はじめに
こんにちは.だいみょーじんです.
この記事は,第41回自作OSもくもく会および第42回自作OSもくもく会で発表した内容をまとめ,自作OSアドベントカレンダー2024の25日目の記事として公開したものです.
私が開発しているRust製のOS,HeliOSにおけるシャットダウンについて解説します.
環境
HeliOSはx64アーキテクチャ上で動作するOSで,以降の説明においてもx64アーキテクチャを想定します.
また,電源管理規格については,ACPIを想定します.
動作確認は以下の4通りの環境で行いました.
- QEMU
- VirtualBox
- VMware
- GPD MicroPC
あなたのOS,シャットダウンできますか?
シャットダウンは,OSが備えるべき重要な機能のひとつです.
しかし,OS自作におけるシャットダウンの実装は難易度が高く,シャットダウンを実装していないOSも多いです.
「30日でできる!OS自作入門」(ISBN 9784839919849)や「ゼロからのOS自作入門」(ISBN 9784839975869)ではシャットダウンは実装されていませんし,「作って理解するOS」(ISBN 9784297108472)もBochsでのシャットダウンにのみ対応しています.
(参考:「作って理解するOS」を読んで「QEMUで電断できねーじゃんか!」になった人を救いたい」)
今回私はx64アーキテクチャ上で動作するRust製の自作OS,HeliOSに,電源管理規格ACPIに従ったシャットダウンを実装したので,その原理についてこの記事にまとめます.
UEFIによるシャットダウン
そんな難しそうなシャットダウンですが,実は割と簡単な方法もあります.
それはUEFIのランタイムサービスに含まれるResetSystem関数を呼び出すという方法です.
UEFI Specification 8.5.1

しかし,この方法では一部の環境でシャットダウンできないことが確認されました.
| 実行環境 | ResetSystem関数によるシャットダウン |
|---|---|
| QEMU | 成功 |
| VirtualBox | 失敗 |
| VMware | 成功 |
| GPD MicroPC | 成功 |
確実にシャットダウンしたい場合は,やはり電源管理規格ACPIを直接いじるべきでしょう.
ACPIによるシャットダウン
ACPI Specification 7.4.2に,以下の6つの電源状態が定義されています.
| 電源状態 | CPUの命令の実行 | CPUのレジスタ | 主記憶 |
|---|---|---|---|
| S0 | 実行 | 保持 | 保持 |
| S1 | 停止 | 保持 | 保持 |
| S2 | 停止 | 破棄 | 保持 |
| S3 | 停止 | 破棄 | 保持 |
| S4 | 停止 | 破棄 | 補助記憶に退避 |
| S2 | 停止 | 破棄 | 破棄 |
S0が通常の実行状態で,数値が大きくなるほど深いスリープ状態となり,S5がシャットダウンされた状態です.
S2とS3にソフトウェアから見た違いはありませんが,ハードウェア面でS3の方がより消費電力が少なくなるそうです.
今回は,実行状態S0から,停止状態S5に遷移することを目指します.
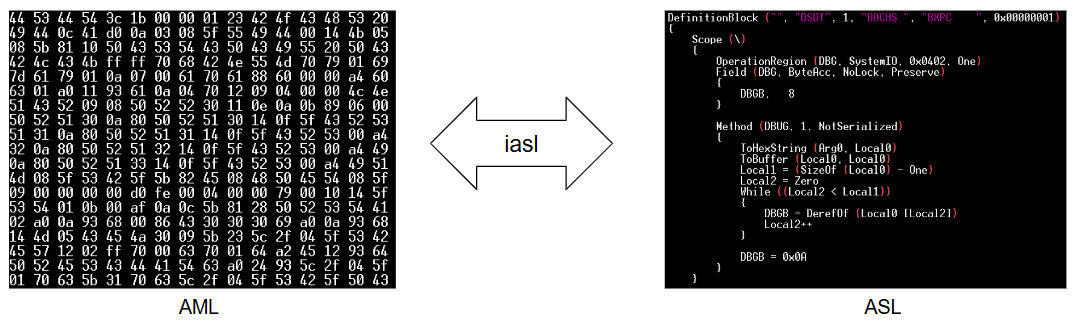
DSDTとAMLとASL
電源状態を遷移する手順は,ACPI System Description TableのひとつDSDT(Differentiated System Description Table)にAML(ACPI Machine Language)というバイナリ言語で記述されています.
HeliOSにおけるDSDTのソースコードはこちら
AMLの文法はACPI Specificationの第20章で定義され,約350種類の非終端記号と,0x00から0xffまでの256種類の終端記号を持ちます.
また,バイナリ形式の言語であるAMLに対応するテキスト形式の言語としてASL(ACPI Source Language)があります.
ASLの文法はACPI Specificationの第19章で定義されます.
AMLとASLはiaslというコマンドを使って相互に翻訳可能です.
シャットダウンの実装に必要なのはAMLのみですが,AMLは機械に読ませる言語であり人間には非常に読みずらいです.
AMLの解析器を開発する上で,手元にAMLをASLに翻訳したものも持っておいて,両者を照らし合わせながら開発を進めることをおすすめします.
AML構文解析のイメージをつかむ
さて,シャットダウンするために電源状態を遷移する手順が書かれたAMLを解析したいわけですが,AMLを解析するプログラムを書く前にまずは自分の手でAMLを解析して感覚をつかみましょう.
今回は練習として,以下のAMLコードを解析してみます.
44 42 47 5f
これを表計算ソフトか何かに入力します.
| 0x44 | 0x42 | 0x47 | 0x5f |
そして上に行を追加し,セルを結合してNameStringと記入します.
| NameString | |||
| 0x44 | 0x42 | 0x47 | 0x5f |
<NameString>は非終端記号の一つで,今回解析する4バイト全体が<NameString>という非終端記号から導出されることを示します.
今は例としてAMLの中の<NameString>の部分を抜き出して解析しているので<NameString>から解析を開始していますが,AMLは本来<AMLCode>を開始記号とするので,AML全体を解析する場合は<AMLCode>から解析を開始しなければならないことに注意してください.
1バイト目の解析
1バイト目は0x44つまり大文字のDです.
ACPI specificationの第20章に記述されている生成規則を見て,<NameString>からDに至る経路を探し出します.
すると以下のような経路が見つかります.
<NameString> ::= <RoorChar><NamePath> | <PrefixPath><NamePath>
<PrefixPath> ::= ε | <ParentPrefixChar><PrefixPath>
<NamePath> ::= <NameSeg> | <DualNamePath> | <MultiNamePath> | <NullName>
<NameSeg> ::= <LeadNameChar><NameChar><NameChar><NameChar>
<LeandNameChar> ::= 'A' | 'B' | 'C' | 'D' | ... | 'Z' | '_'
この記事では生成規則をバッカス・ナウア記法で記述することとします.
まず,<NameString>が<PrefixPath><NamePath>に展開されます.
次に,<PrefixPath>がεつまり空文字列に展開されます.
次に,<NamePath>が<NameSeg>に展開されます.
次に,<NameSeg>が<LeadNameChar><NameChar><NameChar><NameChar>
最後に,<LeadNameChar>がDつまり0x44に展開されます.
この経路を,表に記入します.
| NameString | |||
| NamePath | |||
| NameSeg | |||
| LeadNameChar | |||
| 0x44 | 0x42 | 0x47 | 0x5f |
2バイト目の解析
2バイト目は0x42つまり大文字のBです.
<NameSeg>は<LeadNameChar>の後に<NameChar>が続いているので,<NameChar>からBに至る経路を探し出します.
すると以下のような経路が見つかります.
<NameChar> ::= <DigitChar> | <LeadNameChar>
<LeadNameChar> ::= 'A' | 'B' | ... | 'Z' | '_'
まず,<NameChar>が<LeadNameChar>に展開されます.
次に,<LeadNameChar>がBつまり0x42に展開されます.
この経路を,表に記入します.
| NameString | |||
| NamePath | |||
| NameSeg | |||
| LeadNameChar | NameChar | ||
| LeadNameChar | |||
| 0x44 | 0x42 | 0x47 | 0x5f |
3バイト目の解析
3バイト目は0x47つまり大文字のGです.
<NameSeg>から展開された2つ目の<NameChar>からGに至る経路を探し出します.
すると以下のような経路が見つかります.
<NameChar> ::= <DigitChar> | <LeadNameChar>
<LeadNameChar> ::= 'A' | ... | `G` | ... | 'Z' | '_'
まず,<NameChar>が<LeadNameChar>に展開されます.
次に,<LeadNameChar>がGつまり0x47に展開されます.
この経路を,表に記入します.
| NameString | |||
| NamePath | |||
| NameSeg | |||
| LeadNameChar | NameChar | NameChar | |
| LeadNameChar | LeadNameChar | ||
| 0x44 | 0x42 | 0x47 | 0x5f |
4バイト目の解析
4バイト目は0x5fつまりアンダースコアです.
<NameSeg>から展開された3つ目の<NameChar>からアンダースコアに至る経路を探し出します.
すると以下のような経路が見つかります.
<NameChar> ::= <DigitChar> | <LeadNameChar>
<LeadNameChar> ::= 'A' | ... | 'Z' | '_'
まず,<NameChar>が<LeadNameChar>に展開されます.
次に,<LeadNameChar>が_つまり0x5fに展開されます.
この経路を,表に記入します.
| NameString | |||
| NamePath | |||
| NameSeg | |||
| LeadNameChar | NameChar | NameChar | NameChar |
| LeadNameChar | LeadNameChar | LeadNameChar | |
| 0x44 | 0x42 | 0x47 | 0x5f |
今回解析した4バイトのAMLは,DBG_という名前を意味しています.
そして,その4バイトを解析した結果できた上の表がまさに構文木となっているのです.
RustでAMLを構文解析
手動構文解析でAMLの感覚をつかんだところで,次は構文解析を行うプログラムをRustで書いていきましょう.
非終端記号の定義
AMLを解析するにあたって,まずは非終端記号をデータ型として表現します.
いくつか例を挙げます.
非終端記号<ExtOpPrefix>
生成規則
<ExtOpPrefix> ::= 0x5b
に対して,
pub struct ExtOpPrefix;
と定義します.
非終端記号<DefOpRegion>
生成規則
<DefOpRegion> ::= <OpRegionOp> <NameString> <RegionSpace> <RegionOffset> <RegionLen>
に対して,
pub struct DefOpRegion(
OpRegionOp,
NameString,
RegionSpace,
RegionOffset,
RegionLen,
);
と定義します.
非終端記号<DataObject>
生成規則
<DataObject> ::= <ComputationalData> | <DefPackage> | <DefVarPackage>
に対して,
pub enum DataObject {
ComputationalData(ComputationalData),
DefPackage(DefPackage),
DefVarPackage(DefVarPackage),
}
と定義します.
HeliOSにおけるこれらのデータ型の定義はこちら
Readerトレイト
データ型として表現した非終端記号に,以下のReaderトレイトを実装します.
pub trait Reader {
fn matches(aml: &[u8]) -> bool where Self: Sized;
fn read(aml: &[u8]) -> (Self, &[u8]) where Self: Sized;
}
matches関数は,引数として受け取ったAMLのバイト列の先頭が,非終端記号Selfとして解釈可能かどうかを返します.
read関数は,引数として受け取ったAMLのバイト列を構文解析し,非終端記号Selfを根とする構文木と,構文解析されなかった残りのAMLのバイト列を返します.
read関数のイメージ
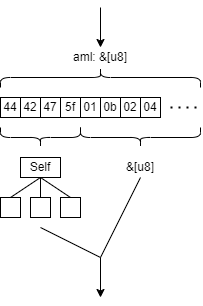
Readerトレイトの実装例を見てみましょう.
非終端記号<ExtOpPrefix>のReaderトレイト実装
impl Reader for ExtOpPrefix {
fn matches(aml: &[u8]) -> bool {
aml.first().is_some_and(|byte| *byte == 0x5b)
}
fn read(aml: &[u8]) -> (Self, &[u8]) {
(Self, &aml[1..])
}
}
<ExtOpPrefix>の生成規則は
<ExtOpPrefix> ::= 0x5b
です.
matches関数は,AMLのバイト列の先頭バイトが存在しその値が0x5bであるときに,そのAMLの先頭を<ExtOpPrefix>として解釈可能であると判定します.
read関数は,Selfと,AMLのバイト列の先頭の0x5bを取り除いた残りのバイト列を返します.
非終端記号<DefOpRegion>のReaderトレイト実装
impl Reader for DefOpRegion {
fn matches(aml: &[u8]) -> bool {
OpRegionOp::matches(aml)
}
fn read(aml: &[u8]) -> (Self, &[u8]) {
let (op_region_op, aml) = OpRegionOp::read(aml);
let (name_string, aml) = NameString::read(aml);
let (reagion_space, aml) = RegionSpace::read(aml);
let (region_offset, aml) = RegionOffset::read(aml);
let (region_len, aml) = RegionLen::read(aml);
(Self(
op_region_op,
name_string,
region_space,
region_offset,
region_len,
), aml)
}
}
<DefOpRegionの生成規則は
<DefOpRegion> ::= <OpRegionOp><NameString><RegionSpace><RegionOffset><RegionLen>
です.
matches関数は,AMLのバイト列の先頭が<OpRegionOp>として解釈できる場合,それは<DefOpRegion>としても解釈できると判定します.
read関数は,まずAMLのバイト列amlを<OpRegionOp>として解析し,解析結果op_region_opと残りのバイト列amlを取得します.
次にそのamlを<NameString>として解析し,解析結果name_stringと残りのバイト列amlを取得します.
次にそのamlを<RegionSpace>として解析し,解析結果region_spaceと残りのバイト列amlを取得します.
次にそのamlを<RegionOffset>として解析し,解析結果region_offsetと残りのバイト列amlを取得します.
次にそのamlを<RegionLen>として解析し,解析結果region_lenと残りのバイト列amlを取得します.
最後に,op_region_op,name_string,region_space,region_offset,region_lenをSelfとしてまとめ,残りのバイト列amlと共に返します.
非終端記号<DataObject>のReaderトレイト実装
impl Reader for DataObject {
fn matches(aml: &[u8]) -> bool {
ComputationalData::maches(aml)
| DefPackage::matches(aml)
| DefVarPackage::matches(aml)
}
fn read(aml: &[u8]) -> (Self, &[u8]) {
if ComputationalData::matches(aml) {
let (computational_data, aml) = ComputationalData::read(aml);
(Self::ComputationalData(computational_data), aml)
} else if DefPackage::matches(aml) {
let (def_package, aml) = DefPackage::read(aml);
(Self::DefPackage(def_package), aml)
} else if DefVarPackage::matches(aml) {
let (def_var_package, aml) = DefVarPackage::read(aml);
(Self::DefVarPackage(def_var_package), aml)
} else {
panic!("Invalud DataObject!")
}
}
}
<DataObject>の生成規則は
<DataObject> ::= <ComputationalData> | <DefPackage> | <DefVarPackage>
です.
matches関数は,AMLのバイト列の先頭が<ComputationalData>または<DefPackage>または<DefVarPackage>として解釈できる場合,それは<DataObject>としても解釈できると判定します.
read関数は,AMLのバイト列の先頭が<ComputationalData>として解釈できる場合,<ComputationalData>として解析したものをSelf::ComputationalDataの中に入れ,残りのバイト列と一緒に返します.
AMLのバイト列の先頭が<DefPackage>として解釈できる場合,<DefPackage>として解析したものをSelf::DefPackageの中に入れ,残りのバイト列と一緒に返します.
AMLのバイト列の先頭が<DefVarPackage>として解釈できる場合,<DefVarPackage>として解析したものをSelf::DefVarPackageの中に入れ,残りのバイト列と一緒に返します.
トレイト実装の自動化
上に示したように約350種類のAMLの非終端記号全てにReaderトレイトを実装していきます.
ひたすら実装していきます.
めげずに実装していきます.
なんかもうパターン見えてみました.
なんか同じようなコードばかり書いています.
単調なコーディング
飽きた
辛い
なんとかならないものでしょうか?
そこで登場するのがRustのderiveという機能です!
Rustで何らかの型を定義するときに,上に#[derive(A)]と書くと,その型にトレイトAが自動実装されるあの機能です.
実はこのRustのderiveを使って,データ型として表現した全ての非終端記号に,#[derive(Reader)]と書くだけで,Readerトレイトを実装することができるようになるわけです.
まずは,Rustのderiveの仕組みを眺めてみましょう.
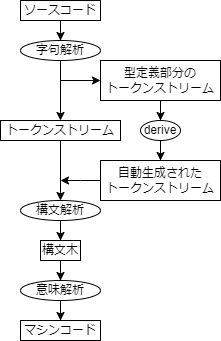
一般的なコンパイルの流れはこんな感じです.
- まずソースコードを字句解析して,字句の列であるトークンストリームを生成する.
- 次にトークンストリームを構文解析して字句同士の関係性を構文木として表現します.
- 最後に構文木を意味解析して,マシンコードを生成します.
この流れの中でRustのderiveが動くのは字句解析の後,構文解析の前です.
字句解析されたトークンストリームの中から,deriveが掛かった型定義部分のトークンストリームが掬い取られて,derive関数に入力されます.
derive関数は,deriveが掛かった型定義部分のトークンストリームを入力とし,その型がderiveするトレイトのimplブロックのトークンストリームを出力とします.
そして出力されたトークンストリームが本流のトークンストリームに合流することで,型にトレイトが自動的に実装されるわけです.
deriveによって自作トレイトを自動実装する場合,上の図におけるderive関数は,自分で作る必要があります.
derive関数の作り方
derive関数はカーネル本体のクレートとは別のクレートとして作成する必要があります.
kernel/Cargo.tomlに,acpi_machine_languageという新しいクレートを作ります.
[package]
name = "kernel"
version = "0.1.0"
edition = "2021"
[dependencies]
bitfield-struct = "0.5"
naked-function = "0.1.5"
[dependencies.acpi_machine_language]
path = "acpi_machine_language"
[profile.dev]
panic = "abort"
[profile.release]
panic = "abort"
[workspace]
members = ["acpi_machine_language"]
workspaceにacpi_machine_languageという新しいディレクトリを追加した上で,dependenciesの中に自作のクレートacpi_machine_languageを追加し,その場所は先ほどworkspaceに追加したacpi_machine_languageだよ,ということを書いておきます.
そして新しく作成したacpi_machine_languageクレートに対して,kernel/acpi_machine_language/Cargo.tomlを配置します.
[package]
name = "acpi_machine_language"
version = "0.1.0"
edition = "2021"
[dependencies]
proc-macro2 = "1.0.73"
quote = "1.0.34"
[dependencies.syn]
version = "2.0.44"
features = ["extra-traits"]
[lib]
proc-macro = true
proc-macro2やらquoteやらsynというのは,deriveを自作するときに使うお決まりのライブラリです.
そして,kernel/acpi_machine_language/src/lib.rsに,derive関数を記述します.
#[proc_macro_derive(Reader)]
pub fn derive(input: proc_macro::TokenStream) -> proc_macro::TokenStream {
...
}
#[proc_macro_derive(Reader)]と書くことによって,カーネル本体のソースコードにおいて型定義に#[derive(Reader)]と書かれると,その型定義部分のトークンストリームを入力としてこの関数が呼び出され,その型がReaderトレイトを実装するimplブロックのトークンストリームが出力されるという仕組みです.
derive関数の内部でやること
まずは入力された型定義部分のトークンストリームを構文解析します.
#[proc_macro_derive(Reader)]
pub fn derive(input: proc_macro::TokenStream) -> proc_macro::TokenStream {
let derive_input: DeriveInput = parse(input).unwrap();
...
}
入力された型定義部分のトークンストリームをparseしてunwrapすると,DeriveInput型という構文木が得られます.
DeriveInput型の定義を見てみましょう.
pub struct DeriveInput {
pub attrs: Vec<Attribute>,
pub vis: Visibility,
pub ident: Ident,
pub generics: Generics,
pub data: Data,
}
各フィールドは以下の通りです.
-
attrsは#[derive]や#[repr]といった,型に付加された属性の構文木 -
visはpubが付いているかどうかとか -
identは型名 -
genericsは型引数やライフタイムパラメータ部分の構文木 -
dataは型の中身の構文木
型の中身の構文木Dataを見てみましょう.
pub enum Data {
Struct(DataStruct),
Enum(DataEnum),
Union(DataUnion),
}
各値は以下の通りです.
-
Structは構造体の構文木 -
Enumは列挙体の構文木 -
Unionは共用体の構文木
構造体の構文木DataStructを見てみましょう.
pub struct DataStruct {
pub struct_token: Struct,
pub fields: Fields,
pub semi_token: Option<Semi>,
}
各フィールドは以下の通りです.
-
struct_tokenは構造体であることを示すstructという字句 -
fieldsは構造体の中身のフィールド一覧の構文木 -
semi_tokenは構造体の定義の最後に付くセミコロンの字句
構造体の中身のフィールド一覧Fieldsを見てみましょう.
pub enum Fields {
Named(FieldsNamed),
Unnamed(FieldsUnnamed),
Unit,
}
各値は以下の通りです.
-
Namedはstruct {...}で囲まれた名前付きフィールド一覧の構文木 -
Unnamedはstruct (...)で囲まれた名前なしフィールド一覧の構文木 -
Unitはフィールドをひとつも持たない構造体の構文木
名前付きフィールド一覧の構文木FieldsNamedを見てみましょう.
pub struct FieldsNamed {
pub brace_token: Brace,
pub named: Punctuated<Fields, Comma>,
}
各フィールドは以下の通りです.
-
brace_tokenはフィールド一覧を囲む括弧の字句 -
namedはフィールドの構文木の列で,.iter()メソッドで各フィールドの構文木&Fieldを出すイテレータが得られる
全部見て行くときりがないのでここまでにしておきますが,このように#[derive(Reader)]が掛けられた型定義の構文木がsynクレートに従って表現されるわけです.
また,Rustの構文木を調べる方法として,synクレートの他にAST Explorerを使うのも便利です.
AST Explorerはいろんな言語を構文解析してくれるサイトで,以下の画像のように言語としてRustを選択し,左側の入力欄にRustのコードを入力すると,右側に構文木を示してくれます.
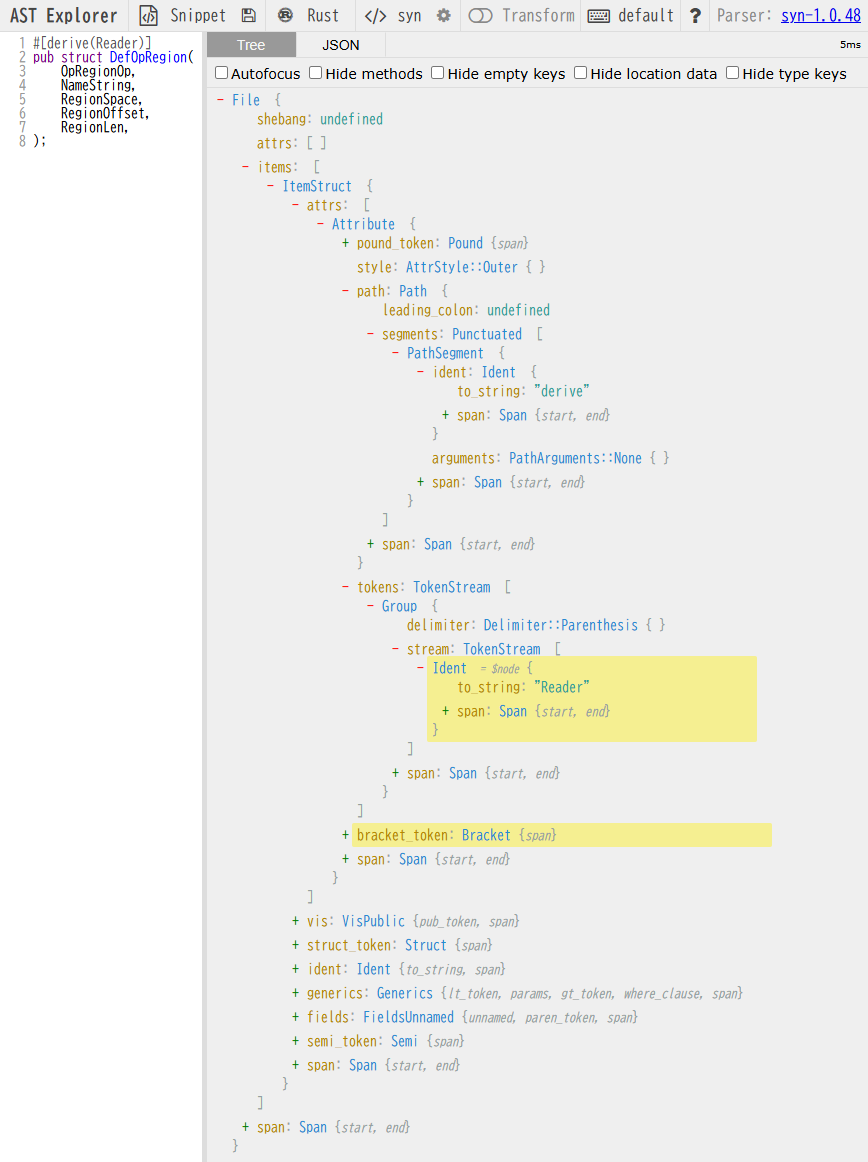
AST Explorerで#[derive(Reader)]が掛けられた型定義の構文木の構造を把握し,synクレートでその構造に従って構文木を解析しつつその型がReaderトレイトを実装するimplブロックを構築していくコードを書いていきます.
derive関数におけるコードの構築方法はこんな感じです.
let ident: Ident = ...;
let read: proc_macro2::TokenStream = ...;
let matches: proc_macro2::TokenStream = ...;
let reader: proc_macro2::TokenStream = quote! {
impl Reader for #ident {
fn read(aml: &[u8]) -> (Self, &[u8]) {
#read
}
fn matches(aml: &[u8]) -> bool {
#matches
}
}
};
型名などの識別子は,Ident型として表現されます.
トークンストリームはproc_macro2::TokenStream型として表現されます.
上のコードでは,Readerトレイトを実装する型の型名をidentに入れ,read関数の中身のコードを構築してreadに入れ,matches関数の中身のコードを構築してmatchesに入れています.
最後にそれらをreaderとしてまとめています.
コード構築の際にはquote!マクロを使用します.
単純にquote!マクロの中に書いたコードがトークンストリームに変換されます.
quote!マクロの中に#identや#readや#matchesと書かれていますが,これによってquote!マクロの中に上のlet文で作成しておいた識別子やトークンストリームを埋め込むことができます.
その他,書式で識別子を構築するformat_ident!マクロや,トークンストリームの配列tokenstreamsを指定した区切りdelimiterで結合する#(#tokenstreams)delimiter*という書き方も存在します.
詳細はderive関数の完全なソースコードはを参照してください.
derive関数へのパラメータ渡し
また,deriveによってある型にトレイトを実装させる際に,derive関数に何らかのパラメータを渡すことによって実装方法を調整することもできます.
例えばAMLの非終端記号に<ExtOpPrefix>があり,その生成規則は
<ExtOpPrefix> ::= 0x5b
です.
これは型としては
pub struct ExtOpPrefix;
と表現されますが,これに対するmatches関数は
fn matches(aml: &[u8]) -> bool
aml.first().is_some_and(|byte| *byte == 0x5b)
}
である必要があります.
しかし,derive関数へ入力される
#[derive(Reader)]
pub struct ExtOpPrefix;
というコードには,肝心の0x5bという値が含まれておらず,これではderive関数は非終端記号ExtOpPrefixのmatches関数において何の値と比較すればよいのかわかりません.
そこで,
#[derive(Reader)]
#[encoding_value = 0x5b]
pub struct ExtOpPrefix;
のようにパラメータを記載すると,derive関数への入力であるDeriveInput型
pub struct DeriveInput {
pub attrs: Vec<Attribute>,
pub vis: Visibility,
pub ident: Ident,
pub generics: Generics,
pub data: Data,
}
のattrsの中から#[encoding_value = 0x5b]の行の構文木を取り出し,正しいmatches関数を構築することができるようになるわけです.
このようにAMLの非終端記号の定義だけを書いておけば,#[derive(Reader)]によって構文解析を行うimplブロックを自動生成できるようになります.
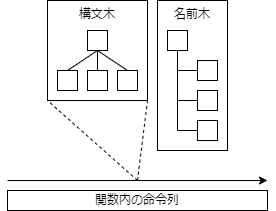
AML構文解析のラスボス,MethodInvocation
AMLの非終端記号の中でも特に構文解析が困難なものがあります.
それは関数呼び出しを意味する非終端記号<MethodInvocation>です.
生成規則は
<MethodInvocation> ::= <NameString><TermArgList>
<TermArgList> ::= ε | <TermArg><TermArgList>
となっています.
<NameString>は呼び出す関数名,<TermArg>は呼び出す関数に渡される引数で,<TermArgList>は0個以上の引数の列を意味します.
<MethodInvocation>の問題点は,引数の個数の情報がな,AMLのバイト列のうち,どこまでをTermArgListとして解釈すればよいのか分からないことです.
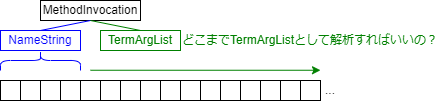
可変長の非終端記号のバイト数を示す非終端記号<PkgLengthLength>
実は,<MethodInvocation>以外にも可変長の非終端記号はたくさんあります.
例えば以下の生成規則を見てみましょう.
<DefScope> ::= <ScopeOp><PkgLength><NameString><TermList>
<TermList> ::= ε | <TermObj><TermList>
これだけ見ると,<TermList>の中にいくつ<TermObj>があるのか分かりません.
その情報は,<PkgLength>が持っています.
<PkgLength>を意味解析すると自然数が得られ,その自然数はAMLのバイト列における<PkgLength>の先頭から<TermList>の末尾までのバイト数を示しています.
つまり,<PkgLength>が100という値を表していたならば,<TermObj>をひとつずつ読んでいき,<PkgLength>の先頭から100バイト目の位置に到達したら,そこが<TermList>の終端であると判定できるのです.
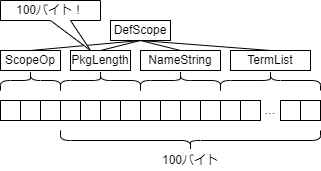
AMLにおける可変長の非終端記号を構文解析する方法が分かったところで,もう一度<MethodInvocation>の生成規則を見てみましょう.
<MethodInvocation> ::= <NameString><TermArgList>
<TermArgList> ::= ε | <TermArg><TermArgList>
なんで<PkgLength>持たせなかったの???
これは30日でできるOS自作入門風に言えば完全にインテルの人に聞いてください案件です.(ACPIはインテルだけでなく東芝やマイクロソフトも関わっています.)
ただし何の手掛かりもないわけではありません.
関数呼び出しがあるということは,当然関数定義も存在するわけです.
AMLにおける関数定義は,非終端記号<DefMethod>で表され,以下のような生成規則を持ちます.
<DefMethod> ::= <MethodOp><PkgLength><NameString><MethodFlags><TermList>
-
<MethodOp>は,「これから関数定義が始まるよ」というしるし -
<PkgLength>は,自信の先頭から<TermList>の終端までのバイト数 -
<NameString>は,関数名 -
<MethodFlags>は,固定長1バイトで,下位3ビットが引数の個数 -
<TermList>は,関数内の命令列
<MethodFlags>が引数の個数の情報を持っています.
つまり,AMLを構文解析する際に,DefMethodの引数の個数の情報を拾いながら読み進めていけば,<MethodInvocation>の引数の個数が分かるわけです.
ただし,いくつか注意点があります.
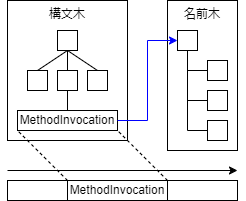
注意点その1:関数定義よりも前に関数呼び出しがある場合がある.
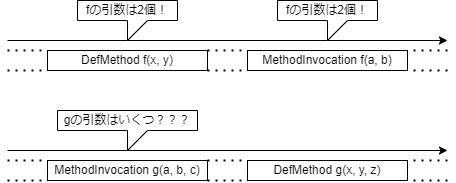
上の図の関数fは,先に関数fの定義が記述され,その後関数fの呼び出しが記述されています.
AMLを前から順番に読んでいけば,関数fの定義で関数fの引数が2個であることがわかり,関数fの呼び出しを構文解析するときに引数が2個であることがわかっているので,問題なく構文解析できます.
一方,関数gに関しては,先に関数gの呼び出しが記述され,その後に関数gの定義が記述されています.
AMLの構文解析は先頭から順番に読んでいき,読み飛ばしはできません.
関数gの呼び出しを構文解析しようとしても,それは構文解析器によっては未定義の関数であり,引数の個数はわかりません.
どうしたものか...
ここであまり自信のない仮説を思いつきました.
それは,
関数呼び出しは,関数の中にしか現れない
という仮説です.
もしこの仮説が正しければ,こんなことが可能になります.
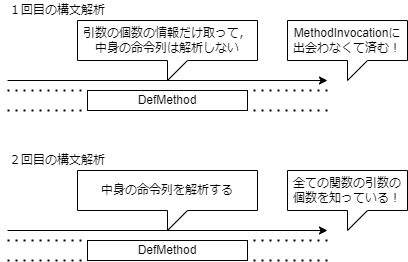
構文解析を,2回に分けます.
1回目の構文解析では,関数定義に出会ったときに,引数の個数の情報だけ取って,中身の命令列は解析しません.
仮説が正しければ,関数呼び出しに出会わなくて済みます.
そして,2回目の構文解析で,改めて関数の中身の命令列を構文解析します.
1回目の構文解析で全ての関数の引数の個数を得られるので,この段階では関数呼び出しも構文解析することができます.
この仮説は真と言えるでしょうか?
残念ながら,構文レベルでは関数の外で関数を呼び出すことは禁止されていません.
なぜならば,関数定義<DefMethod>を経由することなく関数呼び出し<MethodInvocation>に至る経路が存在するからです.
<AMLCode> ::= <DefBlockHeader><TermList>
<TermList> ::= ε | <TermObj><TermList>
<TermObj> ::= <Object> | <StatementOpcode> | <ExpressionOpcode>
<ExpressionOpcode> ::= .. | <MethodInvocation> | ..
しかし,私がHeliOSの動作確認に使用しているQEMU,VirtualBox,VMware,GPD MicroPCでは仮説は真でした.
動作確認用の全環境でこの仮説が真であることが確認できたので,この仮説を採用することにしました.
注意点その2:名前空間
AMLは名前空間<DefScope>及びデバイス<DefDevice>からなる意味的な階層構造を規定します.
例えば下の図において,最上位の名前空間\の下に,2つの名前空間SAとSBがあります.
SAの下にはデバイスMEMがあり,デバイスに対する書き込み関数SETと読み込み関数GETがあります.
SBの下には2つのデバイスMEMとCPUがあり,それぞれのデバイスに対する書き込み関数SETと読み込み関数GETがあります.
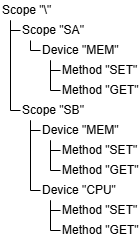
異なる名前空間,異なるデバイスに存在する同名の関数は,引数の個数が違うかもしれないので,ちゃんと区別する必要があります.
そのために,1回目の構文解析で,上の図のような名前木(と呼ぶことにする)を構築する必要があります.
また,構文木と名前木は形が違うことがあります.
これはどういうことかというと,以下のようなASLコードを考えてみましょう.
Scope (_SB)
{
Device (PCI0)
{
Method (^BN00, 0, NotSerialized)
{
...
}
}
}
名前空間_SBの中にデバイスPCI0があり,デバイスPCI0の中に関数BN00があるため,この関数の名前木上のパスも_SB.PCI0.BN00になるように思われますが,実は関数名^BN00の^が親を意味しているため,この関数はデバイスPCI0の中ではなく,名前空間_SBの直下にあります.
注意点その3:外部参照
外部参照は非終端記号<DefExternal>で表され,以下のような生成規則を持ちます.
<DefExternal> ::= <ExternalOp><NameString><ObjectType><ArgumentCount>
SSDTなど外部で定義されている関数のextern宣言のようなもので,<ArgumentCount>が引数の個数なので,この情報も持っておく必要があります.
注意点その4:エイリアス
エイリアスは非終端記号<DefAlias>で表され,以下のような生成規則を持ちます.
<DefAlias> ::= <AliasOp><NameString><NameString>
1つ目の<NameString>は,もともと存在する名前を表し,2つ目の<NameString>は,新しく付けられる名前を表します.
もともと存在する名前が相対パスである場合,その相対パスの起点は<DefAlias>が呼び出された場所ではなく,<DefAlias>が存在する場所であることに注意する必要があります.
関数がエイリアスで呼び出されることも当然あるので,そういう時なもとの名前を辿って適切に引数の個数を取得できるようにする必要があります.
注意点その5:「常識」の存在
名前がアンダースコアで始まる関数は,機種に依存することなく役割や機能が決まっています.
ACPIの仕様書の5.6.8や5.7に,そこら辺の情報が載っています.
引数の個数も暗黙に定められているので,調べておく必要があります.
以上の注意点を踏まえた上で,関数の引数の個数を取得する仕組みをRustで書いてみましょう.
まず名前木上のノードの住所を意味するパスを表現します.
ソースコードはこちら
pub enum Segment {
Child {
name: String,
},
Parent,
Root,
}
pub struct Path {
segments: VecDeque<Segment>,
}
pub struct AbsolutePath {
current: Path,
relative: Path,
}
Segmentは,子ノードChild,親ノードParent,根ノードRootを表現できる列挙体です.
Pathは,Segmentの列です.
AbsolutePathは,現在地currentと相対パスrelativeから絶対パスを求めるための構造体です.
次に名前木のノードを表現します.
pub struct Node {
name: Segment,
object: Object,
children: Vec<Self>,
}
pub enum Object {
Alias {
original_path: AbsolutePath,
},
CreateBitField,
CreateByteField,
CreateDWordField,
CreateField,
CreateQWordField,
CreateWordField,
DataRegion,
Device,
Event,
External {
number_of_arguments: usize,
},
Load,
Method {
number_of_arguments: usize,
},
Mutex,
Name,
NamedField,
OpRegion,
PowerRes,
Processor,
Scope,
ThermalZone,
}
AMLで定義されるあらゆるものを列挙する列挙型Objectを作っておいて,名前木を構成するノードをNodeという構造体として表現します.
Nodeは,名前をsegmentとして持ち,ノードの種類をobjectとして持ち,子ノードの集合をchildrenとして持ちます.
パスや名前木を表現できるようになったところで,1回目の解析と2回目の解析を実装していきます.
解析を2段階に分けるにあたって,まずは関数定義の非終端記号<DefMethod>に少し細工をします.
<DefMethod>の生成規則
<DefMethod> ::= <MethodOp><PkgLength><NameString><MethodFlags><TermList>
に対応するデータ型として
pub struct DefMethod(
MethodOp,
PkgLength,
NameString,
MethodFlags,
MethodTermList,
);
pub enum MethodTermList {
Binary(ByteList),
SyntaxTree(TermList),
}
を定義します.
MethodTermListが関数の中身の命令列を意味しますが,1回目の解析ではBinaryとしてバイト列のまま持っておき,2回目の解析でそれを構文解析してSyntaxTreeに変換します.
1回目の解析および2回目の解析を以下のようにトレイトとして表現します.
ソースコードはこちら
pub trait FirstReader {
fn first_read<'a>(aml: &'a [u8], root: &mut semantics::Node, current: &semantics::Path) -> (Self, &'a [u8]) where Self: Sized;
}
pub trait ReaderOutsideMethod {
fn read_outside_method(&mut self, root: &mut semantics::Node, current: &semantics::Path);
}
pub trait ReaderInsideMethod {
fn read_insize_method<'a>(aml: &'a [u8], root: &mut semantics::Node, current: &semantics::Path) -> (Self, &'a [u8]) where Self: Sized;
}
-
FirstReaderトレイトは,1回目の解析を行います.-
first_read関数は,関数外の構文解析を行い,関数内の命令列の構文解析は行わず,バイナリのまま持っておきます.- 第一引数amlは,解析対象のAMLです.
- 第二引数rootは名前木で,解析しながらノードを追加していきます.
- 第三引数curerntは名前木上の現在地です.
- 返り値は構文解析済みの非終端記号と,AMLお未解析の部分です.
-
-
ReaderOutsideMethodトレイトは,2回目の解析における関数の外側の解析を行います.-
read_outside_method関数は,基本的には自身の直下の非終端記号のread_outside_method関数を再帰的に呼び出し,MethodTermListがあったら,read_inside_method関数を呼び出します.- 第一引数selfは非終端記号で,自信のは以下の関数定義の中身の命令列をバイナリから構文木に変換するのでmutとしています.
- 第二引数rootは名前木で,関数定義内のローカル変数が追加されることがあるのでmutとしています.
- 第三引数currentは名前木上の現在地です.
-
-
ReaderInsideMethodトレイトは,2回目の解析における関数の内側の解析を行います.-
read_inside_method関数は,関数定義内の命令列を構文解析し,関数呼び出しに遭遇したら,名前木からその関数の引数の個数を取得して構文解析を続行します.- 第一引数amlは解析対象のAMLです.
- 第二引数rootは名前木で,関数の検索やローカル変数の追加などを行います.
- 第三引数currentは名前木上の現在位置です.
- 返り値は構文解析済みの非終端記号と,AMLの未解析の部分です.
-
これらのトレイトを,deriveを駆使して全ての非終端記号に実装していきます.
メソッドごとにトレイトを分けている理由は,deriveによる自動実装とソースコード直書きによる手動実装を柔軟に切り替えられるようにするためです.
それをやっている例が以下のコードです.
#[derive(Reader)]
#[manual(matcher)]
pub enum NameString {
AbsolutePath(
RootChar,
NamePath,
),
RelativePath(
PrefixPath,
NamePath,
),
}
impl Matcher for NameString {
fn matches(aml: &[u8]) -> bool {
DualNamePath::matches(aml)
|| MultiNamePath::matches(aml)
|| NameSeg::matches(aml)
|| ParentPrefixChar::matches(aml)
|| RootChar::matches(aml)
}
}
この例では,非終端記号<NameString>にReaderトレイトを自動実装していますが,#[manual(Matcher)]と指定することで,Readerトレイトからmatches関数だけを分離させたMatcherトレイトだけは手動実装しています.
このようにトレイトをメソッドごとに分離させることで,メソッドごとに自動実装と手動実装を切り替えることができます.
ここで,AMLの構文解析における2回読みの全体的な流れを確認しましょう.
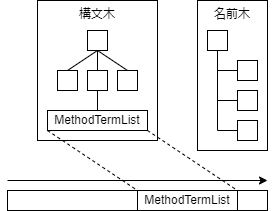
まずはFirstReaderトレイトによる1回目の解析です.
AMLを読みながら,構文木と名前木を同時に構築していきます.
関数内の命令列は,解析せずにバイナリのまま持っておきます.
次にReaderOutsideMethodトレイトによる2回目の解析です.
1回目の解析で得られた構文解析に対して,深さ優先探索の順番でread_outside_methodを再帰呼び出ししていきます.
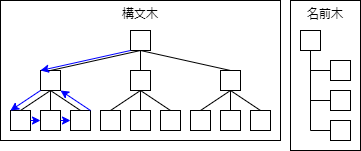
1回目の解析で解析せずにバイナリのまま持っておいた関数内の命令列MethodTermListに遭遇したら,ReaderInsideMethodトレイトのread_inside_method関数を呼び出します.
ReaderInsideMethodトレイトは,関数内の命令列を構文解析していきます.
関数呼び出しに遭遇したら,名前木からその関数を探し出して引数の個数を取得し,構文解析を続行します.
これでようやくAMLを構文解析できるようになりました!
AMLの実行
さて,電源状態を遷移する手順は,ACPI Specificationの7.5に記載されています.
電源状態S5に遷移する方法は,以下の通りです.
-
\_TTS(5)を実行 -
\_PTS(5)を実行 -
\_S5に記述された値をPM1a_CNT_BLKおよびPM1b_CNT_BLKに書き込む
関数\_TTS,関数\_PTS,値\_S5は,全てDSDTにAMLで記述されています.
関数\_TTSと関数\_PTSに関しては存在しない場合がありますが,その場合はその関数を実行する必要はありません.
DSDTの構文木の中から,その部分木として存在する関数\_TTS,関数\_PTS,値\_S5を探し出しましょう.
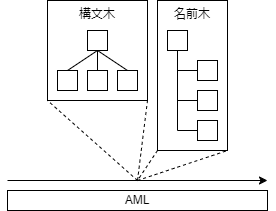
構文木の地図を作る
先程も説明したように,AMLは構文木の形と意味上の木の形が異なる場合があります.
そうなると\_TTSや\_PTSといったパスが与えられたとき,それに対応する構文木上の部分木がどこにあるかわからないので結局構文木全体を探し回る必要があります.
さらに,\_TTSや\_PTSといった関数からさらに別の関数が呼び出されることもあります.
そのたびに呼び出す関数を構文木から探していては,実行速度はかなり遅くなるでしょう.
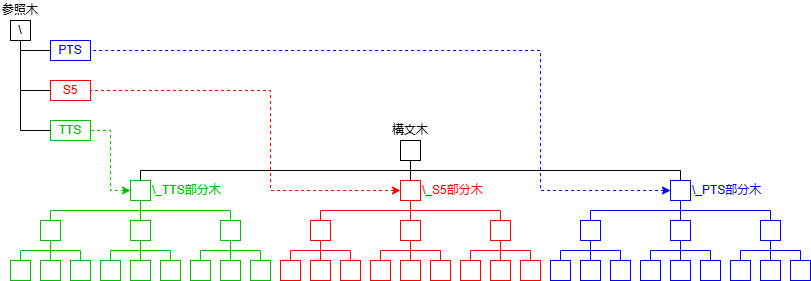
この問題を解決するために,下の図のようにパスから構文木の対応部分を参照する参照木をあらかじめ作っておきます.
参照木のソースコードはこちら
参照木は以下のノードから構成されます.
pub struct Node<'a> {
name: name::Segment,
objects: Vec<Object<'a>>,
children: Vec<Self>,
}
nameは\や_TTSといった名前を持ちます.
objectsはその名前が指し示す構文木上の部分木への参照を持ちます.
childrenは参照木上の子ノードを持ちます.
pub enum Object<'a> {
Alias(&'a syntax::DefAlias),
CreateBitField(&'a syntax::DefCreateBitField),
CreateByteField(&'a syntax::DefCreateByteField),
CreateDWordField(&'a syntax::DefCreateDWordField),
CreateField(&'a syntax::DefCreateField),
CreateQWordField(&'a syntax::DefCreateQWordField),
CreateWordField(&'a syntax::DefCreateWordField),
DataRegion(&'a syntax::DefDataRegion),
Device(&'a syntax::DefDevice),
Event(&'a syntax::DefEvent),
External(&'a syntax::DefExternal),
Load(&'a syntax::DefLoad),
Method(&'a syntax::DefMethod),
Mutex(&'a syntax::DefMutex),
Name(&'a syntax::DefName),
NamedField {
access_type: interpreter::AccessType,
named_field: &'a syntax::NamedField,
offset_in_bits: usize,
op_region: name::Path,
},
OpRegion(&'a syntax::DefOpRegion),
PowerRes(&'a syntax::DefPowerRes),
Processor(&'a syntax::DefProcessor),
Scope(&'a syntax::DefScope),
ThermalZone(&'a syntax::DefThermalZone),
}
構文木上の部分木への参照であるObject列挙型は,各種構文を表す非終端記号への参照を持ちます.
AMLのデータ型
AMLで表現しうるすべてのデータ型を列挙する列挙型Valueを定義します.
ソースコードはこちら
pub enum Value {
Bool(bool),
Buffer(Vec<u8>),
Byte(u8),
Char(char),
DWord(u32),
One,
Ones,
Package(Vec<Self>),
QWord(u64),
String(String),
Word(u16),
Zero,
}
それぞれのデータ型は以下のような意味を持ちます.
-
Boolは真理値 -
Bufferはバイト列 -
Byteは8ビット整数 -
Charは文字 -
DWordは32ビット整数 -
Oneは最下位ビットのみが1であるという情報のみを持ち,自身のビット数を定めない値 -
Onesは全ビットが1であるという情報のみを持ち,自身のビット数を定めない値 -
Packageは複数の値をまとめたタプル -
QWordは64ビット整数 -
Stringは文字列 -
Wordは16ビット整数 -
Zeroは全ビットが0であるという情報のみを持ち,自身のビット数を定めない値
値を表現できるようになったところで,次は値に対する演算を実装します.
以下に一部の演算の実装コードを掲載します.
fn match_type(&self, other: &Self) -> (Self, Self) {
match (self, other) {
(Self::Bool(left), Self::Bool(right)) => (Self::Bool(*left), Self::Bool(*right)),
(Self::Buffer(left), Self::Buffer(right)) => (Self::Buffer(left.clone()), Self::Buffer(right.clone())),
(Self::Buffer(left), Self::String(right)) => {
let right: Vec<u8> = right
.bytes()
.chain(iter::repeat(0x00))
.take(left.len())
.collect();
(Self::Buffer(left.clone()), Self::Buffer(right))
},
(Self::Byte(left), Self::Byte(right)) => (Self::Byte(*left), Self::Byte(*right)),
(Self::Byte(left), Self::DWord(right)) => (Self::DWord(*left as u32), Self::DWord(*right)),
(Self::Byte(left), Self::One) => (Self::Byte(*left), Self::Byte(0x01)),
(Self::Byte(left), Self::Ones) => (Self::Byte(*left), Self::Byte(0xff)),
(Self::Byte(left), Self::QWord(right)) => (Self::QWord(*left as u64), Self::QWord(*right)),
(Self::Byte(left), Self::Word(right)) => (Self::Word(*left as u16), Self::Word(*right)),
(Self::Byte(left), Self::Zero) => (Self::Byte(*left), Self::Byte(0x00)),
(Self::Char(left), Self::Char(right)) => (Self::Char(*left), Self::Char(*right)),
(Self::DWord(left), Self::Byte(right)) => (Self::DWord(*left), Self::DWord(*right as u32)),
(Self::DWord(left), Self::DWord(right)) => (Self::DWord(*left), Self::DWord(*right)),
(Self::DWord(left), Self::One) => (Self::DWord(*left), Self::DWord(0x00000001)),
(Self::DWord(left), Self::Ones) => (Self::DWord(*left), Self::DWord(0xffffffff)),
(Self::DWord(left), Self::QWord(right)) => (Self::QWord(*left as u64), Self::QWord(*right)),
(Self::DWord(left), Self::Word(right)) => (Self::DWord(*left), Self::DWord(*right as u32)),
(Self::DWord(left), Self::Zero) => (Self::DWord(*left), Self::DWord(0x00000000)),
(Self::One, Self::Byte(right)) => (Self::Byte(0x01), Self::Byte(*right)),
(Self::One, Self::DWord(right)) => (Self::DWord(0x00000001), Self::DWord(*right)),
(Self::One, Self::One) => (Self::One, Self::One),
(Self::One, Self::Ones) => (Self::One, Self::Ones),
(Self::One, Self::QWord(right)) => (Self::QWord(0x0000000000000001), Self::QWord(*right)),
(Self::One, Self::Word(right)) => (Self::Word(0x0001), Self::Word(*right)),
(Self::One, Self::Zero) => (Self::One, Self::Zero),
(Self::Ones, Self::Byte(right)) => (Self::Byte(0xff), Self::Byte(*right)),
(Self::Ones, Self::DWord(right)) => (Self::DWord(0xffffffff), Self::DWord(*right)),
(Self::Ones, Self::One) => (Self::Ones, Self::One),
(Self::Ones, Self::Ones) => (Self::Ones, Self::Ones),
(Self::Ones, Self::QWord(right)) => (Self::QWord(0xffffffffffffffff), Self::QWord(*right)),
(Self::Ones, Self::Word(right)) => (Self::Word(0xffff), Self::Word(*right)),
(Self::Ones, Self::Zero) => (Self::Ones, Self::Zero),
(Self::Package(left), Self::Package(right)) => (Self::Package(left.clone()), Self::Package(right.clone())),
(Self::QWord(left), Self::Byte(right)) => (Self::QWord(*left), Self::QWord(*right as u64)),
(Self::QWord(left), Self::DWord(right)) => (Self::QWord(*left), Self::QWord(*right as u64)),
(Self::QWord(left), Self::One) => (Self::QWord(*left), Self::QWord(0x0000000000000001)),
(Self::QWord(left), Self::Ones) => (Self::QWord(*left), Self::QWord(0xffffffffffffffff)),
(Self::QWord(left), Self::QWord(right)) => (Self::QWord(*left), Self::QWord(*right)),
(Self::QWord(left), Self::Word(right)) => (Self::QWord(*left), Self::QWord(*right as u64)),
(Self::QWord(left), Self::Zero) => (Self::QWord(*left), Self::QWord(0x0000000000000000)),
(Self::Revision, Self::Revision) => (Self::Revision, Self::Revision),
(Self::String(left), Self::String(right)) => (Self::String(left.clone()), Self::String(right.clone())),
(Self::Word(left), Self::Byte(right)) => (Self::Word(*left), Self::Word(*right as u16)),
(Self::Word(left), Self::DWord(right)) => (Self::DWord(*left as u32), Self::DWord(*right)),
(Self::Word(left), Self::One) => (Self::Word(*left), Self::Word(0x0001)),
(Self::Word(left), Self::Ones) => (Self::Word(*left), Self::Word(0xffff)),
(Self::Word(left), Self::QWord(right)) => (Self::QWord(*left as u64), Self::QWord(*right)),
(Self::Word(left), Self::Word(right)) => (Self::Word(*left), Self::Word(*right)),
(Self::Word(left), Self::Zero) => (Self::Word(*left), Self::Word(0x0000)),
(Self::Zero, Self::Byte(right)) => (Self::Byte(0x00), Self::Byte(*right)),
(Self::Zero, Self::DWord(right)) => (Self::DWord(0x00000000), Self::DWord(*right)),
(Self::Zero, Self::One) => (Self::Zero, Self::One),
(Self::Zero, Self::Ones) => (Self::Zero, Self::Ones),
(Self::Zero, Self::QWord(right)) => (Self::QWord(0x0000000000000000), Self::QWord(*right)),
(Self::Zero, Self::Word(right)) => (Self::Word(0x0000), Self::Word(*right)),
(Self::Zero, Self::Zero) => (Self::Zero, Self::Zero),
(left, right) => unimplemented!("left = {:#x?}, right = {:#x?}", left, right),
}
}
impl Add for Value {
type Output = Self;
fn add(self, other: Self) -> Self::Output {
match self.match_type(&other) {
(Self::Byte(left), Self::Byte(right)) => Self::Output::Byte(left + right),
(Self::Word(left), Self::Word(right)) => Self::Output::Word(left + right),
(Self::DWord(left), Self::DWord(right)) => Self::Output::DWord(left + right),
(Self::QWord(left), Self::QWord(right)) => Self::Output::QWord(left + right),
(Self::Zero, Self::Zero) => Self::Output::Zero,
(Self::Zero, Self::One) => Self::Output::One,
(Self::Zero, Self::Ones) => Self::Output::Ones,
(Self::One, Self::Zero) => Self::Output::One,
(Self::One, Self::One) => Self::Output::QWord(1 + 1),
(Self::Ones, Self::Zero) => Self::Output::Ones,
(left, right) => unimplemented!("left = {:#x?}, right = {:#x?}", left, right),
}
}
}
impl BitXor for Value {
type Output = Self;
fn bitxor(self, other: Self) -> Self::Output {
match self.match_type(&other) {
(Self::Byte(left), Self::Byte(right)) => Self::Output::Byte(left ^ right),
(Self::Word(left), Self::Word(right)) => Self::Output::Word(left ^ right),
(Self::DWord(left), Self::DWord(right)) => Self::Output::DWord(left ^ right),
(Self::QWord(left), Self::QWord(right)) => Self::Output::QWord(left ^ right),
(Self::Zero, Self::Zero) => Self::Output::Zero,
(Self::Zero, Self::One) => Self::Output::One,
(Self::Zero, Self::Ones) => Self::Output::Ones,
(Self::One, Self::Zero) => Self::Output::One,
(Self::One, Self::One) => Self::Output::Zero,
(Self::One, Self::Ones) => Self::Output::QWord(1 ^ u64::MAX),
(Self::Ones, Self::Zero) => Self::Output::Ones,
(Self::Ones, Self::One) => Self::Output::QWord(u64::MAX ^ 1),
(Self::Ones, Self::Ones) => Self::Output::Zero,
(left, right) => unimplemented!("left = {:#x?}, right = {:#x?}", left, right),
}
}
}
他にもいくつかの演算を実装しています.
詳細はソースコードを参照してください.
AMLのスタックフレーム
他のプログラミング言語がそうであるように,AMLも関数を実行するためのスタックフレームを必要とします.
pub struct StackFrame {
arguments: [Option<Value>; 0x07],
broken: Vec<bool>,
continued: Vec<bool>,
locals: [Option<Value>; 0x08],
named_locals: BTreeMap<name::Path, Value>,
return_value: Option<Value>,
}
-
argumentsは,現在実行中の関数に渡された引数 -
brokenは,while文実行中にbreak命令が実行されたかどうかを表す真理値 -
continuedは,while文実行中にcontinue命令が実行されたかどうかを表す真理値 -
localsは,現在実行中の関数のローカル変数 -
named_localsは,現在実行中の関数の名前付きローカル変数 -
return_valueは,現在実行中の関数が返すべき値
AMLの式の評価
構文木中の式を表す構文に対し,コンテキストを与えてその式を評価し,評価結果を返すEvaluatorトレイトを定義します.
pub trait Evaluator {
fn evaluate(&self, stack_frame: &mut StackFrame, root: &reference::Node, current: &name::Path) -> Option<Value>;
}
-
selfは,評価対象となる式を表す構文の非終端記号 -
stack_frameは,現在実行中の関数のスタックフレーム -
rootは,参照木の根ノード -
currentは,参照木上の現在地の絶対パス
evaluate関数は,これらの情報をもとに式を評価し,その評価結果をOption<Value>として返します.
Evaluatorトレイトの実装例
ここで,Evaluatorトレイトの実装例をいくつが紹介しましょう.
1バイトの定数の評価
1バイトの定数を表す構文の非終端記号ByteDataに対しては,その1バイトの定数を取り出して,Value列挙型のByteに入れて返します.
pub struct ByteData(u8);
impl Evaluator for ByteData {
fn evaluate(&self, _stack_frame: &mut interpreter::StackFrame, _root: &reference::Node, _current: &name::Path) -> Option<interpreter::Value> {
let Self(byte) = self;
Some(interpreter::Value::Byte(*byte))
}
}
バイト列の定数の評価
バイト列の定数を表す構文の非終端記号ByteListに対しては,そのバイト列からByteDataをひとつずつ取り出し,評価し,Vec<u8>にまとめ,Value列挙型のBufferに入れて返します.
pub struct ByteList(Vec<ByteData>);
impl Evaluator for ByteList {
fn evaluate(&self, stack_frame: &mut interpreter::StackFrame, root: &reference::Node, current: &name::Path) -> Option<interpreter::Value> {
let Self(byte_list) = self;
Some(interpreter::Value::Buffer(byte_list
.iter()
.filter_map(|byte_data| byte_data
.evaluate(stack_frame, root, current)
.and_then(|byte_data| byte_data.get_byte()))
.collect()))
}
}
等式の評価
等式left == rightを表す構文の非終端記号DefLEqualに対しては,両辺をそれぞれ評価し,それらが等しいかどうかをValue列挙型のBoolに入れて返します.
pub struct DefLEqual(
LEqualOp,
[Operand; 2],
);
impl Evaluator for DefLEqual {
fn evaluate(&self, stack_frame: &mut interpreter::StackFrame, root: &reference::Node, current: &name::Path) -> Option<interpreter::Value> {
let Self(
_l_equal_op,
[left, right],
) = self;
let left: Option<interpreter::Value> = left.evaluate(stack_frame, root, current);
let right: Option<interpreter::Value> = right.evaluate(stack_frame, root, current);
left
.zip(right)
.map(|(left, right)| interpreter::Value::Bool(left == right))
}
}
このように,AMLの式の評価を,その式を表す非終端記号へのEvaluatorトレイトの実装として書いていきます.
式の評価だけではなく,命令列や制御文の実行もEvaluatorトレイトの実装として作ることができます.
命令列の実行
関数や制御分などのブロック内の命令列を表す非終端記号TermListに対しては,命令列term_objsを構成する各命令term_objを順番に実行していきます.
ただし,return命令,break命令,continue命令が実行されていないことが継続条件になっています.
これらの命令が実行されたら,そのブロック内のそれ以降の命令はすべて実行されないようにしています.
pub struct TermList(
Vec<TermObj>,
);
impl Evaluator for TermList {
fn evaluate(&self, stack_frame: &mut interpreter::StackFrame, root: &reference::Node, current: &name::Path) -> Option<interpreter::Value> {
let Self(term_objs) = self;
term_objs
.iter()
.for_each(|term_obj| if stack_frame.read_return().is_none() && !stack_frame.is_broken() && !stack_frame.is_continued() {
term_obj.evaluate(stack_frame, root, current);
});
stack_frame
.read_return()
.cloned()
}
}
代入
非終端記号DefStoreは,「super_name = term_arg」という形式の代入文を表します.
代入文の実行もEvaluatorトレイトとして実装され,term_argを評価した結果をsuper_nameにholdさせています.
pub struct DefStore(
StoreOp,
TermArg,
SuperName,
);
impl Evaluator for DefStore {
fn evaluate(&self, stack_frame: &mut interpreter::StackFrame, root: &reference::Node, current: &name::Path) -> Option<interpreter::Value> {
let Self(
_store_op,
term_arg,
super_name,
) = self;
term_arg
.evaluate(stack_frame, root, current)
.map(|term_arg| super_name.hold(term_arg, stack_frame, root, current))
}
}
hold関数は以下のHolderトレイトで定義されています.
pub trait Holder {
fn hold(&self, value: Value, stack_frame: &mut StackFrame, root: &reference::Node, current: &name::Path) -> Value;
}
各引数の意味は以下の通りです.
-
selfは,代入先を表す構文の非終端記号 -
valueは,代入する値 -
stack_frameは,現在実行中の関数のスタックフレーム -
rootは,参照木の根ノード -
currentは,参照木上の現在地
Holderトレイトの実装例を見てみましょう.
ローカル変数への代入
ローカル変数はスタックフレームの中に存在しているので,スタックフレームに対して*index番目のローカル変数にvalueを代入させています.
impl Holder for LocalObj {
fn hold(&self, value: interpreter::Value, stack_frame: &mut interpreter::StackFrame, _root: &reference::Node, _current: &name::Path) -> interpreter::Value {
let Self(index) = self;
stack_frame.write_local(*index as usize, value)
}
}
impl StackFrame {
...
pub fn write_local(&mut self, index: usize, value: Value) -> Value {
self.locals[index] = Some(value.clone());
value
}
...
}
NamedFieldへの代入
AMLには,メモリ空間やIO空間の任意の領域を表す構文NamedFieldがあります.
NamedFieldの例として,VirtualBoxから取り出したDSDTをAMLからASLに翻訳したものからの抜粋を以下に示します.
OperationRegion (DBG0, SystemIO, 0x3000, 0x04)
Field (DBG0, ByteAcc, NoLock, Preserve)
{
DHE1, 8
}
SystemIOつまりIO空間の0x3000番ポートから始まる0x04バイトの領域をDBG0と名付け,その最初の8ビット分の領域をDHE1と名付けています.
AMLインタプリタはAMLを実行していく中でこのようなNamedFieldへの読み書きによってハードウェアとやり取りします.
例えば,Local0 = DHE1はIO空間の0x3000番ポートから1バイト読み取って0番目のローカル変数に代入することを意味しますし,DHE1 = 0はIO空間の0x3000番ポートに1バイトの0を書き込むことを意味します.
制御文の実行
制御文の実行もEvaluatorトレイトとして実装します.
こちらも例を見てみましょう.
if-else文の実行
if-else文は,if文を持ち,オプションでelse文を持つ場合があります.
if文は,条件式predicateと中身の命令列term_listからなります.
条件式predicateを評価して,その結果がtrueだった場合は,if文の中身の命令列term_listを実行します.
条件式predicateの評価結果がfalseであり,なおかつelse文が存在する場合は,そのelse文を実行します.
pub struct DefIfElse(
DefIf,
Option<DefElse>,
);
impl Evaluator for DefIfElse {
fn evaluate(&self, stack_frame: &mut interpreter::StackFrame, root: &reference::Node, current: &name::Path) -> Option<interpreter::Value> {
let Self(
DefIf(
_if_op,
_pkg_length,
predicate,
term_list,
),
def_else,
) = self;
if predicate
.evaluate(stack_frame, root, current)
.map_or(false, |predicate| (&predicate).into()) {
term_list.evaluate(stack_frame, root, current)
} else {
def_else
.as_ref()
.and_then(|def_else| def_else.evaluate(stack_frame, root, current))
}
}
}
while文の実行
while文は条件式predicateと中身の命令列term_listからなります.
条件式predicateの評価結果がtrueであり,break命令が実行されていない限りにおいて,中身の命令列term_listを実行し続けます.
また,term_list実行中にcontinue命令が実行された場合,term_listのそれ以降の命令列は実行されません.
しかし,while文において次のループに進む時には,continue命令が実行されたという記憶をスタックフレームから消しておく必要があるため,stack_frame.uncontinue()を実行しています.
pub struct DefWhile(
WhileOp,
PkgLength,
Predicate,
TermList,
);
impl Evaluator for DefWhile {
fn evaluate(&self, stack_frame: &mut interpreter::StackFrame, root: &reference::Node, current: &name::Path) -> Option<interpreter::Value> {
let Self(
_while_op,
_pkg_length,
predicate,
term_list,
) = self;
stack_frame.enter_loop();
while {
let predicate: bool = predicate
.evaluate(stack_frame, root, current)
.map_or(false, |predicate| (&predicate).into());
let broken: bool = stack_frame.is_broken();
predicate && !broken
} {
term_list.evaluate(stack_frame, root, current);
stack_frame.uncontinue();
}
stack_frame.leave_loop();
None
}
}
関数呼び出し
関数呼び出しもEvaluatorトレイトとして実装されます.
まず関数の相対パスを絶対パスに変換しておきます.
次に関数に渡す引数をあらかじめ評価しておきます.
そして,名前付きローカル変数,名前付きグローバル変数,NamedFieldのような関数でないものの評価も,構文上引数の無い関数呼び出しとして扱われるので,ここで評価しています.
本当に関数呼び出しだった場合,その関数を実行するための新しいスタックフレームを作成し,評価しておいた引数の値を入れ,関数を実行し,その返り値を返します.
pub struct MethodInvocation(
NameString,
Vec<TermArg>,
);
impl Evaluator for MethodInvocation {
fn evaluate(&self, stack_frame: &mut interpreter::StackFrame, root: &reference::Node, current: &name::Path) -> Option<interpreter::Value> {
let Self(
name_string,
term_args,
) = self;
let relative_method_path: name::Path = name_string.into(); // 関数の相対パス
let absolute_method_path = name::AbsolutePath::new(current, &relative_method_path); // 関数の絶対パス
let term_args: Vec<interpreter::Value> = term_args // 関数に渡す引数を評価
.iter()
.filter_map(|term_arg| term_arg.evaluate(stack_frame, root, current))
.collect();
stack_frame
.read_named_local(&relative_method_path) // 名前付きローカル変数だった場合,その値を返す.
.or_else(|| root
.get_name_from_current(&absolute_method_path) // 名前付きグローバル変数名だった場合,その値を返す.
.and_then(|(current, name)| name.evaluate(stack_frame, root, ¤t)))
.or_else(|| root.read_named_field(stack_frame, root, &absolute_method_path)) // NamedFieldだった場合,そこから値を読みだす.
.or_else(|| root
.get_method_from_current(&absolute_method_path) // 関数だった場合,その関数を実行し,その返り値を返す.
.and_then(|(current, method)| {
let mut stack_frame = interpreter::StackFrame::default() // 関数を実行するための新しいスタックフレーム
.set_arguments(term_args); // 新しいスタックフレームに引数を設定
method.evaluate(&mut stack_frame, root, ¤t) // 関数を実行し,その返り値を返す.
}))
}
}
長かったですね.
ここまで来ればAMLを実行するとはどういうことか,なんとなくイメージできるようになったのではないでしょうか?
AMLが表現できるすべての演算を実装したわけではありませんが,これまでに説明したような基本的な演算を実装することで,QEMU,VirtualBox,VMware,GPD MicroPCの4環境でシャットダウンできるようになりました.
まとめ
自作OSにシャットダウンを実装するためには,AMLという言語で書かれたDSDTを解析し,\_TTS(5)を実行し,\_PTS(5)を実行し,\_S5の値をPM1a_CNT_BLKおよびPM1b_CNT_BLKに書き込む必要があります.
AMLを構文解析するために,非終端記号を構造体や列挙体などの型て表現し,それらの型に構文解析するトレイトを実装します.
約350種類の非終端記号に対して,それを解析するコードを手動で書くのはかなり労力がいるので,Rustのderiveを使ってトレイトを実装するコードを自動生成します.
構文解析の段階で発生する「関数呼び出しの引数の個数分からない問題」の解決策として,1回目の解析で関数の中身の命令列を解析せずに関数の引数の個数の情報だけ取って,2回目の解析で関数の中身の命令列を解析する「2回読み」があります.
AML上のパスの解決を様にするため,参照木を作り,参照木上でAMLを実行するようにします.
AMLで表現可能なすべてのデータ型を表す列挙型を作り,値同士の四則演算やビット演算などを実装します.
スタックフレームを定義し,AMLの関数実行中のコンテキストを表現します.
非終端記号にEvaluatorトレイトを実装し,値として評価できるようにします.
変数などの書き込みを行える構文に対してはHolderトレイトを実装し,値を保持できるようにします.
AMLは,NamedFieldへの読み書きによって,ハードウェアとやり取りします.
if文やwhile文などの制御分の実行もEvaluatorトレイトとして実装します.
関数呼び出しは,新しいスタックフレームに引数の評価値を入れて実行するようにします.