この記事はエーピーコミュニケーションズ Advent Calendar 201816日目の記事になります。
はじめに
- 機械学習は環境の準備から実装まであらゆる面でハードルが下がっています。その代表の一つとして、Cloud AutoML Visionがあります。Cloud AutoML Visionは、画像データさえ用意すれば、あとはそれを入れるだけでモデルが完成し、その利用まで簡単にできます。
- 先日のTensorFlow User Group(TFUG)でCloud AutoML Visionについての紹介があり、以前から知ってはいたものの興味が出てきましたので、この機会に色々とやってみようと思い、この記事を書きました。
- またモデルを作成する中でデータ数が足りない問題に直面し、画像データの増幅(Data Augmentation)を実施しました。しかしこれまで画像データを意図的に増やしたことがなく、その効果については疑問視していました。そのため、**画像分類機を作る際に画像データの増幅をすると、予測精度にどのような影響があるのか?**と言う疑問も生じました。この辺りも簡単に見てみました。
Cloud AutoML Visionとは
- Cloud AutoML VisionはGoogle Cloudの提供するサービスの一つです。前項でも述べましたが、利用者はデータを用意するだけで画像分類器を作成することができます。
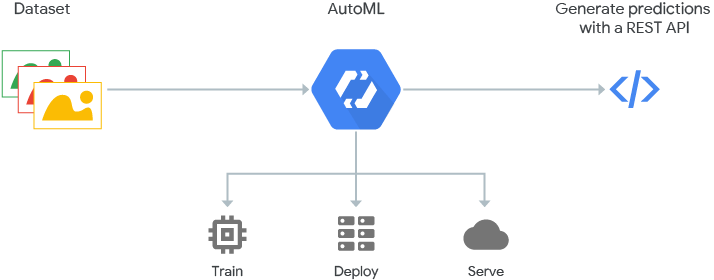
上記模式図のように、利用者はデータセットを用意してAutoMLに入れることで、モデル構築に必要な要素を全てAutoMLにお任せし、出来上がったモデルを利用できます。 - AutoMLの中では、Googleの作成したモデルを転移学習で利用することに加え、NASNetと呼ばれるアーキテクチャを用いているようです。NASNetの説明はこちらからどうぞ。
目的
- 弊社はインフラSIを中心に事業を行う会社です。ネットワークやサーバ構築の案件を多く扱います。ネットワーク周りではCiscoの機器を触ることも多く、検証機もあります。そのためCiscoの製品に触れる機会はよくありますが、当然ながらCiscoはこれまで様々なネットワーク機器を販売しており、生産中止になったものも含めると非常に多くの機種が存在します。
- そこで今回は、様々なネットワーク機器を販売するCiscoの機器の中でも、特にルーターに絞り、Cloud AutoML Visionを使ってCiscoルータ分類機を作ることを目的としました。
方法
画像の準備
- まずは使用する画像を集めます。手元にはCiscoルータの画像が全くなかったため、使う画像はWebから集めることとしました。また集める際には手動でやっていくわけにはいかないので、pythonを使ってWeb上から画像を収集できるこちらのスクリプトを利用しました。1機種あたり200枚を検索することとしました。
画像を集めた後は不要と思われる画像を削除し、最終的に残った画像をデータセットとして利用しました。
検索する対象
- それなりに幅広いタイプを集めようと考え、独断と偏見から以下の機種を対象としました。細かな型番等は省略いたします。
# 使用したCiscoルータ機器(数字のみ)
841/892/1812J/1841/1921/2801/2901/3750/3845/3925
実施した分類系
- 分類モデルは2値ラベル分類と複数ラベル分類の2種類を作成しました。
- 2値ラベル分類として、有名どころであり比較的画像も集めやすそうな892と1812Jとの分類を試しました。
- 次に検索したすべての機種をデータセットとしてモデルを作成し、複数種類を対象でどの程度推定できるかを試しました。
2値ラベル分類(Cloud AutoML Visionの利用方法)
ここから2値分類のモデルを構築します。合わせてCloud AutoML Visionの使い方も簡単に説明します。
プロジェクト作成
-
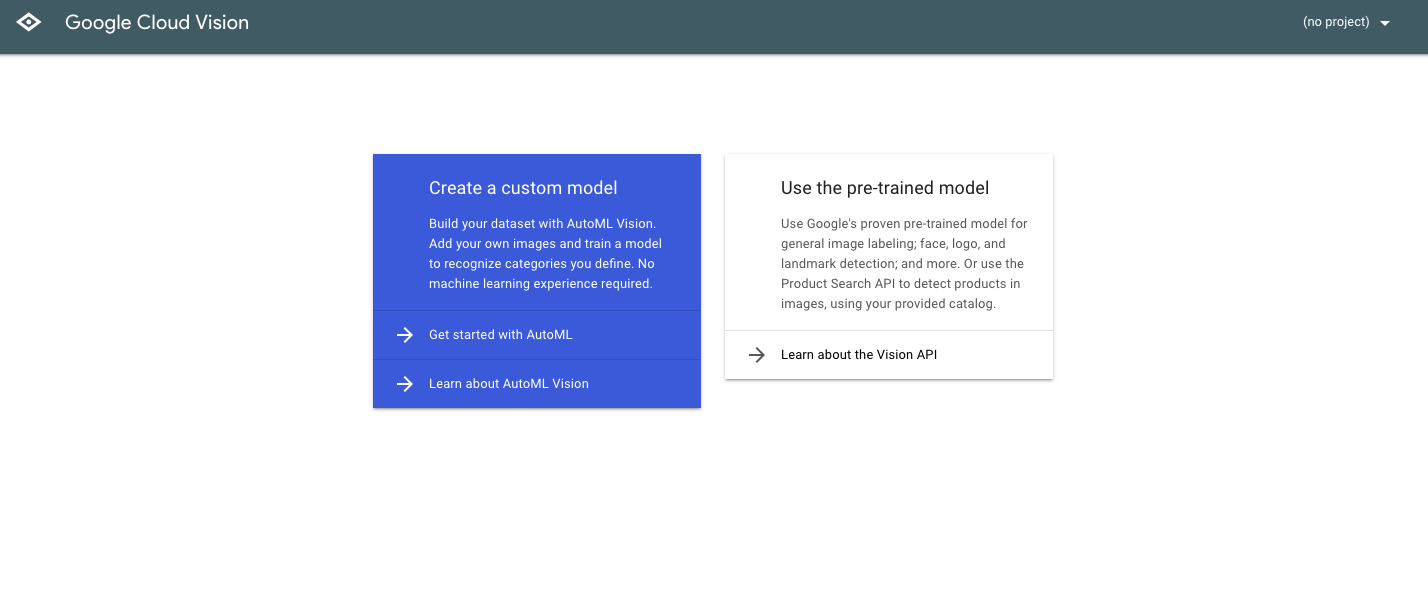
まずはコンソールを開くを選択すると、以下のような画面が表示されます。
-
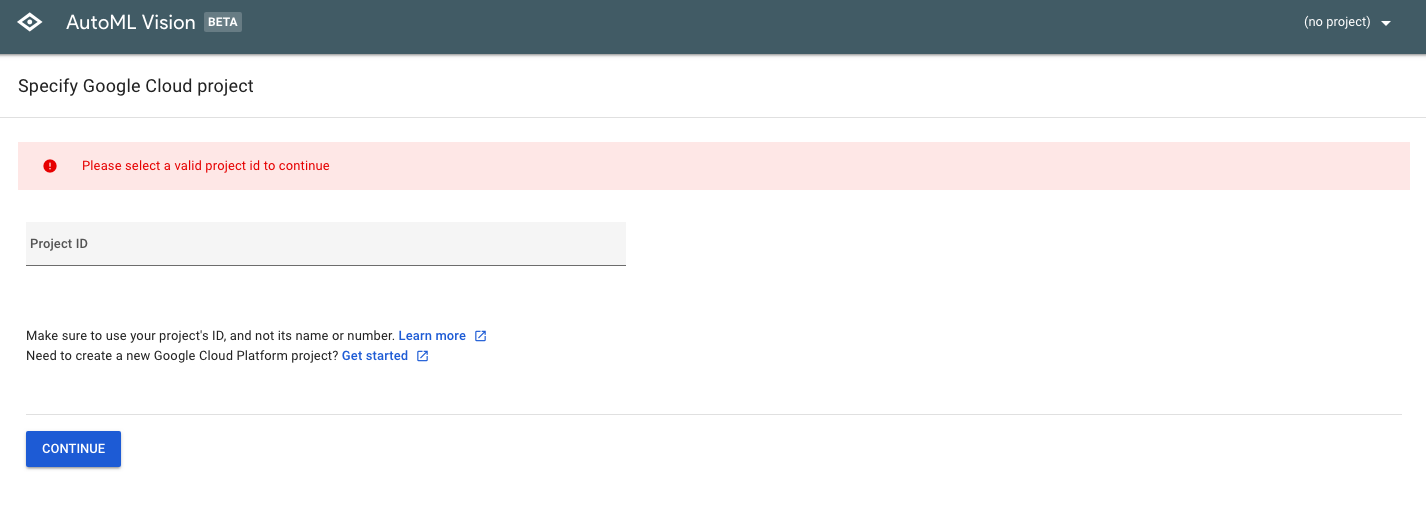
ここでGet started with AutoMLを選択すると、初めての方は以下のような画面が表示されます。
-
新しくGoogle Cloudのプロジェクトを作成する場合は、Get startedを選択します。
-
新しいプロジェクト名を入力して「作成」ボタンを選択します。
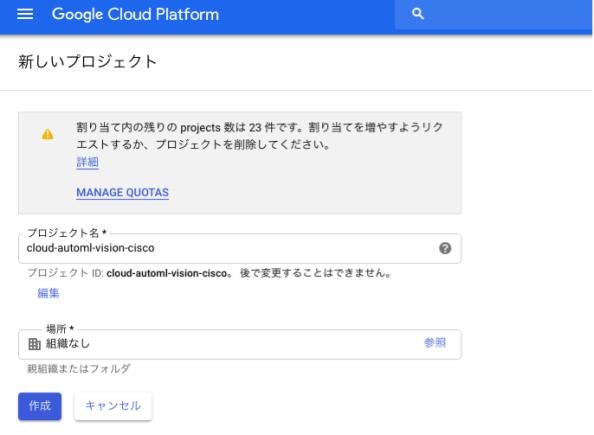
-
Google Cloud Platformのダッシュボード画面に移動しますので、再びAutoML Visionのページに移動し、先ほど作成したプロジェクトを選択します。その後、Continueを選択します。
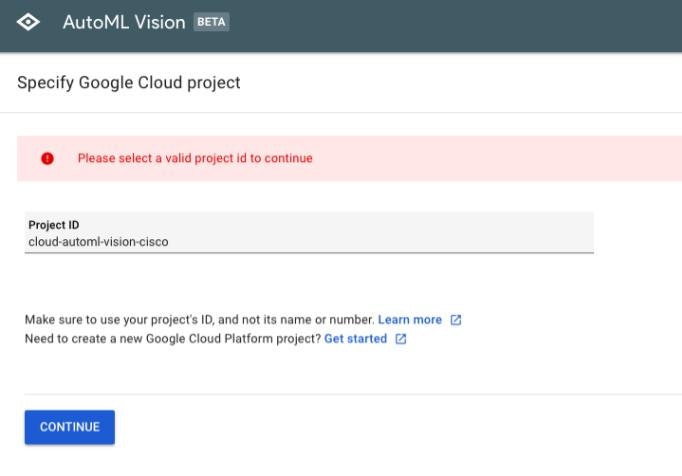
-
プロジェクト作成はこのページが最後になります。課金の登録がまだの方はGo To Billingを選択してください。既に登録されている場合はAutoMLのAPIを有効化するため、Set Up Nowを選択します。
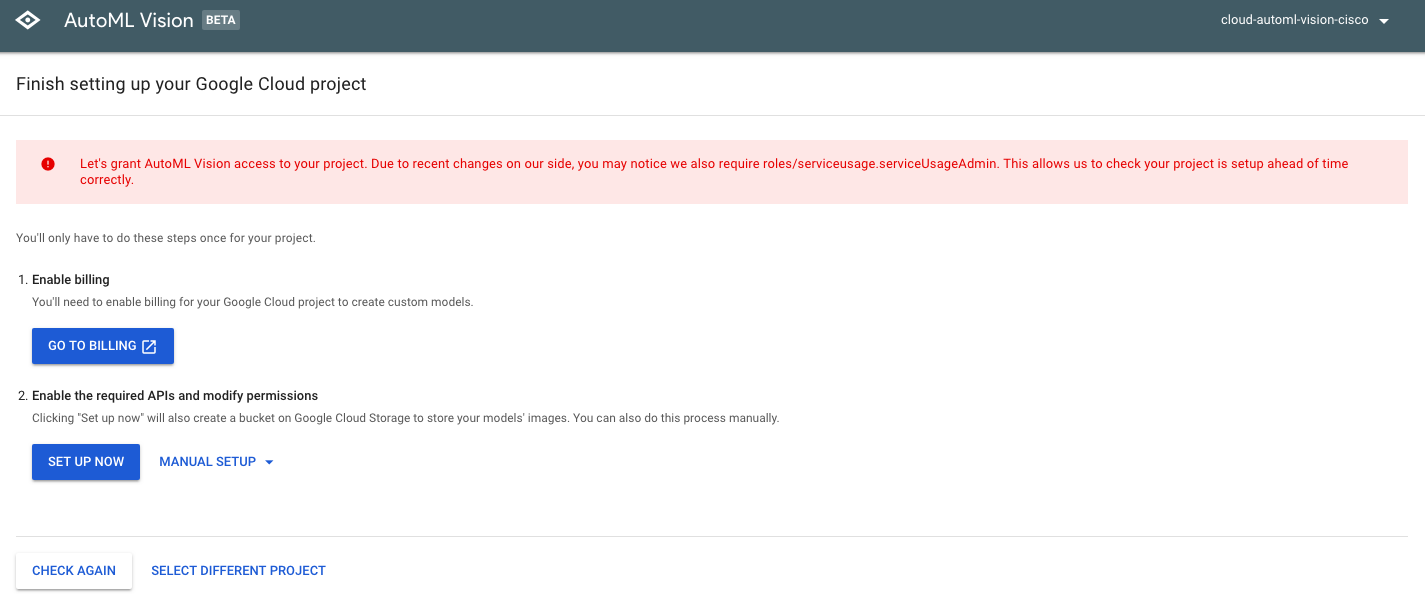
-
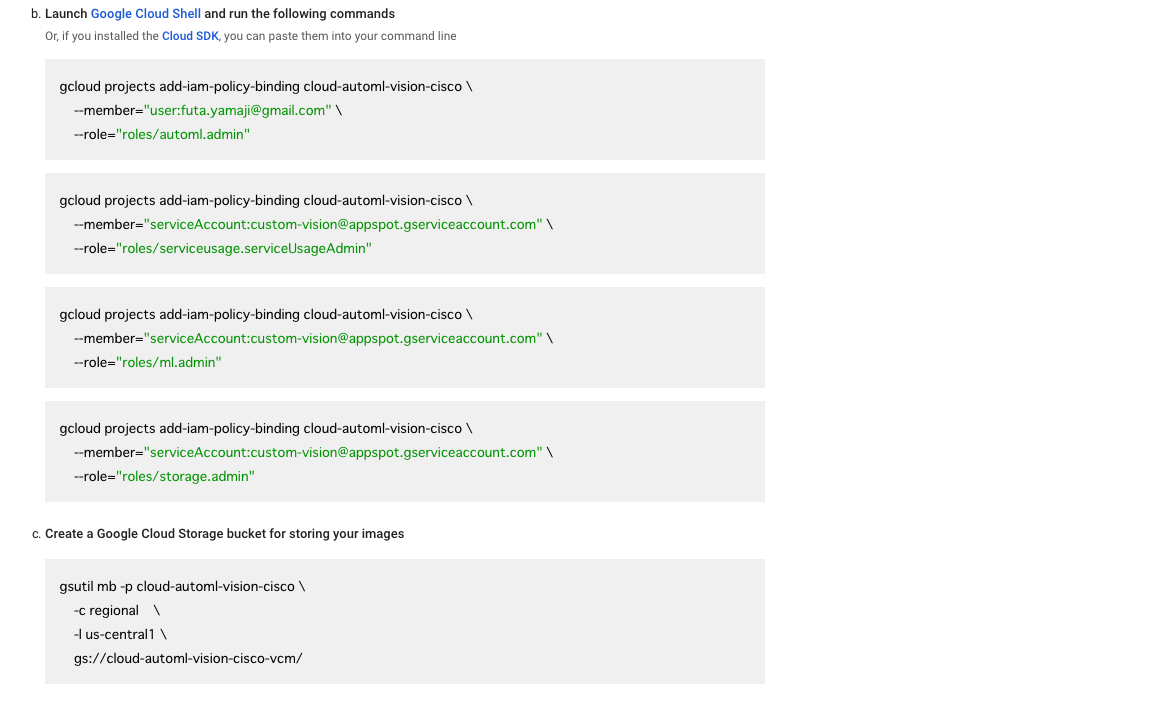
Set Up Nowを選択すると自動的に設定が作成されますが、手動でセットアップすることもできます。Manual Setupを選択すると以下のような画面が表示され、手順が表示されます。
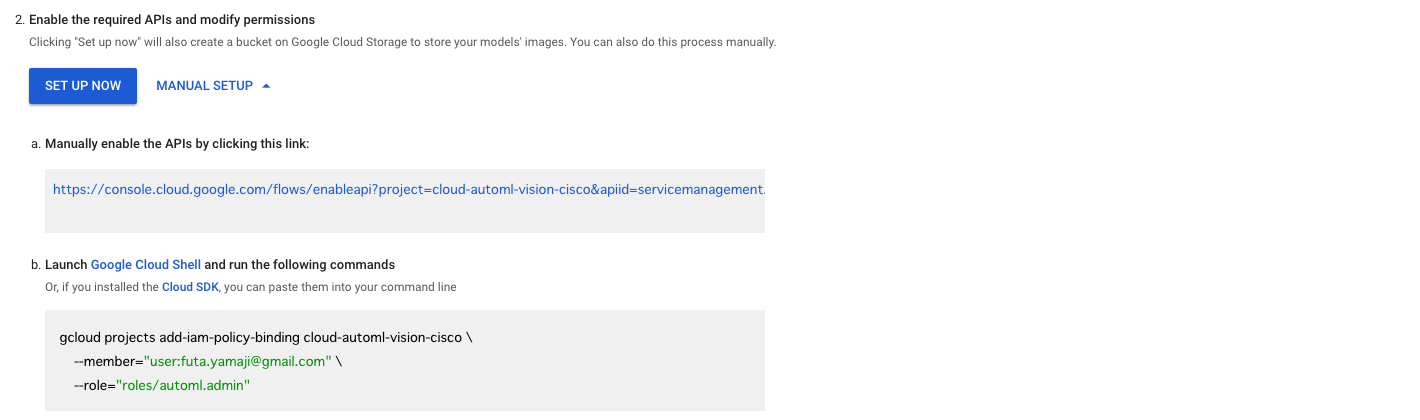
-
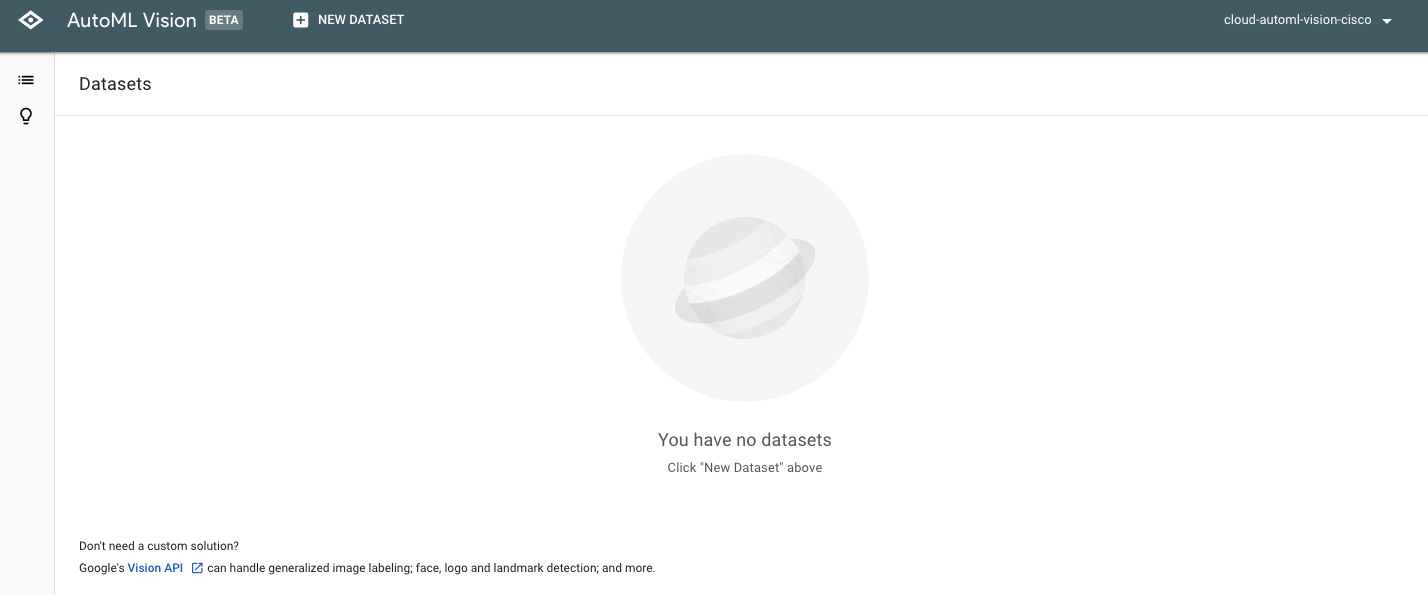
セットアップが完了すると以下のようにDatasetsの画面が表示されます。この段階ではまだデータセットがないため、画面は空っぽになります。
画像アップロード
-
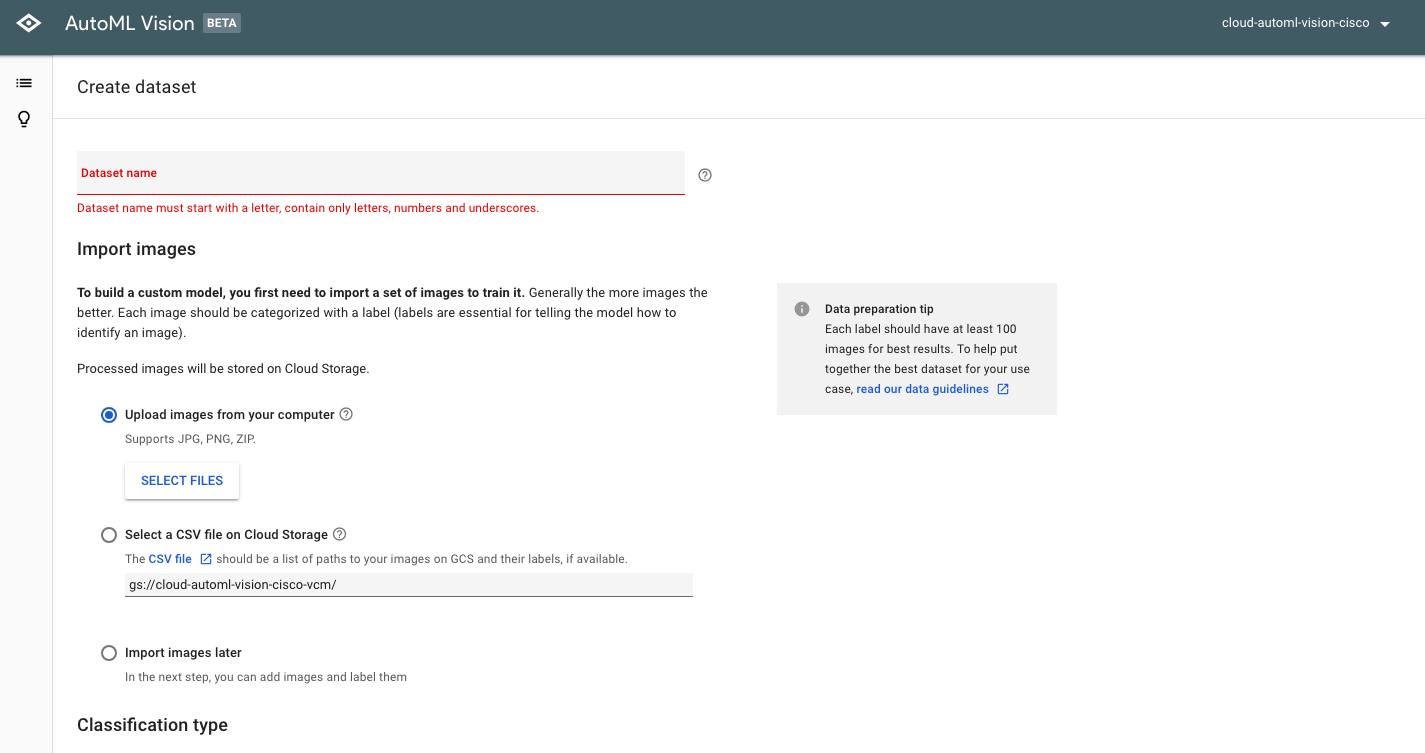
ここから用意した画像のデータセットをアップロードします。まずは先ほどの画面上部にあるNew Datasetを選択します。すると以下のような画面が表示されます。
-
まずはデータセットの名前を入力します。Dataset name部分に作成するデータセットの名前を入力します。
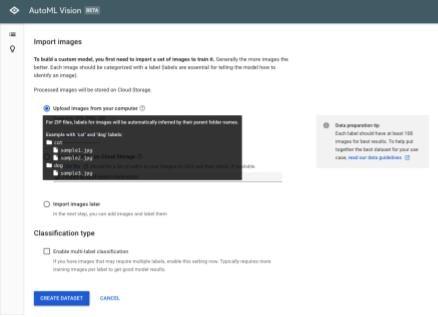
次にデータをインポートします。インポートの方法は幾つかありますが、ここではローカルのPCからアップロードする方法を採用します。jpgやpngファイルを個別にアップロードすることもできますが、まとめてアップロードする場合はzip形式に圧縮してアプロードすることができます。圧縮時は指定されたフォルダ構造でzipを作成します。
-
zipでアップロードする場合、画像のラベリングは画像の格納されたフォルダ名がつけられます。また1つの画像に対して複数のラベリングを与えることも可能で、それを許可するにはClassification typeのチェックをつけます。

-
アップロードした画像はGoogle Cloud Storageに格納されます。Google Cloud Storageについてはこちらから
-
Create Datasetを選択して、しばらく待機します。
-
データセットの作成が完了すると、以下のような画面が表示されます。
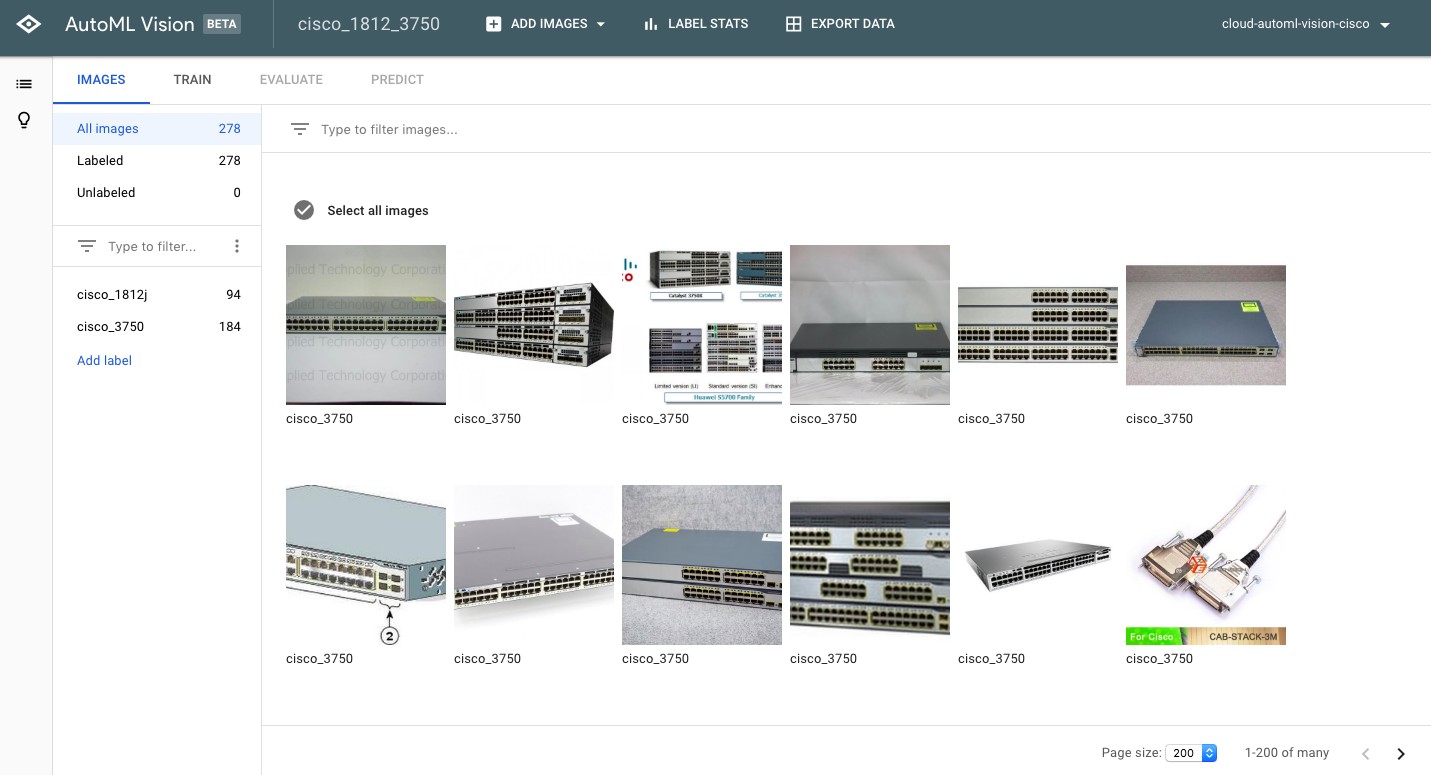
Datasetの修正(画像の削除)
-
ここからデータセットの修正を行います。アップロードした画像の中には、不要な画像や間違ったラベリングのされた画像が含まれることがあります。上記画面上でも、明らかに不要と思われる画像がいくつか含まれます。
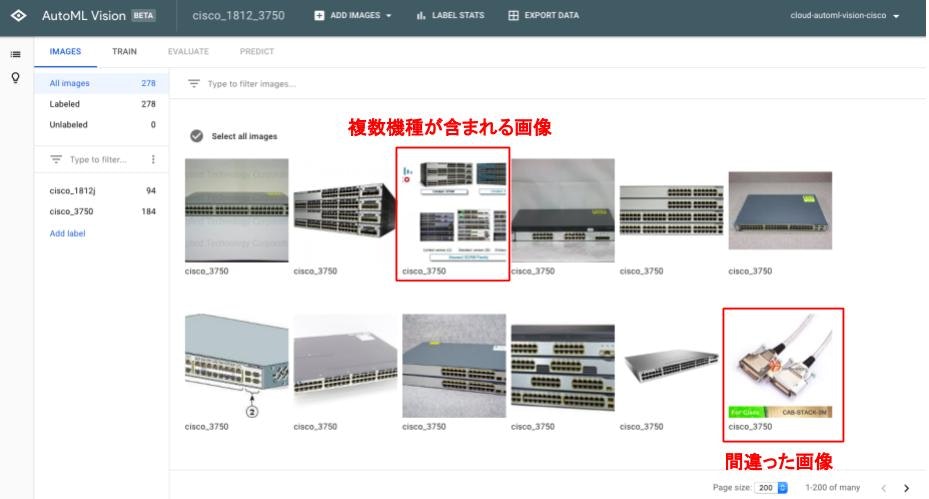
-
これらの画像を削除するには、削除対象の画像を選択し、Deleteを選択します。
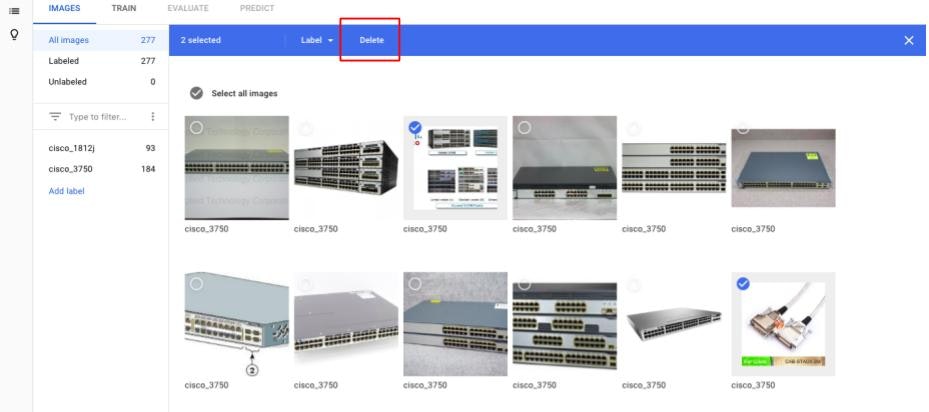
-
すると以下のような画面が表示され、画像を削除しても良いか確認されます。表示されたメッセージにあるように、Cloud Storageにアップした画像は削除されませんので、誤ってここで削除しても問題ありません。
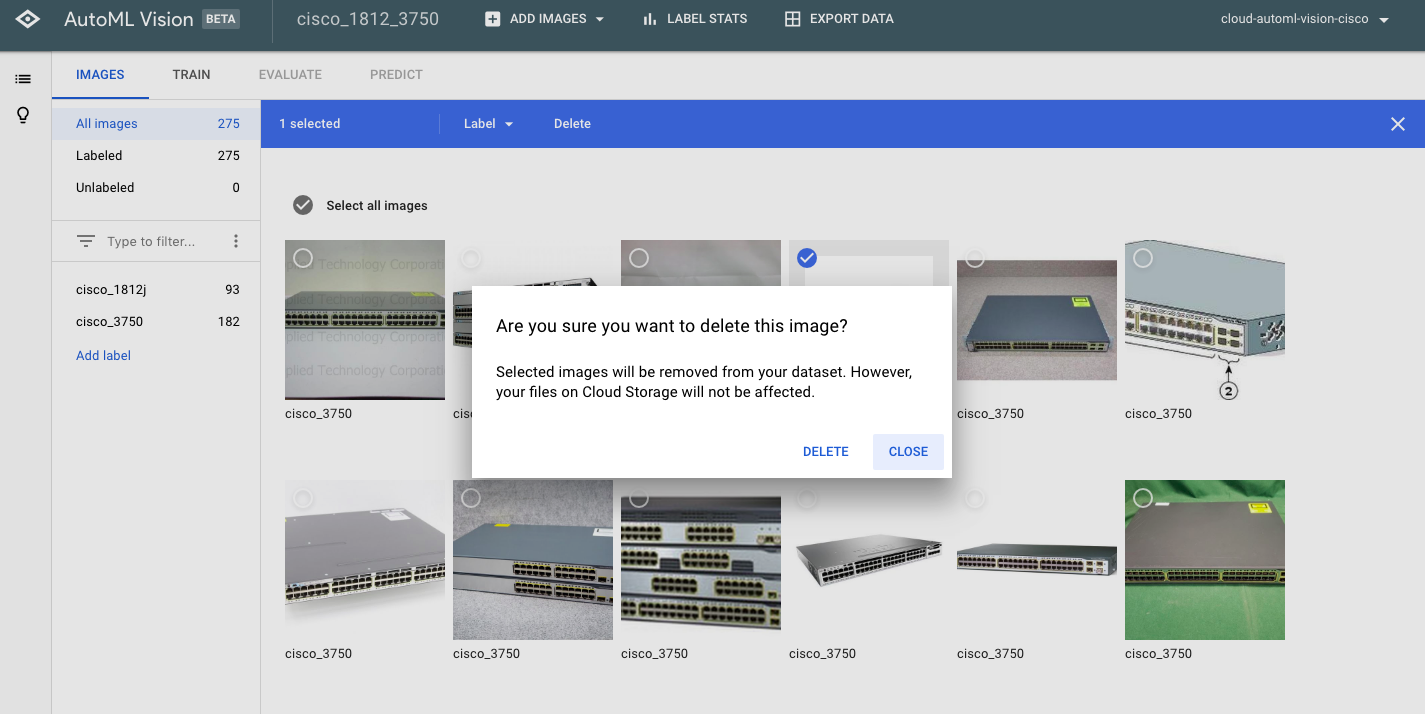
-
また誤ってラベリングした画像も、対象の画像を選択するとラベリングを簡単に修正することができます。

モデルの構築
-
ここからいよいよモデルの作成を行います。と言ってもやることは簡単です。まずはIMAGES画面からTRAINを選択します。
-
すると以下のような画面が表示されます。ここではデータセットにある画像の枚数がラベリングごとに表示されます。AutoML Visionでは1ラベルにつき10枚の画像が最低限必要となります。推奨するデータ数は100枚以上で、100枚に満たないラベルはオレンジ色のバーで表示されます。
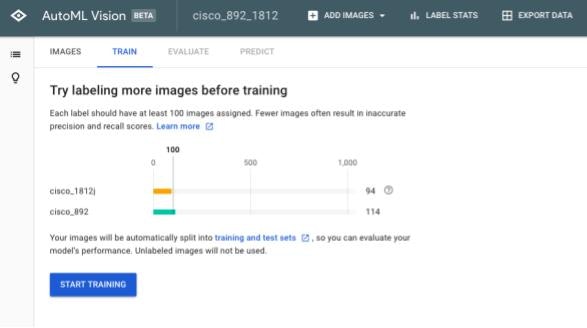
-
Start Trainingを選択すると、以下のような画面が表示されます。ここではモデルを訓練させる時間を選択できます。デフォルトでは1時間に設定されます。公式ページにあるように、毎月10個まではモデルごとの最初の1時間のトレーニングは無料になります。
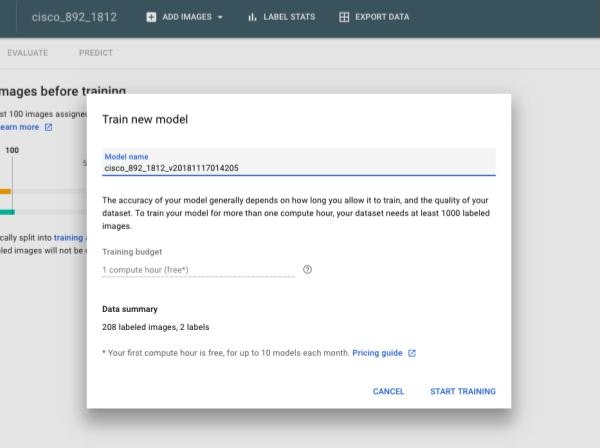
訓練の時間をさらに多くするには、最低1000枚のラベリングされたデータが必要になります。ここでは208枚しか画像がないため、選択することができません。
-
Start Trainingを選択すると、訓練が開始されます。
-
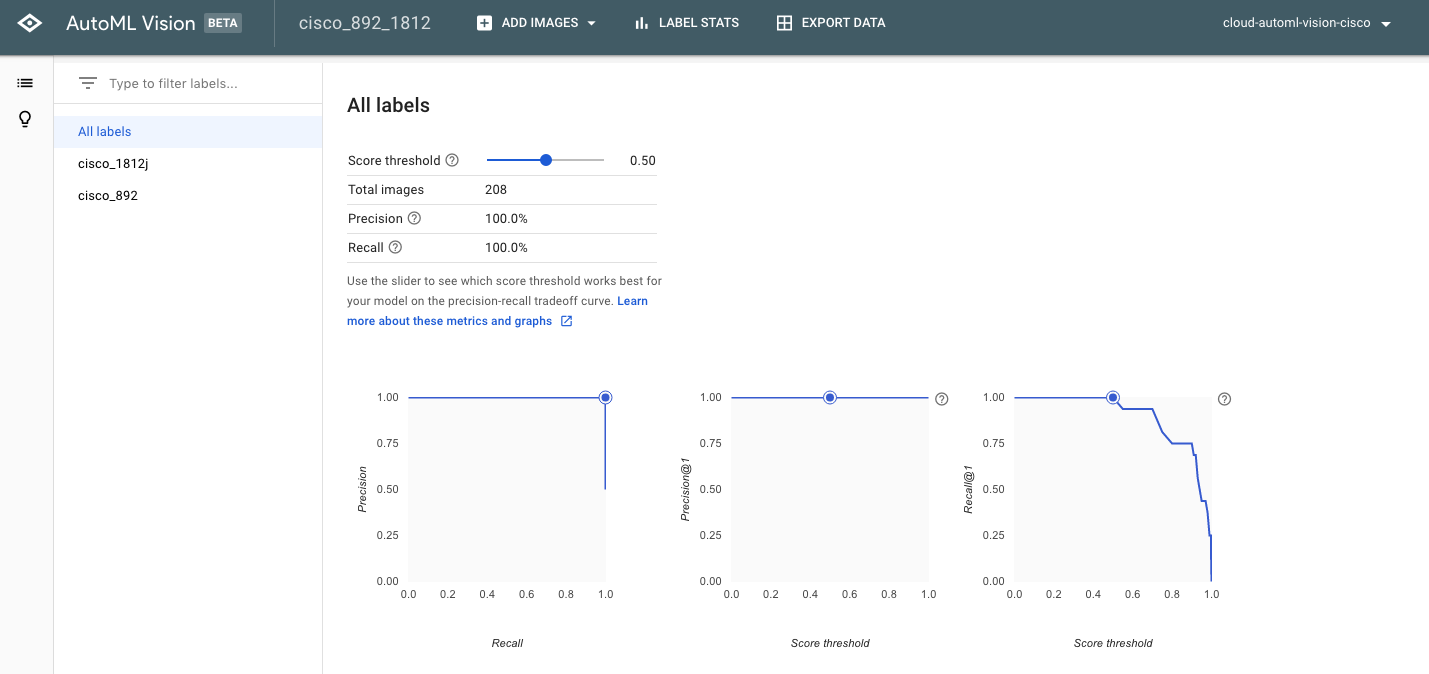
しばらくするとトレーニングが終了し、結果画面が表示されます。ここではまず3つの指標でモデルの性能を評価します。なお指標の見方等は公式ページに説明が書かれていますので、そちらをご覧ください。
- Average Precision: 適合率/再現率曲線の下部面積の値。0.5から1.0の値を取り、1.0に近いほどモデルの精度が高いことを示します。
- Precision: 適合率。
- Recall: 再現率。データセットの10%を使用してモデルの予測率を計測し、その精度を表示します。
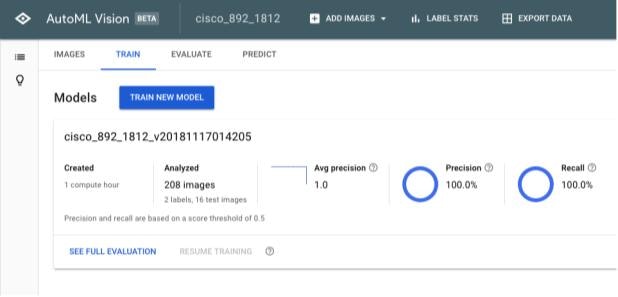
ここでは3つの指標すべてで1.0という値を表示して、とても高い性能であることが予想されます。しかし公式ページで指摘されているように、データが単純すぎてうまく一般化できず、汎化性能が低い可能性があります。実際ここでは2つのラベルでそれぞれ100枚程度しかデータを使用していないため、モデルとしての性能はイマイチであると予想されます。
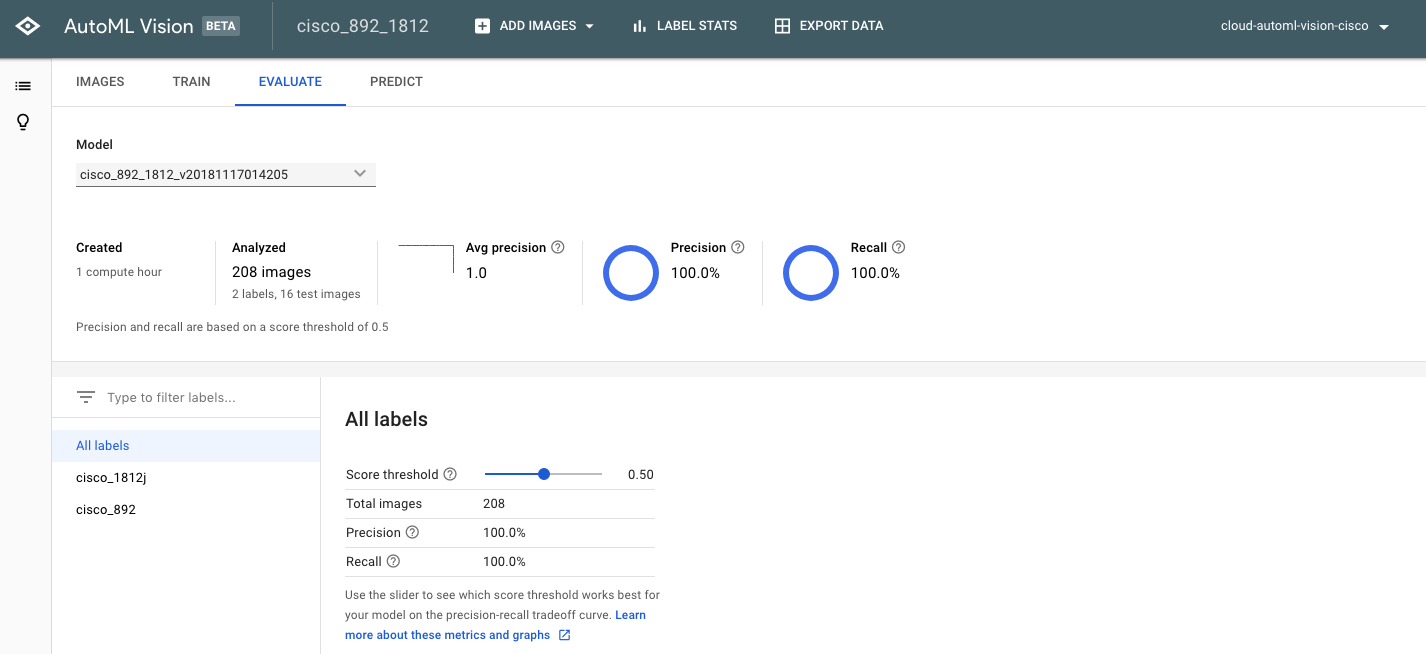
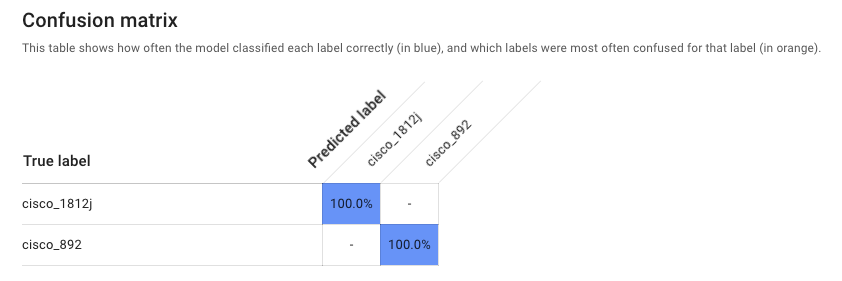
- より詳細な性能評価もすることができます。各ラベルでの適合率・再現率や混合行列を確認できます。混合行列では、各ラベルに対しての予測率などが確認できます。
モデルによる予測
-
ここでは構築したモデルに対してデータを与え、どのラベルに分類できるかを予測します。まずは画面上部のPREDICTを選択します。
-
するとデータをアップロードするように表示されるので、モデルに対する予測に用いる画像を選択しアップロードします。
-
アップロードしてしばらくすると予測結果が表示されます。ここではCisco 892の画像をアップロードしました。
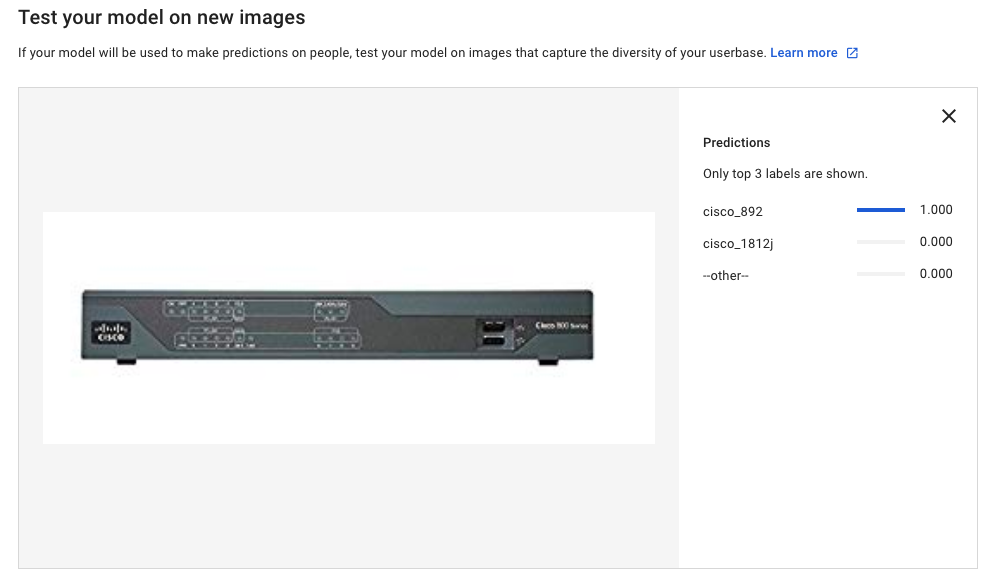
100%の確率でcisco_892であると予想されました。
-
続いてCisco1812Jの画像をアップロードすると、今度は87.9%の確率でcisco_1812jであると予想されました。
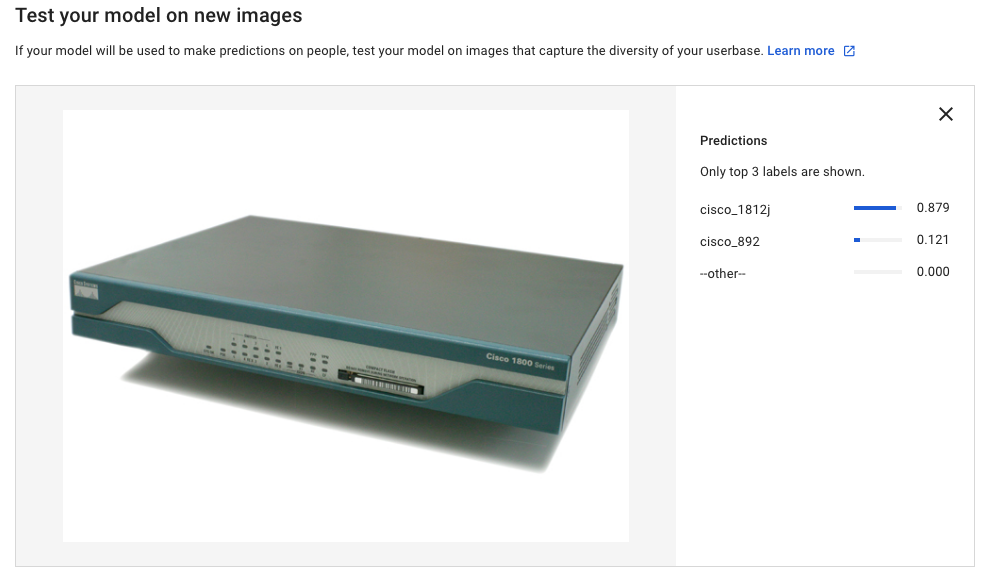
-
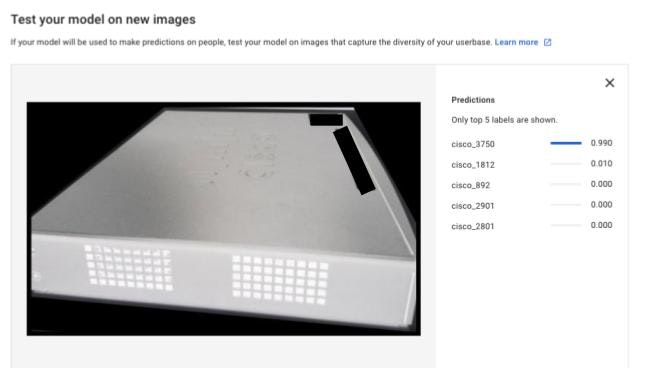
さらに今度はモデルには含めなかったCisco 3750の画像をアップロードすると、98.8%の確率でcisco_1812jであると予想されました。

訓練データに含まれないデータを予測させたので、当然ですが正しい予測はできません。予測をさせるには、そのラベルを含むデータセットを用意し、別のモデルを作成する必要があります。
複数ラベル分類
- 今度はデータを集めた10種類全てのデータを使用したモデルを作成します。データセットの概要とトレーニング結果は以下のようになります。
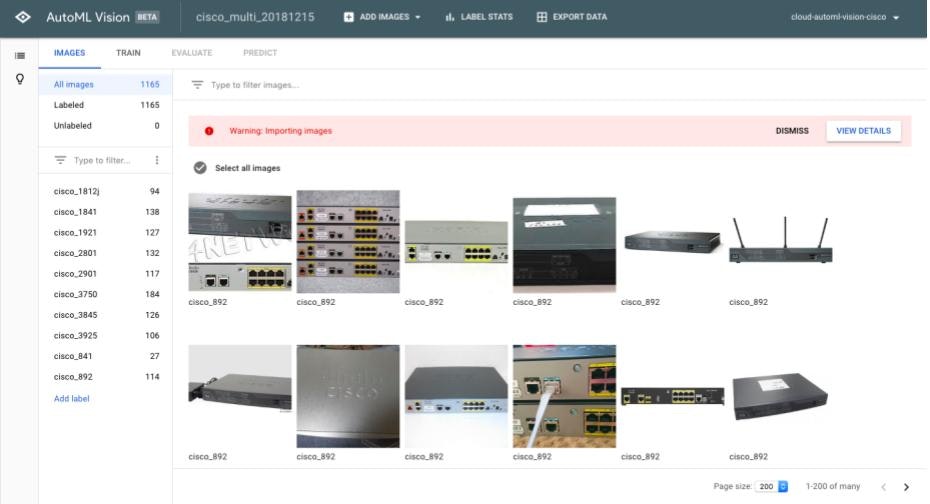
10種類のラベルの中にはデータの枚数が少ないものも含まれています。
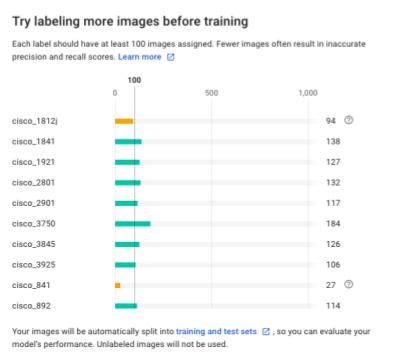

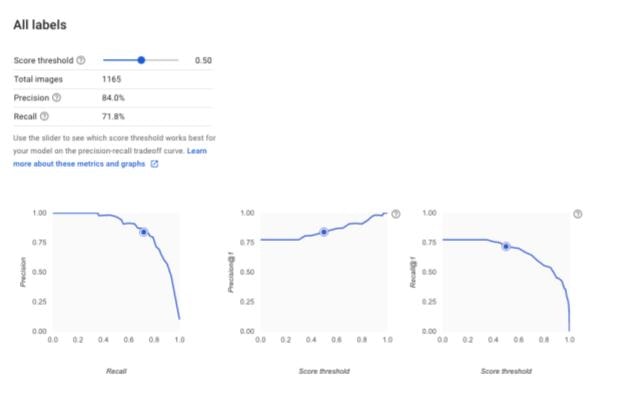
全体の予測率をみると、2値ラベル分類の時と比べて数値が低く表示されます。これは全体的にデータ数も少なく、また偏りがあるために精度も低くなったものと思われます。
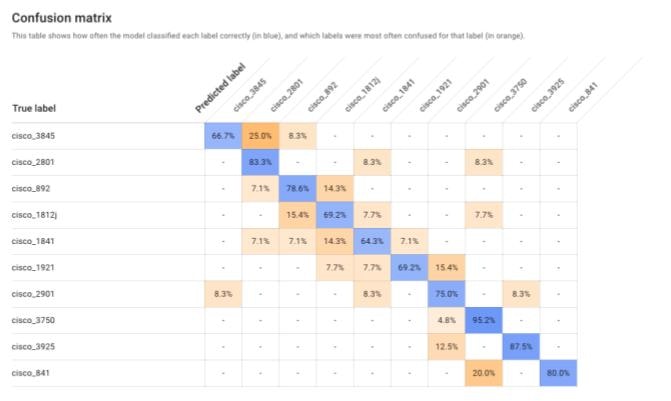
- 上記のように、複数ラベルの分類では、少なくとも2値ラベル分類の時よりも多くの画像データが必要であることが予想されます。そこで新たなデータを収集し、利用するデータ数を増やすことで精度を上昇させようと考えました。
データ数を増やす時の問題点
今回使用している画像はすべてWeb上から検索して集めたものです。そのためデータ数を増やそうと思った時は、さらに多くの枚数を集めれば良いのでは、と考えました。しかしその際、幾つかの問題に当たりました。
- 選別する必要がある
検索で集めた画像はすべてが使えるわけではありません。不要な画像は削除し使えるものだけを集める必要があります。検索で集めた画像が増えるほどその手間は増加し、多くの時間を必要とします。
- 検索件数を増やすほど検索精度が落ちてくる
今回はGoogle検索で引っかかったものを集めてきましたが、どの検索エンジンにも共通して言えるのは、検索件数が増えるほど、後に出てくる検索結果の精度が低下することです。検索ワードと関連性の高いものほど優先的に表示され、逆に関連性の低いものは後ろに表示されます。そのため、むやみに検索枚数を増やしたところでデータセットに使える画像の枚数はそれほど変わらないのではないか、と考えました。
上記の問題を解決するために、画像を増やす別の方法として画像データの増幅を考えました。これはあるひとつの画像を加工・変換して別の画像として扱うことで、データの総量を増加させる方法です。機械学習で画像データが少ない時に行われる方法としては一般的なものですが、私はこれまで試したことがありませんでした。
加工しているとはいえ元は同じ画像のため、対して効果はないのではないか、またモデル構築時の性能は上昇しても、実際に使用した時の性能、つまり汎化性能は上昇しないのではないか、と考えました。
今回の構築するモデルの精度を高めることだけでなく、上記の疑問に対してもアプローチすることを目的とし、画像の増幅を行い、改めてモデルの構築を行いました。
複数ラベル分類(画像データ増幅)
-
モデル構築に使用するデータは、はじめのモデル構築に使用した約1000枚に加え、加工したデータを加えます。データの加工はこちらの記事を参考に行いました。
-
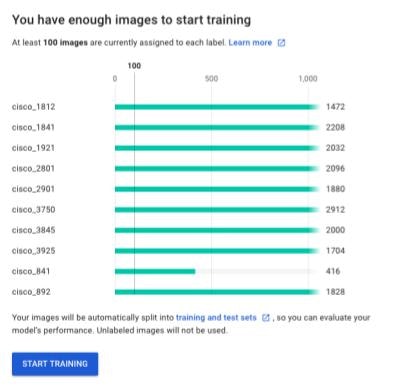
加工した画像を加えた結果、データセットの枚数は以下のようになりました。画像の総数は18548枚となりました。
-
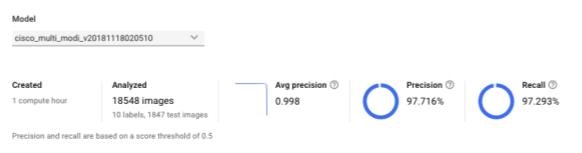
このデータセットを用いてモデルを構築したところ、精度がかなり上昇しました。
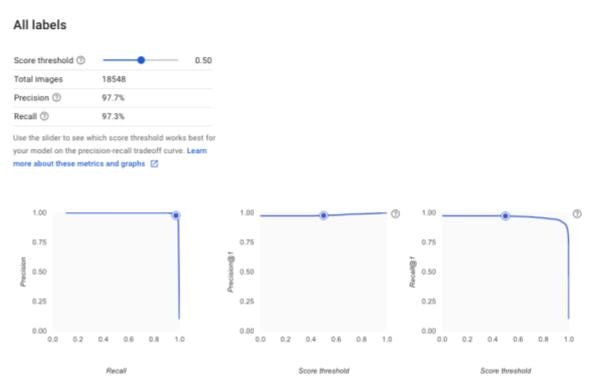
-
各ラベル間での予測率も大きく上昇し、全ラベルで90%以上の数値を表示しました。
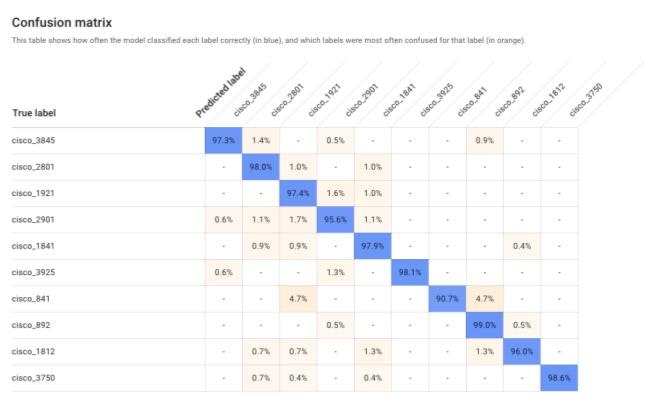
-
ここまでの結果を見るとData Augmentationには一定の成果があるように見えますが、幾つか懸念点があります。
-
公式ドキュメントにあるように、モデルの精度を評価する際の指標であるprecise/recallは、データセットの中からランダムに10%ずつ選んでテストしています。今回用いた画像の多くは加工データを含んでおり、元々は同じ画像から加工された画像が大量に含まれるため、当然精度は上昇することが予想されます。そのため、ここで表示される数値だけではモデルの精度を判断することはできません。モデルの精度を測るには、やはり汎化性能を見る必要があります。
汎化性能の評価
-
汎化性能を評価するため、弊社社内に置いてある検証用の機器を写真に収め、そのラベリングを予測しました。
-
まずは892を写真に撮って予測させてみると、94.8%の確率でcisco_892と予想され、正解します。
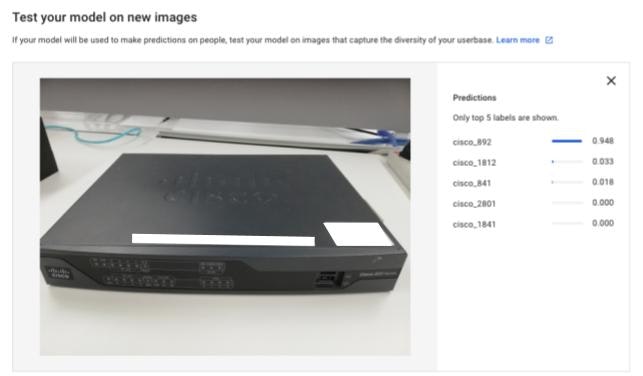
-
後ろから撮影した場合もこのように正解します。

-
Cisco 1812Jでもこのように正解します。
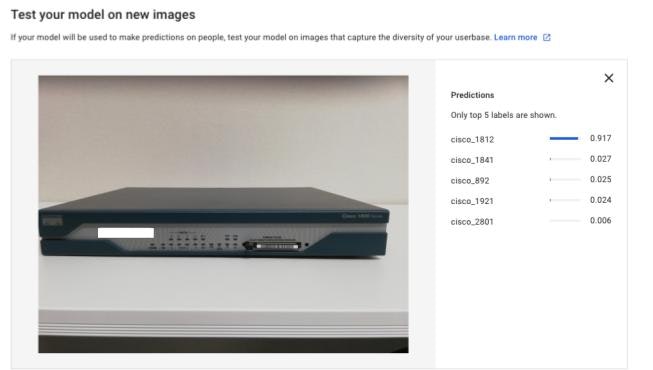
-
汎化性能はそれなりにあるように見えますが、撮影する角度を少し変えると正確に予測できなくなります。これは今回用いたデータセットの影響かと思いますが、Web上で上がっている画像の多くは機器の紹介で使われるため、正面や後ろからの写真です。そのためそこからずれた角度から撮った写真に対しては性能が落ちてしまう傾向にあるものと思われます。
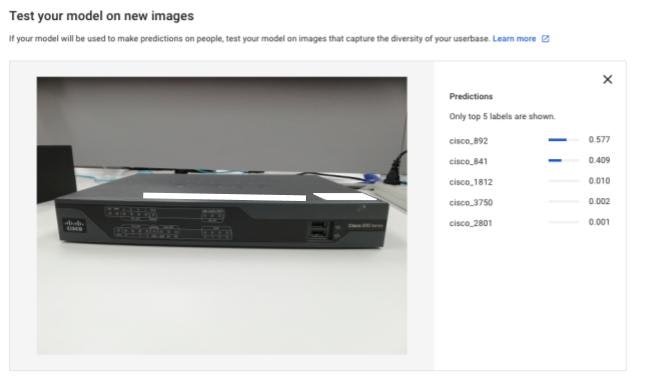
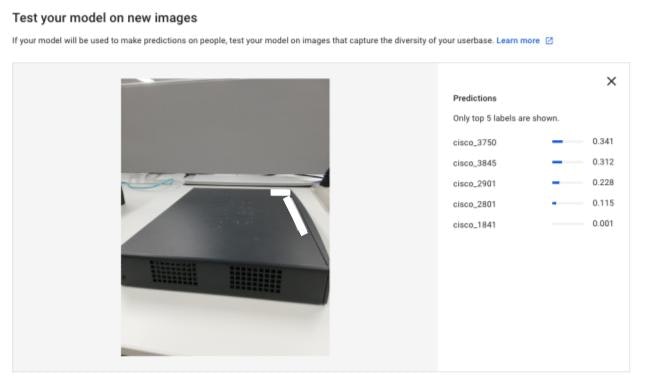
-
しかし角度だけではなく、背景などもノイズとして影響します。このように背景の部分を消してみると、先ほどと比べて性能が上昇することが確認できます。
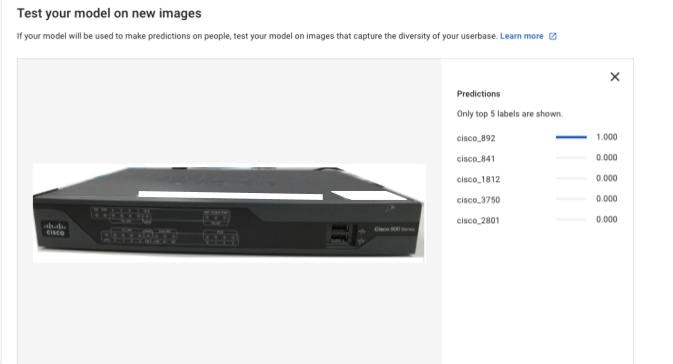
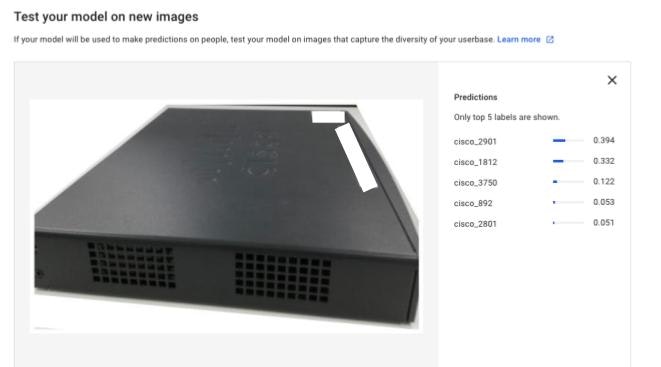
-
また予測する画像の色を反転させたりすると、やはり精度に影響します。構築したモデルでは機器の形状だけではなく色も含めて判断していることが予測できます。
まとめ
- AutoMLはデータを入れるだけでモデルが作成され、とても楽に機械学習を始めることができます。また使用する際の案内も丁寧で、Google Cloud自体が初めての方でも安心して使えると言う印象を受けました。
- またデータ数を増やすために画像データを増幅しても、一定の成果が得られることが確認できました。予測率は劇的に上昇し、汎化性能もそれなりにあることが確認できました。
- Cloud AutoML Visionを使うことで得られるメリットとして、データを集めることに集中できる点があります。アルゴリズムの選定、ハイパーパラメータの調整など、専門知識や経験の必要な部分をある程度無視できるため、他の作業に集中できるからです。一方でデータがなければ当然無理ですので、いかにして目的に沿ったデータを大量に集められるかが重要になります。また今回のように加工データを利用するだけでなく、例えばGANを用いることで新しいデータを作ることも考えられそうです。