目次
概要
Prometheus, Grafana, AlertMamagerを使った監視、アラート通知システムをDockerで作る。また、Node Expoerterを使ってリソースの監視をするところまで行う。
| ツール名 | 役割 |
|---|---|
| Prometheus | メトリクス収集 |
| grafana | メトリクス可視化 |
| AlertMamager | アラート通知 |
| Exporter | 次項を参照 |
Exporterとは
Exporterとは監視サーバーのサーバーのメトリクスを収集、出力するツールで、Prometheusがこれを回収する。メトリクスはPrometheusで保存される。
Exporterには、Officialで用意されているものや、Third-partyのものなど、監視する対象ごとに色々用意されている。詳しくは以下を参照。
https://prometheus.io/docs/instrumenting/exporters/
この記事では、サーバーのUp/Downを監視する仕組みを作るので、Node exporterを使う。
構成
監視サーバーにPrometheus, Grafana, AlertMamagerの3つをインストールする。
監視対象のサーバーにExporterをインストールする。
環境
- prometheus, version 2.27.1
- alertmanager, version 0.22.2
- grafana 7.5.9
Prometheus, Grafana, AlertMamagerの環境構築
これら3つを監視サーバーにインストールする。Dockerイメージが用意されているのでこちらを使う。
ディレクトリ構造
├── alertmanager
│ └── config.yaml
├── docker-compose.yaml
├── grafana
│ └── grafana.env
└── prometheus
├── alert.rules
├── node.yaml
└── prometheus.yaml
docker volume
$ sudo docker volume create metrics_data
$ sudo docker volume create grafana_data
docker-compose.yaml
Prometheus, Grafana, AlertMamager
version: '3'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
hostname: prometheus
volumes:
- ./prometheus:/etc/prometheus
- metrics_data:/prometheus
command:
- "--config.file=/etc/prometheus/prometheus.yaml"
# https://example.com/prometheus のようにサブディレクトリを切る場合
#- '--web.external-url=/prometheus'
ports:
- 9090:9090
restart: always
grafana:
image: grafana/grafana:7.5.9
container_name: grafana
hostname: grafana
volumes:
- grafana_data:/var/lib/grafana
ports:
- 3000:3000
env_file:
- ./grafana/grafana.env
restart: always
alertmanager:
image: prom/alertmanager
container_name: alertmanager
hostname: alertmanager
volumes:
- ./alertmanager:/etc/alertmanager
command:
- "--config.file=/etc/alertmanager/config.yaml"
# https://example.com/alertmanager のようにサブディレクトリを切る場合
#- "--web.route-prefix=/alertmanager"
ports:
- 9093:9093
restart: always
volumes:
metrics_data:
external: true
grafana_data:
external: true
prometheus.yaml
メトリクス収集の設定
global:
# メトリクスを収集する感覚
scrape_interval: 15s
# 監視ルールを評価する感覚
evaluation_interval: 15s
# メトリクス収集のタイムアウト値
scrape_timeout: 10s
external_labels:
# アラート通知に使われるAlertManagerの名前
monitor: 'sample-monitor'
# 監視ルール設定ファイルのパス
rule_files:
- /etc/prometheus/alert.rules
# AlertManagerの設定
alerting:
alertmanagers:
- scheme: http
# http://example.com:9093/alertmanager/ のようにサブディレクトリを切る場合はpath_prefixを定義する
#path_prefix: "/alertmanager/"
static_configs:
- targets:
# AlertManagerのHost名:Port番号
- alertmanager:9093
# メトリクス収集の設定
scrape_configs:
- job_name: prometheus
metrics_path: /metrics
static_configs:
- targets:
# prometheusサーバーのホスト
- your_prometeus.com:9090
# メトリクス収集するnodeサーバー
- job_name: node
metrics_path: /metrics
static_configs:
- labels:
env: development
- targets:
- example01.com:9100
# メトリクス収集する対象の定義を別ファイルに切り出すこともできる
- file_sd_configs:
- files:
- /etc/prometheus/node.yaml
job_name: node
node.yaml
別ファイルに切り出す場合。をメトリクス収集の対象を列挙する。Node Exporterのポートはデフォルトで9100。
- labels:
env: development
targets:
- example02.com:9100
- example03.com:9100
alert.rules
アラートのルール設定。
5分応答がなければアラートを上げる。
- name: example.com
rules:
- alert: instance_down
# PromQLを記述。起動していないインスタンスを検出するPromQL。
expr: up == 0
# 5分間応答がない場合アラートを上げる
for: 5m
labels:
severity: critical
# エラー文言
annotations:
# 異常時の通知メッセージ
firing_text: "[{{ $labels.env }}] {{ $labels.instance }} has been down for more than 5 minutes."
# リカバリー時の通知メッセージ
resolved_text: "[{{ $labels.env }}] {{ $labels.instance }} has recoverd."
config.yaml
アラートの通知先などの設定。Slackとメールに通知してみる。
global:
# Slack の webhook URL の指定
slack_api_url: 'https://hooks.slack.com/************'
# SMTP 接続先
smtp_smarthost: 'localhost:25'
smtp_require_tls: false
# アラート通知主の指定
smtp_from: 'Alertmanager <alert_from@example.com>'
route:
receiver: 'sample-route'
# 同一アラート名、インスタンス名、エラーレベルでグループ化、アラートを同じ種類とみなす条件
group_by: ['alertname', 'instance', 'severity']
# 同じ種類のアラートを1つのアラート群としてにまとめる時間
group_wait: 30s
# 同じ種類のアラートが発生した時に次回通知するまでの時間
group_interval: 5m
# 一度通知したアラートは10分おきに再通知
repeat_interval: 10m
receivers:
- name: 'sample-route'
slack_configs:
# Slack のチャンネル名
- channel: '#alert'
title: '{{ if eq .Status "firing" }}[FIRING]{{else}}[RESOLVED]{{end}} {{ .GroupLabels.alertname }}'
text: '{{ if eq .Status "firing" }}{{ .CommonAnnotations.firing_text }}{{else}}{{ .CommonAnnotations.resolved_text }}{{end}}'
# 正常に戻った際に通知をするか
send_resolved: true
email_configs:
# メールの宛先
- to: "alert_to@example.com"
grafana.env
Grafanaのサーバー設定。とりあえずこれでOK。
GF_SERVER_DOMAIN=localhost
GF_SERVER_HTTP_PORT=3000
GF_SERVER_PROTOCOL=http
# https://example.com/grafana のようにサブディレクトリを切る場合
# GF_SERVER_ROOT_URL=/grafana
Exporter
監視対象のサーバーにNode Exporterをインストールする。
docker-compose.yaml
version: '3'
services:
node-exporter:
image: quay.io/prometheus/node-exporter
container_name: node-exporter
ports:
- 9100:9100
volumes:
- /proc:/host/proc
- /sys:/host/sys
- /:/rootfs
networks:
- sample-network
networks:
sample-network:
external: true
メトリクスデータを保存するvolumeの作成
メトリクスデータが保存される場所は、パッケージからインストールした場合は/var/lib/prometheus/metrics以下となる。
公式Dockerイメージでは/prometheus以下に保存される。
$ docker volume create metrics_data
docker-compose up
$ docker-compose up -d --build
UI確認
Prometheus
メトリクス
http://your_prometeus.com:9090/graph
入力フォームにPromQLを入れることでメトリクスを確認できる。以下の例では、alert.rulesで設定した up を入力している。インスタンスが起動しているので、 1 となっている。 (1 = 正常、0 = 異常)

試しに監視対象をダウンさせてみる。
その後でalert.rulesで設定したPromQLを入れると、該当のnodeが検出される。値は 0 となっている。
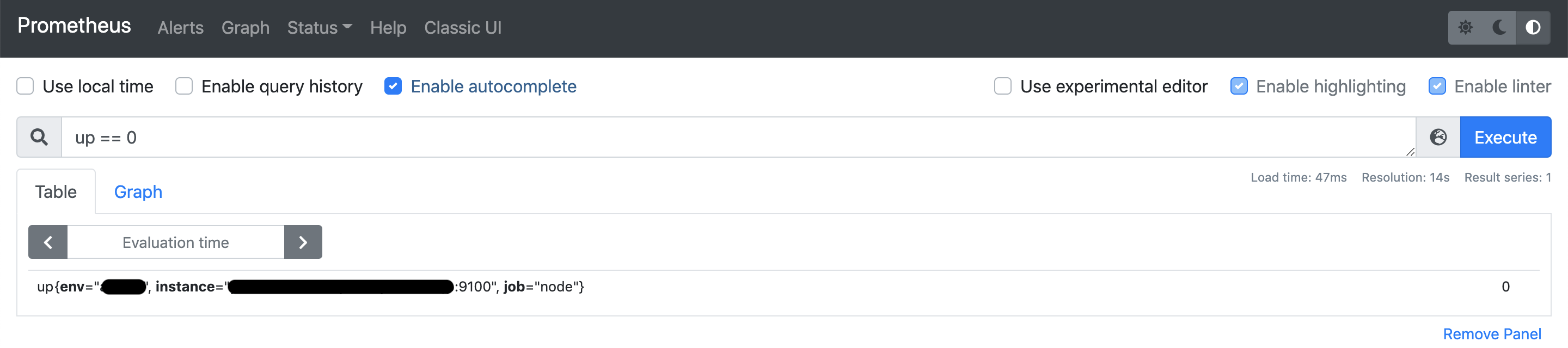
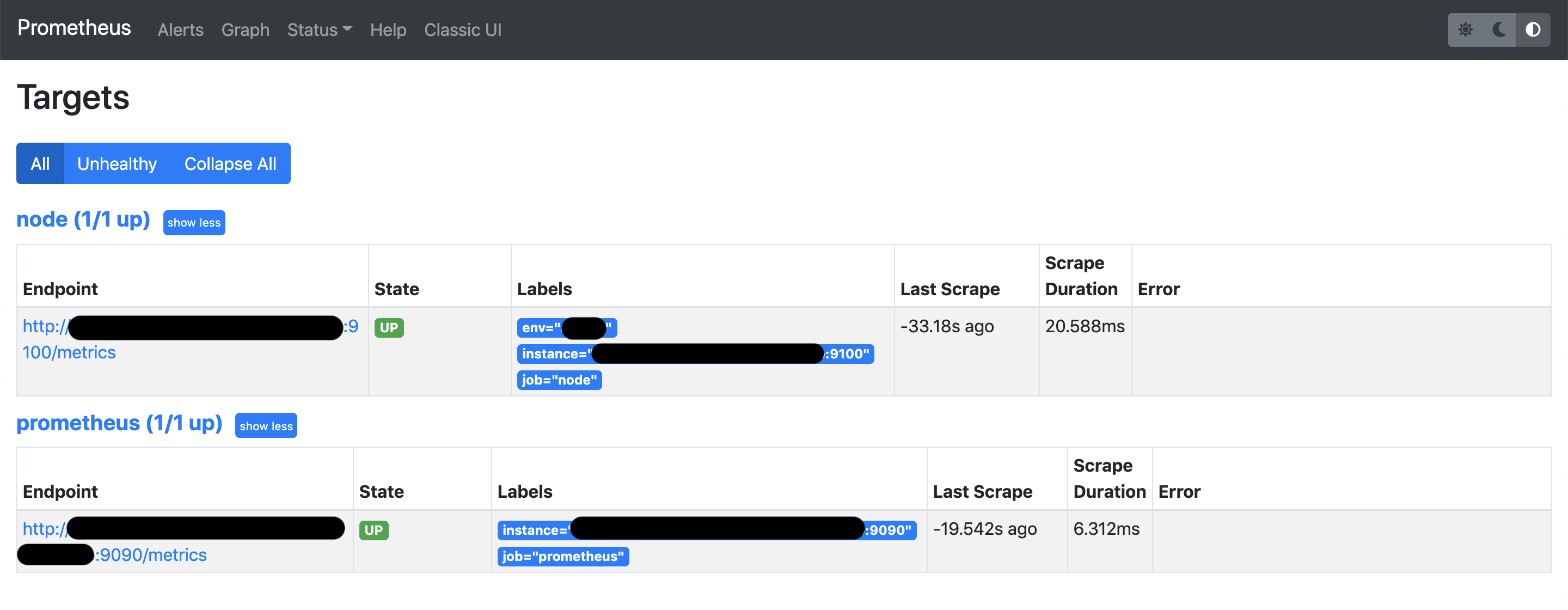
監視対象一覧
https://your_prometeus.com:9090/targets
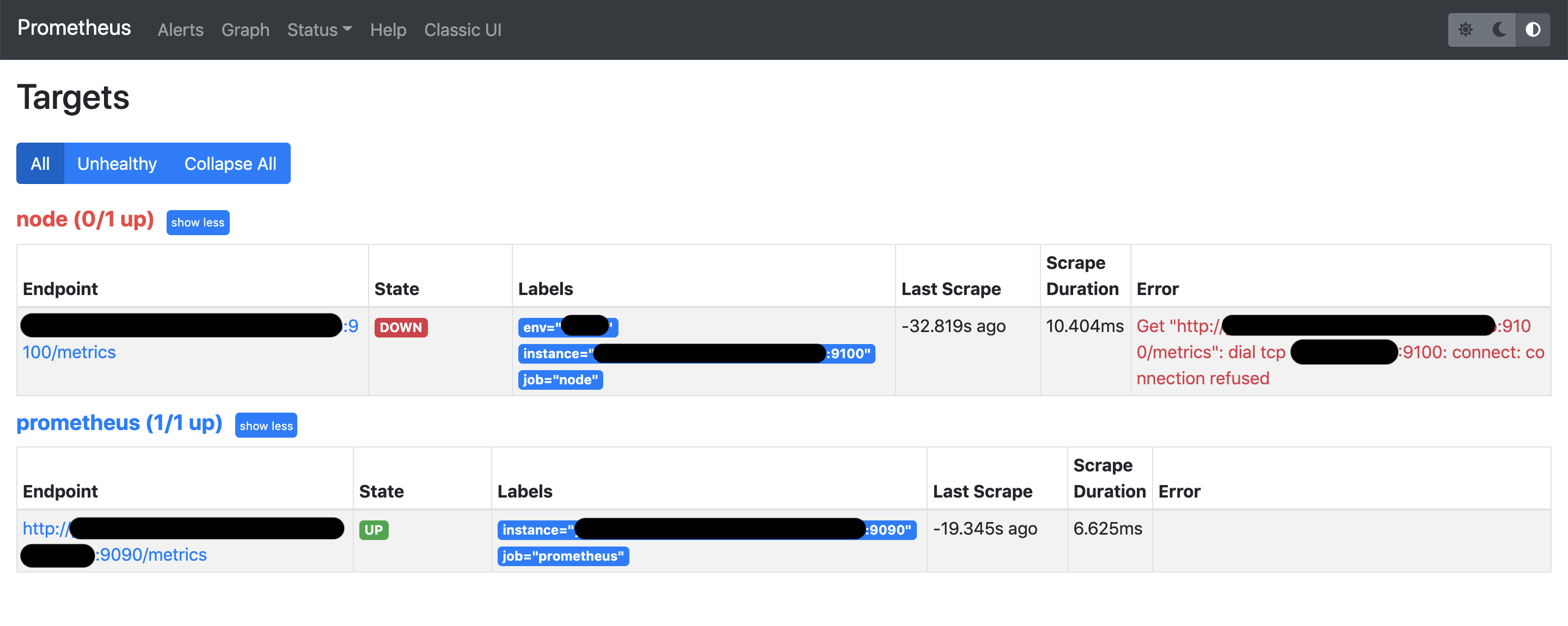
node-exporterをDownさせるとStateが Down になる。
AlertManager
https://your_prometeus.com:9093
監視対象をDownさせるとアラートが検出される。(今回の例では5分間応答がないとアラートが上がる。)
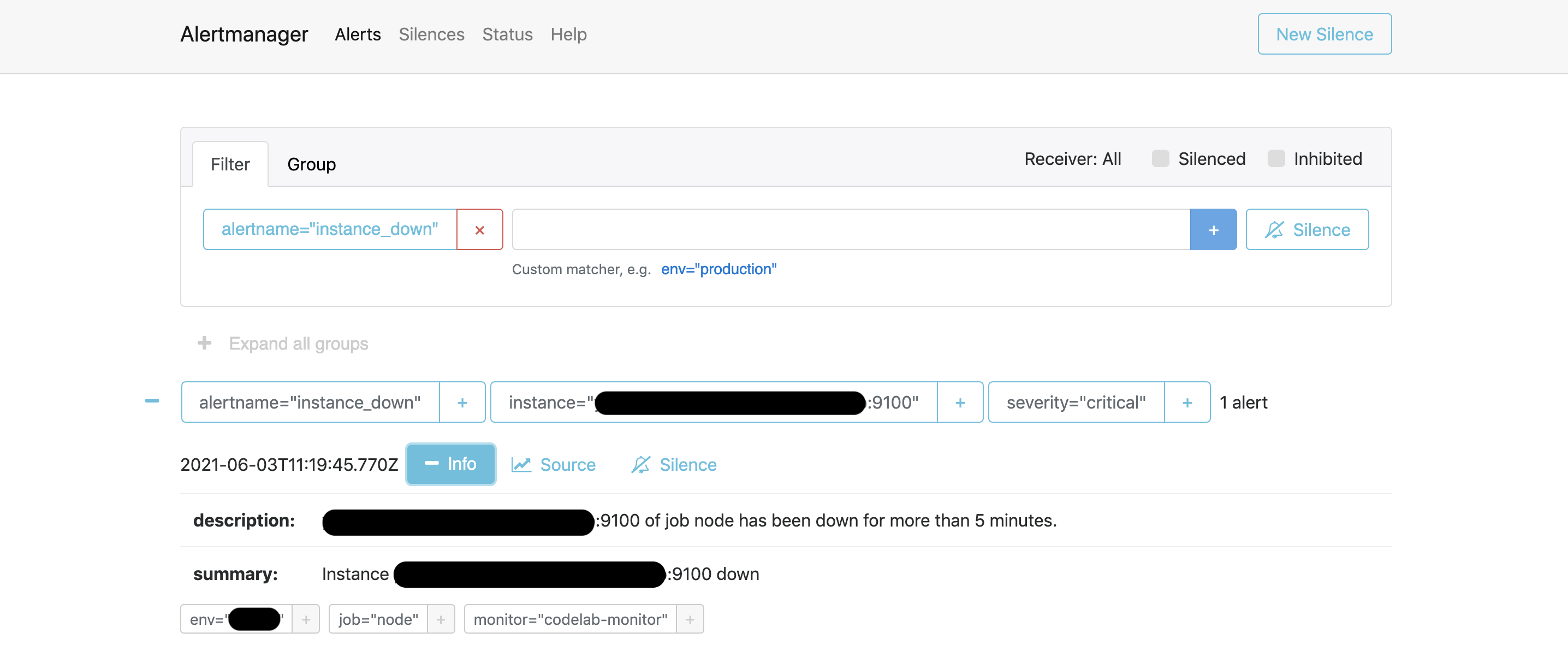
アラート通知
Slackにアラートが通知される。

アラートが解消されたときの通知

Grafana
https://your_prometeus.com:3000
初期アカウントはadmin:admin
Grafanaの詳しい使い方は以下を参照。
GrafanaでPrometheusを可視化する