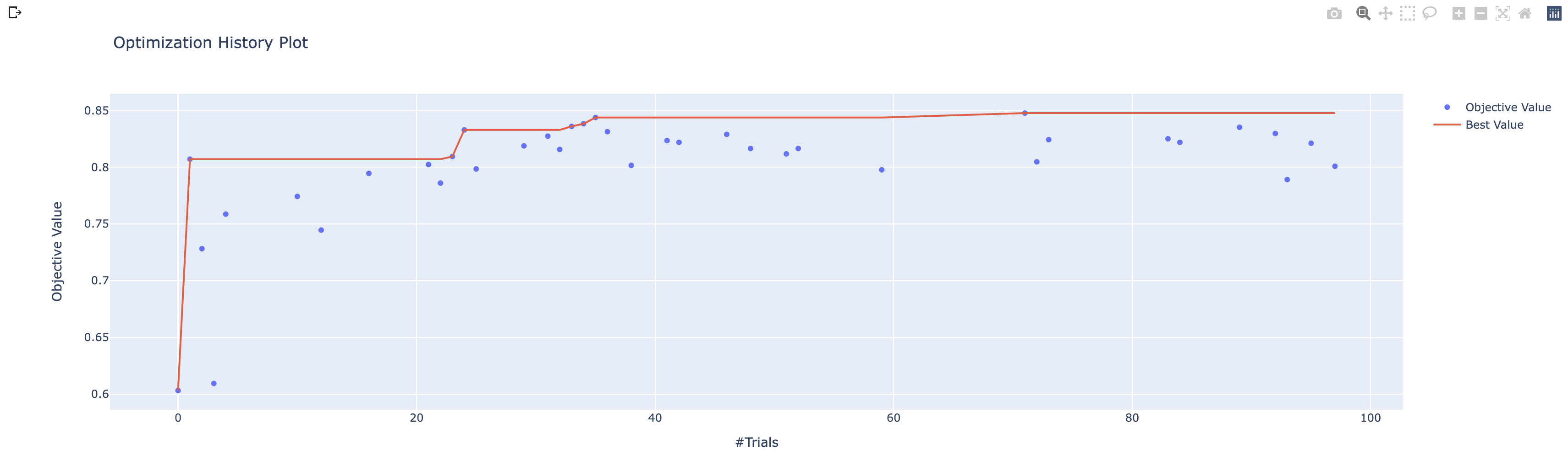
最終的な正答率は84%ほどでした。層の深さは入力層と出力層の2層が最適なのは意外。
探索結果の可視化
ハイパーパラメータ探索の履歴や各パラメータの探索の様子を簡単に可視化できます。
以下の公式doc参考に今回の探索の様子を可視化してみました。
モジュールのインポート
可視化に必要なモジュールを追加でインポート
from optuna.visualization import plot_contour
from optuna.visualization import plot_edf
from optuna.visualization import plot_intermediate_values
from optuna.visualization import plot_optimization_history
from optuna.visualization import plot_parallel_coordinate
from optuna.visualization import plot_param_importances
from optuna.visualization import plot_slice
探索中の精度の推移
探索によってモデルの精度が推移している様子が可視化できる。
plot_optimization_history(study)
探索されたハイパーパラメータと精度の散布図
plot_slice(study)