1.概要
前回の続きで、JPXのHPに公開されている投資部門別株式状況のexcel/csvファイルをpandas(read_excel()ないしread_csv())で参照してデータフレームオブジェクトを生成して夕凪氏がツイートしてるように集計するネタをもう少し考察し拡張していこうと思う。
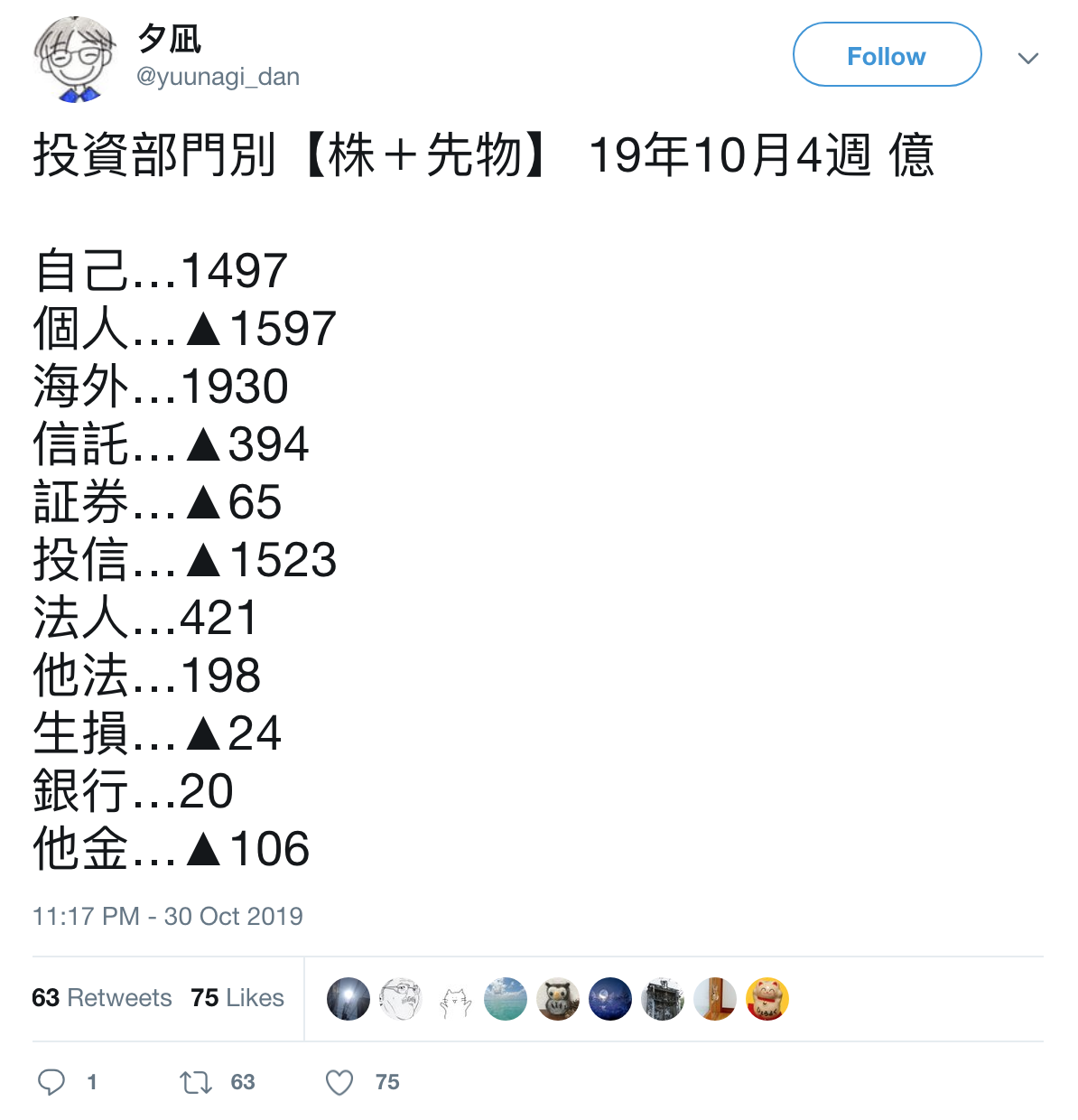
例えばpandasでデータフレームオブジェトを生成したら、それを元にmatplotlibでグラフ描画するのがpyDataの大体の処理の流れだと思うが、matpoltlibでグラフ描画する前に、一旦それをHerokuのadd-on「Heroku Postgres」を用いてHerokuのPostgresqlのDBに用意したtableに、pandasのto_sql()でデータ保存するようにしてはどうだろうか?
それは、一つは現物株式と先物株式とJPXのHPでは別々の統計資料として公開されているものをUNIONしてデータをワンセットで扱えるようにしたいというのと、もう一つは過去分も蓄積するようにすれば、経年比較が可能になるというのがある。そのためにインターネット上で接続可能なクラウド上のDBを利用しませふ!というのが今回の記事で述べたい点である。
matplotlibでグラフ描画する際に、pandasのread_sql()でHeroku Postgres(Herokuのpostgresqlのデータベース)を参照するようにすれば、例えば外国人投資家の東証での売買状況を経年比較するグラフも描画可能だし、現物株式と先物をワンセットで扱うことが可能なので、夕凪氏のツイートのような数字集計したものをグラフ描画可能になるのではないかと思われる。
なお今記事では、Heroku Postgresを利用するが、これは当然ながら別のクラウドDBでもOKで、Amazon RDSでもGoogleのBigqueryでも可。自分が貧乏性で、Heroku Postgresのhobby利用が10000レコードまでなら無料で利用可能であり、単純に自分お金無いからなるべく課金したくないだけなので、お金持ってはる人は別にHerokuのPostgresのhobby以上のバージョンに月額課金してもよいし、あるいはAmazonのRDSやGoogleのBigQueryに課金してもよいし、自分のお小遣いと相談して、お好きなクラウドサービスを利用すると良いかと。
2.HerokuのpostgresqlのDBに接続しデータを保存するPython(pandas)スクリプト
import pandas as pd
import sqlalchemy
from sqlalchemy import create_engine
import numpy as np
# DB接続設定文字列
dbuser='hogehoge_user'
dbpwd='fugafuga_password'
hostname='hogehoge_hostname'
dbname='fugafuga_database'
CONNECT_INFO = 'postgres://{p1}:{p2}@{p3}:5432/{p4}'.format(p1=dbuser, p2=dbpwd, p3=hostname,p4=dbname)
engine = sqlalchemy.create_engine(CONNECT_INFO, encoding='utf-8')
# (中略)
### to_sql() ###
df.to_sql('tbleqty_temp', engine, if_exists='append', index=False)
・上記スクリプト例の「CONNECT_INFO」の文字列は、herokuのadd-on「heroku postgres」の管理画面から「Database Credentials」のsettings欄の各DB設定情報(dbuser,dbpassword,hostname,port,dbname)を参照、もしくはURIの文字列をそのままコピペでも可
・PostgreSQLのportはデフォルトで5432で通信する
・pythonではformat()で文字列に各引数をセットする書き方ができる
・sqlalchemyでherokuの自分のpostgresqlのDBに接続して、pandasのto_sql()でdfデータフレームを任意のテーブル(temptbl)に保存する
・後述のpostgresqlのDB上にストアドプロシージャを作成して、tempテーブルからmasterテーブルにデータを格納していく。なぜストアドプロシージャを利用するかというと、既に格納したレコードは格納せず、新規レコードのみをテーブルに格納するため。この既に格納したレコードを格納せずスキップして、新規レコードのみ格納する行程は、上流工程のpython(pandas)で処理してもOKだが、今回のように下流のDB、ストアドプロシージャで処理しても可かと(...なのだが、自分は個人的には下流のDB側のストアドプロシージャで処理させた方がいいのではないかと思っている)
3.PostgresqlのDBにてストアドプロシージャを実装していく
3-1.ストアドプロシージャの利用可能なPostgresqlのバージョンについて
Postgresqlでストアドプロシージャが利用できるのは、postgresql11以降のバージョンからであり、それ以前のバージョンのPostgresqlではストアドプロシージャは利用不可能、その代わりにストアドファンクションが利用可能とのことである。今回利用するHeroku postgres(postgresqlのデータベース)は、以下のSelect文でバージョンを確認すると、「11.5」と出てきたので、Heroku postgresではストアドプロシージャが利用可能というのがわかる。
SELECT version();
なお自分はHerokuのpostgresqlのDB環境に接続するクライアントツールとして、「DBiever」を使っている。(以前にHeroku Postgresについて調べた記事を参照)。DBクライアントツールとしては、例えばOracleのSQL Developerとか、MicrosoftのAzure DataStudioなど他にいろいろ無償のツールはあるので、自分の好きなDBクライアントツールを選べばよいかと思う。
3-2.PostgresqlのDBでスキーマの定義:create table
投資部門別株式状況のデータは、現物株と先物の2系統の情報を格納するので、テーブルを各々現物株用と先物用と格納テーブルを用意しておく。また今回扱うデータは週次更新で、逐次更新しテーブルに蓄積していく運用なので、モレなくダブリなくテーブルに蓄積保存していきたいので、pansasのto_sql()で保存するデータを一旦「tempテーブル」に保存するようにして、また別に保存用テーブル「masterテーブル」を用意しておいて、あとでストアドプロシージャでtempテーブルからmasterテーブルに新規データのみを保存格納するような処理をするようにして、masterテーブルにデータが蓄積されるようにしておく。
----eqty:現物株式格納用テーブル群(temp/master)
--pandas.to_sql()で一時的に格納するためのテーブル
CREATE TABLE public.tbleqty_temp (
clsid int8 NULL,
clsname text NULL,
bysl text NULL,
vle text NULL,
prd text NULL,
ymw int4 NULL,
unit text NULL,
mkt text NULL
);
--masterテーブル(tempテーブルからモレなくダブリなく格納するためのテーブル)
CREATE TABLE public.tbleqty_master (
clsid int8 NULL,
clsname text NULL,
bysl text NULL,
vle text NULL,
prd text NULL,
ymw int4 NULL,
unit text NULL,
mkt text NULL,
invalid int4 NULL DEFAULT 0,
lastupdatedatetime timestamp NULL DEFAULT CURRENT_TIMESTAMP,
rid serial NULL
);
tempテーブルは、pythonスクリプトでpandasのto_sql()を実行すると、接続したpostgresqlのDBにテーブル生成されるので、何もわざわざDBieverでDB接続してcreate_table文を実行しなくてもテーブル生成は可能といえば可能。
またmasterテーブルの方は、select * into mastertable from temptableを実行すればほぼテーブルの骨格部分が生成可能で、というのもmasterテーブルとtempテーブルは、上記のケースでは構造をほぼ同じ形にしているので、それプラスアルファでtempテーブルにはないがテーブル管理上あったほうがいい列を数列追加している。
masterテーブルに追加した列は、以下の3つ↓
| テーブル追加列名 | 列の型 | デフォルト値 | 説明メモ |
|---|---|---|---|
| invalid | int型(int4) | 0 | 論理削除用。invalid列の値が0がデフォルト値として、無効なレコードはinvalid列の値を1に更新して論理削除ができるようにしておく。基本レコードの物理削除(delete table)は行わない方向で。 |
| lastupdatedatetime | datetime型 | CURRENT_TIMESTAMP | 更新日時を格納しておく。デフォルト値は「CURRENT_TIMESTAMP」で、テーブルにレコードが挿入されたら、postgresqlのシステム日時関数で挿入時の日時が格納されるようにしておく。 |
| rid | serial型 | 列の型はserial型を指定して、レコードが挿入されたら逐次オートナンバーでレコードが一意に決まるようなIDが付与されるようにしておく。 |
あとpostgresqlを初めて触って気づいた点というか後学的な観点からの備忘メモを1点。列名に大文字を含めると、基本小文字の列名と区別して別の列と認識してしまうっぽい(正確にはダブルクォーテーションで囲む大文字は小文字の列と別の列と識別する模様)。で、上記のケースでは当初列名に例えば「ID」とか大文字にして列名命名したのだが、あとでselect文とか書く際にその列は存在しない的なエラーが出てきて、つまりはダブルクォーテーションで囲うとか大文字小文字を識別すると行ったpostgresqlならではの挙動と言うかクセ?というかそういうものがpostgresqlにはあるようなので、最終的には列名テーブル名等は全て小文字で統一して、そもそもダブルクォーテーションで囲うシチュエーションそのものをなくして、いらざるエラーに遭遇しないようにしたのが1点。
あと先物データ格納用のテーブル(temp/master)のスキーマは以下のcreate table文↓
----drvs:先物データ格納用テーブル群(temp/master)
--temptable
CREATE TABLE public.tbldrvs_temp (
drvtsid int8 NULL,
unit int8 NULL,
sycl int8 NULL,
ymw int8 NULL,
prdstart int8 NULL,
prdend int8 NULL,
clsid int8 NULL,
clsname text NULL,
drvname text NULL,
bysl text NULL,
vle int8 NULL
);
---mastertable
CREATE TABLE public.tbldrvs_master (
drvtsid int8 NULL,
unit text NULL,
sycl int8 NULL,
ymw int8 NULL,
prdstart int8 NULL,
prdend int8 NULL,
clsid int8 NULL,
clsname text NULL,
drvname text NULL,
bysl text NULL,
vle int8 NULL,
invalid int4 NULL DEFAULT 0,
lastupdatedatetime timestamp NULL DEFAULT CURRENT_TIMESTAMP,
rid serial NULL
);
現物株格納用テーブルと同様に、先物データ格納用テーブルのmasterテーブルにも、invalid列、lastupdatetime列、rid列の3つの列を追加(alter table)しておく。
ただ本音を言えば、わざわざtempテーブルを用意している点がもう少し修正工夫の余地があるとは思っていて、masterテーブル1個で済むならそれが一番いいのだが、現状ではこのtemp/masterテーブル方式が自分の中では最適解である。
例えば、格納テーブルにユニーク制約を付与して、python側でデータフレームオブジェクトを1件ずつforループでto_sql()を実行して、重複レコードの場合は、ユニーク制約エラーで引っ掛けて、try...exceptでデータが既存のレコードの場合にexceptで逃して的な記述をするやり方もあるにはあるのだが、 わざわざデータオブジェクト全体を一括でto_sql()で格納できるのに、forループでdfオブジェクトを1行ずつ取り出してto_sql()を繰り返すのがなんだかなーと思うのが1点。
※参考:ねりんぷろさんのブログ記事
(DBテーブルのunique制約とpandasのto_sql()を併用した更新方法について)
https://nerimplo.hatenablog.com/entry/2018/07/18/220000
あと重複するかどうかを1件ずつテーブルのユニーク制約に引っ掛けて、引っかからなかったレコードだけをto_sql()の処理が成功し、ユニーク制約に引っかかったものはexcept句でスルーさせる考え方は、ある意味テクニカル的にひとひねりしたアイデアだなーとは思うものの、DB側のテーブルのユニーク制約を設定することで処理のパフォーマンスが遅くならないかなー?と思うのが1点と。重複するかどうかをユニーク制約に引っ掛ける分だけ処理が遅くなりそうで、それならばまずはtempテーブルに一括でpython側でpandasのto_sql()でひとまず格納しておいて、データが重複する既出のデータなのか?新規のデータなのか?を判断するのはDB側にお任せした方が(つまりtempテーブルとmasterテーブルをleft outer joinで結合して、新規レコードのみをInsertでmasterテーブルに格納する、ユニーク制約に引っかからないレコードのみをあらかじめ抽出して格納するようなストアドプロシージャを用意しておけばテーブルにユニーク制約も設けなくてもいいし)良くなくね?というのがこの記事で今回一番述べたかった点あり、**「まあHeroku postgresはバージョンが11以降だし、ストアドプロシージャが利用可能なので、Python(pandas)側でいろいろ頑張らずに、herokuのpostgresqlのDBのストアドプロシージャーに処理を丸投げしようや」**というのが自分の見解である。
3-3.PostgresqlのDBでストアドプロシージャを作成する:create proc
CREATE OR REPLACE PROCEDURE public.sp_impdata()
LANGUAGE sql
AS $procedure$
--equity
insert into public.tbleqty_master(
clsid
, clsname
, bysl
, vle
, prd
, ymw
, unit
, mkt
--invalid
--lastupdatedatetime
)select x.clsid
, x.clsname
, x.bysl
, x.vle
, x.prd
, x.ymw
, x.unit
, x.mkt
--, y.clsid
from public.tbleqty_temp x
left outer join public.tbleqty_master y
on x.clsid=y.clsid
and x.ymw = y.ymw
and x.mkt = y.mkt
and x.bysl = y.bysl
where y.clsid is null;
--derivetives
insert into public.tbldrvs_master(
drvtsid
, unit
, sycl
, ymw
, prdstart
, prdend
, clsid
, clsname
, drvname
, bysl
, vle
)
select x.drvtsid
, x.unit
, x.sycl
, x.ymw
, x.prdstart
, x.prdend
, x.clsid
, x.clsname
, x.drvname
, x.bysl
, x.vle
from public.tbldrvs_temp x
left join public.tbldrvs_master y
on x.drvtsid = y.drvtsid
and x.ymw = y.ymw
and x.clsid =y.clsid
and x.bysl = y.bysl
where y.drvtsid is null;
--あとしまつ
truncate table public.tbleqty_temp restart identity;
truncate table public.tbldrvs_temp restart identity;
$procedure$
;
・postgresqlのストアドは、他のOracleのPL/SQLやMSSQLのストアドプロシージャと若干違っている点があって、language句でどの言語で記述するかを指定する箇所がある模様。でもって、指定できる言語は「sql、pltcl、plpgsql、c」の4つである。
・今回実装するストアドは、簡単なSQLコマンド(SELECT文とInsert文、あとtruncate tableくらい)なので、langrageは「SQL」を指定した。ひょっとしたら「plpgsql」でもOKだったかもしれないが...
・多分begin...endのブロック記述をしようと思うと、langrage「SQL」ではダメで、「plpgsql」を指定しないといけないのかもしれないが、カーソルで1件ずつforループで回してfetch()みたいなことをしないので(←大昔にoracleのPL/SQLに少し触った際の記憶というかイメージで述べている)、「plpgsql」は今回は見送り。
・上記ストアドでの処理でのポイントは1つ。tempテーブルにはpython(pandas)側でto_sql()でデータが一括格納されているので、tempテーブルとmasterテーブルをleft outer join(tempが主、masterが従)で結合して、tempテーブルに存在してmasterテーブルに存在しないレコードを抽出している。
・なおtempテーブルとmasterテーブルをjoinする際のon句、つまりデータを一意になるように結合する条件は、現物株の方が、clsid列(投資部門所ID、自己売買や銀行、証券、外国人投資家などを識別するID)、ymw(年月週、データの時点)、mkt(東証1部とか2部、、ジャスダックやマザーズなどの市場を表すID)、あとはbysl(売買種別、「買い」のデータか「売り」のデータかを識別)の4つである。
また先物データのjoin条件のon句も4つで、、drvtsid(nk225やtopixなどの先物商品を識別するID)、
clsid列(投資部門所ID、自己売買や銀行、証券、外国人投資家などを識別するID)、ymw(年月週、データの時点)、bysl(売買種別、「買い」のデータか「売り」のデータかを識別)の4つである。
・masterテーブルに列追加した3つの列(invalid列、lastupdatedatetime列、rid列)は、Insert文に含めなくても、デフォルトで、invalid列には0が、lastupdatedatetime列には格納時点の日時、rid列にはオートナンバーで一意に定めるためのID値がセットされる。
・株式(現物株)データを格納するテーブル「tbleqty_master」、先物データを格納するテーブル「tbldrvs_master」に対して新規レコードをInsert処理を実行したら、最後にtempテーブルをtruncate tableで空にして、後始末をしておく。次のストアド実行時にto_sql()でJPXのexcel/csvファイルのデータを一時格納できるようにしておく。
・今回はUPDATE処理は割愛している。前回格納データで値が変わっている場合があるので、本来はUpdate処理を入れるべきであるが、その場合は、masterテーブルにinvalid列(デフォルト値は0)を用意してあるので、例えば記述のレコードの場合は、invalid列の値を1に更新して論理削除した上でInsert処理をするようなイメージでストアドプロシージャを実装すればよいかと。
なお一応postgresqlには**upsert()**という「既存のレコードはUpdate、新規レコードはInsert」と言う便利なSQLコマンドがあるようなので、tempテーブルとmasterテーブルをleft outer joinで結合するのではなく、tempテーブルからmasterテーブルへの格納時に、そのUpsert()を用いるという案もあるかもしれないが、なんにせよこのDB側で「モレなくダブリなく」レコードを格納し蓄積する話は、もう少し方法について後日考える余地がある。
3-4.postgresqlのストアドプロシージャをDBieverで実行する
call public.sp_impdata()
自分仕事ではMSSQL(SQLServer)を使っているが、postgresqlのストアドプロシージャを実行するには、call()でストアド実行するのが留意点その1であり、MSSQLでストアドプロシージャを実行する場合は、CALL関数ではなくEXEC関数で実行している点があれ。自分の記憶が確かならば、MySQLも確かストアドプロシージャの実行はCALL()だったかと思...
それとMSSQLで例えばストアドプロシージャ「sp_impdata」を実行する場合、
exec public.sp_impdata
というように、exec関数でストアドを実行する点と、もう一つ。MSSQL(t-sql)では、ストアドプロシージャ名の後ろにカッコが付いていないので、postgresqlのDBで最初ストアドを実行しようとしてストアドプロシージャ名の後ろにカッコ()をつけなかったので、エラーSQL Error [42601]: ERROR: syntax error at end of inputが表示されて、はじめ意味が分からず1時間ほどドツボにハマったが、postgresqlのストアドプロシージャを実行するにはカッコが付いてないとNGらしい。
いやもとい、postgresqlのストアドプロシージャの名前には、カッコがお尻についているので、カッコも含めてストアドプロシージャの名前なのだと、あとでDBiewveでDBの「機能」の部分に表記されるストアドプロシージャの一群を確認して、すべてのストアドプロシージャの名前にはカッコが付いているのを見て自分はそう理解をした。
Postgresqlはバージョン11からストアドプロシージャが使えるようになり、それまではストアドファンクション(関数)が使えなかったというPostgresqlの経緯/変遷を鑑みると、postgresqlのストアドプロシージャの名前には、カッコがお尻についているのも分からなくはない。(DBieverでデータベースを見ると、スキーマ群の分類が、「テーブル」、「ビュー」と同じレベルに「機能」があり、「機能」の下に、「ストアドプロシージャ」や「ストアドファンクション」がぶら下がっていることから、「ストアドプロシージャ」は「ストアドファンクション」と同じコンポーネント(部品)であり、カッコが名前に付与されている扱いなのではないかと類推...)
4.現物株式データの格納
前回の記事で書いたpythonのサンプルスクリプトをほぼそのまま利用するのだが、数点微調整を施している。
import re
import pandas as pd
## (中略) ##
# 株式売買動向
def fn_eqty(pth,si):
#URL指定
url = 'https://www.jpx.co.jp/' + pth
print(url , si)
#データの読み込み(excel)
df = pd.read_excel(url, sheet_name=si)
#期間日付、取引金額単位、市場名の取得
mkt = df.iloc[4,0]
mkt = str(mkt).replace('総売買代金', '')
prd = df.iloc[2,0]
yyyy=prd[:4]
mm=prd[5:7]
ww=prd[:11][-3:]
ww=re.sub('第|週',"",ww)
if mm.find("月")>0:mm='0'+re.sub('月',"",mm)
ymw=yyyy+mm+ww
unit = df.iloc[3,10]
unit = unit.split(',')[0]
unit = str(unit)
print(prd ,ymw, unit ,mkt)
JPXの株式(現物株)と先物の2系統のデータのうち、株式(現物株)のexcelファイルでの日付の持たせ方と、先物のcsvファイルの日付の持たせ方が異なるので、あとでDB側に格納して現物株式データと先物データの同じ時点のデータを抽出してUNIONで結合する際に、狙った時点のデータを取得する際に何かと面倒なので、現物株式側のデータの日付を年月週「yyyymmw」で持たせて、先物データと一緒の日付の持たせ方をして、DB上で一緒に扱えるように、DB格納前に整形処理をしておく。前回記事からの差異は、まず「ymw」を上記のように追加したのが1点。
import re
import pandas as pd
## (中略) ##
#株式売買動向
def fn_eqty(pth,si):
#URL指定
url = 'https://www.jpx.co.jp/' + pth
print(url , si)
#データの読み込み(excel)
df = pd.read_excel(url, sheet_name=si)
#期間日付、取引金額単位、市場名の取得
mkt = df.iloc[4,0]
mkt = str(mkt).replace('総売買代金', '')
prd = df.iloc[2,0]
yyyy=prd[:4]
mm=prd[5:7]
ww=prd[:11][-3:]
ww=re.sub('第|週',"",ww)
if mm.find("月")>0:mm='0'+re.sub('月',"",mm)
ymw=yyyy+mm+ww
unit = df.iloc[3,10]
unit = unit.split(',')[0]
unit = str(unit)
print(prd ,ymw, unit ,mkt)
#整形:データの絞り込み
df = df[11:63]
df.columns = ['a', 'b', 'c', 'd', 'e', 'f','g','h','i','j','k']
df = df.drop(['c', 'd', 'e', 'f','g','h','j' ,'k'], axis=1) #'k'は検算確認用、DBに格納する場合は'k'は削除
df = df[df['b']!='合計']
df = df.dropna(subset=['i'])
df = df.dropna(how='all')
#値の置換
dct = {'Proprietary': '自己計', 'Brokerage': '委託計', 'Total':'総 計', 'Institutions': '法 人'
, 'Individuals': '個 人', 'Foreigners':'海外投資家','Securities Cos.':'証券会社'
, 'Investment': '投資信託', 'Business Cos.':'事業法人', 'Other Cos.': 'その他法人等'
, 'Financial': '金融機関', 'Life & Non-Life':'生保・損保', 'City & Regional BK':'都銀・地銀等'
, 'Trust BK': '信託銀行', 'Other Financials':'その他金融機関'}
#df.a = df.a.replace(dct)
df["a"] = df["a"].replace(dct)
#整形:データの絞り込みや列名設定
df = df.query("a not in ['委託計', '総 計', '法 人', '金融機関']")
df = df.reset_index()
df.columns = ['clsid','clsname', 'bysl', 'vle'] #'diff'
#期間日付、取引金額単位、市場名がセットされたデータフレームを生成
df2 = pd.DataFrame([[prd,ymw,unit,mkt ]]*len(df))
df2.columns = [ 'prd', 'ymw' ,'unit', 'mkt' ]
#dfの結合
df = pd.concat([df, df2], axis=1)
print( df )
### to_sql() ###
df.to_sql('tbleqty_temp', engine, if_exists='append', index=False)
あと前回記事では、売買状況の数値(buyとsell)から合算値(sum)と取引値(dif)、つまり買い値と売り値の加算/減算をpython上で行ったが、今回はDBにデータを格納するのが第一目標であり、それはDBであとでviewを作成してそこで加算/減算を施せばいいので、今回のpythonスクリプトからはその処理は除外した。
また前回記事ではdfデータフレームをpivot()で買いの列と売りの列を横に並列に並べた形にdfを整形したが、今回は、このまま縦の持たせ方の形でDBのテーブルに格納するので、pivot()変換する箇所も除外した。DBに格納する際は、pandasのwideフォーマットなデータの持たせ方ではなく、longフォーマットなデータの持たせ方のほうが、リレーショナルデータベースの正規化の考え方に合致して、そちらの方が好都合だと思う。
そういう意味ではJPXの株式(現物株)と先物の2系統のデータのうち、株式(現物株)のexcelファイルでのデータの持たせ方は、longフォーマットに近い形式であり、DBに格納するという観点でいくと、そちら(longフォーマットでの持たせ方)のほうが望ましい形と言える。
ただ株式(現物株)のexcelファイルでの売買状況の数値(buyとsell)は、文字列型のカンマ表記で記載されているので、DBのテーブル格納はこのまま格納して、DBからデータを取得する差異にカンマ表記の文字列型を、カンマなしの数字型に変換して加減算するようにしなくてはならないので、後述するが変換を忘れずに。(格納前にカンマ表記の文字列型を変換しようかと考えたのだが、今回は格納前の変換は断念。)
5.先物データの格納
# 先物売買動向
def fn_dvs(pth):
#URL指定
url = 'https://www.jpx.co.jp/' + pth
print(url)
#データの読み込み(csv)
df = pd.read_csv(url , header=None)
#整形:データの絞り込み、列名設定など
df = df[0:100]
df.columns = ['a', 'b', 'c', 'd', 'e', 'f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x']
#df = df[df['a']==301]
df = df.query("a in ['301', '313', '314', '316', '323']")
df = df.query("h not in ['80', '30', '20']")
df = df[df['d']==1]
#df = df[df['h']==10]
df = df.drop(['b', 'i','j' ,'k' ,'n','m','o','p','q','s','t','u','v','w','x'], axis=1)
df = df.rename(columns={'l': 'sell', 'r': 'buy'})
#df = df.reset_index()
#値の置換
dct1 = {10: '自己計', 70: '委託計', 50: '個 人', 60: '海外投資家',41: '証券会社'
,31: '投資信託', 32: '事業法人', 33: 'その他法人等', 21: '生保・損保'
,22: '都銀・地銀等', 23: '信託銀行', 24: 'その他金融機関'}
dct2 = {301: 'nk225', 313: 'nk225m'
,314: 'topix', 316: 'topixm', 323: 'nk400' }
df["clsfctnName"] = df["h"].replace(dct1)
df["drvtsName"] = df["a"].replace(dct2)
df.columns = ['drvtsid','unit','sycl','ymw','prdstart','prdend','clsid' ,'sell','buy','clsname', 'drvname' ]
#print(df)
df_long = pd.melt(df ,id_vars=['drvtsid','unit','sycl','ymw','prdstart','prdend','clsid','clsname','drvname'], var_name='bysl', value_name='vle')
### to_sql() ###
df_long.to_sql('tbldrvs_temp', engine, if_exists='append', index=False)
・pandasにはwideフォーマットなデータフレームをlongフォーマットなデータフレームに変換するための関数「melt()」が用意されている。JPXで公開されている先物の統計資料は、買いデータと売りデータが横に並んでいるwideフォーマットなデータの持ち方をしているので、melt()でlongフォーマットなデータフレームに変換して現物株の売買状況とデータの持たせ方と同じように「買い」と「売り」のデータが縦の行単位で保持するように、to_sql()でDB保存前に変換処理をしている。
6.python(sqlalchemy)でストアドプロシージャを実行する
import sqlalchemy
import sqlalchemy.orm
from sqlalchemy import create_engine
### ...(中略)...
def exec_sp():
# セッションを作成
Session = sqlalchemy.orm.sessionmaker(bind=engine)
session = Session()
####ストアド実行
query = "call sp_impdata()"
session.execute(query) #sp実行
session.commit() #コミット
session.close()
・普段仕事で利用しているSQLServer(t-sql)の場合、ストアドプロシージャの実行はEXEC文でキックする、もしくはストアドプロシージャ名だけでも実行可能だが、今回利用するのはHerokuのpostgresqlのDBなので、CALL文でストアドプロシージャを実行する。あとT-SQLの習慣で、ストアドプロシージャ名だけ記述してもストアドプロシージャは実行されず、SQLエラーになるだけなので、忘れずにCALL [ストアドプロシージャ()]と記述するべし。
・あと今回は割愛するが、DB側で各テーブルにトリガーを作っておいて、Pandasでto_sql()でレコードが格納されたタイミングでトリガーが動くようにして、tempテーブルからmasterテーブルへの挿入処理が行われるようにするという実装方法も考えられる。
7.ビューの作成 :creaete views
7-1.DBieverでテーブルを検索する(view作成前の準備)
・DBieverのショートカットキーで、SQLを実行するのは「ctrl + enter」であり、これは多用する。なおMSSQLのmanagement studioの場合でも「F5」ボタンでSQLを実行することが可能であり、ショートカットキーを覚えておくと処理が早くなるのは、MSSQLでもpostgresqlでもpythonでもrubyでもなんでも一緒ですね。
参考
https://wonwon-eater.com/dbeaver-shortcut/
ちなみに同一ペインで、複数SQLが記述されている場合に「ctrl+enter」を押すと、カレントレコード上のSQLが実行されるのは、MSSQLのmanagement studioでも、今回利用した(Postgresqlの)DBieverでも同じのようである。
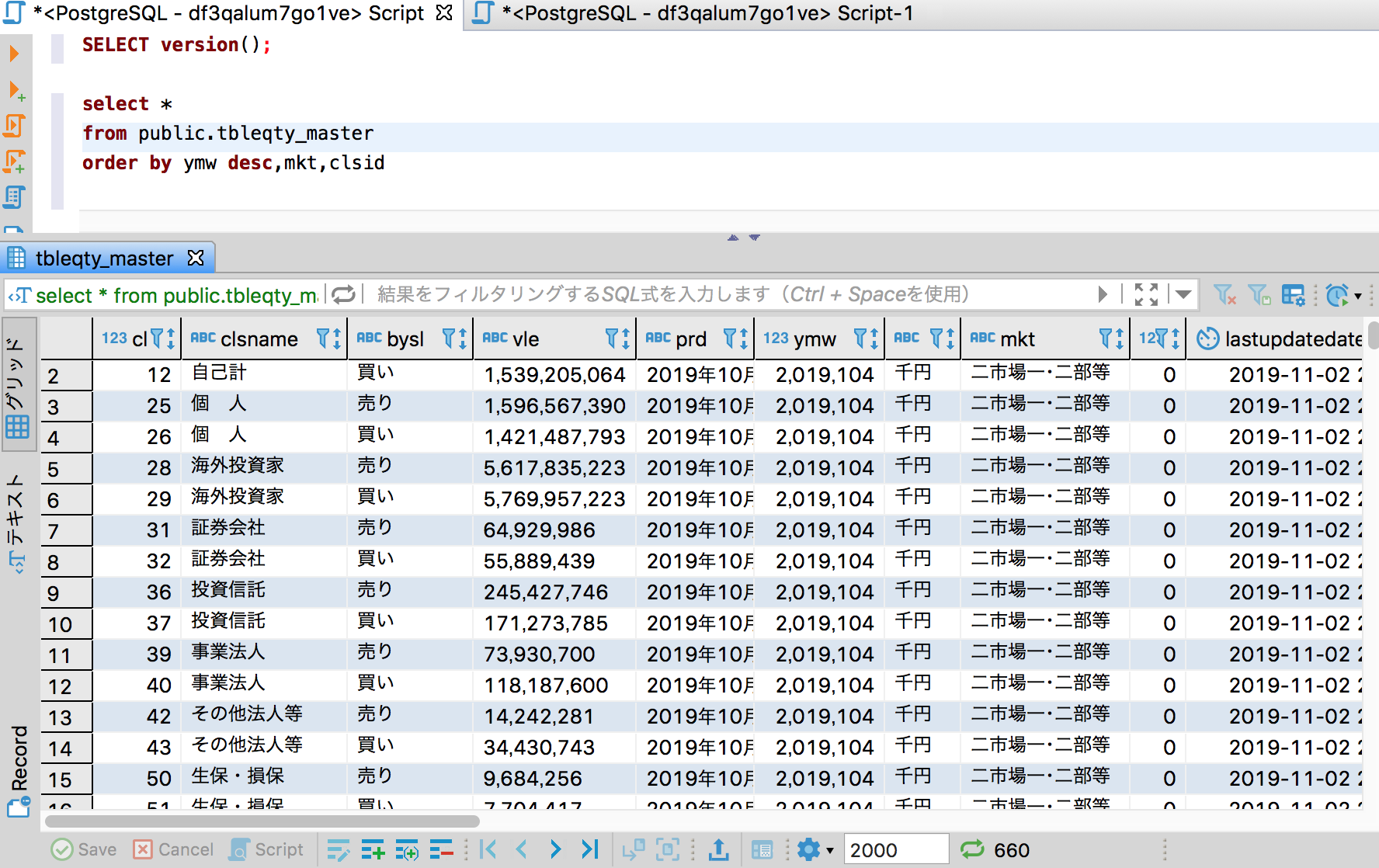
・a)現物株式格納テーブル「public.tbleqty_master」を検索する
select *
from public.tbleqty_master
order by ymw desc,mkt,clsid
・b)先物格納テーブル「public.tbleqty_master」を検索する
select *
from public.tbleqty_master
order by ymw desc,mkt,clsid
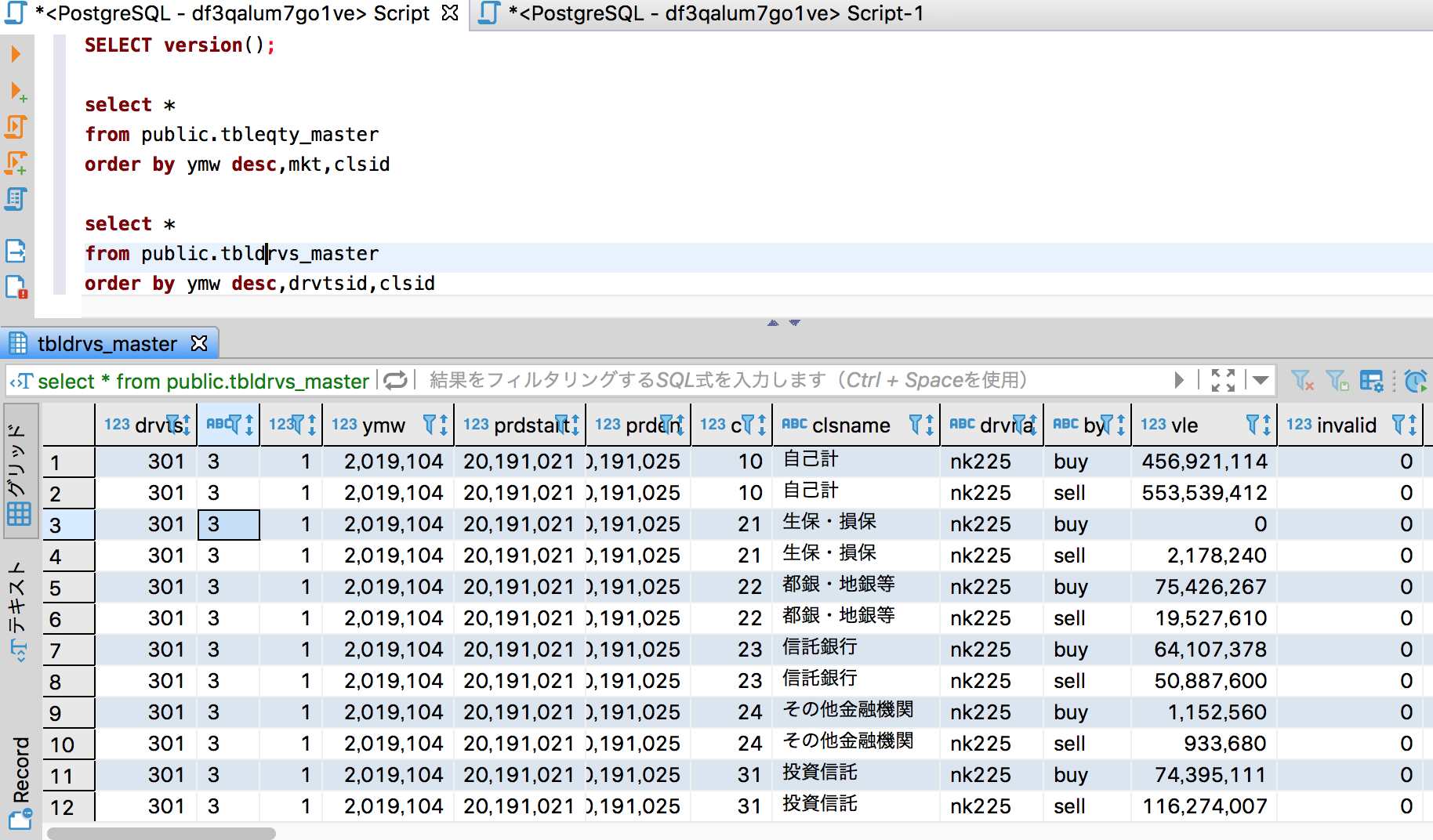
・いつ時点のデータなのかを任意の日付で特定するために、「ymw」列を用意して、年月週(2019年9月4週)で特定可能なようにどちらのテーブルにも列を用意している。今回は2019年10月4週がlatestデータなので、ymw=2019104をwhere句に指定するイメージ。
・どちらのテーブルにも論理削除用の列「invalid」列を用意しているので、where句でinvalid=0をつけるのを忘れずに。(上記クエリーSelect文には、where句にinvalid=0を含めるのを失念している。失礼!)
・夕凪氏のツイートような集計をする場合、所属別にGroup byで集計するようなイメージなので、現物株式のテーブルでは列「mkt」を、先物テーブルでは列「dvrsid」がどの市場(先物商品)においての投資部門の値なのかを識別しているので、上記株式と先物の2テーブルをUNION ALLで「縦に」連結させて、その際、現物株式のテーブルの列「mkt」と先物テーブルの列「dvrsid」を同じ列のように扱って、あとはymw列、bysl列、clsname列(投資部門を識別する列)び3つは上記2テーブルともに同じ列があるので、2つのテーブルをUNION ALLで連結するイメージ。
・bysl列の「買い」と「売り」を識別する列だが、株式テーブルの方はbysl列の値が「買い/売り」と日本語でデータが格納されているのに対して、一方の先物テーブルの方のbysl列の値が「buy/sell」と英語で格納されていてバラバラなので、あとでビューにする際にこの差異を吸収する必要があるので要注意。 (注:先物データをpythonで生計してpandasのto_sql()でpostgresqlのDBにデータ格納する前に、melt()でロングフォーマットに変換した際に、列名を「買い/売り」と日本語の列名を付ければ統一できたのだが、なんとなく日本語の列名を付けたくなかった、というか昭和の会社のダメダメIT部門のシステム要件みたいで、日本語の名前をつけたら負けだと思い英語[buy/sell]で命名かつ整形をしたため。本来ならば、JPXの株式現物株のexcel資料がbuy/sell表記にしてほしいところではあるが...)
7-2.create view
CREATE OR REPLACE VIEW public.vwselect_groupby_investment_sector
AS WITH work AS (
SELECT tbldrvs_master.drvname AS fld1,
tbldrvs_master.clsname,
tbldrvs_master.bysl,
tbldrvs_master.ymw,
tbldrvs_master.vle,
tbldrvs_master.unit
FROM tbldrvs_master
WHERE tbldrvs_master.invalid = 0
UNION ALL
SELECT tbleqty_master.mkt,
tbleqty_master.clsname,
CASE
WHEN tbleqty_master.bysl = '売り'::text THEN 'sell'::text
WHEN tbleqty_master.bysl = '買い'::text THEN 'buy'::text
ELSE 'hoge'::text
END AS bysl,
tbleqty_master.ymw,
to_number(replace(tbleqty_master.vle, ','::text, ''::text), '999999999999'::text) AS vle,
CASE
WHEN tbleqty_master.unit = '千円'::text THEN '3'::text
ELSE '0'::text
END AS unit
FROM tbleqty_master
WHERE tbleqty_master.invalid = 0
AND tbleqty_master.mkt !~~ '東証%'::text
), cdd AS (
SELECT work.fld1,
work.ymw,
work.clsname,
work.bysl,
work.vle::double precision * power(10::double precision, work.unit::integer::double precision) / power(10::double precision, 8::double precision) AS vle
FROM work
WHERE work.ymw = 2019104 AND work.clsname <> '委託計'::text
), gpb AS (
SELECT cdd.ymw,
cdd.clsname,
cdd.fld1,
max(
CASE
WHEN cdd.bysl = 'sell'::text THEN cdd.vle::integer
ELSE NULL::integer
END) AS sell,
max(
CASE
WHEN cdd.bysl = 'buy'::text THEN cdd.vle::integer
ELSE NULL::integer
END) AS buy
FROM cdd
GROUP BY cdd.ymw, cdd.fld1, cdd.clsname
)
SELECT rank() OVER (ORDER BY (
CASE
WHEN gpb.clsname = '自己計'::text THEN 1
WHEN gpb.clsname = '個 人'::text THEN 2
WHEN gpb.clsname = '海外投資家'::text THEN 3
WHEN gpb.clsname = '信託銀行'::text THEN 4
WHEN gpb.clsname = '証券会社'::text THEN 5
WHEN gpb.clsname = '投資信託'::text THEN 6
WHEN gpb.clsname = '事業法人'::text THEN 7
WHEN gpb.clsname = 'その他法人等'::text THEN 8
WHEN gpb.clsname = '生保・損保'::text THEN 9
WHEN gpb.clsname = '都銀・地銀等'::text THEN 10
WHEN gpb.clsname = 'その他金融機関'::text THEN 11
ELSE NULL::integer
END)) AS rnk,
gpb.ymw,
gpb.clsname,
sum(gpb.sell) AS sell,
sum(gpb.buy) AS buy,
sum(gpb.buy - gpb.sell) AS total
FROM gpb
GROUP BY gpb.ymw, gpb.clsname;
・postgresqlではWITH句(Cte)が使える。まずはwith句で、株式データと先物データの投資部門別売買状況が格納されている2テーブルをUNION ALLで縦に連結する。その際、mkt列(株式系テーブルの列)とdvtvsid(先物系テーブルの列)を同じ列として扱い、あとで、投資部門別でgroup byで集計できるようにしておく。
・夕凪氏のツイートの集計では、株式系テーブル「tbleqty_master」のデータは「2市場合計等」というデータを利用しているようで、つまり東証1部や2部、マザーズやジャスダックのデータは除外しないので、where句ではmkt列の値が「東証%」ではないレコード(つまり「2市場合計等」)を取得するように指定している。
・論理削除のレコードはwhere句で検索から除外する。
・CASE式で、bysl列の値(日本語の「買い/売り」、英語の「buy/sell」の4種類の文字列)を「buy/sell」に揃えておく (注:これはあとでgroup byで集計するためなので、値はなんでもよく、買いと売りの2種類に識別できればOKなので、数字「1(買い)と2(売り)」とか「1(買い)と0(売り)」、あるいは「1(買い)と-1(売り)」であってもOKだったかも)。
・売買額の単位(unit列)も、株式系と先物系で表記がバラバラなので、case式で揃えておく。売買額の単位(unit列)は、あとで売買額の単位を揃える際に使うので、取得必須列。
・株式系テーブルの売買額が、カンマ表記の文字列型なので、カンマをreplace()で除去した上で、to_number()で数字型に変換している。変換後の数字型の形式は、小数点なしの整数ならばだいたいOKなので、「999999999999」と億以上の単位になるように指定。
・売買額の単位(unit列)は、株式系テーブル、先物系テーブルの商品によって、「0円」単位であったり、「千円」単位であったりバラバラなので、unit列の値を「10のn乗(千円だったら10の3乗)」に変換した上で売買額と掛け算すれば算出できる。
・あと夕凪氏のツイートの集計は、単位「億円」なので、10の8乗で割り算している。
・postgresqlでの指数表記は、power関数を利用する。 例)1億=100000000=10の8乗=power(10,8)
・ymwでデータの時点を指定している。 例)ymw=2019104
・python側で、ymw列の値を生成している。[10月,11月,12月]と[1月2月・・・9月]と、1桁の月と2桁の月を一緒に扱うために、1桁の月の場合は01,02,03・・・09に変換して、「yyyymmw」形式で扱えるようにしている。なお秋の番号は最大でも5週なので1桁で無問題と上記ではしている。
・clsname列の値が'委託計'のレコードは今回の集計では必要ないことにあとで気づいたので、上記ではwhere句で除外した。
・ymw(任意の時点yyyymmw)と clsname(部門別)でgroup byで集計、集計関数は売買額を計算するので、「buy(買い) - sell(売り)」の合計sum()で算出するイメージ。なお上記クエリーではwhere句で、yyyymmwの値を2019104と指定しているので、group by句にymw列は含めなくてもOKといえばOKかもしれない。
・上記ビューの最大のポイント、と云うかやりたいことはただ1つで、clsname(投資部門別)ごとに集計し、現物株(=2市場合計)と先物(nk225、topix、nk225 mini、topix mini、nk400の5つの先物商品)の同一投資部門ごとに売買額(買いと売りの差額)の合計を算出する点。
・集計後に投資部門ごとに集計結果が出るが、投資部門の名前でソートされてしまうので、上記クエリーでは、rank()関数で、夕凪氏のツイートのような集計の投資部門の並び順、つまりJPXでのエクセル資料の表記順に並ぶようにナンバリングしている。
・上記クエリーでは、日経平均JPX400のことを自分の勘違いというかうろ覚えで、間違えて「nk400」と簡便的に表記してしまっているが、nkjpxくらいが妥当だったかも?
7-3.Dbieverで生成したviewをSelectするクエリーを実行する
まずは DBieverで作成したviewを検索(select文を実行)して確認する
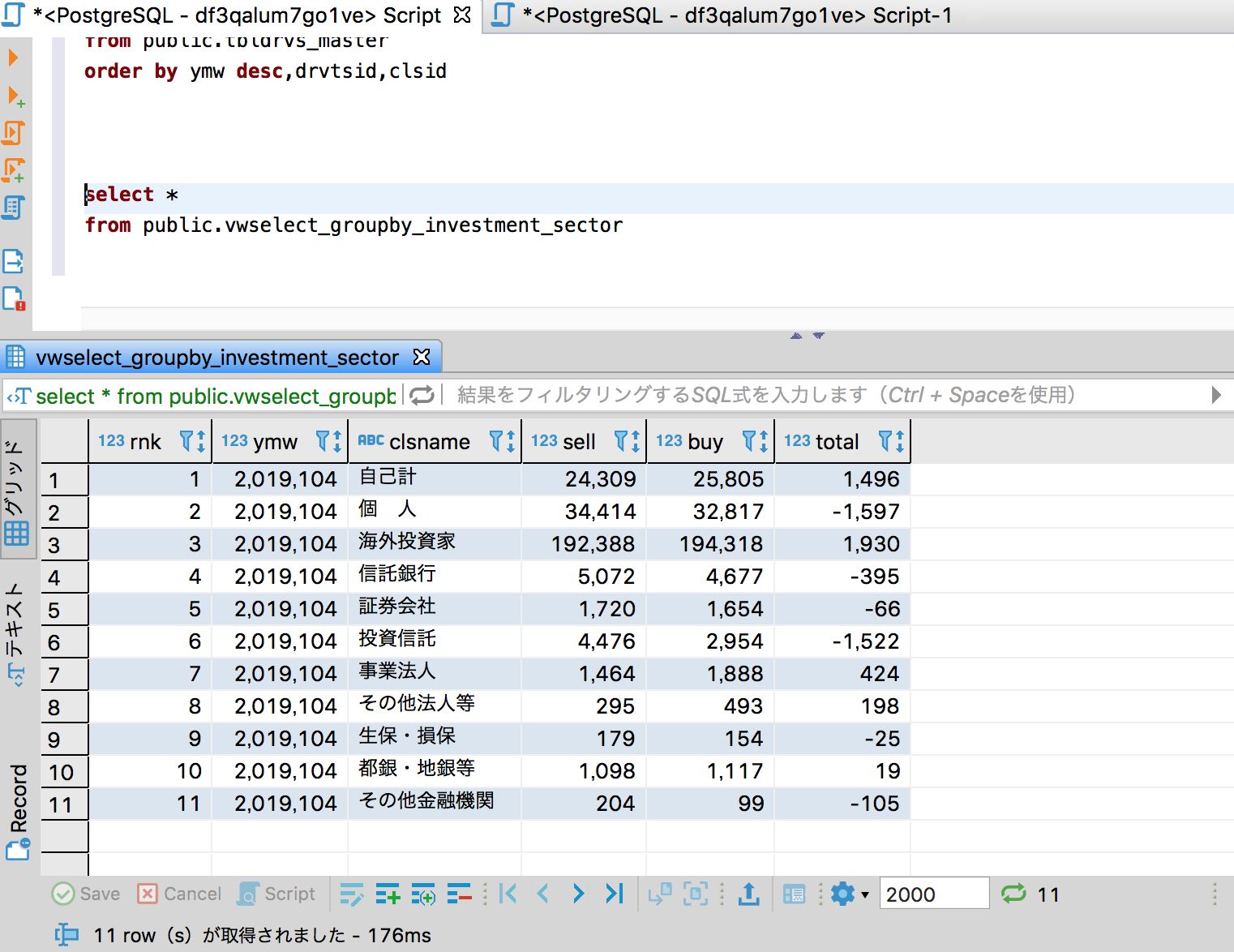
自分のviewのクエリーでは、売買額(vle)を単位(unit)で掛け算した上で、1億円で割っているので、その際の丸めの箇所で、夕凪氏のツイートの集計とは、1ずれてしまっている模様だが、大体合致していると思う。
8.PythonでHeroku postresqlのDBに作成したビューを参照してpandasでデータフレームを生成する
import pandas as pd
import sqlalchemy
from sqlalchemy import create_engine
# DB接続設定文字列
dbuser='hogehoge_user'
dbpwd='fugafuga_password'
hostname='hogehoge_hostname'
dbname='fugafuga_database'
CONNECT_INFO = 'postgres://{p1}:{p2}@{p3}:5432/{p4}'.format(p1=dbuser, p2=dbpwd, p3=hostname,p4=dbname)
engine = sqlalchemy.create_engine(CONNECT_INFO, encoding='utf-8')
query = 'select * from public.vwselect_groupby_investment_sector'
df = pd.read_sql_query(query, engine ,index_col =['ymw'])
display(df)
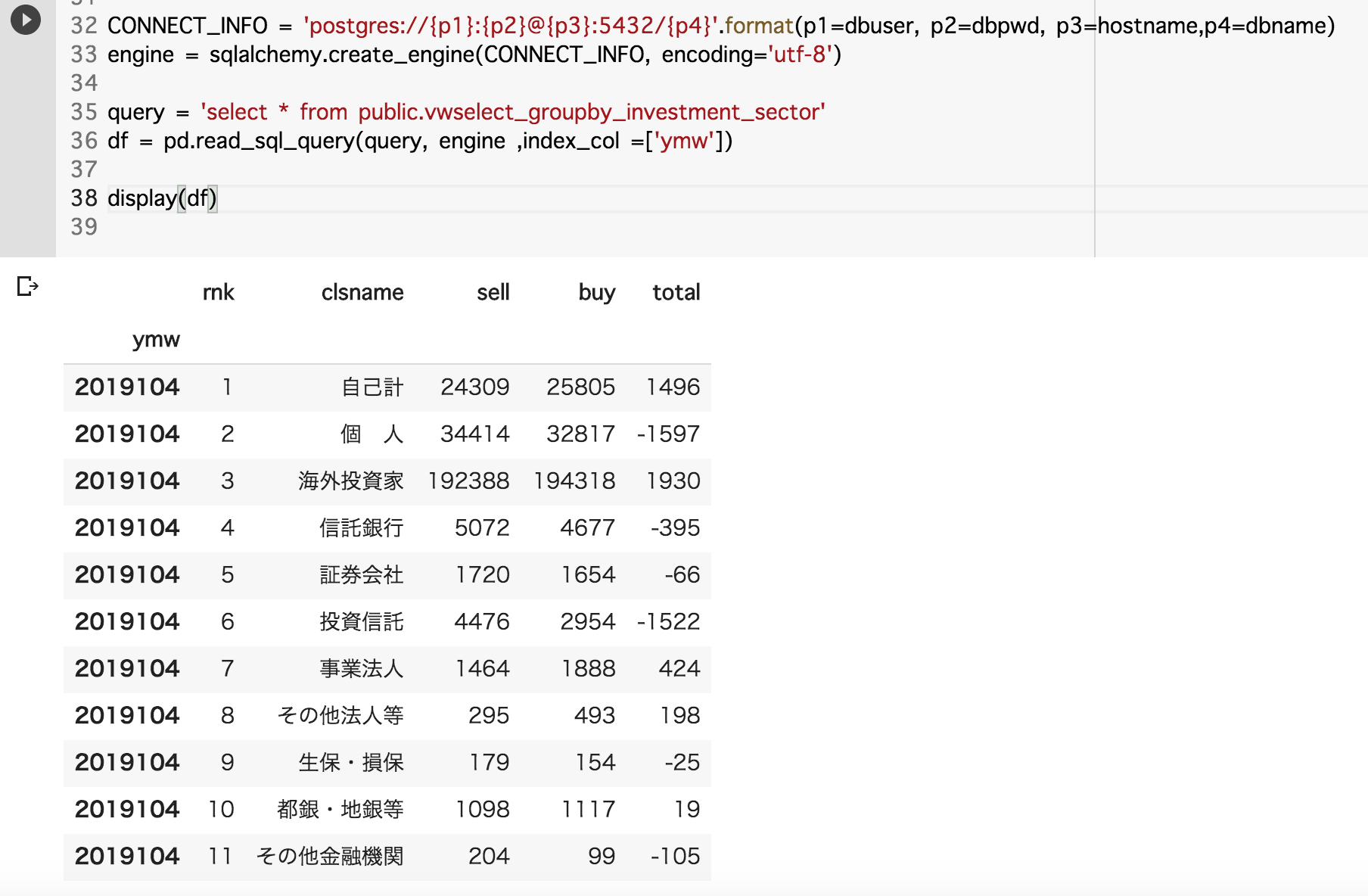
※参考:pandasでRDBのSQLクエリー(select文)を実行するまわり
https://qiita.com/Fortinbras/items/7841aa5545d4a56b93ab
ということで夕凪氏のツイートのような集計ができてデータが準備できたところで、次回に続く...